
# 柔性事务
随着微服务架构的流行,很多大型的业务流程被拆分成为了多个功能单一的基础服务,大家会根据业务的述求在这些基础服务之上编写一些组合调用服务以满足业务述求。为了保证微服务能够独立开发部署运行,通常我们会采用一个微服务一个数据库的架构,将内部数据经微服务封装之后,以服务方式对外暴露。这样以往基于数据库来实现的数据操作,就变成了多个对外提供服务的微服务系统的协同完成操作。因为单个微服务只知道自己的服务执行情况,为了保证分布事务的一致性,参与分布式事务的微服务通常会依托协调器完成相关的一致性协调操作,那我们有什么办法即提高系统运行效率,又能保证事务的数据一致性呢?这里的答案是采用补偿的方式来解决这一问题。
本次提供的柔性事务解决方案为Apache ServiceComb Saga,是一个微服务应用的数据最终一致性解决方案
特性
- 高可用。支持集群模式。
- 高可靠。所有的事务事件都持久存储在数据库中。
- 高性能。事务事件是通过gRPC来上报的,且事务的请求信息是通过Kyro进行序列化和反序列化的。
- 使用简单。仅需编写对应的补偿方法即可进行分布式事务。
- 部署简单。可通过Docker快速部署。
架构
Saga 架构是由 alpha 和 omega组成,其中:
- alpha充当协调者的角色,主要负责对事务进行管理和协调。
- omega是微服务中内嵌的一个agent,负责对网络请求进行拦截并向alpha上报事务事件。
支持模式
现阶段支持柔性事务实现:saga模式。
# alpha-server配置步骤使用 说明
准备环境
- JDK1.8
- Maven3.x
- Docker(可选)
# 获取alpha-server介质包
介质下载:
下载EOS_8.1.0_LA_Alpha_Server.tar.gz
将下载的介质存放到服务器上,例如存放到/opt/alpha_server目录下,解压
修改配置:
cd /opt/alpha_server/config
vi application.yml
修改application.yml配置文件中的mysql配置,修改为本地mysql即可。
启动服务:
./alpha-server-cmd.sh start
停止服务:
./alpha-server-cmd.sh stop
# Omega配置步骤
添加依赖
展开源码
修改配置文件
# 配置alpha-service 集群/单机 服务访问地址
alpha:
cluster:
address: localhost:8080
spring:
application:
name: xxxxx
注意:application.name一定不要过长,因为instanceId的格式是application.name+IP,并且长度为36,否则alpha-server事务持久化会报错 以上两个属性配置为必填,因为alpha-server会依据application.name去查找对应的Omega,其他应用配置自行添加,address可根据alpha-server中的配置实际添加
| 参数 | 说明 |
|---|---|
| alpha.cluster.address | 配置alpha-server地址,格式:host:port。 |
saga模式配置和用法
对于采用不完美的补偿方式的系统(Saga实现)来说,我们的补偿事务逻辑其他的事务逻辑相比没有什么不同, 系统只需要像执行其他业务逻辑一样执行相关的补偿操作即可。系统不需要设置特殊的处理逻辑来恢复事务执行之前的状态。以我们常见的银行ATM取款业务为例,银行账户预先进行扣减的操作,如果取款不成功,其逻辑恢复操作就是通过冲正的方式将预先扣减的款项打回到用户账户,我们可以通过查看账户的交易记录找到扣减和冲正的记录信息。下图展示的内容就是当初始服务调用分别调用服务A和服务B,服务B执行出现错误,这个时候我们事务协调器会调用服务A的冲正方法将系统状态恢复到执行服务调用之前的状态。
一个分布式事务必须由开始、结束图元组成。
分布式事务是基于Saga实现。在分布式事务的范围内,可以包含其他各种的图元(有些图元带补偿操作,有些图元不带补偿操作),当分布式事务范围内出现异常,会自动调用那些已成功执行过图元的补偿操作。
支持补偿操作的图元包括:
Spring Bean调用图元:在【高级】tab页里有补偿的输入框,可以选择的是同一个Spring Bean的不同方法,补偿的方法需要和原方法有一样的输入参数。
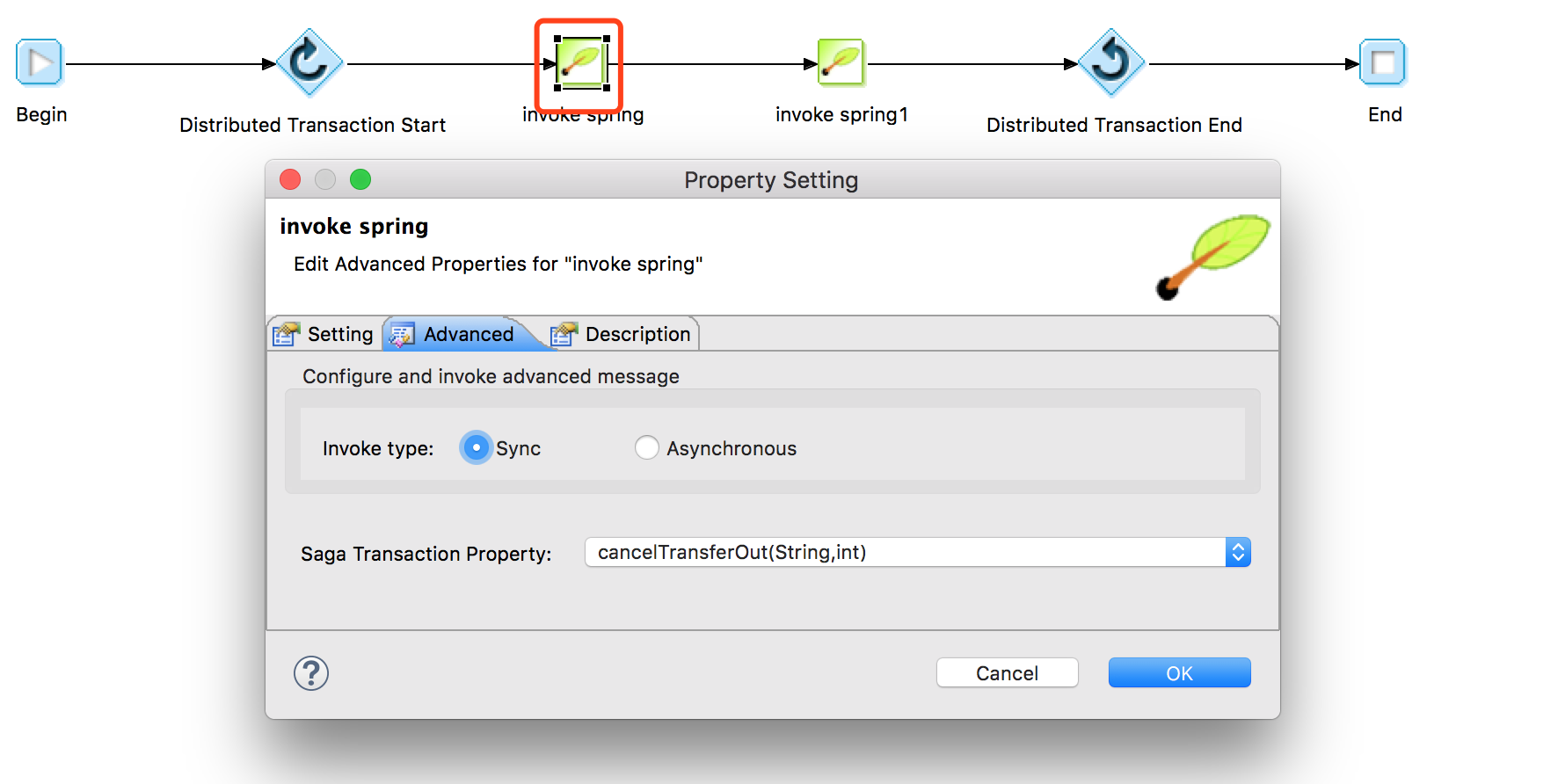
EOS 服务调用图元:在【高级】tab页里有补偿的输入框,补偿的输入框的值是一个URL,该URL指向的是另一个EOS服务,补偿的EOS服务需要和原服务有一样的输入参数。
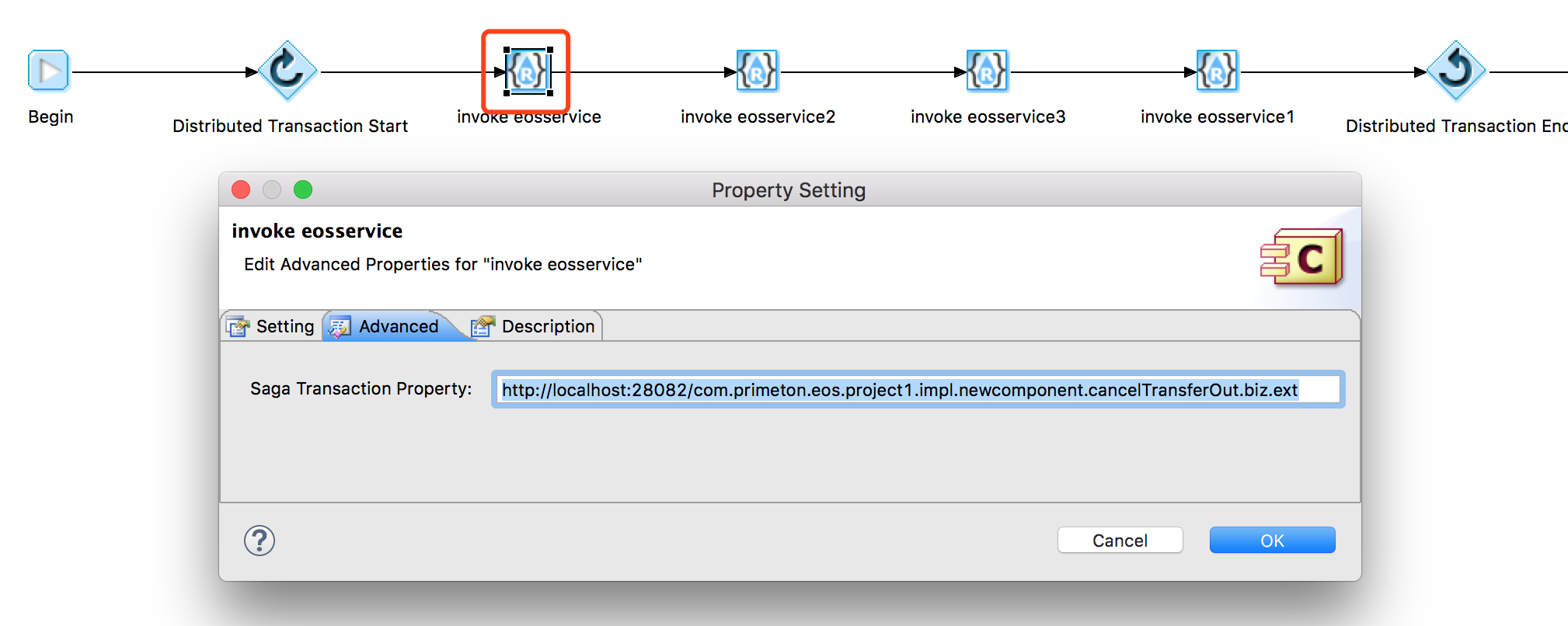
注意:实现的服务和补偿方法必须满足幂等的要求
注意:补偿方法的入参必须与正常方法入参一致,否则无法执行补偿方法(alpha-server找不到补偿方法)
至此,正常启动服务即完成saga模式配置!!!
# 自定义拦截器
某些场景中,业务使用HTTP而不是HTTPS,作为网络传输通道,被调用发可能会对请求进行一些权限校验,发起方也可能会对每一个HTTP请求进行增强,比如添加一些Header等等,具体的Filter和Interceptor如何实现请参考如下:
# 自定义filter
OncePerRequestFilter顾名思义,滤器基类,旨在确保每个请求调度在任何Servlet容器上执行一次执行,自定义Filter并继承这个类,重写doFilterInternal()方法即可,在doFilterInternal()方法内做一些业务逻辑权限校验等即可,具体代码实现如下:
SDKAccessControlFilter.java
public class SDKAccessControlFilter extends OncePerRequestFilter implements Ordered {
private static final Logger logger = LoggerFactory.getLogger(SDKAccessControlFilter.class);
private static final Logger traceLogger = SDKTraceLoggerFactory.getLogger(SDKAccessControlFilter.class);
public static final int ORDER = SDKLoggingFilter.ORDER + 100;
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
//这里进行自定义逻辑校验即可
filterChain.doFilter(request, response);
return;
}
}
# 自定义Interceptor
实现ClientHttpRequestInterceptor接口
该拦截器的作用是拦截客户端HTTP请求。这个接口的实现可以配合RestTemplate一起使用作,在用RestTemplate作为客户端工具向RESTful api发送各种请求时,也许很多请求都需要用到相同的HTTP Header, ClientHttpRequestInterceptor接口就可对该类型请求进行拦截,并在其被发送至服务端之前修改请求或是增强相应的信息。具体代码如下: 1.创建自定义拦截器并实现ClientHttpRequestInterceptor接口:
TransactionClientHttpRequestInterceptor.java
public class TransactionClientHttpRequestInterceptor implements ClientHttpRequestInterceptor {
TransactionClientHttpRequestInterceptor() {
}
@Override
public ClientHttpResponse intercept(HttpRequest request, byte[] body,
ClientHttpRequestExecution execution) throws IOException {
//这里可以进行自定义的一些逻辑操作 比如添加自定义的header等等
HttpHeaders headers = request.getHeaders();
headers.add(HHN_SOURCE_SYS_KEY, "");
headers.add(HHN_SOURCE_SYS_CODE, "");
return execution.execute(request, body);
}
}
2.对自定义拦截器进行装配:创建一个Configuration配置类,配合@Configuration和@Bean注解进行装配
@Configuration
public class RestTemplateConfig {
@Bean(name = "xxxxRestTemplate") //这里bean的名字如果有和其他的冲突,需自定义唯一name
public RestTemplate xxxxRestTemplate() {
RestTemplate template = new RestTemplate();
List<ClientHttpRequestInterceptor> interceptors = template.getInterceptors();
interceptors.add(new TransactionClientHttpRequestInterceptor(context));
template.setInterceptors(interceptors);
return template;
}
}
实现HandlerInterceptor接口
1.自定义class实现HandlerInterceptor接口
TransactionHandlerInterceptor.java
public class TransactionHandlerInterceptor implements HandlerInterceptor {
TransactionHandlerInterceptor() {
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
//这里自定义逻辑进行校验。。。
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object o, ModelAndView mv) {
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object o, Exception e) {
}
}
2.对自定义拦截器进行装配:创建一个Configuration配置类并继承WebMvcConfigurerAdapter或者实现WebMvcConfigurer,配合@Configuration注解进行装配
WebConfig .java
@Configuration
@EnableWebMvc
public class WebConfig extends WebMvcConfigurerAdapter {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new TransactionHandlerInterceptor());
}
}
# 定制序列化和反序列化
在实际开发中,很多应用场景使用的都是HTTP协议进行通信,但是由于HTTP协议的非安全性,这样就会使得在网络中传输的数据能够很轻易的被各种专门的工具进行数据抓包监听。而且在实际业务开发中,业务对应用或服务间传输的敏感数据有较高的安全要求,这类数据需要特别的加密保护(业务不同对算法要求不同),这样即使内容被截获,也可以保护其中的敏感数据不被轻易获取。
解决方案
服务间的通信离不开序列化和反序列化,对于上述的场景,使用jackson类库提供的 @JsonSerialize 和 @JsonDeserialize 注解功能,对敏感数据定制序列化和反序列化方法,并在定制化的方法中实现加解密功能。
注解描述参考:在 https://github.com/FasterXML/jackson-databind/wiki 中查找对应版本的Javadocs
以下是以一个demo示例进行演示如何使用相关注解功能(不涉及加解密相关,加解密可自行自定义加解密方式)
1.新建一个Person类,对Person类中的name属性,通过注解来实现自定义序列化和反序列化功能,具体代码如下:
Person.java
public class Person {
private int usrId;
//指定数据 name 使用特定的序列化和反序列化方法
@JsonSerialize(using = SecretSerialize.class)
@JsonDeserialize(using = SecretDeserialize.class)
private String name;
public int getUsrId() {
return usrId;
}
public void setUsrId(int usrId) {
this.usrId = usrId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"usrId=" + usrId +
", name='" + name + '\'' +
'}';
}
}
| 参数 | 说明 |
|---|---|
| @JsonSerialize | 此注解用于属性或者getter方法上,用于在序列化时嵌入开发者自定义的代码。 |
| @JsonDeserialize | 此注解用于属性或者getter方法上,用于在反序列化时嵌入开发者自定义的代码。 |
2.定义 SecretSerialize 类 和 SecretDeserialize 类,并重写其方法
SecretSerialize.java
public class SecretSerialize extends JsonSerializer<String> {
//重写 name 的序列化方法,可在此实现用户定制的加解密或其他操作
@Override
public void serialize(String value, JsonGenerator gen, SerializerProvider serializers)
throws IOException, JsonProcessingException {
//在数据 name 后增加4个特定字符
value = value + " &#@";
//执行序列化操作
gen.writeString(value);
}
}
public class SecretDeserialize extends JsonDeserializer<String> {
//重写 name 的反序列化方法,与serialize序列化方法匹配,按用户定制的规则获取真实数据
@Override
public String deserialize(JsonParser p, DeserializationContext ctxt) throws IOException, JsonProcessingException {
//获取反序列化数据,除去4个特定字符,获取真实的 name
String value = p.getValueAsString();
value = value.substring(0, value.length() - 4);
return value;
}
}
# 数据库连接扩展点
与数据库连接扩展点相关的接口类: 关键类说明:
| 关键类 | 全名 | 说明 |
|---|---|---|
| ISynchronizationManager | com.eos.infra.connection.ISynchronizationManager | 回调接口的管理者 |
| IStatementSynchronization | com.eos.infra.connection.IStatementSynchronization | Statement的回调接口 |
| IResultSetSynchronization | com.eos.infra.connection.IResultSetSynchronization | 结果集的回调接口 |
| IConnectionSynchronization | com.eos.infra.connection.IConnectionSynchronization | 数据库连接的回调接口 |
# 功能描述
提供的数据库连接创建工厂支持用户自定义的一批回调接口,这些回调接口包括:
- Statement的回调接口(IStatementSynchronization);
- 结果集的回调接口(IResultSetSynchronization);
- 数据库连接的回调接口(IConnectionSynchronization);
利用这些回调接口可以在执行各种数据库操作的时候完成用户的回调操作。
该回调主要用在下面对外提供的获取数据库连接的方法中。 com.eos.infra.connection.ConnectionFactory.createConnection(DataSource dataSource,ISynchronizationManager synchronizationManager)
ISynchronizationManager接口类负责管理上面的三种用户回调接口。
# 关键类
关键类:IStatementSynchronization、IResultSetSynchronization、IConnectionSynchronization、ISynchronizationManager
- IStatementSynchronization类: 在执行Statement时候,提供了不同时机的回调方法。 类定义如下:
public interface IStatementSynchronization {
void onCreate(Statement statement);
void onClose(Statement statement);
void onException(Statement statement, Exception exception);
void beforeSqlExecute(Statement statement, String sql);
void afterSqlExecute(Statement statement, String sql);
void afterSqlExecuteWithException(Statement statement, String sql,
Exception exception);
}
IStatementSynchronization类操作说明:
| 方法签名 | 功能说明 |
|---|---|
| onCreate(Statement statement) | 当Statement被创建的时候会回调该方法 |
| onClose(Statement statement) | 当Statement被关闭的时候会回调该方法 |
| onException(Statement statement, Exception exception) | 当调用Statement方法时发生异常会调用该方法 |
| beforeSqlExecute(Statement statement, String sql) | 在sql执行之前会回调该方法 |
| afterSqlExecute(Statement statement, String sql) | 在sql执行之后会回调该方法 |
| afterSqlExecuteWithException(Statement statement, String sql, Exception exception) | 在sql执行时发生异常会回调该方法 |
- IResultSetSynchronization类: 在执行结果集的时候,提供了不同时机的回调方法。 类定义如下:
public interface IResultSetSynchronization {
void onCreate(ResultSet resultSet);
void onClose(ResultSet resultSet);
void onException(ResultSet resultSet, Exception exception);
}
IResultSetSynchronization类操作说明:
| 方法签名 | 功能说明 |
|---|---|
| onCreate(ResultSet resultSet) | 当结果集被创建时会回调该方法 |
| onClose(ResultSet resultSet) | 当结果集被关闭时会回调该方法 |
| onException(ResultSet resultSet, Exception exception) | 当调用结果集方法时发生异常会调用该方法 |
- IConnectionSynchronization类: 在执行数据库连接的时候,提供了不同时机的回调方法。 类定义如下:
public interface IConnectionSynchronization {
void onCreate(Connection conn);
void onClose(Connection conn);
void onException(Connection conn, Exception exception);
}
IConnectionSynchronization类操作说明:
| 方法签名 | 功能说明 |
|---|---|
| onCreate(Connection conn) | 当创建数据库连接的时候会回调该方法 |
| onClose(Connection conn) | 当数据库连接被关闭的时候会回调该方法 |
| onException(Connection conn, Exception exception) | 当调用数据库连接方法时发生异常会调用该方法 |
- ISynchronizationManager类: 在执行数据库连接的时候,提供了不同时机的回调方法。 类定义如下:
public interface ISynchronizationManager {
List<IConnectionSynchronization> getConnectionSynchronizations();
boolean hasConnectionSynchronizations();
List<IStatementSynchronization> getStatementSynchronizations();
boolean hasStatementSynchronizations();
List<IResultSetSynchronization> getResultSetSynchronizations();
boolean hasResultSetSynchronizations();
}
ISynchronizationManager类操作说明:
| 方法签名 | 功能说明 |
|---|---|
| getConnectionSynchronizations() | 得到数据库连接的回调集合 |
| hasConnectionSynchronizations() | 是否有数据库连接的回调集合 |
| getStatementSynchronizations() | 得到Statement的回调集合 |
| hasStatementSynchronizations() | 是否有Statement的回调集合 |
| getResultSetSynchronizations() | 得到结果集的回调集合 |
| hasResultSetSynchronizations() | 是否有结果集的回调集合 |
# 应用示例
# 场景说明
用户希望获取数据库连接后,能够执行自己的回调操作。在回调操作中可以执行对数据库连接、Statement、ResultSet等进行统计监控、日志记录、异常处理时候,可以通过本扩展点中提供的回调接口来实现功能。
本例中给出了希望在操作数据库连接时候,如果发生了异常,希望记录日志,便于将来对问题的跟踪。
# 示例实现
- 实现IConnectionSynchronization接口,完成LogConnectionSynchronization的开发。 当执行数据库连接发生异常的时候,通过日志服务记录日志; 实现类的代码如下:
public class LogConnectionSynchronization implements
IConnectionSynchronization{
public void onClose(Connection conn) {}
public void onCreate(Connection conn) {}
public void onException(Connection conn, Exception exception) {
//通过日志服务,记录发生异常时候的日志信息
LogService.logException(conn,exception);
}
}
- 实现ISynchronizationManager,将步骤1中LogConnectionSynchronization加入到ISynchronizationManager的实现中。
public class MySynchronizationManagerImpl
ISynchronizationManager {
private List<IConnectionSynchronization> connectionSynchronizations = new ArrayList<IConnectionSynchronization>();
private List<IStatementSynchronization> statementSynchronizations = new ArrayList<IStatementSynchronization>();
private List<IResultSetSynchronization> resultSetSynchronizations = new ArrayList<IResultSetSynchronization>();
private boolean hasConnectionSynchronizations;
private boolean hasStatementSynchronizations;
private boolean hasResultSetSynchronizations;
public List<IConnectionSynchronization> getConnectionSynchronizations() {
return connectionSynchronizations;
}
public List<IResultSetSynchronization> getResultSetSynchronizations() {
return resultSetSynchronizations;
}
public List<IStatementSynchronization> getStatementSynchronizations() {
return statementSynchronizations;
}
public void addConnectionSynchronization(
IConnectionSynchronization connectionSynchronization) {
this.connectionSynchronizations.add(connectionSynchronization);
hasConnectionSynchronizations = true;
}
public void addResultSetSynchronization(
IResultSetSynchronization resultSetSynchronization) {
this.resultSetSynchronizations.add(resultSetSynchronization);
hasResultSetSynchronizations = true;
}
public void addStatementSynchronization(
IStatementSynchronization statementSynchronization) {
this.statementSynchronizations.add(statementSynchronization);
hasStatementSynchronizations = true;
}
public boolean hasConnectionSynchronizations() {
return hasConnectionSynchronizations;
}
public boolean hasResultSetSynchronizations() {
return hasResultSetSynchronizations;
}
public boolean hasStatementSynchronizations() {
return hasStatementSynchronizations;
}
}
- 通过ConnectionFactory创建一个可以执行用户回调方法的数据库连接。 下面代码示例了如何通过上面实现的回调接口创建一个数据库连接。
MySynchronizationManagerImpl manager = new MySynchronizationManagerImpl();
IConnectionSynchronization conSyn = new LogConnectionSynchronization();
manager. addConnectionSynchronization(conSyn);
DataSource ds = DataSourceHelper().getDataSource();
Connection conn = ConnectionFactory.createConnection(ds, manager);
通过上面代码创建的数据库连接之后,当发生异常的时候,就能够回调上面步骤1中我们实现的LogConnectionSynchronization中的方法记录日志。
# 事务同步扩展点
与事务同步扩展点相关的接口类: 关键类说明:
| 关键类 | 包名 | 说明 |
|---|---|---|
| ITransactionSynchronization | com.eos.common.transaction.ITransactionSynchronization | 事务同步回调接口; 可以在事务执行的不同时机执行回调操作。 |
| TransactionSynchronizationManager | com.eos.common.transaction.TransactionSynchronizationManager | 事务回调接口管理器,用于注册事务回调接口。 |
# 功能描述
事务同步扩展点,主要提供了一个事务的回调入口,可以在事务执行的不同阶段,执行用户实现的事务同步扩展点。
主要的回调时机包括:
- beforeCommit,事务提交之前;
- beforeCompletion,事务完成之前;
- afterCompletion,事务完成之后;
- resume,恢复事务;
- suspend,挂起事务。
# 关键类
关键类:ITransactionSynchronization、TransactionSynchronizationManager
- ITransactionSynchronization类: 事务同步回调接口类,用户实现该接口,然后利用TransactionSynchronizationManager注册,可以在事务执行的不同阶段只用用户的回调实现类。 类定义如下:
public interface ITransactionSynchronization extends TransactionSynchronization {
}
ITransactionSynchronization类操作说明:
| 方法签名 | 功能说明 |
|---|---|
| 方法签名 | 功能说明 |
| beforeCommit(boolean readOnly) | 事务提交之前执行 |
| beforeCompletion() | 在事务完成(包括事务提交、事务回滚)之前执行 |
| afterCompletion(int status) | 在事务完成(包括事务提交、事务回滚)之后执行 |
| suspend() | 事务挂起时机 |
| resume() | 事务恢复时机 |
- TransactionSynchronizationManager类: 用于注册事务同步回调接口,只有通过注册后,事务同步回调类才能被执行。 TransactionSynchronizationManager类操作说明:
| 方法签名 | 功能说明 |
|---|---|
| void registerSynchronization( ITransactionSynchronization synchronization) | 注册一个事务回调实现类 |
| isExistSynchronization( ITransactionSynchronization synchronization) | 判断事务回调实现类是否已经被注册 |
# 应用示例
# 场景说明
在一个复杂的场景中,为了跟踪事务的执行情况(例如需要知道何时执行了事务提交),可以使用事务同步回调接口向事务管理器注册一个事务同步接口实现类,用来跟踪事务的执行情况。
# 示例实现
- 实现ITransactionSynchronization接口,完成TraceTransactionSynchronization的开发。 实现提供的5个切入点的方法,在事务执行的不同时机会触发事务同步实现类; 实现类的代码如下:
public class TraceTransactionSynchronization implements
ITransactionSynchronization{
public void afterCompletion(int status) {
System.out.println("afterCompletion method was called.");
}
public void beforeCommit(boolean readOnly) {
System.out.println("beforeCommit method was called.");
}
public void beforeCompletion() {
System.out.println("beforeCompletion method was called.");
}
public void resume() {
System.out.println("resume method was called.");
}
public void suspend() {
System.out.println("suspend method was called.");
}
}
- 通过事务管理注册器注册步骤1中实现的事务同步接口类。 参见下面的代码示例:
TransactionSynchronizationManager.registerSynchronization(
new TraceTransactionSynchronization());
# 网关插件
1.创建插件项目
创建Maven项目,要求如下:
- 项目名称格式建议以 gateway-plugin- 开头, 如 gateway-plugin-xml-json-conversion
- 为了统一第三方jar包依赖, 防止版本冲突, 项目父pom必须为网关的pom:
<parent>
<groupId>com.primeton.eos</groupId>
<artifactId>eos-dap-gateway</artifactId>
<version>5.0.1</version>
</parent>
- 为了统一异常等, 项目需要依赖于 gateway-common 模块
<dependency>
<groupId>com.primeton.eos</groupId>
<artifactId>gateway-common</artifactId>
<version>5.0.1</version>
</dependency>
2.插件代码规范
为了使插件中定义的 Component 可以被扫描到, package包名必须以 com.primeton.gateway 开头, 建议以 com.primeton.gateway.plugin 开头 在插件中, 可以为网关添加各种 RoutePredicateFactory, GatewayFilterFactory, Filter, Predicate 等, 扩充网关在路由匹配, 请求过滤, 负载均衡等各方面的能力。
3.插件构建和部署
在插件的pom中, 需要添加构建相关的配置:
pom.xml 展开源码
网关的部署介质结构如下:
EOS_Microservices_API_Gateway/
├── bin
│ ├── shutdown.sh
│ └── startup.sh
├── config
│ ├── application.yml
│ └── logback-spring.xml
├── gateway-boot-5.0.0.jar
├── lib
│ └── plugins
│ └── gateway-plugin-xml-json-conversion-5.0.0.jar
└── logs
├── eos-dap-gateway
│ └── eos-dap-gateway.pid
├── eos-dap-gateway.out
├── gateway.log
└── gateway-trace.log
插件构建成jar包之后, 需要将期复制至lib/plugins目录之下, 然后重启网关
# 2.网关现有插件功能
# 报文转换
报文转换:网关可接收除json以外的xml格式的报文,这一功能需配合路由配置才能生效,具体步骤如下:
前提:已经安装好Governor和网关。
1.网关和governor正常运行之后,然后在governor上对对应有相关需求的网关进行路由添加,模板如下:
uri: http://192.168.1.181:8080
predicates:
- Path=/api/**
filters:
- RequestBodyXmlToJson=com.primeton.gateway.plugins.conversion.DefaultXmlJsonConvertor
- ResponseBodyJsonToXml=user,com.primeton.gateway.plugins.conversion.DefaultXmlJsonConvertor
注:
- RequestBodyXmlToJson:网关报文转换将请求报文xml转json的拦截器,RequestBodyXmlToJson之后的内容可以留空(留空时需要去掉等号), 如果为空, 默认认的转换器实现,即为com.primeton.gateway.plugins.conversion.DefaultXmlJsonConvertor,用户也可自定义实现,可以配置一个可选的xml到json的转换器实现类的类名. 如果配置了此类名, 转换时将实例化此类进行转换,这个类要求实现 IXmlToJsonConvertor 接口, 并提供一个无参数的构造方法。
- ResponseBodyJsonToXml:网关报文转换将请求结果报文json转为xml的拦截器,ResponseBodyJsonToXml之后的内容可以留空(留空时需要去掉等号), 如果为空, 默认认的转换器实现,即为com.primeton.gateway.plugins.conversion.DefaultXmlJsonConvertor,用户也可自定义实现,可以配置一个可选的xml到json的转换器实现类的类名. 如果配置了此类名, 转换时将实例化此类进行转换,这个类要求实现 IXmlToJsonConvertor 接口, 并提供一个无参数的构造方法。
# 用户认证鉴权
将用户的登录认证,和接口访问权限验证以插件的方式实现
1.项目名称格式建议以 gateway-plugin- 开头, 如 gateway-plugin-handle-eos8为了统一第三方jar包依赖, 防止版本冲突, 项目父pom必须为网关的pom
pom.xml 展开源码
2.依赖 gateway-core 模块
pom.xml 展开源码
3.实现UserService中的checkToken和checkFunction方法
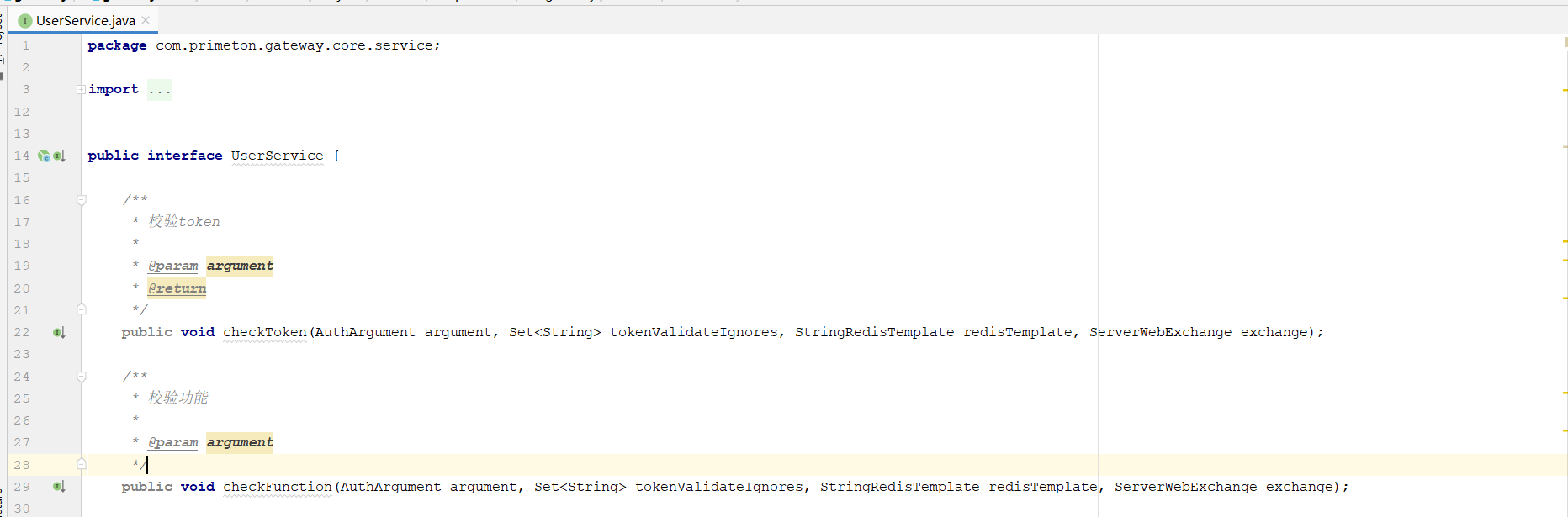
| 参数 | 说明 |
|---|---|
argument | 参数结构对象,包括subKey,appCode,token信息等 |
tokenValidateIgnores | 忽略url名单 |
redisTemplate | 调用的网关reids信息 |
exchange | Request,Response请求 |
4.插件打包后放入网关lib\plugins目录下
# rest请求转为dubbo调用
这一功能是将特定的通过网关的rest请求转为后端dubbo调用,因为是插件式的可插拔的功能,因此默认是不开启的,需要开启该功能具体步骤如下:
1.将rest请求转Dubbo插件放入网关lib\plugins目录下:
- 在离线仓库“EOS_Microservices_5.0.0_Repository.zip”的“com\primeton\eos\gateway-plugin-dubbo-protocol-conversion\5.0.0”目录中,拷贝“gateway-plugin-dubbo-protocol-conversion-5.0.0.jar”到网关lib\plugins目录下
2.修改网关配置文件插件配置:
eos:
gateway:
plugin:
dubbo-protocal-conversion:
generic-invoker-filter:
enabled: true
response-writer-filter:
enabled: true
registry-address: zookeeper://192.168.100.106:2181
rest-context-path: /dubbo
| 参数 | 说明 |
|---|---|
| eos.gateway.plugin.dubbo-protocal-conversion.generic-invoker-filter.enabled | dubbo泛化调用过滤器是否启用, 默认为false不开启 |
| eos.gateway.plugin.dubbo-protocal-conversion.response-writer-filter.enabled | dubbo结果回写filter是否启用, 默认为false不开启 |
| eos.gateway.plugin.dubbo-protocal-conversion.registry-address | dubbo服务的默认注册中心 |
| eos.gateway.plugin.dubbo-protocal-conversion.rest-context-path | 需要进行协议转换的请求的 context-path |
3.协议转换,网关只处理特定的请求,具体请求规范如下:
- 请求必须为POST请求
- 请求body中所带必须参数如下:registryAdress、appName、interfaceName、methodName
| 参数 | 说明 |
|---|---|
| registryAdress | 注册中心地址 |
| appName | dubbo服务名 |
| interfaceName | 调用的dubbo接口名 |
| methodName | 调用的dubbo接口具体的方法名 |
4.重启网关即可
# 配置加密
在日常开发中,我们常常会把一些敏感信息写进*.properties配置文件中,比如数据库密码、redis密码、admin用户的密码甚至系统用户的密码等,这在信息安全和权限控制等方面有很大的隐患。所以出于安全考虑,对配置文件中敏感信息的加密就很有必要了。
本次配置加密作为一个小工具提供给用户使用,需结合Governor管理平台使用,具体使用步骤如下:
首先使用Governor 里的小工具进行加密,加密完配置之后需把加密后的密文以及相关配置在应用中进行相应配置,Governor小工具使用方法如下:
单击用户下“小工具”,进入“小工具”界面:

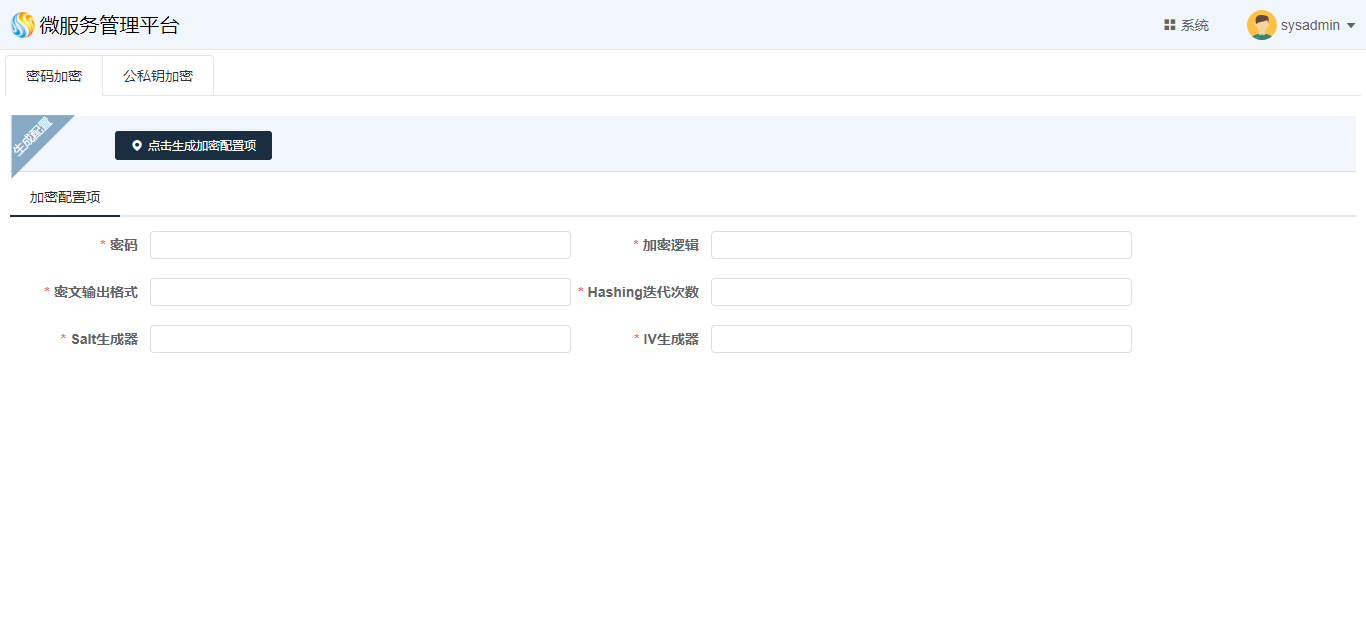
密码加密
单击“密码加密”tab页,进入“密码加密”界面,点击“点击生成加密配置项”,会自动生成加密配置串,如图所示:
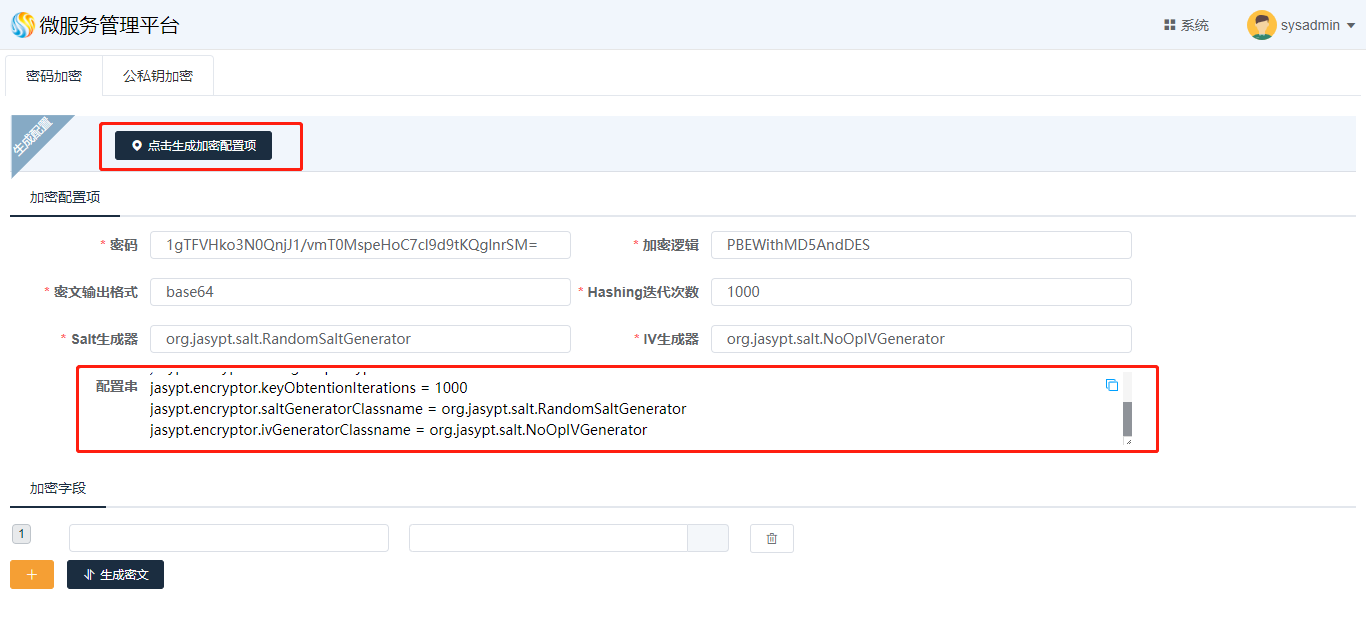
将生成的配置串粘贴复制到应用配置文件中,此处以application.properties文件为例:
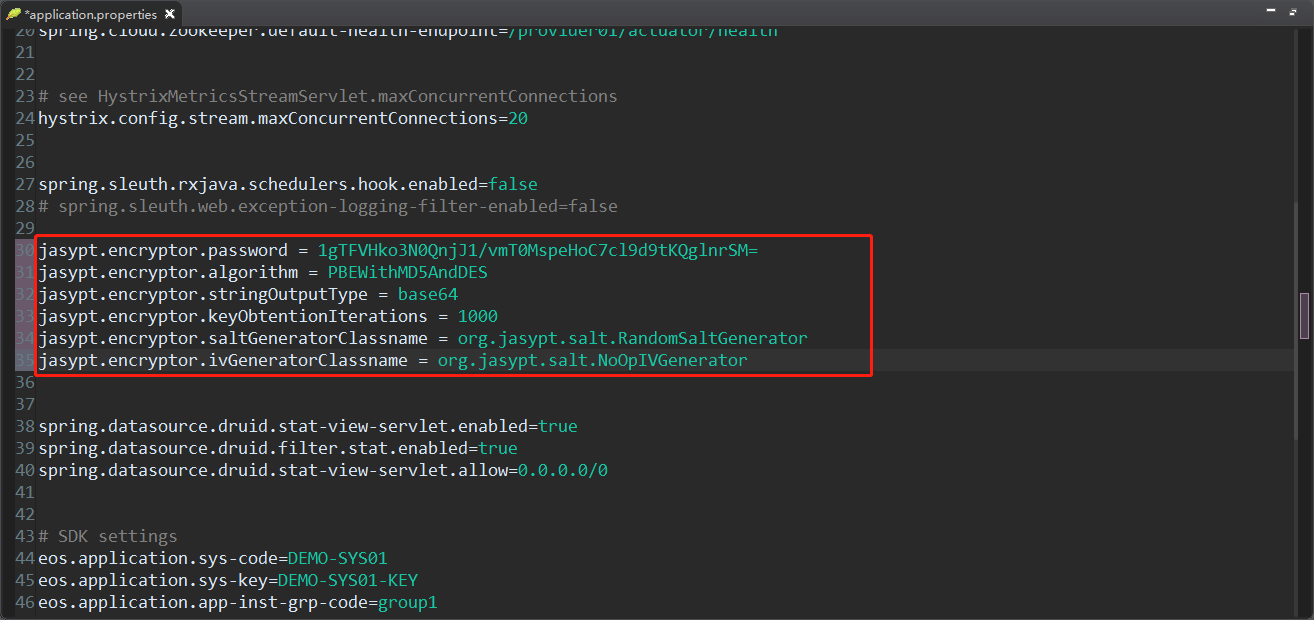
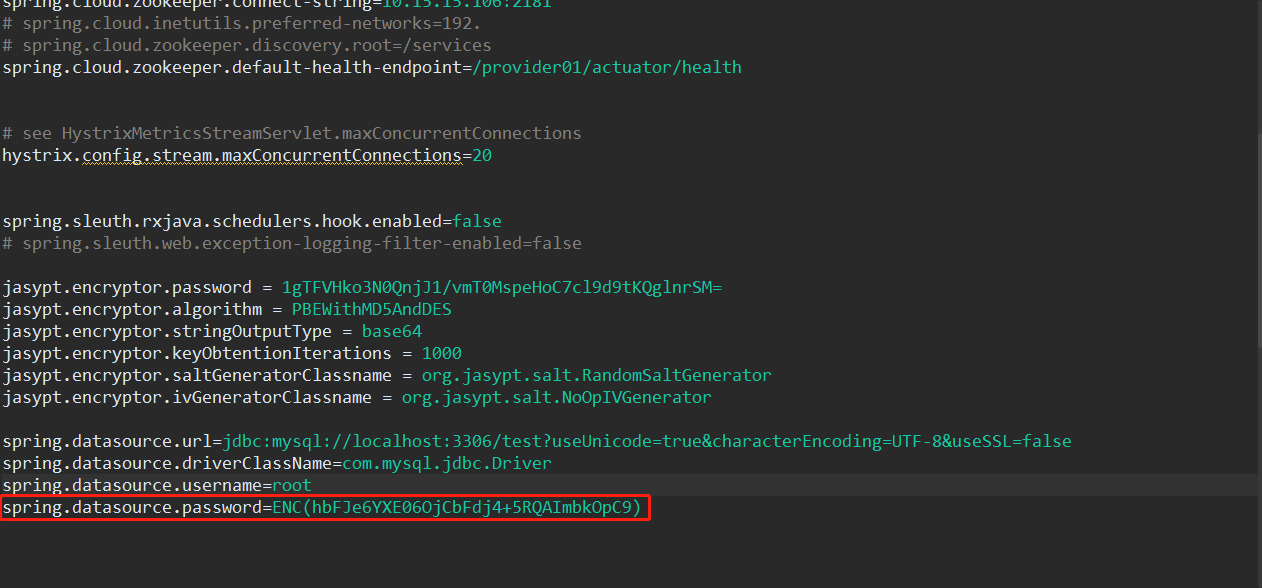
将MySQL密码输入到加密字段中(如MySQL密码为00000000),点击“生成密文”,会自动生成加密字段密文,如图所示:

将生成的加密字段密文复制到application.properties中,格式为ENC(加密字段密文):
公私钥加密
单击“公私钥加密”tab页,进入“公私钥加密”界面,点击“点击生成密钥”,会自动生成加密密钥配置串,如图所示:
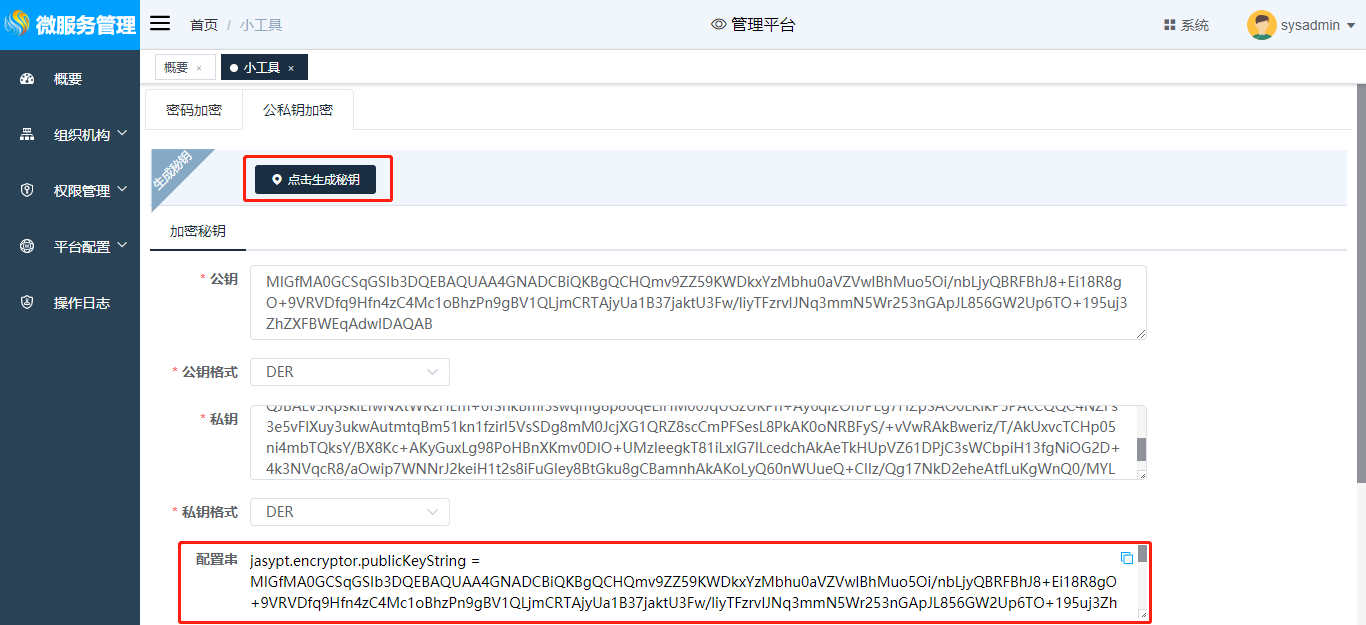
该加密密钥串包含了公钥jasypt.encryptor.publicKeyString及私钥jasypt.encryptor.privateKeyString(公私钥可分开写进代码中,具体实现方式根据业务需求不同可参考jasypt-github, 此处仅演示将公私钥一起复制到配置文件application.properties中), 将包含了公私钥的配置串复制到application.properties中,然后点击添加加密字段进行加密,并将加密后的密文复制到配置文件即可:
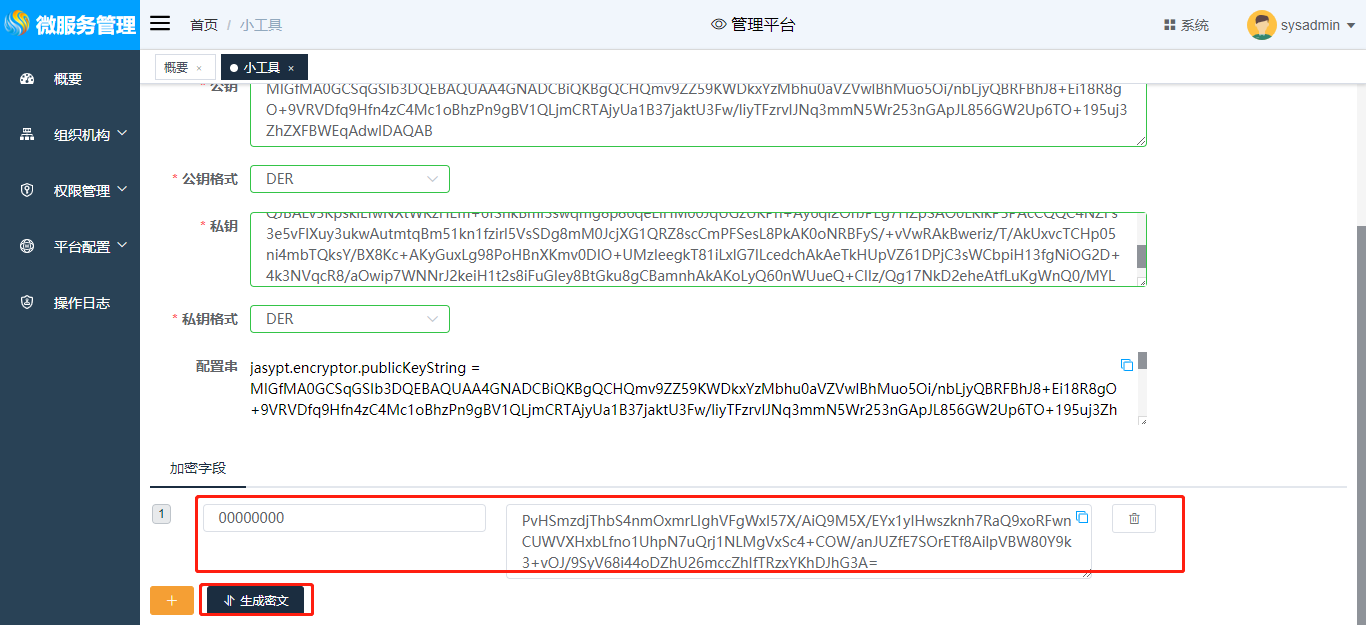
在开发中使用
引入依赖
<dependency>
<groupId>com.primeton.eos</groupId>
<artifactId>eos-server-starter</artifactId>
<version>8.1.0-LA</version>
</dependency>
公私钥加解密配置:
jasypt:
encryptor:
publicKeyString: MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDKpUxXb2rfUEaBTHvWXbbuVVXpHHT56cAyIYNUobMQXMiwv2iZYi9U7bi5DQ5b6ABiYtxZbvI0tD+hf9CXmnwXcNx0KTkFYW34Wt5crANoBIaqGscSA0Ukxo/jNCSaha8TwkSRdCIl2u/xq7bP7IvovqDwtVVmmRMxJ9rznkrqGQIDAQAB
publicKeyFormat: DER
privateKeyString: MIICdgIBADANBgkqhkiG9w0BAQEFAASCAmAwggJcAgEAAoGBAMqlTFdvat9QRoFMe9Zdtu5VVekcdPnpwDIhg1ShsxBcyLC/aJliL1TtuLkNDlvoAGJi3Flu8jS0P6F/0JeafBdw3HQpOQVhbfha3lysA2gEhqoaxxIDRSTGj+M0JJqFrxPCRJF0IiXa7/Grts/si+i+oPC1VWaZEzEn2vOeSuoZAgMBAAECgYBst7H1VrknhZHN3JKztyNlSjMFFVdMnLOYMZKb3QSMSrsA2C/t2lc6YS8xWGfTtuw93HwLHxKiY/GfW0s1ipP3qb0B40YP/PCPHqf94XQK6ChzrVIQ6k4oNLWYCJwDCwXys06ANP308h0PTsRgidIhbJv9Z5WkY5HFvstSv7954QJBAP0TiVa2hiR3ehsjbIp5mJA9mu6t4h2nDcgCLZjweauKr4EpGGVeJLAXdPbzEIwOYIgTszLru96QCfd45U5GkG8CQQDM/J13hteFL7itau4yxAbRSHLouMyrM5gb/BzziVGN8lCdmK42cibpXDvZJI+RhAhAWzDJC6AtRjdRz0J6/OH3AkA6DhNBWxmmn+nY8+VgVsiSvi8edbEbUEkvCqDfJrsiiOv92ymHh3MvGhJw3A19s4adcLd5BO7R/YTrykYAENvtAkAEB1Lw7m196JowjlFwHfokUtAvUrJzCuiKZEINZz17FLAQ6NdDqqqpG27xrY5ExduDqEclLF1Rhne/29rqn92xAkEA1HnwG1eEJqg9fbCqtd5ZdxhMKs48fpFem/WxzmVT1eLp62bypfXjO90ZRZzA1O0NDPkHpM5KGuDet0bE7Ok/Fg==
privateKeyFormat: DER
# 把在governor小工具中生成的密文配置进来即可,配置格式必须为 key:ENC(密文)
test_password: ENC(Q0MmzSMnvr9vNFc
| 参数 | 说明 |
|---|---|
| jasypt.encryptor.publicKeyString | 配置公钥。 |
| jasypt.encryptor.publicKeyFormat | 配置公钥格式。 |
| jasypt.encryptor.privateKeyString | 配置私钥。 |
| jasypt.encryptor.privateKeyFormat | 配置私钥格式。 |
密码加密
jasypt:
encryptor:
password: 0VPAefq+2Nw5FUxR2pX50Pmgmyw0Gg+5r0430EMl7+s=
algorithm: PBEWithMD5AndDES
string-output-type: base64
key-obtention-iterations: 1000
salt-generator-classname: org.jasypt.salt.RandomSaltGenerator
iv-generator-classname: org.jasypt.salt.NoOpIVGenerator
#配置格式必须为: key:ENC(密文)
userName: ENC(05gp3uhhmnhAarb0X4n9GQ==)
| 参数 | 说明 |
|---|---|
| jasypt.encryptor.password | 配置加密的盐值,根密码。 |
| jasypt.encryptor.algorithm | 配置加密方式,默认为PBEWithMD5AndDES。 |
| jasypt.encryptor.string-output-type | base64。 |
| jasypt.encryptor.key-obtention-iterations | 1000。 |
| jasypt.encryptor.salt-generator-classname | org.jasypt.salt.RandomSaltGenerator。 |
| jasypt.encryptor.iv-generator-classname | org.jasypt.salt.NoOpIVGenerator。 |
注意:直接把Governor生成的配置copy过来即可,然后加密的配置项配置格式必须为: xxx.xxx:ENC(密文), 一个配置文件中只能配置一种加密key生成出来的加密配置
# 命名sql多数据库支持有两种方式
# 1. 根据命名sql的id进行匹配
匹配策略:id + 任意字符 + 数据库类型 + 分隔字符 + 数据库版本,不区分大小写,分隔字符可以是点(.)或者中杠(-)或者下划线(_),优先精准匹配模式。
示例如下:
命名sql定义:
<select id="selectSchool" resultClass="commonj.sdo.DataObject">
<![CDATA[SELECT * from school order by school_id]]>
</select>
<select id="selectSchool.mysql" resultClass="commonj.sdo.DataObject">
<![CDATA[SELECT * from school order by school_id]]>
</select>
<select id="selectSchool.mysql_5.7" resultClass="commonj.sdo.DataObject">
<![CDATA[SELECT * from school order by school_id]]>
</select>
Java调用:
INamedSqlSession namedSqlSession = NamedSqlSessionFactory.createSQLMapSession(connection);
List schools = session.queryForList("selectSchool", null);
匹配说明:
如果数据库信息是:Mysql 5.7.31,则会匹配selectSchool.mysql_5.7对应的sql;
如果数据库信息是:Mysql 5.6,则会匹配selectSchool.mysql对应的sql;
如果数据库信息是:Oracle 11g,则会匹配selectSchool对应的sql。
# 2. 动态sql中使用内置数据库信息变量进行判断
内置的数据库信息变量如下:
- context.databaseType:数据库类型信息
- context.databaseTypeLowerCase:数据库类型信息(小写)
- context.databaseTypeUpperCase:数据库类型信息(大写)
- context.databaseVersion:数据库版本信息
- context.databaseVersionLowerCase:数据库版本信息(小写)
- context.databaseVersionUpperCase:数据库版本信息(大写)
示例如下:
<select id="dynamicGetAccountList" resultMap="commonj.sdo.DataObject" >
select * from ACCOUNT
<isEqual prepend="and" property="context.databaseTypeLowerCase" compareValue="mysql">
where ACC_ID = #id#
</isEqual>
order by ACC_LAST_NAME
</select>
或者
<select id="dynamicGetAccountList" resultMap="commonj.sdo.DataObject" >
select * from ACCOUNT
<isTrue prepend="and" expression="context.databaseTypeLowerCase == 'mysql'">
where ACC_ID = #id#
</isTrue>
order by ACC_LAST_NAME
</select>
或者
<select id="dynamicGetAccountList" resultMap="commonj.sdo.DataObject" >
select * from ACCOUNT
<switch>
<case expression="context.databaseTypeLowerCase == 'mysql'">
where ACC_ID = '1'
</case>
<case expression="context.databaseTypeLowerCase == 'oracle'">
where ACC_ID = '2'
</case>
<default>
where ACC_ID = '3'
</default>
</switch>
order by ACC_LAST_NAME
</select>
说明:expression支持groovy表达式,内置变量:context,parameterObject
#
当业务上一些实体需要存储海量数据的时候,考虑到数据库的单表或单库性能和容量问题,需要进行分库或分表处理,比如互联网的订单数据、运营商的用户数据等等。分库分表有很多策略可以使用,如字段取模、时间切分、地域切分等手段,结合业界的常用技术方案(嵌入式方案、代理中间件方案、边车方案等),在EOS Platform 8 产品中,默认使用嵌入式方案完成分库分表能力。
EOS Platform 8 使用了shardingsphere-jdbc,通过简单改造,与EOS现有数据源和事务管理打通,让用户可以无缝使用命名SQL等数据操作能力,最终按策略配置完成业务数据切分功能。
以最简单的取模策略配置为例,EOS Platform 8 中提供了sharding.yml配置,此文件默认需存放在boot构建包的配置目录下,即:***.boot/src/META-INF/sharding.yml(构件包模板中默认不存在此文件,用户需自行创建),文件的内容配置可参考Shardingsphere官网 (opens new window),具体配置文件内容里稍有调整如下:
databaseName: sharding
rules:
- !SHARDING
tables:
t_user:
actualDataNodes: ds_${0..1}.t_user_${0..1}
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: t-user-inline
keyGenerateStrategy:
column: user_id
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database-inline
defaultTableStrategy:
none:
shardingAlgorithms:
database-inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t-user-inline:
type: INLINE
props:
algorithm-expression: t_user_${(user_id % 5) % 2}
props:
datasourceRef: ds_0,ds_1
- 此配置文件中不在需要配置dataSources的信息,因为EOS已经在user-config.xml中配置了数据源信息,假设配置了ds_0, ds_1两个数据源
- 需要配置props.datasourceRef,数据源名字之间用逗号隔开,这样执行分库分表时会根据配置中的数据源列表,从EOS数据源连接池中获取对应连接
- 其他配置则完全可参考官网说明
EOS Platform 8 产品中,可以使用基础构件库或DAS相关的API,达到分库分表的效果,以命名SQL的使用为例,上述配置中可以看到在ds_0, ds_1两个数据源中分别建立了t_user_0, t_user_1两张表,具体策略是针对t_user(这是个逻辑表,实际不存在)同时进行分库+分表,根据表中user_id的值进行模除,从而确定具体数据的存储位置。
命名SQL的示例如下,其中insertUser操作t_user逻辑表(有分库分表效果),insertUser1则直接操作物理表(无分库分表效果):
<?xml version="1.0" encoding="UTF-8"?>
<!-- author:guwei -->
<sqlMap>
<parameterMap id="insert-param" class="com.primeton.eos.project.mapper.User">
<parameter property="username"/>
<parameter property="password"/>
</parameterMap>
<statement id="insertUser" parameterMap="insert-param">
<![CDATA[insert into t_user(username, password) values (?, ?)]]>
</statement>
<statement id="insertUser1" parameterMap="insert-param">
<![CDATA[insert into t_user_1(username, password) values (?, ?)]]>
</statement>
</sqlMap>
接着可通过eos提供的DatabaseExt工具类中的方法完成调用,方法第一个参数为数据源的名字,其中:分库分表数据源是在sharding.yml中配置的逻辑数据源名称。
public void test() throws SQLException, IOException {
List<User> list = new ArrayList<User>();
for (int i = 0; i < 100; i++) {
User user = new User("u" + System.nanoTime(), "p" + System.nanoTime());
list.add(user);
}
DatabaseExt.executeNamedSqlBatch("sharding", "com.primeton.eos.project.core.newnamingsql.insertUser", list.toArray(new User[list.size()]));
DatabaseExt.executeNamedSqlBatch("ds_1", "com.primeton.eos.project.core.newnamingsql.insertUser1", list.toArray(new User[list.size()]));
}
# Mac环境下安装EOS8 Studio
# 1. 准备介质
下载eostools.zip插件包,解压后得到eclipse目录。
# 2. 准备eclipse
登录Eclipse官方下载页面下载4.24版本的Eclipse:https://www.eclipse.org/downloads/packages/release/2022-06/r

# 3. 安装插件
下载elipse后解压,进入eclipse/dropins目录,将解压后的eclipse目录(包含eclipse)复制到dropins下。
# 4. 启动Studio
启动eclispe,右上角透视图上选择EOS开发。

# 5. EOS8 Studio插件升级
如果是已有EOS8 Studio,做插件升级。
- 进入eclipse/dropins/eostools目录,并清空目录。将解压的插件包eclipse目录下的plugins和feature全部复制到eclipse/dropins/eostools目录下。
- 进入eclipse/configuration,删除org.eclipse.osgi目录。
- 进入原eclipse工作空间,删除工作空间中.metadata目录。
- 启动EOS8 Studio,导入已存在Maven项目。