
# 数据服务
数据服务是对关系型数据库访问的封装。
用户可以通过EOS提供的持久化实体、查询实体和命名SQL等工具来实现对数据库的访问,改变以往通过底层JDBC的编程,直接运行sql语句进行数据库查询和更新的做法;从而屏蔽技术细节,方便用户开发,并提供更好的跨数据库的移植性。
# 数据集
数据集是多个数据实体的一个集合,具体的表现形式就是多个实体类型定义在一个.xsd文件中。这个.xsd文件就被称作数据集。

newdataset就是一个数据集,对应的文件就是newdataset.xsd。 该数据集里定义了3个持久化实体:Product、ProductService、Service。 这3个实体的类型全名分别是:
- com.primeton.eos.newdataset.Product
- com.primeton.eos.newdataset.ProductService
- com.primeton.eos.newdataset.Service
# 实体
# 基本概念
EOS6中,实体就是指通过XSD来定义的SDO的数据对象(commonj.sdo.DataObject)。
一个实体会有类型,类型会包含一些属性,每个属性又都有自己的类型。
这就类似于一个Java Class的定义,每个Class都有自己的属性,每个属性也会有相应的Class。
可以把DataObject和JavaBean进行类比,2种对象都是用于存放数据的。
在Stuido中可以创建3种不同类型的实体,分别是实体、持久化实体、查询实体,以及4种关联关系。如下图:

这些概念会在后面逐一介绍。
# 示例
下面是一个实体的例子:
在数据集中创建一个User实体,可以通过在选用板中选中实体拖动到数据集视图中,并设置名称和属性。
在数据集中如下图显示:

User实体包括3个属性:userName(String)、age(Int)、gender(String),其中gender的默认值是male。
说明
对于设置了默认值的属性,创建对象以后,如果没有操作过该属性,则该属性的值就是默认值。
在数据集中双击User实体,出现属性设置框,如下图:
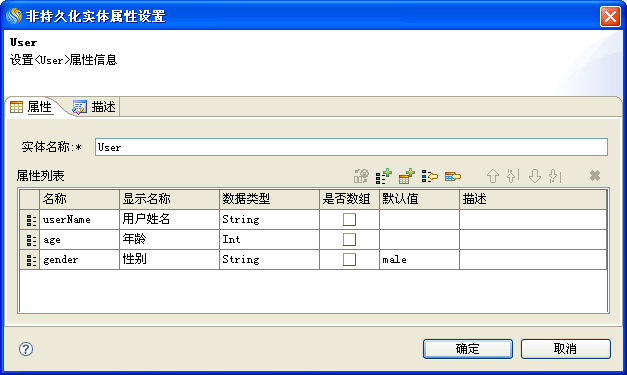 设置实例类属性,这个属性用来说明该实体所对应的静态SDO类型,这里没有设置,说明没有静态的SDO类型与该实体对应。
设置实例类属性,这个属性用来说明该实体所对应的静态SDO类型,这里没有设置,说明没有静态的SDO类型与该实体对应。说明
静态的SDO类型实际上是实现了commonj.sdo.DataObject接口,并且对于该实体的属性提供了setter/getter的Java Class。 关于实体类型及其静态的SDO类型对应的例子可以参见CriteriaEntity静态SDO类型 (opens new window)的描述。
# 持久化实体
持久化实体是和数据库表有映射关系的实体。每个持久化实体必须对应一个数据库表。
持久化实体里的简单类型的属性可以直接和列做映射。 如果是个复杂类型的属性则需要通过关联关系来设置映射。关联关系会在关联 (opens new window)中说明。
通过操作持久化实体可以对数据库表的记录进行增删改查操作。
下表中,显示了持久化实体属性的数据类型和数据库表的字段类型的映射关系。
| 显示类型(显示在Studio上供用户选择的类型) | SDO类型 | DAS类型 | Jdbc类型 |
|---|---|---|---|
| Byte | Byte | byte | TINYINT |
| Short | Short | short | SMALLINT |
| Float | Float | float | FLOAT |
| Int | Int | int | INTEGER |
| Double | Double | double | DOUBLE |
| Long | Long | long | BIGINT |
| Decimal | Decimal | big_decimal | NUMERIC |
| Boolean | Boolean | boolean | BIT |
| String | String | string | VARCHAR |
| Date | Date | date | DATE |
| Time | Time | timeString | TIME |
| TimeStamp | Date | timestamp | TIMESTAMP |
| ClobString | String | com.primeton.das.entity.impl.lob.type.ClobStringType | CLOB |
| BlobByteArray | Bytes | com.primeton.das.entity.impl.lob.type.BlobByteArrayType | BLOB |
| ClobFile | String | com.primeton.das.entity.impl.lob.type.ClobFileType | CLOB |
| BlobFile | String | com.primeton.das.entity.impl.lob.type.BlobFileType | BLOB |
说明
表中第一列显示类型就是持久化实体属性的数据类型。 用户在Studio创建持久化实体时可以选择属性的类型,后面3列的类型对用户是不可见的,会根据选择的显示类型自动生成。
持久化实体属性设置如下图:
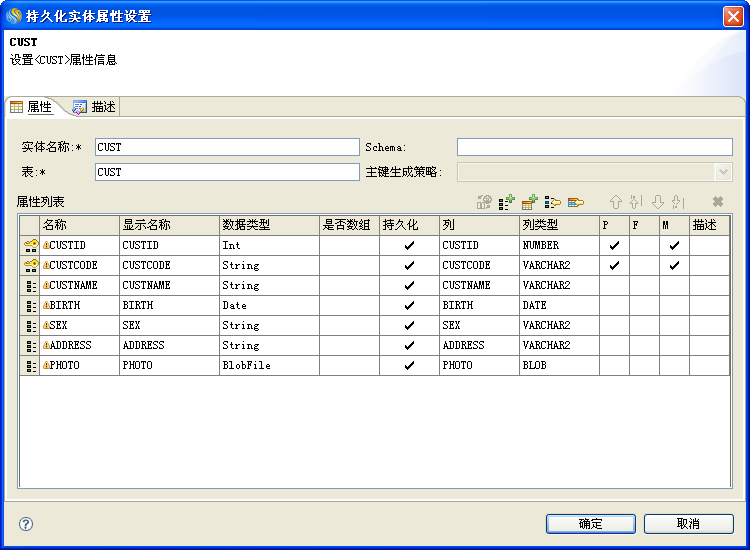
持久化实体的其它设置项说明如下:
| 持久化实体的设置项 | 说明 |
|---|---|
| 表 | 说明持久化实体要和哪张表做映射。 |
| Schema | 说明映射的表是在哪个Schema中,不写就认为连接数据库时用户对应的Schema。 |
| 主键生成策略 | native:利用数据库本身提供的主键自增的功能自动生成主键。 如Oracle就要使用sequence来实现自动生成主键,sequence的名字是"eos_sequence",而DB2、MySql、SQLSERVER、SYBASE、INFORMIX则可以在建表时指定主键列是自增长的。assigned:由用户自己分配一个主键。uuid:由程序自动生成一个32位的无连续性的字符串作为主键。注意uuid的主键生成策略不支持在一台机器上搭建的集群环境。 |
# 相关约束
- 持久化实体里不能定义属性名为id的属性(主键对应的属性可以使用id这个名称),id是保留关键字;
- 同一数据集中持久化实体名称具有唯一性,大小写敏感;
- 允许不同的持久化实体对应同一张数据库表;
- 不支持继承关系的映射。
# 简单示例
com.eos.das.entity.IDASSession是对java.sql.Connection的封装,可以使用该接口对持久化实体进行增删改查的操作。
持久化实体com.eos.User定义如下,该实体对应的数据库表为EOS_USER,下面的代码的作用是对USER表新增一条记录。

更多的接口定义和介绍参见接口及方法说明 (opens new window)。
//TODO:beginTransaction();
//TODO:getConnection();
//创建IDASSession,用于操作实体
IDASSession session = DASManager.createDasSession(connection);
//创建一个User.
DataObject dataObject = DataFactory.INSTANCE.create("com.eos","User");
dataObject.setString("userId","0001");
dataObject.setString("userName","xiaohu");
//保存User.
session.insertEntity(dataObject);
session.close();
//TODO:closeConnection();
//TODO:commitTransaction();
# 查询实体
通过定义一句查询的sql语句或一个数据库的视图来指明数据是如何获取的,并且设置获取后的数据如何和一个实体做映射,则这个实体就被称作查询实体。 查询实体用于映射的属性都是简单属性。
可以对不同类型的数据库指定查询的sql语句或视图名称,因为每种数据库的sql语法有差异,并且也不是每种数据库都支持视图;但是必须指定一个default类型的配置,因为EOS6会在程序运行时根据数据库连接自动判断数据库类型,然后根据对该种类型的数据库配置来获取数据,如果没有找到对该种数据库的配置,则会使用default类型的配置。
查询实体的定义界面如下:
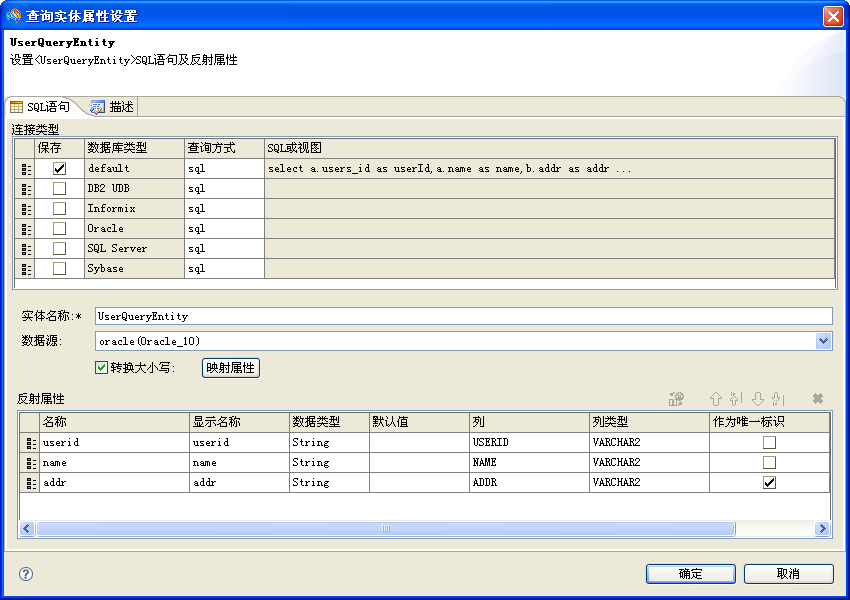
可以对不同类型的数据库设置查询方式(sql或view),写上查询语句、实体名称,选好数据源,然后点击映射属性,就会在下面的反射属性里生成属性和列的映射。以后使用该查询实体查询时,数据库记录就会按照设置的映射关系,把列的值放入到对应的属性里。
# 相关约束
- 查询实体里不能定义属性名叫id的属性(唯一标识对应的属性可以使用id这个名称),id是保留关键字;
- 同一数据集中查询实体名称具有唯一性;
- 查询实体只能用于查询,不可以对其执行增删改的操作;
- 如果指定的查询sql语句或视图中有2个相同的列名,需要起不同的别名来区分。
注意
查询实体允许用户通过指定某一列或几列的值来做为查询实体的唯一标识。 如果用户没有指定,EOS6会自动使用一个常量来作为该查询实体唯一标识。 但是如果用默认的唯一标识,就不能使用持久化实体和该查询实体做单向1:1关联和单向N:1关联,否则对持久化实体做操作会抛异常。
# 简单示例
可以使用com.eos.das.entity.IDASSession的接口对查询实体进行查询操作。关于接口方法的介绍可以参见接口及方法说明 (opens new window)。
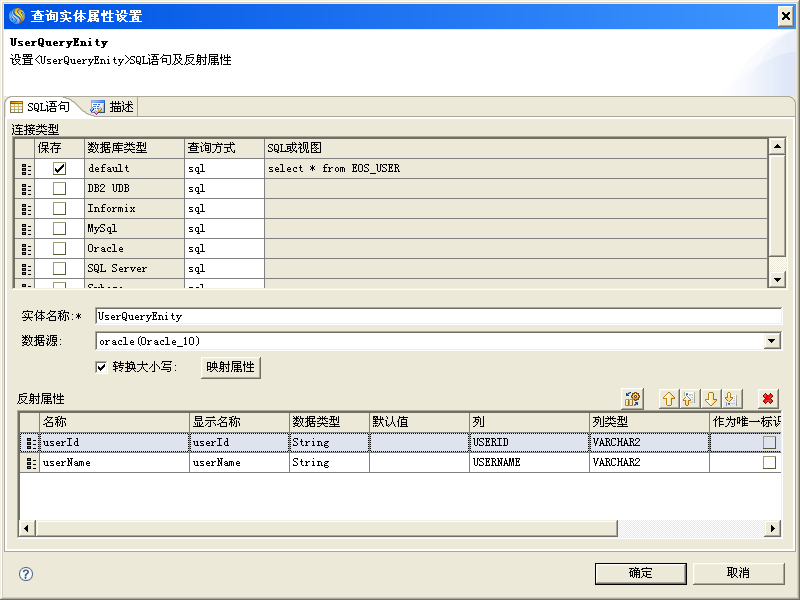
查询实体的定义如下图所示,该实体的全名是com.eos.UserQueryEnity。
//TODO:getConnection();
//创建IDASSession,用于操作实体
IDASSession session = DASManager.createDasSession(connection);
//创建一个IDASCriteria,指明对哪个实体操作,用于查询
IDASCriteria criteria =
DASManager.createCriteria("com.eos.UserQueryEnity");
//增加一个查询条件 User.userId = '0001'
criteria.add(ExpressionHelper.eq("userId","0001"));
//查询出一个UserQueryEntity对象,
DataObject userQueryEntity = session.queryEntity(criteria);
session.close();
//TODO:closeConnection();
com.eos.UserQueryEntity是通过"select * from EOS_USER"这句sql定义的。 上面代码实际上等于执行了这样的查询"select * from (select * from EOS_USER) t where t.USERID='0001'"。
注意
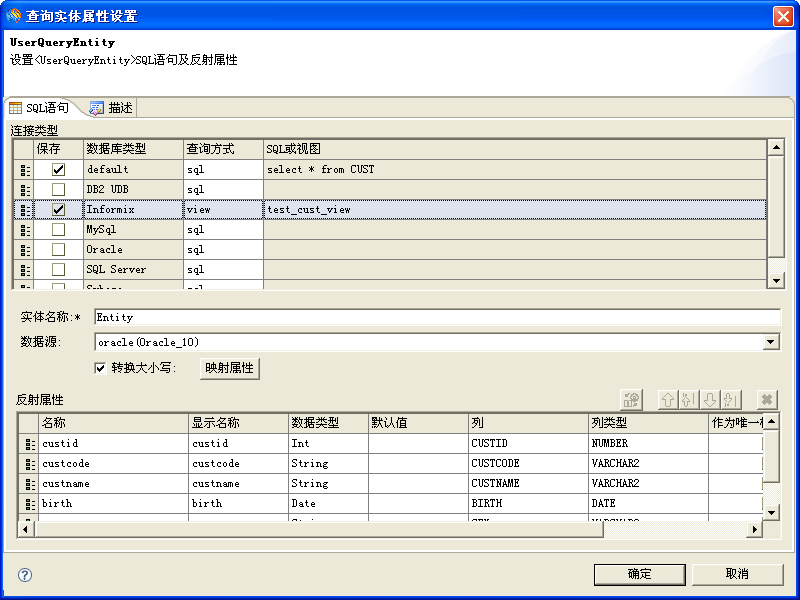
由于Informix数据库本身不支持SQL方式,所以在使用Informix时需要将查询方式设置为View。如下图所示:
# 关联
这里介绍的关联只适用于持久化实体和查询实体,不包括一般实体。因此下面的介绍中会用"实体"来代替"持久化实体"和"查询实体"。
关联就是指在一个实体对象中有另一个实体对象的引用。 EOS6支持4种关联关系:单向1:1关联、单向1:N关联、单向N:1关联、双向1:N关联。
# 基本规则
有持久化实体PersistentEntityA、PersistentEntityB、查询实体QueryEntityC。
- 2个持久化实体之间只能建立一个关联关系,但不限定是由哪个实体发起。 就是说既可以是从PersistentEntityA关联到PersistentEntityB,也可以是从PersistentEntityB关联到PersistentEntityA。(双向1:N被认为是一个关联关系)
- 1个持久化实体和1个查询实体之间只能建立一个关联关系,而且必须是从持久化实体关联到查询实体。
EOS6支持的4种关联关系,如无特别说明,则只有上面2条规则。
# 延迟加载
延迟加载就是指当查询出一个主端的对象时,其关联的对象并不会立即被连带的查出。 这在1:N关联时对于性能有影响,因为1端对象关联的N端对象可能非常多。每次查询1端实体就把关联的N端实体查询出来,是非常慢的。
说明
单向1:1关联没有延迟加载。
双向1:N关联就是单向1:N关联和单向N:1关联的组合。所有可用的功能和约束也是单向1:N关联和单向N:1关联的并集。
# 单向1:1关联
# 简介
单向1:1关联不需要设置关联属性,直接通过2个实体的主键关联。
如com.eos.User和com.eos.UserInfo两个实体是单向1:1关联。那么在实体上表现出来就是User里有一个UserInfo类型的属性。通过User就可以访问到UserInfo的属性。
user.getString("userInfo/phone");
EOS6限制如果2个实体要建立单向1:1关联,则2个实体必须是单主键且生成策略必须是用户指定(assigned)。因为在保存时需要用户自行保证2个实体id的一致性。所以不能选用其它2种生成策略。如果想建立复合主键的单向1:1关联,可以使用单向N:1替代(会在单向N:1关联 (opens new window)中说明)。
注意
- 如果要设置User的主键是通过 user.set("userId","1");
- 如果要设置UserInfo的主键是通过 userInfo.set("userId","1");
这和N:1的关联是不同的,因为N:1的关联,会把N端实体中用于关联的属性用1端实体代替,所以如果上面的例子改成User和UserInfo是N:1关联,则要设置User的主键就是通过user.set("userInfo/userId","1"),因为在N:1的情况下,N端实体里已经没有userId这个属性了。
单向1:1是没有延迟加载的,即当用户查询一个1端的实体,另一个被关联的1端实体也会被查询出来。
如com.eos.User和com.eos.UserInfo是单向1:1关联,则查询User时,会自动把UserInfo也查询出来。如果查询和更新在同一个IDASSession中,那么对User和UserInfo的修改都会反映到数据库中。

# 相关约束
- 2个实体必须是单主键且生成策略必须是用户指定(assigned);
- 用户保证2个实体主键的一致性;
- 单向1:1关联没有延迟加载,会通过一个左外联查询出主控对象和关联对象。
# 简单示例
//TODO:beginTransaction();
//TODO:getConnection();
//创建IDASSession,用于操作实体
IDASSession session = DASManager.createDasSession(connection);
//创建一个IDASCriteria,用于查询
IDASCriteria criteria = DASManager.createCriteria("com.eos.User");
//增加一个查询条件 User.userId = '0001'
criteria.add(ExpressionHelper.eq("userId","0001"));
//查询出一个User对象,并且关联的UserInfo也会被查出来
DataObject user = session.queryEntity(criteria);
//更新User及UserInfo
user.set ("userName","xiaohu2");
user.set("userInfo/phone","13310945445");
//保存更新, 这样对User和UserInfo的更新都会更新到数据库.
session.updateEntity(user);
session.close();
//TODO:closeConnection();
//TODO:commitTransaction();
这里之所以会产生类似级联操作的效果是因为查询和更新在同一个session里。
在session里会维护一个cache。在这个cache里会保存通过该session操作过的所有实体(包括查询和修改)。因此放在这个cache里的实体可以简单的理解为就是在数据库中的数据。当这个session和数据库进行同步时(如update),session会自动把cache里的所有单个实体和数据库进行一次同步。
注意
- 这种情况下session只会处理单个实体,对于实体集合会忽略。因为实体集合一定是属于某个实体的,而单个实体无法确认是否被其它实体引用还是就是一个孤立的实体。单向N:1也会有这种情况。
- 对于新增不存在该问题,因为新增时,实体还没有在session cache中。
# 单向N:1关联
# 简介
设置单向N:1关联的时候,需要在N端实体中指定用于关联的属性。该N端的属性可以是主键也可以是非主键。
1端的关联字段必须是主键(可以是单主键也可以是复合主键)。N端必须要选择相同个数的属性和1端主键匹配。 如:1端主键是单主键,那么N端也只要选择一个属性和它对应即可;如果1端主键是多主键,那么N端也要选择多个属性和它对应。
注意
当在N端选择了用于关联的属性,那么这些属性在N端实体中就会被删除,然后会用1个1端实体来代替。当要访问N端这些属性的值时,就需要通过访问相应的1端的主键值来获得。
单向N:1关联有3种不同方式的关联,以下的举例只是为了说明如何建立这3种不同的关联,并没有任何实际意义。
# 使用N端外键关联
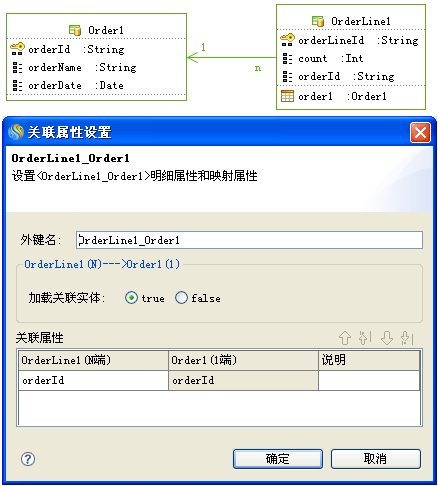 这是一种普遍使用的场景,使用N端实体的非主键属性(orderId)和1端实体的主键属性(orderId)进行关联。
这是一种普遍使用的场景,使用N端实体的非主键属性(orderId)和1端实体的主键属性(orderId)进行关联。
# 使用N端部分主键关联
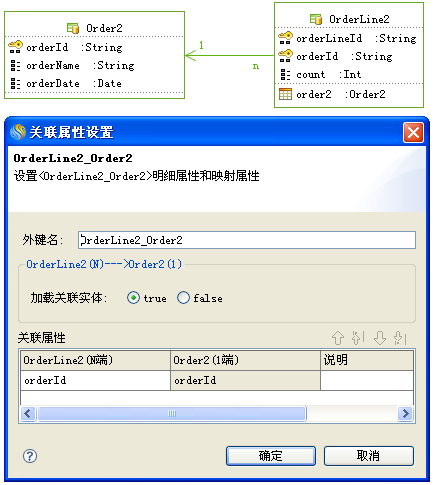 N端实体是个联合主键(orderLineId,orderId),用了其中一个主键(orderId)和1端实体关联。
N端实体是个联合主键(orderLineId,orderId),用了其中一个主键(orderId)和1端实体关联。
# 使用N端全部主键关联
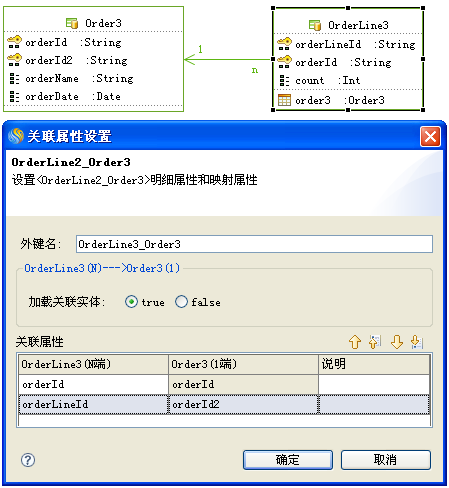 可以把这个当作一种特殊的单向1:1关联,N端实体是个联合主键,并且所有主键都用于和1端实体进行关联。因为单向1:1关联不支持用联合主键做关联。
可以把这个当作一种特殊的单向1:1关联,N端实体是个联合主键,并且所有主键都用于和1端实体进行关联。因为单向1:1关联不支持用联合主键做关联。
说明
如果想操作N端的用于关联的属性,则要通过操作1端实体的主键属性才可以。如oderLine.setString("order/oderId","0001"); orderLine.getString("order/oderId'); 因为N端用于关联的这个属性会在N端实体中被删除,所以无法操作。
单向N:1关联是支持延迟加载的。
- 如果设置延迟加载为false,那么会在查询N端实体时,同时查询1端实体,查询时是用一句join sql查询;
- 如果设为true,则先是查出所有的N端实体,然后根据N端的关联属性去查询1端实体。
# 相关约束
- 被关联的1端实体一定是主键,单/复合主键都可以。
- N端实体必须要选择相同个数的属性和1端主键匹配。 被选择的N端实体的属性或者全部是主键,或者全部是非主键。
- 单向N:1关联支持延迟加载。
# 单向1:N关联
# 简介
1端的关联字段必须是主键(可以是单主键也可以是复合主键)。N端必须要选择相同个数的列和1端主键匹配。
注意
- 单向1:N关联时的约束和单向N:1关联 (opens new window)没有区别。 不同之处在于实体的使用方式。
- 单向N:1的关联,可以通过N端的实体对象访问到1端的实体对象,如orderLine.getString("order/orderDate");但是通过1端的实体对象无法访问到N端的实体对象,如order.getString("orderLines[1]/detail")。
- 单向1:N的关联,可以通过1端的实体对象访问到N端的实体对象,但是无法通过N端的实体对象访问到1端的实体对象。
单向1:N是支持延迟加载的,如果延迟加载设为false,那么会先用一句sql查出1端实体,然后根据1端实体的主键查询出关联的N端实体,这样就会产生1+N的sql查询。 如:
select * from ORDER
select * from ORDERLINE where ORDERID = '1'
select * from ORDERLINE where ORDERID = '2'
这样就是1+N的查询,会有3条sql。因为第一句sql查询出了2条1端记录,然后根据这2个1端实体的主键作为条件产生2句查询N端实体的sql。 数据量大的情况下会对性能造成影响。
如果延迟加载设为true,一开始只会生成第1句查询语句,后面2句不会生成,然后按照用户的需要指定要加载哪个1端实体关联的N端实体。
# 相关约束
- 1端实体一定是主键,单/复合主键都可以。
- 被关联的N端实体必须要选择相同个数的属性和1端主键匹配。 被选择的N端实体的属性或者全部是主键,或者全部是非主键。
- 单向1:N关联支持延迟加载。
# 关联相关API
EOS6的数据服务模块暂时不支持级联操作,级联操作就是指对关联的主控方(即拥有关联属性的那个实体,如单向N:1中的OrderLine)进行新增/更新/删除操作时,被关联的对象也会跟着被新增/更新/删除。我们在这里主要讨论和查询相关的API。
示例代码中用到的实体定义如下:

# 动态的关联查询
对于关联实体是否使用延迟加载,除了可以通过创建关联时在Studio中指定,也可以通过API来动态的指定。 IDASCriteria的addAssociation就是为了完成该功能而提供的API。
- 对于单向N:1关联
//TODO:getConnection();
//创建IDASSession,用于操作实体
IDASSession session = DASManager.createDasSession(connection);
//创建一个IDASCriteria,用于查询
IDASCriteria criteria = DASManager.createCriteria("com.eos.OrderLine");
//增加一个关联查询
criteria.addAssociation("order");
List<DataObject> orderLines= session.query(criteria);
session.close();
//TODO:closeConnection();
以上代码会产生类似于下面的sql:
select * from ORDERLINE left outer join ORDER on ORDERLINE.ORDERID = ORDER.ORDERID
注意
EOS6只提供了addAssociation,能把延迟加载变为立即加载,而没有提供API能把已经设置为立即加载的变为延迟加载;
使用该API会产生左外联的sql查询语句。
对于单向1:N关联
//TODO:getConnection();
//创建IDASSession,用于操作实体
IDASSession session = DASManager.createDasSession(connection);
//创建一个IDASCriteria,用于查询
IDASCriteria criteria = DASManager.createCriteria("com.eos.Order");
//增加一个关联查询
criteria.addAssociation("orderLines");
criteria.add(ExpressionHelper.eq("orderId","1"));
List<DataObject> orders= session.query(criteria);
session.close();
//TODO:closeConnection();
以上代码也会产生一个左外联的sql查询。如果ORDERID='1'的ORDER记录有3条ORDERLINE的关联记录,那么查询出来的结果就是3个Order对象,3个Order对象的地址(相当于java中==)是一样的,并且每个Order对象里都会有一个3个OrderLine对象的集合。这是因为sql查询出来的ResultSet会有3条记录,为了保证和ResultSet行数一样,所以对象也会产生3个。
注意
对于1:N的关联不建议使用左外联的查询,除非用户不关心查询出来的实体集合里有重复对象。
# 加载延迟的关联对象
对于已经在Studio里设置了延迟加载的关联,而又不想通过上面的API变为动态的关联查询,还可以通过IDASSession的expandRelation(DataObject entity,String property)这个API来查询一个对象的延迟加载的关联属性。参数entity是一个主键信息已经被设置好的数据对象,property是该数据对象中的一个关联属性,可以是1:N的关联属性也可以是N:1的关联属性。
对于延迟加载的单向1:N关联:
//TODO:getConnection();
//创建IDASSession,用于操作实体
IDASSession session = DASManager.createDasSession(connection);
//创建一个IDASCriteria,用于查询
IDASCriteria criteria = DASManager.createCriteria("com.eos.Order");
criteria.add(ExpressionHelper.eq("orderId","1"));
DataObject order= session.queryEntity (criteria);
//查询延迟加载的属性"orderLines"
session.expandRelation(order, "orderLines");
session.close();
//TODO:closeConnection();
单向N:1关联也可以使用该API进行查询,不再举例。
# 关联对象的属性做为查询条件
关联对象就是指有关联关系的对象。
对于使用关联对象的属性作为查询条件分为2种情况:
- 使用关联对象中用于关联的属性作为查询条件;
- 使用关联对象中其它的属性作为查询条件。
单向1:1、单向N:1,使用1端对象属性作为查询条件。
- 对于第一种情况代码示例如下:
//TODO:getConnection();
//创建IDASSession,用于操作实体
IDASSession session = DASManager.createDasSession(connection);
//创建一个IDASCriteria,用于查询
IDASCriteria criteria = DASManager.createCriteria("com.eos.OrderLine");
//增加一个关联对象的属性作为查询条件
criteria.add(ExpressionHelper.eq("order.orderId","1"));
List<DataObject> orderLines= session.query(criteria);
session.close();
//TODO:closeConnection();
criteria.add(ExpressionHelper.eq("order.orderId","1"));就是一个以关联对象中用于关联的属性作为查询条件的。因为OrderLine和Order的关联就是通过ORDERLINE.ORDERID和ORDER.ORDERID建立的。产生的sql类似于:
select * from ORDERLINE where ORDERID='1'
即一个单表查询。
说明
这里之所以生成的sql语句是对单表查询,是因为N端实体所对应的表里一定会有列和1端实体中用于关联的属性(即主键)所对应的列关联。 所以用1端实体的主键做为条件可以优化成使用N端的表里的关联列(可以理解成外键)作为查询条件。
注意
如果写了criteria.addAssociation("order");,再使用order.orderId做为查询条件,就不会再优化了,因为已经关联了Order,就会直接使用ORDER.ORDERID做为查询条件了。
- 对于第二种情况代码示例如下:
//TODO:getConnection();
//创建IDASSession,用于操作实体
IDASSession session = DASManager.createDasSession(connection);
//创建一个IDASCriteria,用于查询
IDASCriteria criteria = DASManager.createCriteria("com.eos.OrderLine");
java.util.Date orderDate = new Date();
//ORDER.ORDERDATE < new Date();
//增加一个关联对象的属性作为查询条件
criteria.addAssociation("order");
criteria.add(ExpressionHelper.lt("order.orderDate", orderDate));
List<DataObject> orderLines= session.query(criteria);
session.close();
//TODO:closeConnection();
以上代码产生的sql类似于:
select * from ORDERLINE left outer join ORDER on ORDERLINE.ORDERID = ORDER.ORDERID
where ORDER.ORDERDATE < new Date()
注意
和第一种情况不同的,第二种情况的查询需要先addAssociation("order"),然后才能使用Order对象里的属性orderDate作为查询条件。
对于单向1:N,无论是第一种情况还是第二种情况,都需要先addAssociation N端的实体对象,才能使用N端的属性作为查询条件。
# IDASCriteria
IDASCriteria通过面向对象化的设计,将数据查询条件封装为一个对象。 简单来讲,IDASCriteria可以看作是传统SQL的对象化表示,如:
//TODO: getConnection;
IDASCriteria criteria = DASManager.createCriteria("com.eos.User");
criteria.add(ExpressionHelper.eq("userName", "xiaohu"));
criteria.add(ExpressionHelper.eq("gender",1));
IDASSession session = DASManager.createDasSession(conn);
List<DataObject> result = session.query(criteria);
session.close();
//TODO: printResult;
//TODO: closeConnection;
以上代码就完成了一个数据库查询,并把查询结果转换成了"com.eos.User"类型的实体对象。 criteria就相当于SQL"SELECT * from EOS_USER where USERNAME='xiaohu' and GENDER= 1"。 "com.eos.User"的实体定义如下:

EOS6在运行期会根据Criteria中指定的查询条件(也就是上面代码中通过criteria.add方式添加的查询表达式)生成相应的SQL语句。
# 查询表达式
IDASCriteria本身只是一个查询容器,具体的查询条件需要通过Criteria.add方法添加到Criteria实例中。
如上例所示,Expression对象具体描述了查询条件。针对SQL语法,ExpressionHelper提供了对应的查询限定机制。
| 方法 | 描述 |
|---|---|
| ExpressionHelper.eq | 对应SQL"field = value"的表达式 |
| ExpressionHelper.ne | 对应SQL"field <> value"的表达式 |
| ExpressionHelper.like | 对应SQL"field like value"的表达式 |
| ExpressionHelper.gt | 对应SQL"field > value"的表达式 |
| ExpressionHelper.lt | 对应SQL"field < value"的表达式 |
| ExpressionHelper.ge | 对应SQL"field >= value"的表达式 |
| ExpressionHelper.le | 对应SQL"field <= value"的表达式 |
| ExpressionHelper.between | 对应SQL"field between value"的表达式。 如下面的年龄表达式(age)位于13到50区间内。 ExpressionHelper.between("age",13,50); |
| ExpressionHelper.in | 对应SQL"field in (value1,value2)"的表达式 |
| ExpressionHelper.isNull | 对应SQL"field is null"的表达式 |
| ExpressionHelper.isNotNull | 对应SQL"field is not null"的表达式 |
| ExpressionHelper.eqProperty | 用于比较2个属性之间的值,对应SQL中的"field=field"。如 ExpressionHelper.eqProperty ("User.userId","UserInfo.userId"); |
| ExpressionHelper.neProperty | 用于比较2个属性之间的值,对应SQL中的"field<>field" |
| ExpressionHelper.ltProperty | 用于比较2个属性之间的值,对应SQL中的"field<field" |
| ExpressionHelper.leProperty | 用于比较2个属性之间的值,对应SQL中的"field<=field" |
| ExpressionHelper.gtProperty | 用于比较2个属性之间的值,对应SQL中的"field>field" |
| ExpressionHelper.geProperty | 用于比较2个属性之间的值,对应SQL中的"field>=field" |
| ExpressionHelper.and | and关系组合 |
| ExpressionHelper.or | or关系组合 |
| ExpressionHelper.not | not 关系 |
| ExpressionHelper.sizeEq | 对集合属性有效,判断集合属性的大小== |
| ExpressionHelper.sizeGt | 对集合属性有效,判断集合属性的大小> |
| ExpressionHelper.sizeLt | 对集合属性有效,判断集合属性的大小< |
| ExpressionHelper.sizeGe | 对集合属性有效,判断集合属性的大小>= |
| ExpressionHelper.sizeLe | 对集合属性有效,判断集合属性的大小<= |
# Projection
IDASCriteria除了可以使用查询条件外,还可以通过设置Projection对SQL的select部分进行操作,如查询某几个字段,使用某些聚合函数等。
//TODO: getConnection;
IDASCriteria criteria = DASManager.createCriteria("com.eos.User");
criteria.setProjection(ProjectionHelper.projectionList()
.add(ProjectionHelper.count("userId", "cnt"))
.add(ProjectionHelper.groupProperty("gender"))
);
IDASSession session = DASManager.createDasSession(conn);
List<DataObject> result = session.query(criteria);
session.close();
//TODO: printResult;
//TODO: closeConnection;
这样的查询结果和执行了以下的SQL的查询结果是一样的:
select count(USERID) cnt,GENDER from EOS_USER group by GENDER
注意
- 如果有多个Projection需要添加到IDASCriteria,必须通过ProjectionList;
- 使用了Projection之后查询出来的DataObject将不再是IDASCriteria指定的类型,如"com.eos.User",而是统一返回"com.primeton.das.datatype.AnyType"类型的DataObject。
| 方法 | 描述 |
|---|---|
| ProjectionHelper. projectionList | 生成一个ProjectionList,可以为其add Projection |
| ProjectionHelper.rowCount | 对应SQL"count( * )"的表达式 |
| ProjectionHelper.count | 对应SQL"count(field)"的表达式 |
| ProjectionHelper.max | 对应SQL"max(field)"的表达式 |
| ProjectionHelper.min | 对应SQL"min(field)"的表达式 |
| ProjectionHelper.avg | 对应SQL"avg(field)"的表达式 |
| ProjectionHelper.sum | 对应SQL"sum(field)"的表达式 |
| ProjectionHelper.property | 对应 SQL"select field"的表达式 |
| ProjectionHelper.groupProperty | 对应 SQL "group by field"的表达式 |
# 其它特性
IDASCriteria除了可以设置查询表达式、Projection之外,还可以通过setFirstResult和setMaxResult方法限制一次查询返回的记录范围:
IDASCriteria criteria = DASManager.createCriteria("com.eos.User");
//限定查询结果,从第50条结果开始的20条记录
criteria.setFirstResult(50);
criteria.setMaxResults(20);
记录排序:
IDASCriteria criteria = DASManager.createCriteria("com.eos.User");
//按照"userId"降序和"userAge"升序排列
criteria.desc("userId");
criteria.asc("userAge");
# CriteriaEntity
# 基本概念
CriteriaEntity是一个用于表示IDASCriteria (opens new window)的数据对象(DataObject),是为了用户可以方便的在页面端表示出一个IDASCriteria语义而专门设计的对象。
# CriteriaEntity静态SDO类型
为了方便编程,EOS提供了CriteriaEntity所对应的静态java代码。 这些静态代码和每个CriteriaEntity Type相对应,并且提供了CriteriaEntity Type中属性的setter/getter方法。
| CriteriaEntity Type | Java Interface Class |
|---|---|
| criteriaType | com.eos.das.entity.criteria.CriteriaType |
| refType | com.eos.das.entity.criteria.RefType |
| selectType | com.eos.das.entity.criteria.SelectType |
| logicType | com.eos.das.entity.criteria.LogicType |
| exprType | com.eos.das.entity.criteria.ExprType |
| orderbyType | com.eos.das.entity.criteria.OrderbyType |
| sortType | com.eos.das.entity.criteria.OrderbyType.SORT |
| likeRuleType | com.eos.das.entity.criteria.ExprType.LIKERULE |
| opType | com.eos.das.entity.criteria.ExprType.OP |
| lockType | com.eos.das.entity.criteria.CriteriaType.LOCK |
注意
这些CriteriaEntity Type所对应的Java Class实际上是实现了commonj.sdo.DataObject接口并对于CriteriaEntity Type中的属性提供了setter/getter方法的Class,因此这些Class不可以脱离EOS环境单独的当成JavaBean使用。
例如:生成一个CriteriaType的对象,并用于查询。
CriteriaType criteriaType = CriteriaType.FACTORY.create();
criteriaType.set_entity("com.test.User");
//而后就可以将这个criteriaType对象传给基础构件库中以CriteriaEntity为查询参数的运算逻辑。
return DatabaseUtil.queryEntitiesByCriteriaEntity("default", criteriaType);
# CriteriaEntity的定义
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="com.primeton.das.criteria" xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="com.primeton.das.criteria">
<xsd:element name="_criteria" type="criteriaType"/>
<xsd:complexType name="criteriaType">
<xsd:sequence>
<xsd:element name="_entity" type="xsd:string"/>
<xsd:element name="_select" type="selectType" minOccurs="0"/>
<xsd:element name="_expr" type="exprType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_and" type="logicType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_or" type="logicType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_not" type="logicType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_order" type="orderType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_orderby" type="orderbyType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_group" type="xsd:string" minOccurs="0"/>
<xsd:element name="_distinct" type="xsd:boolean" minOccurs="0"/>
<xsd:element name="_association" type="xsd:string" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_ref" type="refType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_lock" type="lockType" minOccurs="0" maxOccurs="1"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="refType">
<xsd:sequence>
<xsd:element name="_id" type="xsd:string"/>
<xsd:element name="_entity" type="xsd:string"/>
<xsd:element name="_select" type="selectType" minOccurs="0"/>
<xsd:element name="_expr" type="exprType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_and" type="logicType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_or" type="logicType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_not" type="logicType" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="selectType">
<xsd:sequence>
<xsd:element name="_field" type="xsd:string" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_count" type="xsd:string" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_avg" type="xsd:string" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_sum" type="xsd:string" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_min" type="xsd:string" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_max" type="xsd:string" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="logicType">
<xsd:sequence>
<xsd:element name="_and" type="logicType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_or" type="logicType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_not" type="logicType" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_expr" type="exprType" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="exprType">
<xsd:sequence>
<xsd:any namespace="##other" processContents="skip" minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="_op" type="opType" minOccurs="0"/>
<xsd:element name="_min" type="xsd:string" minOccurs="0"/>
<xsd:element name="_max" type="xsd:string" minOccurs="0"/>
<xsd:element name="_likeRule" type="likeRuleType" minOccurs="0"/>
<xsd:element name="_dateRule" type="xsd:string" minOccurs="0"/>
<xsd:element name="_pattern" type="xsd:string" minOccurs="0"/>
<xsd:element name="_year" type="xsd:string" minOccurs="0"/>
<xsd:element name="_quarter" type="xsd:string" minOccurs="0"/>
<xsd:element name="_month" type="xsd:string" minOccurs="0"/>
<xsd:element name="_opProperty" type="opType" minOccurs="0"/>
<xsd:element name="_ref" type="xsd:string" minOccurs="0"/>
<xsd:element name="_processNullValue" type="xsd:string" minOccurs="0"/>
<xsd:element name="_property" type="xsd:string" minOccurs="0"/>
<xsd:element name="_value" type="xsd:string" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="orderType">
<xsd:choice>
<xsd:element name="_asc" type="xsd:string"/>
<xsd:element name="_desc" type="xsd:string"/>
</xsd:choice>
</xsd:complexType>
<xsd:complexType name="orderbyType">
<xsd:sequence>
<xsd:element name="_property" type="xsd:string"/>
<xsd:element name="_sort" type="sortType"/>
</xsd:sequence>
</xsd:complexType>
<xsd:simpleType name="likeRuleType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="start"/>
<xsd:enumeration value="end"/>
<xsd:enumeration value="all"/>
<xsd:enumeration value="none"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="opType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="like"/>
<xsd:enumeration value="="/>
<xsd:enumeration value="<>"/>
<xsd:enumeration value=">"/>
<xsd:enumeration value="<"/>
<xsd:enumeration value=">="/>
<xsd:enumeration value="<="/>
<xsd:enumeration value="null"/>
<xsd:enumeration value="notnull"/>
<xsd:enumeration value="between"/>
<xsd:enumeration value="in"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="sortType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="desc"/>
<xsd:enumeration value="asc"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="lockType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="NONE"/>
<xsd:enumeration value="UPGRADE"/>
<xsd:enumeration value="UPGRADE_NOWAIT"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:schema>
# criteriaType
criteriaType就是CriteriaEntity对象的Type。
下表中:
- {1,1}表示最少出现1次,最多出现1次
- *表示0到多次
- ?表示0到1次
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
|---|---|---|
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
| _entity{1,1} | String | 指明该Criteria是对哪个实体进行查询。 |
| _select? | selectType | 指明要查询哪些字段(相当于IDASCriteria中的Projection),如果没有设置该属性,相当于查询指定实体的所有字段。可选值: |
| _expr * | exprType | 相当于IDASCriteria的查询表达式。 |
| _and * | logicType | 用于组合_expr、_and、_or、_not成为一个复杂的查询表达式。 |
| _or* | logicType | 用于组合_expr、_and、_or、_not成为一个复杂的查询表达式。 |
| _not* | logicType | 用于组合_expr、_and、_or、_not成为一个复杂的查询表达式。 |
| _order* | orderType | 指定用于排序的属性以及排序方式。说明该属性已经废弃。 |
| _orderby* | orderbyType | 指定用于排序的属性以及排序方式,提供比order更加合适的表现形式。 _orderby的优先级比_order高,即会先处理通过_orderby定义的排序条件。 |
| _group? | String | 指定按一个属性做group。 |
| _distinct? | Boolean | 是否是distinct查询。 |
| _association* | String | 是否要join查询关联属性的对象。 |
| _ref* | refType | 子查询定义。 |
| _lock? | lockType | 查询时加锁。 |
说明
在本部分所有的例子中,为了便于理解,会使用xml的格式表示CriteriaEntity的数据内容。该xml只是用于表示数据,不可以直接用于运行。
如果想使用CriteriaEntity的功能,可以在页面上提交符合criteriaType定义的key/value对。 JSP代码如下:
<form action="com.primeton.eos.test2.flow" method="post">
<input name="var01/_entity" value="com.eos.User">
<input name="var01/_expr[1]/gender" value="male">
<input name="var01/_expr[2]/age" value="20,21,22,23">
<input name="var01/_expr[2]/_op" value="in">
<input type="submit"value="Submit">
</form>
页面流com.primeton.eos.test2.flow里定义var01变量类型是com.primeton.das.criteria.criteriaType,等页面提交的数据经过server解析后就会生成类似于下面的xml。
<_criteria xmlns="com.primeton.das.criteria">
<_entity>com.eos.User</_entity>
<_expr>
<gender>male</gender>
</_expr>
<_expr>
<age>20,21,22,23</age>
<_op>in</_op>
</_expr>
</_criteria>
通过对该CriteriaEntity的查询会产生:
select * from EOS_USER where GENDER='male' and AGE in (20,21,22,23)
注意
- 在一个_expr中如果没有定义_op则默认是"="操作;
- 2个_expr之间如果没有指定组合关系,则默认是and关系。
# refType
refType用于表示一个子查询的定义。会在_expr中被引用。
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
|---|---|---|
| _id{1,1} | String | refType在criteriaType的唯一标识,多个refType之间不能重复。 |
| _ entity{1,1} | String | 同criteriaType中的_entity |
| _select? | selectType | 同criteriaType中的_select |
| _expr* | exprType | 同criteriaType中的_expr |
| _and * | logicType | 同criteriaType中的_and |
| _or* | logicType | 同criteriaType中的_or |
| _not* | logicType | 同criteriaType中的_not |
关于refType的用法可以参见子查询示例 (opens new window)。
# selectType
selectType被定义为一个不允许动态增加属性的DataObject,用于指定要查询的属性,以及对属性的一些求和、计数的功能。
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
|---|---|---|
| _field* | String | 要查询的属性名称。 |
| _count* | String | 对某一个属性计数,相当于sql的count(column) |
| _avg* | String | 对某一个属性求平均值,相当于sql的avg(column) |
| _sum* | String | 对某一个属性求和,相当于sql的sum(column) |
| _min* | String | 对某一个属性求最小值,相当于sql的min(column) |
| _max* | String | 对某一个属性求最大值,相当于sql的max(column) |
关于selectType的用法可以参见查询时使用函数示例 (opens new window)。
说明
如果通过CriteriaEntity设置查询条件时,使用了"_field"、"_count"、"_avg"、"_sum"、"min"、"max"属性,并且使用基础构件库的API进行查询,如:queryEntitiesByCriteriaEntity(参见《EOS基础构件库参考》中的"数据库操作类\基本操作类DatabaseUtil\queryEntitiesByCriteriaEntity:根据查询条件实体查询所有记录"),则返回的结果就会是一个"com.primeton.das.datatype.AnyType"类型的DataObject数组。 数组里第一个DataObject里会有指定了函数操作的属性,属性名称为"count+被count的属性名"、"avg+被avg的属性名"......,以此类推。如:"avg_userId"。 如果指定了函数操作的属性对应的数据库列的值全部为null,则该属性对应的属性值也是null,如果使用count函数,则属性值为0。 如:dataObject.get("avg_userId") == null,在流程分支条件判断中采用"NullOrEmpty"方式进行判断。
# logicType
logicType用于表示一个where语句,它被定义成一个嵌套的数据结构,允许and、or、not等逻辑条件的组合。
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
|---|---|---|
| _and* | logicType | 用于表示where中的and |
| _or* | logicType | 用于表示where中的or |
| _not* | logicType | 用于表示where中的not |
| _expr* | exprType | 用于表示where中的一个条件表达式(如:USER_ID='1') |
关于logicType的用法可以参见复杂查询示例 (opens new window)。
# exprType
exprType被定义是一个可以动态增加属性的DataObject。因为需要在表达式里指定要操作的属性名,而属性名是不定的。
说明
从6.0GA版本开始,exprType里新增了2个属性:_property和_value,分别表示对哪个属性进行操作,以及对应的值是什么。
由于sqlserver2000数据库是以1/300秒作为精度,对于datetime和smalldatetime类型它的毫秒值是以.000,.003,007作为约进,
所以对于属性_dateRule规则有所不同 只设置了year为2007:表示查询的是 between 2007-01-01 and 2008-01-01。 设置了year、quarter分别为2007、1:表示查询的是 between 2007-01-01 and 2007-04-01。 设置了year、month分别为2007、1:表示查询的是 between 2007-01-01 and 2007-02-01。
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
|---|---|---|
| _op? | opType | 表达式的操作符。包括:like、=、<>、>、<、>=、<=、null、notnull、between、in。 |
| _min? | String | 只有当_op等于between的时候有用,用于指定between的小值。 |
| _max? | String | 只有当_op等于between的时候有用,用于指定between的大值。 |
| _likeRule? | likeRuleType | 对应于sql的"like"。可选值包括: start 在参数值前面加 %end 在参数值后面加 %all 在参数值前后加 %none 不对参数值加 % |
| _pattern? | String | 当参数值是个Date类型的时候,需要指定转换的格式,支持的格式和java.text.SimpleDateFormat相同。 |
| _dateRule? _year? _quarter? _month? | String | Unknown macro: {span}_dateRule一定要配合_year、_quarter、_month使用,并且在设置了_dateRule的情况下,必须设置_year。 _dateRule的设置值可以是"year"、"year,quarter"或"year,month"。 _quarter的取值范围为1~4。 _month的取值范围为1~12。 举例:只设置了year为2007:表示查询的是 between 2007-01-01 and 2007-12-31。 设置了year、quarter分别为2007、1:表示查询的是 between 2007-01-01 and 2007-03-31。 设置了year、month分别为2007、1:表示查询的是 between 2007-01-01 and 2007-01-31。 |
| _opProperty? | opType | 用于表示属性和属性的比较,前面的_op表示属性和值的比较。 |
| _ref? | String | 表示引用一个在criteriaType中定义的_ref,通过指定refType中的_id实现引用。 |
| _processNullValue? | String | Unknown macro: {span}是否要处理空值,可选值为true、false。 如果为true,则当_expr节点中只指定了属性名,没有指定值时,sql会类似于 " property is null";如果为false则不处理。 |
| _property? | String | 表达式的要操作的属性。 |
| _value? | String | 表达式的要操作的属性值。 |
关于exprType的用法可以参见单表查询示例 (opens new window)。
# orderbyType
orderbyType用于表示一个sql语句中的order by。
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
|---|---|---|
| _property{1,1} | String | 用于排序的属性 |
| _sort? | sortType | 按何种顺序排序(如果为null,默认按升序排序) |
关于orderbyType的用法可以参见单表查询示例 (opens new window)。
# sortType
sortType用于指定排序的顺序。
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
|---|---|---|
| desc? | String | 降序 |
| asc? | String | 升序 |
关于sortType的用法可以参见单表查询示例 (opens new window)。
# likeRuleType
likeRuleType用于当_op="like"时,指明在参数值的哪个位置加%。
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
|---|---|---|
| start? | String | 在参数值前面加 % |
| end? | String | 在参数值后面加 % |
| all? | String | 在参数值前面和后面都加 % |
| none? | String | 不对参数值加 % |
说明
如果_op="like",但又没有指定likeRuleType,默认会按照all处理。
关于likeRuleType的用法可以参见关联表查询示例 (opens new window)。
# opType
opType用于表示一个表达式的操作符(包括:like、=、<>、>、<、>=、<=、null、notnull、between、in),会在_expr中被引用。
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
|---|---|---|
| like? | String | 对应SQL"field like value"的表达式 |
| =? | String | 对应SQL"field = value"的表达式 |
| <>? | String | 对应SQL"field <> value"的表达式 |
| >? | String | 对应SQL"field > value"的表达式 |
| <? | String | 对应SQL"field < value"的表达式 |
| >=? | String | 对应SQL"field >= value"的表达式 |
| <=? | String | 对应SQL"field <= value"的表达式 |
| null? | String | 对应SQL"field is null"的表达式 |
| notnull? | String | 对应SQL"field is not null"的表达式 |
| between? | String | 对应SQL"field between value"的表达式。 |
| in? | String | 对应SQL"field in (value1,value2,...,valueN)"的表达式 |
说明
如果在一个_expr中没有指定_op,则默认为_op="="。
关于opType的用法可以参见单表查询示例 (opens new window)。
# lockType
lockType用于指定查询时加锁。
| 属性(属性后面的符号是表示该属性可以出现的次数) | 属性类型 | 描述 |
|---|---|---|
| NONE? | String | 不加锁 |
| UPGRADE? | String | 生成如"select...for update"的sql语句 |
| UPGRADE_NOWAIT? | String | oracle下生成如"select...for update nowait"的sql语句,其它数据库下等同于UPGRADE |
# CriteriaEntity示例
# 单表查询
<_criteria xmlns="com.primeton.das.criteria">
<_entity>TypeTest</_entity>
<_select>
<_field>dateType</_field>
<_field>doubleType</_field>
<_field>bigdecimalType</_field>
</_select>
<_expr>
<!-- bigdecimalType 是实体TypeTest的一个属性。
这个结点对于_expr来说就是一个动态结点。
-->
<!--=========================================
在GA版本里 可以用
<_property>bigdecimalType</_property>
来代替<bigdecimalType></bigdecimalType>
===========================================-->
<bigdecimalType></bigdecimalType>
<_op>between</_op>
<_min>2344234</_min>
<_max>2344235</_max>
</_expr>
<_expr>
<!--========================================
在GA版本里 可以用
<_property>intType</_property>
<_value>1,2,3,4</_value>
来代替<intType>1,2,3,4</intType>
===========================================-->
<intType>1,2,3,4</intType>
<_op>in</_op>
</_expr>
<_expr>
<dateType>20070320</dateType>
<_pattern>yyyyMMdd</_pattern>
</_expr>
<_expr>
<timestampType></timestampType>
<_dateRule>year,month</_dateRule>
<_year>2007</_year>
<_month>3</_month>
</_expr>
<_orderby>
<_property>typeId</_property>
<_sort>asc</_sort>
</_orderby>
<_order>
<_desc>timestampType</_desc>
</_order>
<_order>
<_asc>dateType</_asc>
</_order>
</_criteria>
上面的示例对应的sql:
select DATETYPE,DOUBLETYPE,BIGDECIMALTYPE from TYPETEST
where
BIGDECIMALTYPE between 2344234 and 2344235
and INTTYPE in (1,2,3,4)
and DATETYPE = to_date('2007-03-20','yyyy-MM-dd')
and TIMESTAMPTYPE between to_date('2007-03-01','yyyy-MM-dd') and to_date('2007-03-31','yyyy-MM-dd')
order by TYPEID asc,TIMESTAMPTYPE desc, DATETYPE asc
如果需要通过页面提交数据来组装成这样的CriteriaEntity,页面上需要提交以下格式的数据。 页面提交到的页面流action连线上必须有定义类型为"com.primeton.das.criteria.criteriaType"数据实体的_criteria变量。
<input type="hidden" name="_criteria/_entity" value="TypeTest" >
<input type="hidden" name="_criteria/_select/_field[1]" value="dateType" >
<input type="hidden" name="_criteria/_select/_field[2]" value="doubleType" />
<input type="hidden" name="_criteria/_select/_field[3]" value="bigdecimalType" >
<input type="hidden" name="_criteria/_expr[1]/bigdecimalType" value="" >
<input type="hidden" name="_criteria/_expr[1]/_op" value="between" >
<input type="hidden" name="_criteria/_expr[1]/_min" value="2344234" >
<input type="hidden" name="_criteria/_expr[1]/_max" value="2344235" >
<input type="hidden" name="_criteria/_expr[2]/intType" value="1,2,3,4" >
<input type="hidden" name="_criteria/_expr[2]/_op" value="in" >
<input type="hidden" name="_criteria/_expr[3]/dateType" value="20070320" >
<input type="hidden" name="_criteria/_expr[3]/_pattern" value="yyyyMMdd" >
<input type="hidden" name="_criteria/_expr[4]/timestampType" value="" >
<input type="hidden" name="_criteria/_expr[4]/_dateRule" value="year,month" >
<input type="hidden" name="_criteria/_expr[4]/_year" value="2007" >
<input type="hidden" name="_criteria/_expr[4]/_month" value="3" >
<input type="hidden" name="_criteria/_orderby[1]/_property" value="typeId" >
<input type="hidden" name="_criteria/_orderby[1]/_sort" value="asc" >
<input type="hidden" name="_criteria/_order[1]/_desc" value="timestampType" >
<input type="hidden" name="_criteria/_order[2]/_asc" value="dateType" >
说明
按照XPath的规范,对于数组类型的属性,使用[]访问时,下标是从1开始;但是这些数据在内存中使用数组或List存放时,下标还是从0开始。
以上通过页面提交的数据,也可以通过以下java代码完成:
DataObject criteriaType = DataFactory.INSTANCE.create
("com.primeton.das.criteria","criteriaType");
criteriaType.set("_entity","TypeTest");
criteriaType.set("_select/_field[1]","dateType");
criteriaType.set("_select/_field[2]","doubleType");
criteriaType.set("_select/_field[3]","bigdecimalType");
criteriaType.set("_expr[1]/bigdecimalType","");
criteriaType.set("_expr[1]/_op","between");
criteriaType.set("_expr[1]/_min","2344234");
criteriaType.set("_expr[1]/_max","2344235");
criteriaType.set("_expr[2]/intType","1,2,3,4");
criteriaType.set("_expr[2]/_op","in");
criteriaType.set("_expr[3]/dateType","20070320");
criteriaType.set("_expr[3]/_pattern","yyyyMMdd");
criteriaType.set("_expr[4]/timestampType","");
criteriaType.set("_expr[4]/_dateRule","year,month");
criteriaType.set("_expr[4]/_year","2007");
criteriaType.set("_expr[4]/_month","3");
criteriaType.set("_orderby[1]/_property","typeId");
criteriaType.set("_orderby[1]/_sort","asc");
criteriaType.set("_order[1]/_desc","timestampType");
criteriaType.set("_order[1]/_asc","dateType");
//然后调用基础构件库
com.eos.foundation.database.DatabaseUtil.queryEntitiesByCriteriaEntity("default",criteriaType);
//就可以从"default"数据源中查询相应的记录
# 关联表查询
<_criteria xmlns="com.primeton.das.criteria">
<_entity>Address</_entity>
<_expr>
<school.school_name>张公山一小1</school.school_name>
</_expr>
<_expr>
<address_name>张公山</address_name>
<_op>like</_op>
<_likeRule>all</_likeRule>
</_expr>
</_criteria>
上面的示例对应的sql:
select * from ADDRESS
left outer join SCHOOL
on ADDRESS.SCHOOLID = SCHOOL.SCHOOLID
where SCHOOL.SCHOOLNAME = '张公山一小1'
and ADDRESSNAME like '%张公山%'
注意
使用关联表查询时,2个实体之间一定是建立了关联的。
# 复杂查询
<_criteria xmlns="com.primeton.das.criteria">
<_entity>School</_entity>
<_select>
<_field>addresses.address_name</_field>
<_field>addresses.address_id</_field>
</_select>
<_expr>
<school_name>张公山一小</school_name>
<_op>like</_op>
<_likeRule>all</_likeRule>
</_expr>
<_expr>
<addresses.address_name>张公山</addresses.address_name>
<_op>like</_op>
<_likeRule>all</_likeRule>
</_expr>
<_and>
<_or>
<_expr>
<school_name>张公山一小1</school_name>
</_expr>
<_expr>
<school_name>张公山一小2</school_name>
</_expr>
<_expr>
<school_name>张公山一小3</school_name>
</_expr>
</_or>
<_expr>
<addresses.address_name>张公山一小1</addresses.address_name>
<_op>like</_op>
<_likeRule>end</_likeRule>
</_expr>
</_and>
</_criteria>
上面的示例对应的sql:
select ADDRESS.ADDRESSNAME, ADDRESS.ADDRESSID from SCHOOL left outer
join ADDRESS on SCHOOL.SCHOOLID = ADDRESS.SCHOOLID
where (((SCHOOLNAME='张公山一小1' or SCHOOLNAME='张公山一小2') or SCHOOLNAME='张公山一小3')
and ADDRESS.ADDRESSNAME like '张公山一小1%')
and SCHOOLNAME like '%张公山一小%'
and ADDRESS.ADDRESSNAME like '%张公山%'
注意
生成的where条件表达式的顺序和用户定义的不同。因为在把CriteriaEntity转换成IDASCriteria时,由于DataObject实现的原因无法按照用户定义的查询表达式的顺序进行解析,而是按照在同一级的查询表达式中_and、_or、_not、_expr的顺序来进行解析的。
# 子查询
<_criteria xmlns="com.primeton.das.criteria">
<_entity>City</_entity>
<_expr>
<cityId></cityId>
<_op>in</_op>
<_ref>1</_ref>
</_expr>
<_ref>
<_id>1</_id>
<_entity>Phone</_entity>
<_select>
<_field>phoneId</_field>
</_select>
</_ref>
</_criteria>
cityId的_expr通过_ref 一个 _ref/_id = '1' 达到子查询的功能。
上面的示例对应的sql:
select * from CITY where CITYID in (select PHONEID from PHONE)
注意
- 使用子查询时,2个实体之间可以没有关联;
- <_ref>里定义的子查询只能针对单表操作,不可以使用关联查询。
# 查询时使用函数
<_criteria xmlns="com.primeton.das.criteria">
<_entity>TypeTest</_entity>
<_select>
<_max>intType</_max>
<_max>doubleType</_max>
<_sum>floatType</_sum>
</_select>
</_criteria>
上面的示例对应的sql:
select max(INTTYPE), max(DOUBLETYPE), sum(FLOATTYPE) from TYPETEST
说明
如果通过基础构件库对此CriteriaEntity进行查询,则返回的结果是一个"com.primeton.das.datatype.AnyType"类型的DataObject数组。 数组里的每个DataObject里会有"max_intType"、"max_doubleType"、"sum_floatType"属性。属性值就是对应的数据库查询结果。
# Template
为了方便用户查询,提出了template概念。
如果已经定义了一个持久化或查询实体com.eos.EntityA,当把EntityA作为查询条件使用时,就可以认为EntityA是一个Template。 对于EntityA里的已经设置了值的属性都会当作查询条件,设置了值的属性就会生成field = 'value'的sql条件(如果设置的值为null,则该属性不会生成sql条件),多个已经设置了值的属性则会使用and进行连接。
DataObject template = DataFactory.INSTANCE.
.create("com.eos","OrderLine");
template.set("count",5);
Date date = new DateFormat("yyyy-MM-dd").parse("2007-01-01");
template.set("order/orderDate", date);
IDASCriteria criteria = DASManager.template2DASCriteria(template,session);
session.query(criteria);
上面的示例对应的sql:
select * from ORDERLINE
left outer join ORDER on ORDERLINE.ORDERID = ORDER.ORDERID
where COUNT = 5 and ORDER.ORDERDATE= date
注意
- Template支持用本实体内的简单属性作为查询条件;
- Template支持用1:1、N:1关联对象的简单属性作为查询条件;
- Template不支持用1:N关联对象的简单属性作为查询条件。
实体定义如下:

# 子查询
除了可以使用CriteriaEntity来使用子查询的功能外,还可以直接使用API的方式使用子查询。
IDASSession session = DASManager.createDasSession(connection);
IDASCriteria orderCriteria =
DASManager.createCriteria("com.eos.Order");
IDASCriteria orderLineCriteria =
DASManager.createCriteria("com.eos.OrderLine");
orderLineCriteria.setProjection(
ProjectionHelper.property("order.orderId"));
Criterion subQuery = SubqueryHelper
.propertyIn("orderId", orderLineCriteria, session);
List<DataObject> orders = session.query(orderCriteria.add(subQuery));
创建了一个对于Order查询的orderCriteria;
创建了一个对于OrderLine查询的orderLineCriteria;
指定对于orderLineCriteria要查询的属性order.orderId;
注意
这里虽然写的是order.orderId,但做的还是单表查询,具体原因参见相关API中的"关联对象的属性做为查询条件 (opens new window)"。
创建一个子查询subQuery,创建时写的"orderId"是指Order实体里的orderId;
把subQuery添加到orderCriteria,查询orderCriteria。
实体定义请参见Template (opens new window)。
上面的示例对应的sql:
select * from ORDER where ORDERID in (select ORDERID from ORDERLINE)
注意
- 数据服务支持的子查询只能用于where语句部分;
- 子查询只支持单表。
子查询方法如下:
| 方法 | 描述 |
|---|---|
| SubqueryHelper.propertyIn | 对应SQL"filed in (subquery)"的表达式 |
| SubqueryHelper.propertyEq | 对应SQL"filed = (subquery)"的表达式 |
| SubqueryHelper.propertyNe | 对应SQL"filed <> (subquery)"的表达式 |
| SubqueryHelper.propertyGt | 对应SQL"filed > (subquery)"的表达式 |
| SubqueryHelper.propertyLt | 对应SQL"filed < (subquery)"的表达式 |
| SubqueryHelper.propertyGe | 对应SQL"filed >= (subquery)"的表达式 |
| SubqueryHelper.propertyLe | 对应SQL"filed <= (subquery)"的表达式 |
| SubqueryHelper.in | 对应SQL"固定值 in (subquery)"的表达式 |
| SubqueryHelper.eq | 对应SQL"固定值 = (subquery)"的表达式 |
| SubqueryHelper. ne | 对应SQL"固定值 <> (subquery)"的表达式 |
| SubqueryHelper.ht | 对应SQL"固定值 > (subquery)"的表达式 |
| SubqueryHelper.lt | 对应SQL"固定值 < (subquery)"的表达式 |
| SubqueryHelper.ge | 对应SQL"固定值 >= (subquery)"的表达式 |
| SubqueryHelper.le | 对应SQL"固定值 <= (subquery)"的表达式 |
# 批量处理
为了提高效率,数据服务提供了批处理API用于一次性insert/update/delete多个实体。
IDASSession session = DASManager.createDasSession(connection);
List<DataObject> orderLines = new ArrayList<DataObject>();
for(int i=0;i<10;i++){
DataObject orderLine =
DataFactory.INSTANCE.create("com.eos","OrderLine");
orderLine.set("orderLineId",String.valueOf(i));
orderLine.set("count",i);
orderLines.add(orderLine);
}
//批量新增的接口
session.insertEntityBatch(orderLines);
实体定义请参见Template (opens new window)。
说明
- 批处理会按照一个固定值来分批提交数据给数据库,该固定值不是要新增实体的个数(如上例中的orderLines),而是在sys-config.xml中的/module[@name='Das']/group[@name=' Hibernate']/ configValue[@name='BatchSize']来指定的。 该配置项对于批量的增/改/删都有效。
- 执行批量更新/删除实体时,传入的实体一定要设置好id。
- IDASSession接口中,所有以Batch结尾的方法都是批量处理数据的。
# 按条件更新删除实体
为了提高效率,数据服务提供了按照一定条件更新/删除实体的方法,类似于SQL中的"update ... where ..."。
IDASSession session = DASManager.createDasSession(connection);
DataObject orderLine =
DataFactory.INSTANCE.create("com.eos"," OrderLine");
orderLine.set("count",5);
IDASCriteria criteria = DASManager.createCriteria("com.eos.OrderLine");
session.update(orderLine,criteria);
上面的代码作用是把ORDERLINE里的COUNT列都更新为5。
# LOB字段的处理
对于BLOB、CLOB类型的字段,数据服务提供了4种类型用于映射。
| 类型 | 描述 |
|---|---|
| 类型 | 描述 |
| com.primeton.das.entity.impl.lob.type.BlobFileType | 使用这种类型的映射表示BLOB字段所对应的属性是个String类型的属性,该属性的值表示的是文件的绝对路径。 数据服务会根据这个路径读取文件里的内容并写入数据库BLOB列。 当从数据库读取这一列时,也会先生成一个临时文件(该临时文件的目录是通过sys-config.xml配置的),并把文件的绝对路径写入对应的属性。如果BLOB列的值为null,那么就会把null写入对应的属性。 |
| com.primeton.das.entity.impl.lob.type.BlobByteArrayType | 使用这种类型的映射表示BLOB字段所对应的属性是个byte[]属性,数据服务会把该属性的值保存进数据库BLOB列。 当读时,也会把数据库里的BLOB列变成byte[]写入对应的属性。 |
| com.primeton.das.entity.impl.lob.type.ClobFileType | 使用这种类型的映射表示CLOB字段所对应的属性是个String类型的属性,该属性的值表示的是文件的绝对路径。 数据服务会根据这个路径读取文件里的内容并写入数据库CLOB列。 当从数据库读取这一列时,也会先生成一个临时文件,并把文件的绝对路径写入对应的属性。如果CLOB列的值为null,那么就会把null写入对应的属性。 |
| com.primeton.das.entity.impl.lob.type.ClobStringType | 使用这种类型的映射表示CLOB字段所对应的属性是个String属性,数据服务会把该属性的值保存进数据库CLOB列。 当读时,也会把数据库里的CLOB列变成String写入对应的属性。 |
同时,对于LOB类型的列,还提供了延迟加载。因为读取LOB类型的列很消耗资源,影响性能,所以推荐使用延迟加载。 使用延迟加载的情况下,当对这个实体做查询时,将不会查询LOB列,需要时可以通过session.expandLobProperty(DataObject,lobProperty)来查询这个LOB列。
实体定义如下:

IDASCriteria criteria = DASManager.createCriteria("com.eos.User");
//增加一个查询条件 User.userId = '0001'
criteria.add(ExpressionHelper.eq("userId","0001"));
//查询出一个User对象,
DataObject user = session.queryEntity(criteria);
session.expandLobProperty(user, "photo");
注意
对于Informix数据库的BLOB、CLOB对象,Informix存放在SBSPACE表空间(智能化表空间)中。如果没有建立SBSPACE表空间,或缺省没有时,存储可能出错。 所以使用Informix LOB类型时,需要检查Informix数据库本身的SBSPACE表空间是否已经创建。
# 实体类型映射关系
数据类型:是指在studio中的数据集编辑器中,创建实体属性时可以看到的下拉框中类型。
| 数据类型 | SDO类型 | DAS类型 | JAVA 类型 |
|---|---|---|---|
| Byte | Byte | byte | byte |
| Short | Short | short | short |
| Float | Float | float | float |
| Int | Int | int | int |
| BigInteger | Integer | big_integer | java.math.BigInteger |
| Double | Double | double | double |
| Long | Long | long | long |
| Decimal | Decimal | big_decimal | java.math.BigDecimal |
| Boolean | Boolean | boolean | boolean |
| String | String | string | java.lang.String |
| Date | Date | date | java.util.Date |
| Time | Time | timeString | java.lang.String |
| TimeStamp | Date | timestamp | java.util.Date |
| ClobString | String | com.primeton.das.entity.impl.lob.type.ClobStringType | java.lang.String |
| BlobByteArray | Bytes | com.primeton.das.entity.impl.lob.type.BlobByteArrayType | byte[] |
| ClobFile | String | com.primeton.das.entity.impl.lob.type.ClobFileType | java.lang.String |
| BlobFile | String | com.primeton.das.entity.impl.lob.type.BlobFileType | java.lang.String |
# 命名SQL
命名SQL就是给每个sql语句定义一个唯一标识(id)、配置sql语句执行所需参数以及如何处理sql语句执行后的结果。 通过命名SQL可以达到集中管理sql语句的作用,因为所有sql语句都是定义在文件中而不是散落在代码里。在调用时,只需传入唯一标识(id)和参数即可。
注意
id的值中不允许包含"."。
命名SQL的基本元素包括:
- <parameterMap>:parameterMap负责将对象属性映射成statement的参数;
- <resultMap>:resultMap负责将结果集的列值映射成对象的属性值;
- <statement>(Mapped Statement):该元素是个通用声明,可以用于任何类型的sql语句,但具体的statement类型(即<insert>、<update>、<delete>、<select>、<procedure>)提供了更直观的XML DTD,因此强烈推荐使用。
下表总结了statement类型及其属性:
| Statement类型 | 属性 |
|---|---|
| statement | id、parameterClass、resultClass、parameterMap、resultMap |
| insert | id、parameterClass、parameterMap |
| update | id、parameterClass、parameterMap |
| delete | id、parameterClass、parameterMap |
| select | id、parameterClass、resultClass、parameterMap、resultMap |
| procedure | id、parameterClass、resultClass、parameterMap、resultMap |
说明
关于上述 元素及其属性 的更多描述,请参见下面的内容。
# Mapped Statement
命名SQL的核心概念是Mapped Statement。Mapped Statement可以使用任意的SQL语句,并支持parameterMap(输入)和resultMap(输出)。 如果只是简单情况,Mapped Statement可以使用Java类来作为parameter和result。 Mapped Statement的结构如下:
<statement id="statementName"
[parameterClass="some.class.Name"]
[resultClass="some.class.Name"]
[parameterMap="nameOfParameterMap"]
[resultMap="nameOfResultMap"]
>
select * from PRODUCT where PRD_ID = [?|#propertyName#]
order by [$simpleDynamic$]
</statement>
在上面的表达式中,括号[]里的属性是可选的属性。因此下面这个简单的例子也是正确的:
<statement id="insertTestProduct" >
insert into PRODUCT (PRD_ID, PRD_DESCRIPTION) values (1, "Shih Tzu")
</statement>
上面的例子仅在需要用命名SQL来执行任意sql语句时才有作用。 常见的用法还是通过ParameterMap和ResultMap,来实现DataObject映射的特性,这是命名SQL的价值所在。
<statement>元素是个通用声明,可以用于任何类型的SQL语句,但具体的statement类型(即<insert>、<update>、<delete>、<select>、<procedure>)提供了更直观的XML DTD,并拥有某些<statement>元素所没有的特性,因此强烈推荐使用。
下表总结了statement类型及其属性:
| Statement类型 | 属性 |
|---|---|
| statement | id、parameterClass、resultClass、parameterMap、resultMap |
| insert | id、parameterClass、parameterMap |
| update | id、parameterClass、parameterMap |
| delete | id、parameterClass、parameterMap |
| select | id、parameterClass、resultClass、parameterMap、resultMap |
| procedure | id、parameterClass、resultClass、parameterMap、resultMap |
SQL显然是Mapped Statement中最重要的部分,可以使用对于数据库和JDBC Driver合法的任意SQL语句。只要JDBC Driver支持,可以使用任意的函数,甚至是多条语句。因为SQL语句是嵌在XML文档中的,因此有些特殊的字符不能直接使用,例如大于号和小于号(<>)。 幸运的是,解决的办法很简单,只需将包含特殊字符的SQL语句放在XML的CDATA区中即可。例如:
<statement id="getPersonsByAge" parameterClass="int" resultClass="commonj.sdo.DataObject">
<![CDATA[SELECT * FROM PERSON WHERE AGE > #value# ]]>
</statement>
# 存储过程
命名SQL通过<procedure>元素支持存储过程。下面的例子说明如何使用具有输出参数的存储过程。
<parameterMap id="swapParameters" class="map">
<parameter property="email1" jdbcType="VARCHAR" javaType="java.lang.String" mode="INOUT"/>
<parameter property="email2" jdbcType="VARCHAR" javaType="java.lang.String" mode="INOUT"/>
</parameterMap>
<procedure id="swapEmailAddresses" parameterMap="swapParameters">
{call swap_email_address (?, ?)}
</procedure>
调用上面的存储过程将同时互换两个字段(数据库表)和参数对象(Map)中的两个email 地址。如果参数的mode属性设为INOUT或OUT,则参数对象的值被修改,否则保持不变。
注意
要确保始终只使用标准的JDBC存储过程语法,详情请参考JDBC的CallableStatement文档。
# Mapped Statement的属性
# parameterClass
属性parameterClass的值是Java类的全限定名(即包括类的包名)。parameterClass属性虽然是可选的,但强烈建议使用,它的目的是限制输入参数的类型为指定的Java类,并优化框架的性能。如果您使用parameterMap,则没有必要使用parameterClass属性。 例如,如果想只允许Java类"commonj.sdo.DataObject"来作为输入参数,可以参考如下:
<statement id="statementName" parameterClass="commonj.sdo.DataObject">
<![CDATA[insert into PRODUCT values (#id#, #description#, #price#)]]>
</statement>
执行该命名SQL时,会使用传入的DataObject对象中属性为id、description、price的值来作为sql执行时的参数值。
# parameterMap
属性parameterMap的值等于一个预先定义的<parameterMap>元素的id。parameterMap属性很少使用,更多的是使用上面的parameterClass属性和inline parameter。
说明
inline parameter不是Mapped Statement的属性,是一个概念,请参考Inline Parameter Map (opens new window)中的介绍。
parameterMap的基本思想是定义一系列有次序的参数系列,用于匹配JDBC PreparedStatement的值符号。例如:
<parameterMap id="insert-product-param" class="commonj.sdo.DataObject">
<parameter property="id"/>
<parameter property="description"/>
</parameterMap>
<statement id="insertProduct" parameterMap="insert-product-param">
<![CDATA[insert into PRODUCT (PRD_ID, PRD_DESCRIPTION) values (?,?)]]>
</statement>
注意
对于使用了parameterMap作为参数的statement,写sql语句时 只能用占位符'?'。
上面的例子中,parameterMap中的两个参数按次序匹配SQL语句中的值符号(?)。因此,第一个"?"号将被"id"属性值替换,而第二个"?"号将被"description"属性值替换。 (opens new window)及其选项将在后面详细讨论。
注意
动态Mapped Statement只支持inline parameter,不支持parameterMap。
# resultClass
resultClass属性的值是Java类的全限定名(即包括类的包名)。resultClass属性可以让您指定一个Java类,根据ResultSetMetaData将其自动映射到JDBC的ResultSet。只要是属性名称和ResultSet的列名匹配,属性自动赋值给列值。这使得查询Mapped Statement变得简短。例如:
<statement id="getPerson" parameterClass="int" resultClass="commonj.sdo.DataObject">
SELECT PER_ID as id,
PER_FIRST_NAME as firstName,
PER_LAST_NAME as lastName,
PER_BIRTH_DATE as birthDate,
PER_WEIGHT_KG as weightInKilograms,
PER_HEIGHT_M as heightInMeters
FROM PERSON
WHERE PER_ID = #value#
</statement>
在上面的例子中,会返回一个Type是"com.primeton.das.datatype.AnyType"(系统默认)的DataObject。拥有的属性包括:id、firstName、lastName、birthDate、weightInKilograms和heightInMeters。每一个属性对应SQL查询语句一个列的别名(使用"as"关键字-标准的SQL语法)。一般情况下,列名和属性名称不匹配,就需要使用"as"关键字。当执行Mapped Statement时就会创建一个DataObject,从结果集中得到的列值将根据属性名和列名映射成DataObject对象的属性值。
使用resultClass的自动映射存在一些限制,无法指定输出字段的数据类型(如果需要的话),无法自动装入相关的数据(复杂属性),并且因为需要ResultSetMetaData的信息,会对性能有轻微的不利影响。但使用resultMap,这些限制都可以很容易解决。
# resultMap
属性resultMap是最常用和最重要的属性。resultMap属性的值等于预先定义的<resultMap>元素的name属性值(参照下面的例子)。使用resultMap可以控制数据如何从结果集中取出,以及哪一个属性匹配哪一个字段。不像使用resultClass的自动映射方法,resultMap属性可以允许指定字段的数据类型。后面会对resultMap (opens new window)进行详细讨论,这里只给出一个相关statement的resultMap例子。
<resultMap id="get-product-result" class="commonj.sdo.DataObject">
<result property="id" column="PRD_ID"/>
<result property="description" column="PRD_DESCRIPTION"/>
</resultMap>
<statement id="getProduct" resultMap="get-product-result">
select * from PRODUCT
</statement>
上面的例子中,通过resultMap的定义,查询语句得到的ResultSet被映射成DataObject对象。resultMap定义的"id"属性值将赋予"PRO_ID"字段值,而"description"属性值将赋予"PRD_DESCRIPTION"字段值。
说明
- resultMap并不要求对查询出来的所有列都做映射;
- resultMap的class属性如果写commonj.sdo.DataObject,那么生成的DataObject的对象的类型是"com.primeton.das.datatype.AnyType"(系统默认),如果想生成自定义类型的DataObject,class属性就要写成自定义类型的DataObject的全限定名,如"com.primeton.Customer"。
# Parameter Map
parameterMap负责将对象属性映射成statement的参数。
<parameterMap id="parameterMapName" class="commonj.sdo.DataObject">
<parameter property ="propertyName"
[jdbcType="VARCHAR"] [javaType="string"]
[nullValue="NUMERIC"]/>
<parameter ...... />
<parameter ...... />
</parameterMap>
括号[]是可选的属性。一个parameterMap可包含任意多的parameter元素。后面讨论parameter的各个属性 (opens new window)。
# Parameter的属性
# property
属性property是传给statement的参数对象的属性名称。该名称根据需要,可以在statement中多次出现。
# jdbcType
属性jdbcType用于显式地指定给本属性(property)赋值的数据库字段的数据类型。对于某些特定的操作,如果不指定字段的数据类型,某些JDBC Driver无法识别字段的数据类型。一个很好的例子是PreparedStatement.setNull(int parameterIndex, int sqlType)方法,要求指定数据类型。如果不指定数据类型,某些Driver可能指定为Types.Other或Types.Null。但是,不能保证所有的Driver都表现一致。对于这种情况,需要使用该属性来指定数据库字段的类型。
说明
当字段可以为NULL时最好设置jdbcType属性,否则某些Jdbc Driver会抛出异常,如db2的jcc驱动。
另一需要指定jdbcType属性的情况是字段类型为日期时间类型的情况。因为Java只有一个Date类型(java.util.Date),而大多数SQL数据库有多个(通常至少有3种)。因此,需要指定字段类型是DATE还是DATETIME。 属性jdbcType可以是java.sql.Types类中定义的任意参数的字符串值。虽然如此,还是有某些类型不支持(即BLOB)。Parameter Map和Result Map支持的数据类型 (opens new window)说明命名SQL支持的数据类型。
# javaType
属性javaType用于显式地指定被赋值参数的类型。如果没有提供类型将被假定为Object类型。
# nullValue
属性nullValue的值可以是对于property类型来说任意的合法值,用于指定NULL的替换值。即当属性值等于指定值时,相应的字段将赋值NULL。这个特性允许在应用中给不支持null的数据类型(即int、double、float等)赋值null。
# 示例
<parameterMap id="insert-product-param" class="commonj.sdo.DataObject">
<parameter property="id" jdbcType="NUMERIC" javaType="int" nullValue="-9999999"/>
<parameter property="description" jdbcType="VARCHAR" nullValue="NO_ENTRY"/>
</parameterMap>
<insert id="insertProduct" parameterMap="insert-product-param">
insert into PRODUCT (PRD_ID, PRD_DESCRIPTION) values (?,?)
</insert>
当id的属性值=-9999999的时候,会给PRD_ID设个null值。
# Inline Parameter Map
parameterMap的语法虽然简单,但很繁琐。还有一种更受欢迎更灵活的方法,可以大大简化定义和减少代码量。这种方法把属性名称嵌在Mapped Statement的定义中(即直接写在SQL语句中)。缺省情况下,任何没有指定parameterMap的Mapped Statement都会被解析成inline parameter(内嵌参数)。用前面的例子来说,即:
<statement id="insertProduct" parameterClass="commonj.sdo.DataObject">
insert into PRODUCT (PRD_ID, PRD_DESCRIPTION) values (#id#, #description#);
</statement>
这样就会从传入的DataObject查找属性名为id和description的2个属性值,赋值到相应的数据库字段。 在内嵌参数中指定数据类型可以用下面的语法:
<statement id="insertProduct" parameterClass="commonj.sdo.DataObject">
insert into PRODUCT (PRD_ID, PRD_DESCRIPTION) values (#id:NUMERIC#, #description:VARCHAR#);
</statement>
如果有null值处理,可以参考下面的语句:
<insert id="insertProduct" parameterClass="com.domain.Product">
insert into PRODUCT (PRD_ID, PRD_DESCRIPTION) values (#id:NUMERIC:-999999#, #description:VARCHAR:NO_ENTRY#)
</insert>
说明
- Inline Parameter Map有2种语法,一种是简单的以":"分割,这种语法只包括3种格式:
- #propertyName#
- #propertyName:jdbcType#
- #propertyName:jdbcType:nullValue#
- 第2种语法是以","分割,语法如下:#propertyName,javaType=?,jdbcType=?,mode=?,nullValue=?#。
注意
上面的例子中,所有的参数都用##包起来,这样生成的是PreparedStatement;还可以使用$$把参数包起来,这样生成的是Statement,即在执行sql时会先把参数放入到sql中,这在like或in条件时会有用。例如:
<select id="selectProduct" parameterClass="commonj.sdo.DataObject">
select * from PRODUCT where PRD_DESCRIPTION like '%$description$%'
</select>
<select id="selectProduct" parameterClass="commonj.sdo.DataObject">
select * from PRODUCT where PRD_ID in ($prdIdList$)
</select>
# 基本类型输入参数
假如没必要写一个Java Bean作为参数,可以直接使用基本类型的包装类(String、Integer、Date等)作为参数。例如:
<statement id="insertProduct" parameterClass="java.lang.Integer">
select * from PRODUCT where PRD_ID = #value#
</statement>
假设PRD_ID的数据类型是NUMERIC,要调用上面的Mapped Statement,可以传入一个java.lang.Integer对象作为参数。Integer对象的值将代替#value#参数。当使用基本类型包装类代替对象时,切记要使用#value#作为参数。
为了使定义更简洁,基本类型可以使用别名。例如,可以用"int"来代替"java.lang.Integer"。这些别名参见Parameter Map和Result Map支持的数据类型 (opens new window)。
# Map类型输入参数
假如没必要写一个SDO对象作为参数,而要传入的参数又不止一个时,可以使用Map类(如HashMap、TreeMap等)作为参数对象。例如:
<statement id="insertProduct" parameterClass="java.util.Map">
select * from PRODUCT where PRD_CAT_ID = #catId# and PRD_CODE = #code#
</statement>
注意
Mapped Statement的形式完全没有区别!上面的例子中,如果把Map对象作为输入参数去调用Mapped Statement,Map对象必须包含键值"catId"和"code"。键值引用的对象必须是合适的类型,以上面的例子来说,必须是Integer和String。
# Result Map
在命名SQL框架中,Result Map是极其重要的组件。在执行查询Mapped Statement时,resultMap负责将结果集的列值映射成对象的属性值。resultMap的结构如下:
<resultMap id="resultMapName" class="commonj.sdo.DataObject" >
<result property="propertyName" column="COLUMN_NAME" [columnIndex="1"]
[javaType="int"] [jdbcType="NUMERIC"] [nullValue="-999999"] />
<result .../>
<result .../>
</resultMap>
括号[]中是可选的属性。resultMap的id属性是唯一标识。ResultMap的class属性用于指定DataObject的类型名称(包括URI)。resultMap可以包括任意数量的属性映射,将查询结果集的列值映射成DataObject的属性。属性的映射按它们在resultMap中定义的顺序进行。
# Result Map的属性
# property
属性property的值是Mapped Statement返回结果对象的属性的名称。
# column
属性column的值是ResultSet中字段的名称,该字段赋值给names属性指定的Java Bean属性。同一字段可以多次使用。
注意
可能某些JDBC Driver(例如:JDBC/ODBC桥)不允许多次读取同一字段。
# columnIndex
属性columnIndex是可选的,用于改善性能。属性columnIndex的值是ResultSet中用于赋值DataObject属性的字段次序号。在99%的应用中,不太可能需要牺牲可读性来换取性能。
# jdbcType
属性jdbcType用于指定ResultSet中用于赋值DataObject属性的字段的数据库数据类型。虽然resultMap没有NULL值的问题,指定jdbcType属性对于映射某些类型(例如Date属性)还是有用的。因为Java只有一个Date类型,而SQL数据库可能有几个(通常至少有3个),为保证Date(和其他)类型能正确的赋值,某些情况下指定type还是有必要的。同样地,String类型的赋值可能来自VARCHAR、CHAR和CLOB,因此同样也有必要指定jdbcType属性。
# javaType
属性javaType用于显式地指定被赋值的DataObject属性的类型。如果没有提供类型将被假定为Object。
# nullValue
属性nullValue指定数据库中NULL的替代值。因此,如果从ResultSet中读出NULL值,DataObject属性将被赋值属性null指定为替代值。属性null的值可以指定任意值,但必须对于DataObject属性的类型是合法的。如果数据库中存在NULLABE属性的字段,但用户需要用指定的常量代替NULL,可以这样设置resultMap:
<resultMap id="get-product-result" class="com.eos.Product">
<result property="id" column="PRD_ID"/>
<result property="description" column="PRD_DESCRIPTION"/>
<result property="subCode" column="PRD_SUB_CODE" nullValue="-999"/>
</resultMap>
上面的例子中,如果PRD_SUB_CODE的值是NULL,subCode属性将被赋值-999。这可以让用户在DataObject中用基本类型的属性映射数据库中的NULLABLE字段。
注意
如果用户要在查询和更新中同样使用这个功能,必须同时在parameterMap中指定nullValue属性。
# 基本类型的Result
Result Map还可以给基本类型包装类(如String、Integer、Boolean等)赋值。
注意
要记住一个限制,基本类型只能有一个属性,名字必须用"value"。
例如,如果用户要获得所有产品描述的一个列表而不是整个Product,Result Map如下:
<resultMap id="get-product-result" class="java.lang.String" >
<result property="value" column="PRD_DESCRIPTION"/>
</resultMap>
更简单方法是,在Mapped Statement中使用resultClass属性(使用"as"关键字给字段取别名"value")。
<statement id="getProductCount" resultClass="java.lang.Integer">
select count(1) as value from PRODUCT
</statement>
# Map类型的Result
Result Map也可以方便地为一个Map(如HashMap或TreeMap)对象赋值。Map对象与DataObject同样的方式映射,只是使用name属性值作为Map的键值,用它来索引相应的数据库字段值,而不是像DataObject一样给属性赋值。例如,如果用户要将Product对象的数据装入Map,可以参照下面的语句:
<resultMap id="get-product-result" class="java.util.HashMap">
<result property="id" column="PRD_ID"/>
<result property="code" column="PRD_CODE"/>
<result property="description" column="PRD_DESCRIPTION"/>
<result property="suggestedPrice" column="PRD_SUGGESTED_PRICE"/>
</resultMap>
上面的例子会创建一个HashMap的实例并用Product的数据赋值。Property的name属性值(即"id")作为HashMap的键值,而列值则作为HashMap中相应的值。
# 动态Mapped Statement
直接使用JDBC的一个非常普遍的问题是动态SQL。使用参数值、参数本身和数据列都是动态的SQL,通常非常困难。 典型的解决方法是:使用一系列if-else条件语句和一连串复杂的字符串连接。对于这个问题,SQL Map API使用和Mapped Statement非常相似的结构,提供了较为优雅的方法。下面是一个简单的例子:
<select id="dynamicGetAccountList" resultMap="commonj.sdo.DataObject" >
select * from ACCOUNT
<isGreaterThan prepend="and" property="id" compareValue="0">
where ACC_ID = #id#
</isGreaterThan>
order by ACC_LAST_NAME
</select>
上面的例子中,根据参数"id"属性的不同情况,可创建两个可能的语句。
- 如果参数"id"大于0,将创建下面的语句:
select * from ACCOUNT where ACC_ID = ? order by ACC_LAST_NAME
- 如果"id"参数小于等于0,将创建下面的语句:
select * from ACCOUNT order by ACC_LAST_NAME
在更复杂的例子中,动态Mapped Statement的用处更明显。如下面比较复杂的例子:
<statement id="dynamicGetAccountList" resultMap="account-result" >
select * from ACCOUNT
<dynamic prepend="WHERE">
<isNotNull prepend="AND" property="firstName">
(ACC_FIRST_NAME = #firstName#
<isNotNull prepend="OR" property="lastName">
ACC_LAST_NAME = #lastName#
</isNotNull>
)
</isNotNull>
<isNotNull prepend="AND" property="emailAddress">
ACC_EMAIL like #emailAddress#
</isNotNull>
<isGreaterThan prepend="AND" property="id" compareValue="0">
ACC_ID = #id#
</isGreaterThan>
</dynamic>
order by ACC_LAST_NAME
</statement>
根据不同的条件,上面动态的语句可以产生16条不同的查询语句。使用if-else结构和字符串,会产生上百行很乱的代码。
而使用动态Statement,和在SQL的动态部位周围插入条件标签一样容易。例如:
<statement id="someName" resultMap="account-result" >
select * from ACCOUNT
<dynamic prepend="where">
<isGreaterThan prepend="and" property="id" compareValue="0">
ACC_ID = #id#
</isGreaterThan>
<isNotNull prepend="and" property="lastName">
ACC_LAST_NAME = #lastName#
</isNotNull>
</dynamic>
order by ACC_LAST_NAME
</statement>
上面的例子中,<dynamic>元素划分出SQL语句的动态部分。动态部分可以包含任意多的条件标签元素,条件标签决定是否在语句中包含其中的SQL代码。所有的条件标签元素将根据传给动态查询Statement的参数对象的情况来工作。 <dynamic>元素和条件元素都有"prepend"属性,它是动态SQL代码的一部分,在必要情况下,可以被父元素的"prepend"属性覆盖。上面的例子中,prepend属性"where"将覆盖第一个为"真"的条件元素。这对于确保生成正确的SQL语句是有必要的。例如,在第一个为"真"的条件元素中,"AND"是不需要的,事实上,加上它肯定会出错。
下面讨论不同的条件元素,包括二元条件元素和一元条件元素。
# 二元条件元素
二元条件元素将一个属性值和一个静态值或另一个属性值比较,如果条件为"真",元素体的内容将被包括在查询SQL语句中。
二元条件元素的属性如下:
- prepend:可被覆盖的SQL语句组成部分,添加在语句的前面(可选)
- property:被比较的属性(必选)
- compareProperty:另一个用于和前者比较的属性(必选或选择compareValue)
- compareValue:用于比较的值(必选或选择compareProperty)
| 二元条件元素 | 说明 |
|---|---|
| isEqual | 比较属性值和静态值或另一个属性值是否相等 |
| isNotEqual | 比较属性值和静态值或另一个属性值是否不相等 |
| isGreaterThan | 比较属性值是否大于静态值或另一个属性值 |
| isGreaterEqual | 比较属性值是否大于等于静态值或另一个属性值 |
| isLessThan | 比较属性值是否小于静态值或另一个属性值 |
| isLessEqual | 比较属性值是否小于等于静态值或另一个属性值。 例子: |
# 一元条件元素
一元条件元素检查属性的状态是否符合特定的条件。
一元条件元素的属性如下:
- prepend:可被覆盖的SQL语句组成部分,添加在语句的前面(可选)
- property:被比较的属性(必选)
| 一元条件元素 | 说明 |
|---|---|
| isNull | 检查属性是否为null |
| isNotNull | 检查属性是否不为null |
# Parameter Map和Result Map支持的数据类型
对于Parameter Map和Result Map,命名SQL支持的Java类型如下表所示:
| Java Type | SDO property mapping | ResultClass/ParameterClass | Type Alias | JdbcType |
|---|---|---|---|---|
| boolean | YES | NO | boolean | BIT |
| java.lang.Boolean | YES | YES | boolean | BIT |
| byte | YES | NO | byte | TINYINT |
| java.lang.Byte | YES | YES | byte | TINYINT |
| short | YES | NO | short | SMALLINT |
| java.lang.Short | YES | YES | short | SMALLINT |
| int | YES | NO | int/integer | INTEGER |
| java.lang.Integer | YES | YES | int/integer | INTEGER |
| long | YES | NO | long | BIGINT |
| java.lang.Long | YES | YES | long | BIGINT |
| float | YES | NO | float | FLOAT |
| java.lang.Float | YES | YES | float | FLOAT |
| double | YES | NO | double | DOUBLE |
| java.lang.Double | YES | YES | double | DOUBLE |
| java.lang.String | YES | YES | string | VARCHAR |
| java.util.Date | YES | YES | date | DATE |
| java.math.BigDecimal | YES | YES | decimal | NUMERIC |
| java.sql.Date | YES | YES | N/A | DATE |
| java.sql.Time | YES | YES | N/A | TIME |
| java.sql.Timestamp | YES | YES | N/A | TIMESTAMP |
# 数据服务接口及方法说明
# 包含的类
| 类名 | 描述 |
|---|---|
| com.eos.das.entity.DASManager | IDASCriteria和IDASSession的工厂类以及一些通用方法。 |
| com.eos.das.entity.IDASCriteria | IDASCriteria通过面向对象化的设计,将数据查询条件封装为一个对象。 |
| com.eos.das.entity.IDASSession | IDASSession的主要作用是封装一个数据库连接,所有的实体映射通过该接口访问数据库。 |
| com.eos.das.sql.NamedSqlSessionFactory | INamedSqlSession的工厂类。 |
| com.eos.das.sql.INamedSqlSession | INamedSqlSession的主要作用是封装一个数据库连接,所有的命名SQL通过该接口访问数据库。 |
| com.eos.das.entity.DynamicHBMLoader | DynamicHBMLoader的主要作用加载一个.hbm文件流。 |
# 类的方法
# com.eos.das.entity.DASManager
类的说明 IDASCriteria和IDASSession的工厂类以及一些通用方法。
类的方法
方法 说明 IDASCriteria createCriteria(String entityName) 创建一个与entityName对应实体的IDASCriteria,用于实体查询。 IDASSession createDasSession(Connection conn) 根据Connection创建一个IDASSession,用于数据库操作。 IDASCriteria queryForm2CountDASCriteria(DataObject criteriaEntity, IDASSession session) 把CriteriaEntity转换成一个取count()值的IDASCriteria。 IDASCriteria queryForm2DASCriteria(DataObject criteriaDataObject, IDASSession session) 把CriteriaEntity转换成一个对实体进行查询的IDASCriteria。 IDASCriteria template2DASCriteria(DataObject template, IDASSession session) 把template转换成一个对实体进行查询的IDASCriteria。 DataObject template2QueryForm(DataObject template) 把template转换成CriteriaEntity。
# com.eos.das.entity.IDASCriteria
类的说明 IDASCriteria通过面向对象化的设计,将数据查询条件封装为一个对象。
类的方法
方法 说明 IDASCriteria add(Criterion expression) 增加一个条件表达式。expression是通过ExpressionHelper创建出来的。 IDASCriteria addAssociation(String associationPath); 对于关联属性使用左外联一次性查出。associationPath是关联属性的名称。 IDASCriteria asc(String propertyName) 按指定属性升序排列。 IDASCriteria desc(String propertyName) 按指定属性降序排列。 void setDistinct(boolean isDistinct) 设置查询sql是否加distinct进行查询。 IDASCriteria setFirstResult(int firstResult) 从第几条记录开始取(从0开始计算)。 IDASCriteria setMaxResults(int maxResults) 设置取多少条记录。 IDASCriteria setProjection(Projection projection) 设置Projection(对于Projection的描述见前面的文档)。
# com.eos.das.entity.IDASSession
类的说明 IDASSession的主要作用是封装一个数据库连接,所有的实体映射通过该接口访问数据库。
类的方法
方法 说明 void close() 关闭session int count(IDASCriteria criteria) 根据一个criteria设置的条件来查询满足条件的记录数 int delete(IDASCriteria criteria) 根据一个criteria设置的条件来删除数据 void deleteEntity(DataObject entity) 根据主键删除一个对象,传入的实体里的主键所对应属性必须已被赋值。 void deleteEntityBatch(DataObject[] entities) 批量删除一批实体。实体的主键属性必须被赋值了。 boolean expandEntity(DataObject entity) 扩展一个数据实体对象的所有属性(不包括懒加载为true的关联对象),传入的实体一定要包含主键属性。如果没有找到相应的记录,则返回false。 void expandEntityForUpdate(DataObject entity) 用select ... for update锁住记录行。传入的实体一定要包含主键属性。 void expandLobProperty(DataObject entity,String property) 查询一个实体对象的一个延迟加载的LOB类型列对应的属性,传入的实体一定要包含主键属性。 void expandRelation(DataObject entity,String property) 查询一个数据实体对象的一个延迟加载的关联属性,传入的实体一定要包含主键属性。 void insertEntity(DataObject entity) 新增一个实体到数据库中。 void insertEntityBatch(DataObject[] entities) 批量新增一批实体到数据库中。 void insertEntityBatch(List<DataObject> entities) 批量新增一批实体到数据库中。 List<DataObject> query(IDASCriteria criteria) 根据criteria查询实体。 List<DataObject> query(IDASCriteria criteria,int firstResult,int resultSize) 根据一个criteria设置的条件来查询数据,并且设置了分页条件。firstResult从第几条开始,resultSize取多少条。 DataObject queryEntity(IDASCriteria criteria) 根据criteria取查询出来的重复对象的第一个对象,如果有两个以上的不同对象则报错。 void saveEntities(DataObject[] entities) 新增或者更新一批对象到数据库中。 void saveEntities(List<DataObject> entities) 新增或者更新一批对象到数据库中。 void saveEntity(DataObject entity) 新增或者更新一个对象到数据库中。 int update(DataObject obj,IDASCriteria criteria) 用传入的实体已经设置过值的属性来更新满足criteria条件的记录。 void updateEntity(DataObject entity) 更新数据库中该实体对应的记录。 void updateEntityBatch(DataObject[] entities) 批量更新一批实体。 void updateEntityBatch(List<DataObject> entities) 批量更新一批实体。
# com.eos.das.sql.NamedSqlSessionFactory
类的说明 INamedSqlSession的工厂类。
类的方法
方法 说明 INamedSqlSession createSQLMapSession(Connection conn) 创建一个INamedSqlSession
# com.eos.das.sql.INamedSqlSession
类的说明 INamedSqlSession的主要作用是封装一个数据库连接,所有的命名sql通过该接口访问数据库。
类的方法
方法 说明 close() 关闭session。 Integer execute(String id, Object parameterObject) 执行一个命名sql的语句,除了select语句之外,如果执行的是insert语句或是procedure就返回null,如果是执行update或是delete就返回受影响的行数。 id是命名sql的唯一标识,parameterObject是执行sql需要的参数,如果没有可以传null。 List queryForList(String id, Object parameterObject) 执行一个命名sql的查询语句。 queryForList(String id, Object parameterObject, int startNo, int length) 执行一个命名sql的查询语句,并指定返回记录的开始位置和条数。 int count(String id, Object parameterObject) 查询一个select结果集的条数。注意如果命名sql已经是 select count(*) from ...的语句,请直接调用queryForList,否则会变成select count(*) from (select count(*) from ...)
# com.eos.das.entity.DynamicHBMLoader
类的说明 动态的加载hbm的文件流。
类的方法
方法 说明 InputStream[] listInputStreams() 列出动态加载的InputStream的列表。 String[] listIds() 列出动态加载的InputStream的id列表。 String[] listIds() 列出动态加载的InputStream的id列表。 void add(String id, InputStream inputStream) 新增需要动态加载的InputStream,并给InputStream设定一个id,这个id需要在DynamicHBMLoader中保证唯一。 void delete(String id) 删除一个动态加载的InputStream。
InputStream input = ......;
try{
DynamicHBMLoader.add("1",input);
} finally {
if (input!=null)
input.close();
}