
# 缓存
缓存(Cache)是一个原始数据的集合,用于提高存储或者计算的性能,因为原始数据的存取可能很昂贵;即一个Cache就是一个临时数据存取区域,以提高频繁访问的性能。Cache在应用中主要是解决高性能的访问问题,这些数据的特点是会被频繁的读取,但是修改却很少。例如:业务字典,一般将业务字典的信息保存在数据库中或者文件中,为了提高性能,把数据取出保存在一个Cache中,用户访问到某个业务字典信息时,就在Cache中直接查找是否存在。如果数据库或文件中业务字典的信息发生了变化,那就需要更新Cache中的数据。
Cache模块的基本功能是Cache的管理(创建、查询、销毁)、Cache的基本操作(存储数据)、以及Cache的加载。除此之外,Cache可以在配置文件中直接配置好,系统启动时就自动加载好所配置的Cache。
在EOS的Server中,可以配置两类缓存,一种是系统缓存,一种是用户缓存。
- user-config.xml中默认配置了3种系统缓存,分别是业务字典缓存、服务注册缓存和在线用户缓存。
- 用户可以配置自己的用户缓存,来存放用户的业务数据。
使用缓存的好处是可以缓存经常使用的数据,提高数据的访问效率,并且可以在集群中进行数据的同步,维护集群各个节点的缓存数据的一致性。
为了便于用户开发使用缓存,EOS提供了4种缓存的开发方式,用户可以简单地使用数据实体、命名SQL或编写逻辑流来开发使用缓存的程序,也可以使用稍微复杂点,但更灵活的开发缓存数据加载器来开发,下面会介绍这些开发的方法。
# 缓存概念(Cache)
缓存就是一个临时数据存取区域,用于提高频繁访问的性能,使用key-value键值对操作,类似于Map。EOS的缓存使用com.eos.common.cache.ICache接口表示,系统有一种Cache实现:HashMapCache。
# HashMapCache
HashMapCache是基于HashMap实现的,并使用JMX的MBean调用方式实现的底层通讯功能,来进行集群通知的。
特点:
- 支持集群:支持集群节点直接的数据同步(即维持数据的一致性);
- 不支持事务:缓存的操作如果在事务中,不受事务的影响;
# Cache使用
缓存有一些基本的使用方法,下面的方法是com.eos.common.cache.ICache接口的常用方法:
判断某一个Key值是否存在
booleancontainsKey(Object key);- 参数说明: key:键对象。
- 返回值说明: 如果存在,返回true。
取得key所对应的数据
V get(Object key);- 参数说明: key:键对象。
- 返回值说明: 返回key所对应的数据。
更新数据
voidput(K key, V value);- 参数说明:
- key:键对象。
- Value:数据。
- 参数说明:
删除数据
V remove(Object key);- 参数说明: key:键对象。
- 返回值说明: 返回所删除的key对应的数据。
取得所有的key值列表
Set<K> keySet();- 返回值说明: 返回所有的key值列表。
# 缓存数据加载器(CacheLoader)
# 简介
缓存数据加载器(CacheLoader),用于加载Cache中的数据。
缓存可以根据需要配置CacheLoader,配置的目的:
- 当从缓存中查找数据找不到时,可以通过CacheLoader将数据从数据库或其他地方查找出来(加载)。
- 如果缓存的数据发生变化,可以通过CacheLoader将数据保存到数据库或其他数据源(即负责数据的持久化)。
- 如业务字典缓存就配置了CacheLoader,当某个字典项找不到时,就会从数据库中进行查询,并加载数据。
缓存可以不配置CacheLoader。如果一个缓存没有CacheLoader,则缓存就类似是一个Map,只用来存放内存数据。如在线用户缓存就没有配置CacheLoader,因为数据不需要进行持久化,只需要内存中保留。
EOS中的CacheLoader是通过com.eos.common.cache.ICacheLoader接口进行定义的,如下所示。用户如果需要开发CacheLoader,就需要实现这个接口。
- public Map<K, V> preLoad(); // 预加载,Cache初始数据
- public V get(Object key); // 从数据来源中取得key对应的值
- public void put(K key, V value); // 设定数据来源的值
- public V remove(Object key); // 删除数据来源中的值
# Cache与CacheLoader的交互
要理解为什么要实现CacheLaoder的上述4个接口,需要先了解一下Cache和CacheLoader之间的交互过程。
- 第一次查找数据的预加载: 当cache刚创建完后,cache中的没有任何数据。这时,如果调用cache的get(Object key)方法,cache会判断自己是空的。 如果cache配置了CacheLoader,这时就会自动调用cacheLoader的Map<K, V> preLoad(),进行数据的预加载,然后将该方法返回的Map中的数据全部放入cache中。因此,preLoad()方法用于加载数据,可以加载所有的数据,也可以加载部分数据,用户自己可以根据需要来选择预加载多少数据。
- 第二次查找数据: 当cache的数据经过预加载之后,再次调用cache的get(Object key)方法时,如果找到数据,直接返回;如果找不到,并且cache配置了CacheLoader,就会自动调用CacheLoader的V get(Object key)方法,从数据源中查询数据。 因此,这个方法用来从数据源中查找(或加载)一个数据。
- 用户向cache中存放数据: 当用户向缓存中存放数据,即调用cache的put(K key, V value)方法时,如果cache配置了CacheLoader,cache会自动调用CacheLoader的put(K key, V value)方法,用户可以在该方法中,将数据保存到数据库中。
- 用户从缓存中删除数据: 当用户将某个数据从缓存中删除,即调用cache的remove(Object key)方法时,如果cache配置了CacheLoader,cache会自动调用CacheLoader的remove(Object key)方法,用户可以在该方法中,将数据从数据库中删除。
# Cache管理工厂
用于管理Cache,对Cache进行创建、查询、销毁操作;主要使用com.eos.common.cache.CacheFactory类提供的API实现。
# 查询Cache
Cache是否存在
booleanexists(String cacheName);- 参数说明: cacheName:Cache名称。
- 返回值说明: 如果存在,返回true。
取得某一个Cache
ICache<?, ?> findCache(String cacheName);- 参数说明: cacheName:Cache名称。
- 返回值说明: 如果存在,返回指定的Cache;否则返回null。
查询所有的Cache名称
Set<String> keySet()
# 创建Cache
ICache<?, ?> createCache(CacheProperty cacheConfig, ``boolean` `persistentFlag)`` ``throws` `CacheRuntimeException;
参数说明:
- cacheConfig:Cache配置信息。
- persistentFlag:是否持久化到配置文件。
返回值说明:
- 返回创建的Cache。
# Cache基本属性说明
Cache的基本属性保存在com.eos.common.cache.CacheProperty类中,注意包含下面的信息:
- Cache的名称
- Cache的提供者类名称(目前EOS提供了一个内置的provider,HashMapCacheProvider。目前暂时没有提供用户扩展的方式)
- 是否支持集群
示例:
CacheProperty cacheConfig = ``newCacheProperty(``"SimpleCache"``);``CacheFactory.getInstance().createCache(cacheConfig, ``false``);
# 销毁Cache
销毁某一个Cache
voiddestroyCache(String cacheName);- 参数说明: cacheName:Cache名称。
销毁所有Cache
voiddestroyCache();
# 注意
Cache本身是懒加载的,即如果不使用Cache的时候,Cache默认是不创建的,这样可以减少内存的占用。当用户使用Cache的时候,会通过CacheFactory调用findCache(cacheName),这时候如果Cache还没有创建,CacheFactory会自动创建Cache。
# 配置文件
Cache的相关配置在user-config.xml中,具体如何配置请参考《EOS管理员手册》中的"Governor配置功能\缓存配置"。下面是一个具体的例子:
<module name="Cache">
<group name="CacheForDict">
<configValue key="IsSystemCache">true</configValue>
<configValue key="CacheLoader">com.eos.server.dict.impl.EosDictCacheLoaderImpl</configValue>
</group>
<group name="CacheForAccess">
<configValue key="IsSystemCache">true</configValue>
<configValue key="CacheLoader">com.primeton.access.client.impl.uddi.ServiceCacheLoader</configValue>
<configValue key="ClusterName">CacheForAccessGroup</configValue>
</group>
<group name="CacheForUserObject">
<configValue key="IsSystemCache">true</configValue>
<configValue key="CacheMode">REPL_SYNC</configValue>
<configValue key="IsClustered">true</configValue>
</group>
<group name="orgCache">
<configValue key="DataSourceName">default</configValue>
<configValue key="DataEntityQName">com.primeton.sample.org.Organization</configValue>
<configValue key="IsClustereded">false</configValue>
<configValue key="IsSystemCache">false</configValue>
<configValue key="CacheMode">INVALIDATION_ASYNC</configValue>
</group>
<group name="MyCache1">
<configValue key="DataSourceName">default</configValue>
<configValue key="DataEntityQName">com.primeton.test.newdataset.Customer</configValue>
<configValue key="IsClustered">true</configValue>
<configValue key="IsSystemCache">false</configValue>
<configValue key="CacheMode">INVALIDATION_ASYNC</configValue>
</group>
</module>
从上面的例子可以看出,配置了3个系统缓存(CacheForDict、CacheForAccess和CacheForUserObject),2个用户缓存(orgCache和syncCache)。
Cache相关配置的说明如下表所示:
| 配置项 | 配置说明 |
|---|---|
| 配置项 | 配置说明 |
| IsSystemCache | 是否为系统缓存,取值为true或false,true表示系统缓存,false表示用户缓存。 |
| CacheLoader | CacheLoader的实现类全名(可选),当用户配置自定义数据加载方式的时候,需要设置CacheLoader。 |
| CacheDataModificationListener | 用于配置缓存的,修改监听事件的监听器的类全名(可选)。当缓存配置了监听器后,监听器可以监控cache的数据变化,当cache的数据被改变后,监听器可以收到修改通知,用户可以做相应的处理。用户可以开发自己的cache监听器程序,需要实现com.primeton.ext.common.cache.CacheDataModificationListener接口。 |
| IsClustered | 集群标志(可选):true(集群模式)或者false(本地模式) 默认可以不填写,按照默认规则判断缓存是否支持集群。如果应用在一个服务器组中且当前配置项未填写,则默认支持集群;如果配置了集群的名称,ClusterName,也支持集群;其他情况,均不支持集群。 |
| CacheMode | 集群的同步模式,表明集群中的数据采取何种通知方式进行同步。有下面的选项:Unknown macro: {span}INVALIDATION_ASYNC:异步失效INVALIDATION_SYNC:同步失效REPL_ASYNC:异步复制REPL_SYNC:同步复制 |
| DataSourceName | 应用数据源的名称。当用户配置数据实体、命名SQL两种数据加载方式的缓存时,需要设置该属性。 |
| DataEntityQName | 数据实体全名,当用户配置数据实体数据加载方式的缓存时,需要设置该属性。 |
| LoadOneSqlID | 加载单个数据的命名SQL的ID,当用户配置命名SQL数据加载方式的缓存时,需要设置该属性。 |
| LoadAllSqlID | 加载所有数据的命名SQL的ID,当用户配置命名SQL数据加载方式的缓存时,需要设置该属性。 |
| LoadOneBizQName | 加载单个数据的逻辑流的全限定名,当用户配置逻辑流数据加载方式的缓存时,需要设置该属性。 |
| LoadAllBizQName | 加载所有数据的逻辑流的全限定名,当用户配置逻辑流数据加载方式的缓存时,需要设置该属性。 |
| DataType | 逻辑流加载方式的返回数据类型,支持java对象和sdo对象两种。需要填写类的全名,或数据实体全名。 |
| PrimaryKeys | 主键列表,多个主键使用逗号","分隔。用于当用户配置命名SQL和逻辑流两种数据加载方式的主键列表。 |
# 数据实体缓存的开发
数据实体缓存是最容易开发和配置的一种缓存。用户只需要定义一个数据实体,就可以实现缓存数据的自动加载。系统默认为这种缓存配置了CacheLoader,该CacheLoader只负责加载数据,不负责持久化数据。
数据实体缓存如果配置成支持集群,集群的数据同步方式默认采用同步失效方式,以保证一个节点数据修改后,另一个节点的数据失效,用户请求时可以重新从数据库中加载数据。
# 开发数据实体
数据实体可以是持久化实体和查询实体,但不能是非持久化实体,如下图是用户开发的一个数据集,里面有一个持久化实体TEmployee和一个查询实体QEmployee。

不过数据实体是有要求的,持久化数据实体必须设置唯一的主键,如下图,TEmployee持久化实体设置了主键empId。
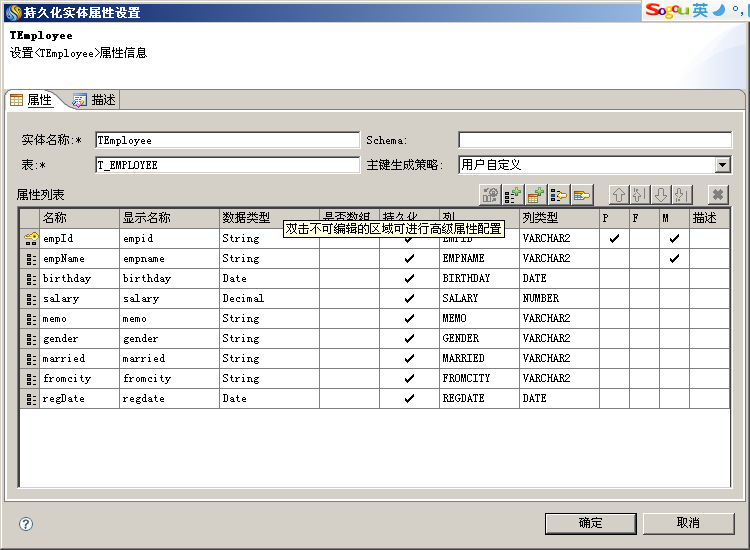
对于查询实体,也必须设置唯一标识,如下图,QEmployee查询实体设置了唯一标识empId。
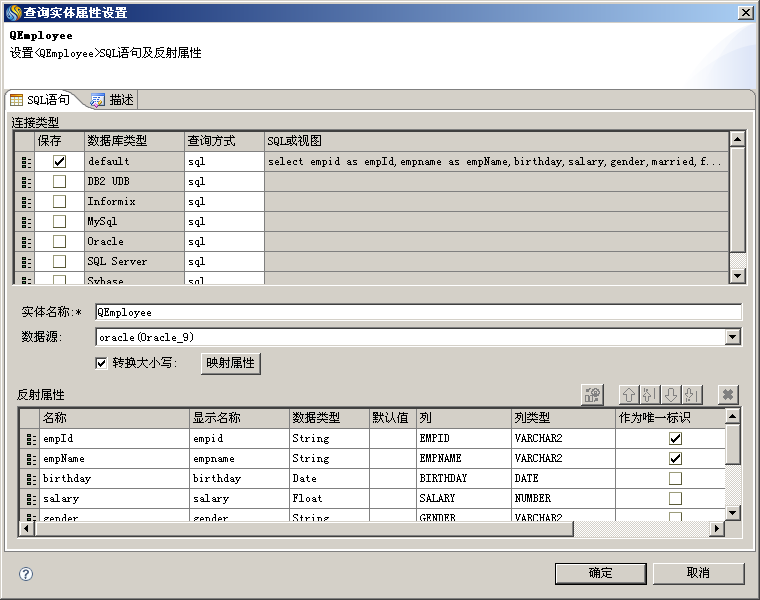
另外,数据实体可以带有关联实体,可以支持1对1、1对多、多对1的关联实体,但关联的层次只限于一层,如A关联B,但B不能再关联C。有关联实体的情况,如果查询出本实体的数据,则本实体的所有关联实体的数据也会被自动查出。
下面有三个例子,来说明各种关联实体。
持久化实体,单主键,主键是一个关联实体(1:1)。

PersonInfo作为缓存配置的数据实体,PersonInfo关联一个BirthArea实体,BirthArea实体的属性id作为主键。
持久化实体,多主键,一个主键是关联实体(n:1)。

EosDictEntry作为缓存配置的数据实体,有两个主键:一个简单主键是dictid,另一个dicttypeid与实体EosDictType作关联。
持久化实体,数据实体含有1对多关联实体(1:n)。

Class(班级)中有一个1对多的关联实体Student(学生),查询的时候,会自动将所有关联实体一并查出。
# 配置数据实体缓存
在数据模型中定义完数据实体以后,将程序通过Studio导出ecd部署的服务器上,就可以通过Govenror进行缓存配置了。下图是缓存的配置页面(假设数据实体的全名为com.primeton.mysample.employee.TEmployee)。

配置完缓存,就可以在程序中使用缓存了。缓存是懒加载的,第一次从缓存中查询数据时,会创建缓存,并且预加载所有的数据。
# 使用编程方式创建缓存
缓存可以通过Governor配置,然后在应用中自动创建。还有一种更灵活的方式创建缓存,就是在程序运行过程中,通过缓存的API接口自动创建缓存(前提是缓存的相关程序,如数据实体已经部署到应用中)。 com.eos.common.cache.CacheUtil类提供了创建数据实体、命名SQL、逻辑流三种数据加载方式缓存的API接口。下面用这个类的创建数据实体缓存的API来创建TEmployee缓存。
String cacheName="entityCache";
ICache cache=CacheUtil.createDataEntityCache(cacheName, false, null, CacheProperty.NONE,
"default","com.primeton.mysample.employee.TEmployee",null, null);
缓存的销毁:
CacheUtil.destroyCache("entityCache");
# 使用缓存
缓存创建后,就可以使用了,下面是使用缓存的一些例子:
String key = "0001";
DataObject dataObj=DataObjectUtil.createDataObject("com.primeton.mysample.employee.TEmployee");
cache.put(key, dataObj);
dataObj.set("empId","0001");
Object value=cache.get(key);
System.out.println("key="+key+",value="+value);
System.out.println("keyset="+cache.keySet());
cache.remove(key);
System.out.println("remove "+key);
value=cache.get(key);
System.out.println("key="+key+",value="+value);
cache.clear();
# 命名SQL缓存开发
命名SQL缓存是使用命名SQL作为缓存数据加载方式的一种缓存。用户需要开发加载单个数据和加载所有数据的命名SQL。系统默认为这种缓存配置了CacheLoader,该CacheLoader只负责加载数据,不负责持久化数据。
数据实体缓存如果配置成支持集群,集群的数据同步方式默认采用同步失效方式,以保证一个节点数据修改后,另一个节点的数据失效,用户请求时可以重新从数据库中加载数据。
# 开发命名SQL
下面的例子是一个从T_employee表中查询出员工信息的命名SQL,命名SQL的输入和输出参数都是一个HashMap(即主键empId和员工数据map的对照表)。
<parameterMap class="java.util.HashMap" id="employeeMapInput">
<parameter javaType="String" jdbcType="varchar2" property="empId"/>
</parameterMap>
<resultMap class="java.util.HashMap" id="employeeMapResult">
<result column="empid" javaType="string" property="empId"/>
<result column="empname" javaType="string" property="empName"/>
<result column="birthday" javaType="java.sql.Date" property="birthday"/>
<result column="salary" javaType="float" property="salary"/>
<result column="gender" javaType="string" property="gender"/>
<result column="married" javaType="string" property="married"/>
<result column="fromcity" javaType="string" property="fromcity"/>
<result column="memo" javaType="string" property="memo"/>
</resultMap>
<select id="employeeSelectMap" parameterMap="employeeMapInput"
resultMap="employeeMapResult">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
<isNotNull property="empId">
WHERE empid = #empId#
</isNotNull>
</select>
可以看出,命名SQL的输入参数、输出参数都是一个HashMap,但定义的主键为empId,这个必须和parameterMap中定义的大小写完全一致。这个命名SQL由于有了一个isNotNull的判断,所以加载单个命名SQL和加载所有数据的命名SQL都可以共用这一个命名SQL。
# 配置命名SQL缓存
有了命名SQL,就可以在Governor上配置命名SQL缓存了,下面是一个配置的例子。
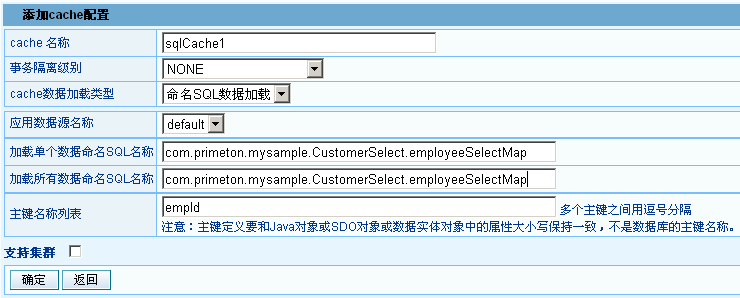
# 需要遵守的一些规则
用户缓存加载的命名SQL,必须遵守一些必要的规则:
加载单个数据的命名SQL
必须定义一个输入参数(parameterMap)和一个输出参数(resultMap)。
输入、输出参数的类型可以是:Map、JavaBean、数据实体(包括非持久化实体、持久化实体和查询实体)、一个通用的SDO对象(commonj.sdo.DataObject)。
用户定义必须写具体实现类的全限定名,如支持java.util.HashMap,但不支持java.util.Map。
下表是各种类型输入或输出参数类的定义例子:
| 类型 | 命名SQL参数的class属性写法举例 |
|---|---|
| Map | java.util.HashMap |
| JavaBean | com.primeton.mysample.vo.Employee |
| 数据实体 | com.primeton.mysample.dataset1.TEmployee |
| 通用SDO对象 | commonj.sdo.DataObject |
输入参数和输出参数的类型可以一致,也可以不一致。如果不一致,用户必须保证输入参数和输出参数中主键字段的大小写完全一致,否则在值转换过程中会出错。 推荐用户保持一致,以免出现编程的失误。
使用数据实体作为返回参数时,不支持带有关联实体的数据实体。
加载所有数据的命名SQL
- 不需要定义输入参数,但必须定义返回参数。
- 输出参数的要求和加载单个数据的命名SQL的要求一致。
单主键和多主键的使用:用户可以使用缓存基础构件库的com.eos.foundation.eoscommon.CacheUtil.getValue(String cacheName, Objec key)从缓存中取数据,分为单主键和多主键两个使用场景。
- 单一主键:key参数只需要传入一个String或数值(支持int、long、float、double及其封装对象)、Date(日期或时间戳)对象即可,用户不需要构造一个复合对象(JavaBean、Map、DataObject或数据实体等),当然系统也支持用户传入复合对象,但必须和用户在加载单个命名SQL中定义的输入参数类型保持一致,并在主键字段上赋值。
- 多个主键:对于多主键情况,用户必须传入一个复合对象,对象的所有主键字段必须都赋值,符合对象的类型必须和加载单个命名SQL的输入参数一致(注意:不是和数据库字段名称保持一致)。
注意
命名SQL部署到应用服务器上后,必须重新启动应用或服务器,才可以生效,否则命名SQL的缓存无法使用。
# 命名SQL的一些开发案例
这里给出一些常用的命名SQL的开发示例,列举了单主键、多主键、不同输入、输出参数的场景。
- 使用java.util.HashMap作为输入、输出参数的命名SQL,加载单个数据和加载所有数据共用一个命名SQL。
<parameterMap class="java.util.HashMap" id="employeeMapInput">
<parameter javaType="String" jdbcType="varchar2" property="empId"/>
</parameterMap>
<resultMap class="java.util.HashMap" id="employeeMapResult">
<result column="empid" javaType="string" property="empId"/>
<result column="empname" javaType="string" property="empName"/>
<result column="birthday" javaType="java.sql.Date" property="birthday"/>
<result column="salary" javaType="float" property="salary"/>
<result column="gender" javaType="string" property="gender"/>
<result column="married" javaType="string" property="married"/>
<result column="fromcity" javaType="string" property="fromcity"/>
<result column="memo" javaType="string" property="memo"/>
</resultMap>
<select id="employeeSelectMap" parameterMap="employeeMapInput" resultMap="employeeMapResult">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
<isNotNull property="empId">
WHERE empid = #empId#
</isNotNull>
</select>
- 输入参数为字符串,输出参数为java.util.HashMap的命名SQL。
<resultMap class="java.util.HashMap" id="employeeMapResult">
<result column="empid" javaType="string" property="empId"/>
<result column="empname" javaType="string" property="empName"/>
<result column="birthday" javaType="java.sql.Date" property="birthday"/>
<result column="salary" javaType="float" property="salary"/>
<result column="gender" javaType="string" property="gender"/>
<result column="married" javaType="string" property="married"/>
<result column="fromcity" javaType="string" property="fromcity"/>
<result column="memo" javaType="string" property="memo"/>
</resultMap>
<select id="employeeSelectMapSimpleInputOne" parameterClass="java.lang.String" resultMap="employeeMapResult">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
WHERE empid = #value#
</select>
<select id="employeeSelectMapSimpleInputAll" resultMap="employeeMapResult">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
</select>
- 输入输出都是HashMap,多主键,并且加载单个数据和加载所有数据是分开的命名SQL。
<parameterMap class="java.util.HashMap" id="employeeMapInput2">
<parameter javaType="String" jdbcType="varchar2" property="empId"/>
<parameter javaType="java.util.Date" jdbcType="varchar2" property="birthday"/>
</parameterMap>
<resultMap class="java.util.HashMap" id="employeeMapResult2">
<result column="empid" javaType="string" property="empId"/>
<result column="empname" javaType="string" property="empName"/>
<result column="birthday" javaType="java.sql.Date" property="birthday"/>
<result column="salary" javaType="float" property="salary"/>
<result column="gender" javaType="string" property="gender"/>
<result column="married" javaType="string" property="married"/>
<result column="fromcity" javaType="string" property="fromcity"/>
<result column="memo" javaType="string" property="memo"/>
</resultMap>
<select id="employeeSelectAllMap" resultMap="employeeMapResult2">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
</select>
<select id="employeeSelectOneMap" parameterMap="employeeMapInput2" resultMap="employeeMapResult2">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
<isNotNull property="empId">
WHERE empid = #empId# and birthday=#birthday#
</isNotNull>
</select>
- 输入、输出参数是同一个Java类的命名SQL(com.primeton.mysample.vo.Employee是一个Java值对象)。
<parameterMap class="com.primeton.mysample.vo.Employee" id="employeeJavaInput">
<parameter javaType="String" jdbcType="varchar2" property="empId"/>
<parameter javaType="String" jdbcType="varchar2" property="empName"/>
</parameterMap>
<resultMap class="com.primeton.mysample.vo.Employee" id="employeeJavaResult">
<result column="empid" javaType="string" property="empId"/>
<result column="empname" javaType="string" property="empName"/>
<result column="birthday" javaType="java.sql.Date" property="birthday"/>
<result column="salary" javaType="float" property="salary"/>
<result column="gender" javaType="string" property="gender"/>
<result column="married" javaType="string" property="married"/>
<result column="fromcity" javaType="string" property="fromcity"/>
<result column="memo" javaType="string" property="memo"/>
</resultMap>
<select id="employeeSelectAllJava" resultMap="employeeJavaResult">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
</select>
<select id="employeeSelectOneJava" parameterMap="employeeJavaInput" resultMap="employeeJavaResult">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
<isNotNull property="empId">
WHERE empid = #empId# and empname=#empName#
</isNotNull>
</select>
- 输入、输出对象是通用数据对象commonj.sdo.DataObject的命名SQL。
<parameterMap class="commonj.sdo.DataObject" id="employeeSDOInput">
<parameter javaType="String" jdbcType="varchar2" property="empId"/>
<parameter javaType="String" jdbcType="varchar2" property="empName"/>
</parameterMap>
<resultMap class="commonj.sdo.DataObject" id="employeeSDOResult">
<result column="empid" javaType="string" property="empId"/>
<result column="empname" javaType="string" property="empName"/>
<result column="birthday" javaType="java.sql.Date" property="birthday"/>
<result column="salary" javaType="float" property="salary"/>
<result column="gender" javaType="string" property="gender"/>
<result column="married" javaType="string" property="married"/>
<result column="fromcity" javaType="string" property="fromcity"/>
<result column="memo" javaType="string" property="memo"/>
</resultMap>
<select id="employeeSelectSDO" parameterMap="employeeSDOInput" resultMap="employeeSDOResult">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
<isNotNull property="empId">
WHERE empid = #empId#
</isNotNull>
</select>
- 输入、输出参数是同一持久化数据实体的命名SQL(com.primeton.mysample.employee.TEmployee是一个持久化数据实体)。
<parameterMap class="com.primeton.mysample.employee.TEmployee" id="employeeEntityInput">
<parameter javaType="String" jdbcType="varchar2" property="empId"/>
<parameter javaType="float" jdbcType="varchar2" property="salary"/>
</parameterMap>
<resultMap class="com.primeton.mysample.employee.TEmployee" id="employeeEntityResult">
<result column="empid" javaType="string" property="empId"/>
<result column="empname" javaType="string" property="empName"/>
<result column="birthday" javaType="java.sql.Date" property="birthday"/>
<result column="salary" javaType="float" property="salary"/>
<result column="gender" javaType="string" property="gender"/>
<result column="married" javaType="string" property="married"/>
<result column="fromcity" javaType="string" property="fromcity"/>
<result column="memo" javaType="string" property="memo"/>
</resultMap>
<select id="employeeSelectEntity" parameterMap="employeeEntityInput" resultMap="employeeEntityResult">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
<isNotNull property="empId">
WHERE empid = #empId# and salary=#salary#
</isNotNull>
</select>
- 输入、输出参数是同一查询实体的命名SQL(com.primeton.mysample.employee.QEmployee是一个查询实体)。
<parameterMap class="com.primeton.mysample.employee.QEmployee" id="employeeEntityInput3">
<parameter javaType="String" jdbcType="varchar2" property="empName"/>
<parameter javaType="java.sql.Timestamp" jdbcType="varchar2" property="regDate"/>
</parameterMap>
<resultMap class="com.primeton.mysample.employee.QEmployee" id="employeeEntityResult3">
<result column="empid" javaType="string" property="empId"/>
<result column="empname" javaType="string" property="empName"/>
<result column="birthday" javaType="java.sql.Date" property="birthday"/>
<result column="salary" javaType="float" property="salary"/>
<result column="gender" javaType="string" property="gender"/>
<result column="married" javaType="string" property="married"/>
<result column="fromcity" javaType="string" property="fromcity"/>
<result column="memo" javaType="string" property="memo"/>
<result column="regdate" javaType="java.sql.Timestamp" property="regDate"/>
</resultMap>
<select id="employeeSelectEntity3" parameterMap="employeeEntityInput3" resultMap="employeeEntityResult3">
select empid,empname,birthday,salary,gender,married,fromcity,memo,regdate
from T_employee
<isNotNull property="empName">
WHERE empName = #empName# and regdate=#regDate#
</isNotNull>
</select>
- 输入参数是一个HashMap,输出参数是Java对象的命名SQL。
<parameterMap class="java.util.HashMap" id="employeeMapInput2">
<parameter javaType="String" jdbcType="varchar2" property="empId"/>
<parameter javaType="String" jdbcType="varchar2" property="empName"/>
</parameterMap>
<resultMap class="com.primeton.mysample.vo.Employee" id="employeeJavaResult">
<result column="empid" javaType="string" property="empId"/>
<result column="empname" javaType="string" property="empName"/>
<result column="birthday" javaType="java.sql.Date" property="birthday"/>
<result column="salary" javaType="float" property="salary"/>
<result column="gender" javaType="string" property="gender"/>
<result column="married" javaType="string" property="married"/>
<result column="fromcity" javaType="string" property="fromcity"/>
<result column="memo" javaType="string" property="memo"/>
</resultMap>
<select id="employeeSelectComplex" parameterMap="employeeMapInput2" resultMap="employeeJavaResult">
select empid,empname,birthday,salary,gender,married,fromcity,memo
from T_employee
<isNotNull property="empId">
WHERE empid = #empId# and empname=#empName#
</isNotNull>
</select>
# 逻辑流缓存开发
逻辑流缓存是通过开发加载单个数据和所有数据的逻辑流,并将逻辑流配置成缓存数据加载方式的缓存。由于逻辑流可以使用数据实体和基础构件库等工具,因此逻辑流开发比单纯开发底层的Java类更方便,而且比直接使用数据实体和命名SQL更灵活,所以使用逻辑流缓存是比较便捷且更灵活的缓存使用方式。
系统默认为这种缓存配置了CacheLoader,该CacheLoader只负责加载数据,不负责持久化数据。 逻辑流缓存如果配置成支持集群,集群的数据同步方式默认采用同步失效方式,以保证一个节点数据修改后,另一个节点的数据失效,用户请求时可以重新从数据库中加载数据。
# 逻辑流开发规则
开发用于缓存加载的逻辑流,用户必须开发加载单个数据的逻辑流和加载所有数据的逻辑流,并指定返回的数据类型,并且需要遵守一定的规则。
- 加载单个数据的逻辑流
- 逻辑流必须且只能定义一个输入参数,需要和用户的定义的返回数据类型保持一致。
- 逻辑流的返回参数只能且必须返回一个对象,需要和用户定义的返回数据类型保持一致。
- 用户使用ICache的get(Object key),或基础构件库的CacheUtil的getValue(String cacheName, Object key)中的key输入参数必须和逻辑流定义的输入参数类型保持一致。
- 加载所有数据的逻辑流
- 不能定义输入参数。
- 逻辑流的输出参数只能是用户定义返回数据类型的List、Set、Map集合或数组。
- 单主键和多主键的使用:用户可以使用缓存基础构件库的com.eos.foundation.eoscommon.CacheUtil.getValue(String cacheName, Objec key)从缓存中取数据,分为单主键和多主键两个使用场景。
- 单一主键:key参数只需要传入一个String或数值(支持int、long、float、double及其封装对象)、Date(日期或时间戳)对象即可,用户不需要构造一个输入对象,当然系统也支持用户传入复合对象,但必须和用户定义的返回数据类型保持一致,并且必须在主键字段上赋值。
- 多个主键:对于多主键情况,用户必须传入定义的数据类型的一个实例,且对象的所有主键字段必须都赋值。
# 逻辑流缓存的配置
下面是一个逻辑流缓存的配置例子:
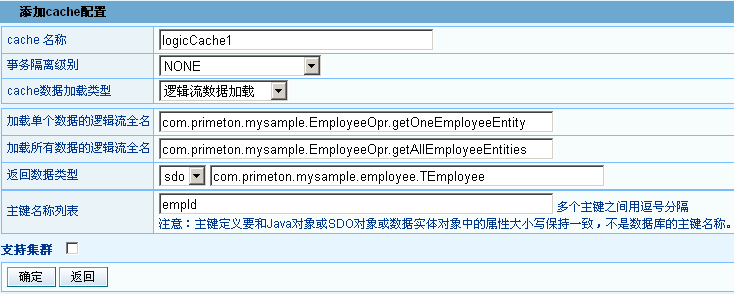
# 自定义CacheLoader
自定义CacheLoader是最灵活,但较为复杂的一种缓存的开发方式,CacheLoader主要用于加载数据,并在数据更改后进行持久化。
# 开发CacheLoader
CacheLoader需要实现com.eos.common.cache.ICacheLoader接口,下面是一个自定义的CacheLoader例子(为了简化起见,没有写任何加载数据的逻辑,这些逻辑可以由读者补充)。
package com.primeton.mysample;
import java.util.Map;
import com.eos.common.cache.ICacheLoader;
public class MyCacheLoader implements ICacheLoader {
public Object get(Object key) {
System.out.println("get("+key+")");
return null;
}
public Map preLoad() {
System.out.println("preLoad");
return null;
}
public void put(Object key, Object value) {
System.out.println("put("+key+","+value+")");
}
public Object remove(Object key) {
System.out.println("remove("+key+")");
return null;
}
}
# 配置缓存
在EOS控制台可以按下图配置缓存:

由于是自定义CacheLoader,用户可以选择是否加载数据或是否持久化数据,所以这种缓存最灵活,可以满足复杂的应用场景。这种缓存的集群数据同步模式也不限于失效方式,用户可以采取异步复制、同步复制等其他数据同步方式。
# Redis
EOS缓存还支持使用Redis作为缓存实现,需要设置:
- 在pom.xml里增加redis的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 在application.properties里增加redis的设置
spring.redis.host=10.15.15.51
spring.redis.port=6379
spring.redis.database=0
设置完成后,所有使用ICache的接口的缓存,默认都是使用Redis作为缓存实现,如果不想所有缓存都使用这种方式,可以在application.properties里设置
eos.cache.mode=map
eos.cache.$CACHE_NAME.mode=map
eos.cache.mode: 指定所有Cache的默认实现,可选值: map, redis eos.cache.$CACHE_NAME.mode: 指定某一个Cache的实现,可选值: map, redis 注意:$CACHE_NAME变量需要替换成具体的值
# 接口及方法说明
# 包含的类
# 类的方法
# com.eos.common.cache.CacheProperty
类的说明 Cache配置属性信息。
类的方法
| 方法 | 说明 |
|---|---|
| String getCacheName() | 取得Cache名称 |
| void setCacheName(String cacheName) | 设定Cache名称 |
| String getCacheProvider() | 取得CacheProvide |
| void setCacheProvider(String cacheProvider) | 设定CacheProvide |
| String getCacheLoader() | 取得CacheLoader |
| void setCacheLoader(String cacheLoader) | 设定CacheLoader |
| Boolean getClustered() | 是否集群模式 |
| void setClustered(Boolean clustered) | 设定集群模式标志 |
| CacheClusterProperty getClusterProperty() | 取得集群配置属性 |
| void setClusterProperty(CacheClusterProperty clusterProperty) | 设定集群配置属性 |
| Properties getOtherProperties() | 取得Cache其他属性 |
| void setOtherProperties(Properties cacheProp) | 设定Cache其他属性 |
| CacheProperty clone() | 深度克隆 |
# com.eos.common.cache.ICache
类的说明 Cache定义接口。
类的方法
| 方法 | 说明 |
|---|---|
| String getCacheName() | 取得Cache名称 |
| int size() | 获取CACHE大小 |
| boolean isEmpty() | 判断是否空 |
| boolean containsKey(Object key) | 是否包含指定键 |
| boolean containsValue(Object value) | 是否包含指定值 |
| V get(Object key) | 取值(如果用户实现了CacheLoader,并配置,如果Cache中没有key,则会调用CacheLoader的get方法) |
| void put(K key, V value) | 存值(如果是集群模式,则同步其他节点下的Cache) |
| void putAll(Map<? extends K, ? extends V> t) | 存入一组键值对(如果是集群模式,则同步其他节点下的Cache) |
| V remove(Object key) | 移除某一个key-value(如果是集群模式,则同步其他节点下的Cache) |
| void clear() | 清空(只是清空当前Cache,如果是集群模式,则不会同步其他节点下的Cache) |
| Set<K> keySet() | 取得Key集合 |
| String getCacheType() | 取得实现cache的内部存储器类全名 |
| CacheProperty getCacheConfig() | 获取创建cache的配置信息 |
| ICacheLoader<K, V> getCacheLoader() | 获取此Cache的CacheLoader实例 |
# com.eos.common.cache.ICacheLoader
类的说明 Cache加载器定义接口。
类的方法
| 方法 | 说明 |
|---|---|
| Map<K, V> preLoad() | 预加载,Cache初始数据 |
| V get(Object key) | 从数据来源中取得key对应的值 |
| void put(K key, V value) | 设定数据来源的值 |
| V remove(Object key) | 删除数据来源中的值 |
# com.eos.common.cache.CacheFactory
类的说明 Cache管理工厂。
类的方法
| 方法 | 说明 |
|---|---|
| ICache<?, ?> createCache(CacheProperty cacheConfig) throws CacheRuntimeException | 程序根据相关参数创建Cache |
| ICache<?, ?> createCache(CacheProperty cacheConfig, boolean persistentFlag) throws CacheRuntimeException | 程序根据相关参数创建Cache |
| ICache<?, ?> findCache(String cacheName) | 查找指定的Cache |
| void destroyCache(String cacheName) | 销毁某一个Cache |
| void destroyCache() | 销毁所有Cache |
| boolean exists(String cacheName) | 查看指定名称的Cache是否创建过 |
| Set<String> keySet() | 获取已经创建所有Cache名称列表 |
# com.eos.common.cache.CacheUtil
类的说明 Cache操作类,可以很方便地创建用户缓存、查找缓存、销毁缓存、获取缓存的所有key和value等。
类的方法
| 方法 | 说明 |
|---|---|
| 方法 | 说明 |
| public static ICache<?,?> createBizLogicCache( String cacheName, boolean isClustered, String clusterName, String loadAllBizFqn, String loadOneBizFqn, String dataType,String primaryKeyNames) | 创建逻辑流缓存 |
| public static ICache<?,?> createNamingSqlCache( String cacheName, boolean isClustered, String clusterName, String dataSourceName, String loadAllSqlID,String loadOneSqlID, String primaryKeyNames) | 创建命名SQL缓存 |
| public static ICache<?,?> createDataEntityCache( String cacheName, boolean isClustered, String clusterName, String dataSourceName, String dataEntityQName) | 创建数据实体缓存 |
| public static ICache findCache(String cacheName) | 通过缓存的名称查找缓存实例 |
| public static void destroyCache(String cacheName) | 通过缓存名称销毁一个缓存 |
| public static Set<?> getAllKeys(String cacheName) | 返回缓存的所有Key |
| public static List<?> getAllValues(String cacheName) | 返回缓存的所有值 |