# LocalFile Sink组件使用说明
# 组件说明
LocalFile Sink 连接器用于将数据写入本地文件系统。
# 配置项说明
| 配置名称 | 数据类型 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|
| 节点名称 | String | 是 | LocalFile | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。确保唯一性。 |
| 节点编码 | String | 是 | 自动生成 | 当前创建的节点编码,以此标识此组件,由用户自定义且不可为空。命名可包含字母、数字、下划线。确保唯一性。 |
| 输出路径 | String | 是 | - | 目标文件路径。 |
| 自定义文件名 | Boolean | 否 | 否 | 若选择"是"时,需要配置"文件表达式"和"文件名时间格式"。 |
| 是否启用事务 | Boolean | 是 | 是 | 是否启用 2PC 事务保证 exactly-once。 |
| 文件表达式 | String | 是 | ${transactionId} | 文件名表达式。支持${now}、${uuid}。启用事务时自动加${transactionId}_前缀。 |
| 文件名时间格式 | String | 是 | yyyy.MM.dd | ${now}变量的时间格式 |
| 文件类型 | String | 否 | - | 支持:text、csv、parquet、orc、json、excel、xml、binary 八种文件类型。 |
| sheet名称 | String | 否 | Sheet${随机数} | 工作表名称。文件类型是 excel 时填写。 |
| 最大缓存行 | Int | 否 | 100 | 内存中最大缓存行数。文件类型是 excel 时填写。 |
| XML根标签 | String | 否 | RECORDS | 根标签名。文件类型是 xml 时填写。 |
| XML行标签 | String | 否 | RECORD | 行标签名。文件类型是 xml 时填写。 |
| 是否使用属性格式 | Boolean | 否 | 是否使用标签属性。文件类型是 xml 时填写。 | |
| 压缩算法 | String | 否 | - | 支持文件的压缩算法: - txt: lzo、none; - json: lzo、none; - csv: lzo、none; - orc: lzo、snappy、lz4、zlib、none; - parquet: lzo、snappy、lz4、gzip、brotli、zstd、none; - excel / xml:不支持任何压缩算法。 |
| 添加头部行 | Boolean | 否 | - | 是否写入表头。当"是否分区"为 "是" 时使用。如果设置为"是",则分区字段及其值将写入数据文件。 |
| 字段分隔符 | String | 否 | - | 数据行中列之间的分隔符。仅文本文件格式需要。 - text / csv:\001(Hive默认) |
| 行分隔符 | String | 否 | - | 文件中行之间的分隔符。仅文本文件格式需要。 - text / csv:\n |
| 写入字段 | List | 否 | - | 哪些列需要写入文件,默认值是从"转换"或"数据源"获取的所有列。字段的顺序决定了文件实际写入的顺序。 |
| 是否分区 | Boolean | 否 | 否 | 是否需要处理分区。默认为"否"。 |
| 分区字段 | String | 否 | - | 当"是否分区"为 "是" 时使用。根据所选字段对数据进行分区。 |
| 分区目录表达式 | Boolean | 否 | false | 当"是否分区"为 "是" 时使用。如果指定了"分区字段",将根据分区信息生成相应的分区目录,最终文件将放置在分区目录中。默认"分区目录表达式"为${k0}=${v0}/${k1}=${v1}//${kn}=${vn}/。k0是第一个分区字段,v0是第一分区字段的值。 |
| 分区字段及其值是否写入文件 | Boolean | 否 | 否 | 当"是否分区"为 "是" 时使用。如果"分区字段及其值是否写入文件"为"是",则分区字段及其值将写入数据文件。例如,如果要编写配置单元数据文件,其值应为"否"。 |
| 批次大小 | Int | 否 | 1000000 | 文件中的最大行数。对于 SeaTunnel Engine,文件中的行数由batch_size和checkpoint.interval共同决定。如果checkpoint.interval的值足够大,则接收器写入程序将在文件中写入行,直到文件中的行大于batch_size。如果checkpoint.interval很小,则当触发新的检查点时,接收器写入程序将创建一个新文件。 |
| 可选参数 | Map | 否 | - | 其他参数,用户可以根据需求进行配置。 |
# 格式与分隔符
| 配置项名称 | 数据类型 | 默认值 | 适用格式 | 说明 |
|---|---|---|---|---|
| 字段分隔符 | string | \001 | text/csv | 列分隔符 |
| 行分隔符 | string | \n | text/csv | 行分隔符 |
| 添加头部行 | boolean | 否 | text/csv | 是否写入表头 |
# FAQ
Q:设置了file_format_type = "json",为什么写出的还是文本表格?
A:请检查参数名。SeaTunnel 2.3.0+必须使用file_format_type,老参数fileFormat或file_format已失效 。
Q:文件没有按照partition_by生成目录?
A:2.3.0+需同时设置have_partition = true。老版本直接使用partition_by即可 。
Q:如何保证数据不丢不重?
A:保持is_enable_transaction = true(默认)。数据先写入tmp_path,checkpoint成功时原子化mv到目标路径 。
Q:Excel写入很慢/内存溢出?
A:调小max_rows_in_memory,或增大batch_size减少文件切换频率 。
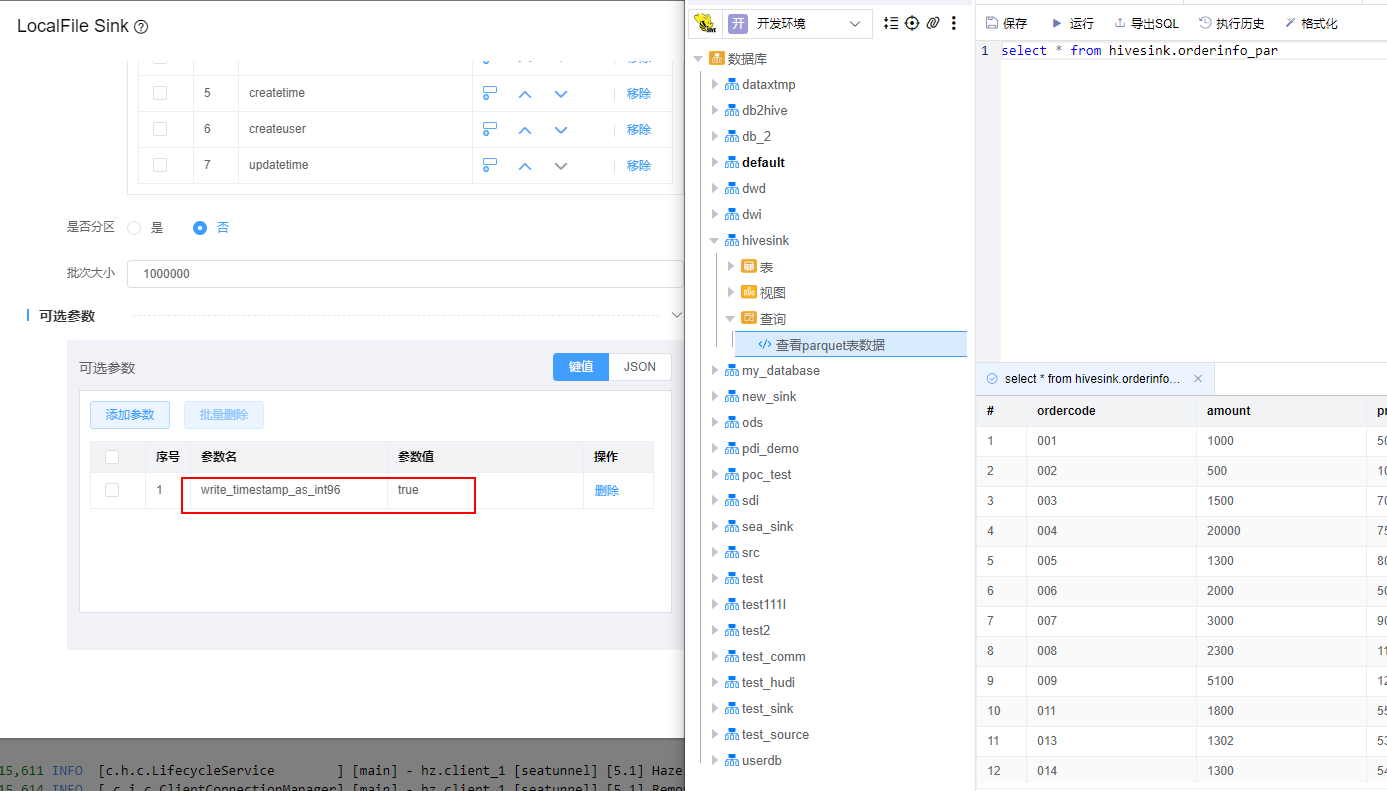
Q: 使用LocalFile Sink输出parquet类型的文件,其中有字段类型是timestamp。作业运行成功,将输出的文件放到parquet类型对应结构的表下查询时报错: java.io.IOException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.ClassCastException: org.apache.hadoop.io.IntWritable cannot be cast to org.apache.hadoop.hive.serde2.io.TimestampWritable,应该怎么处理?
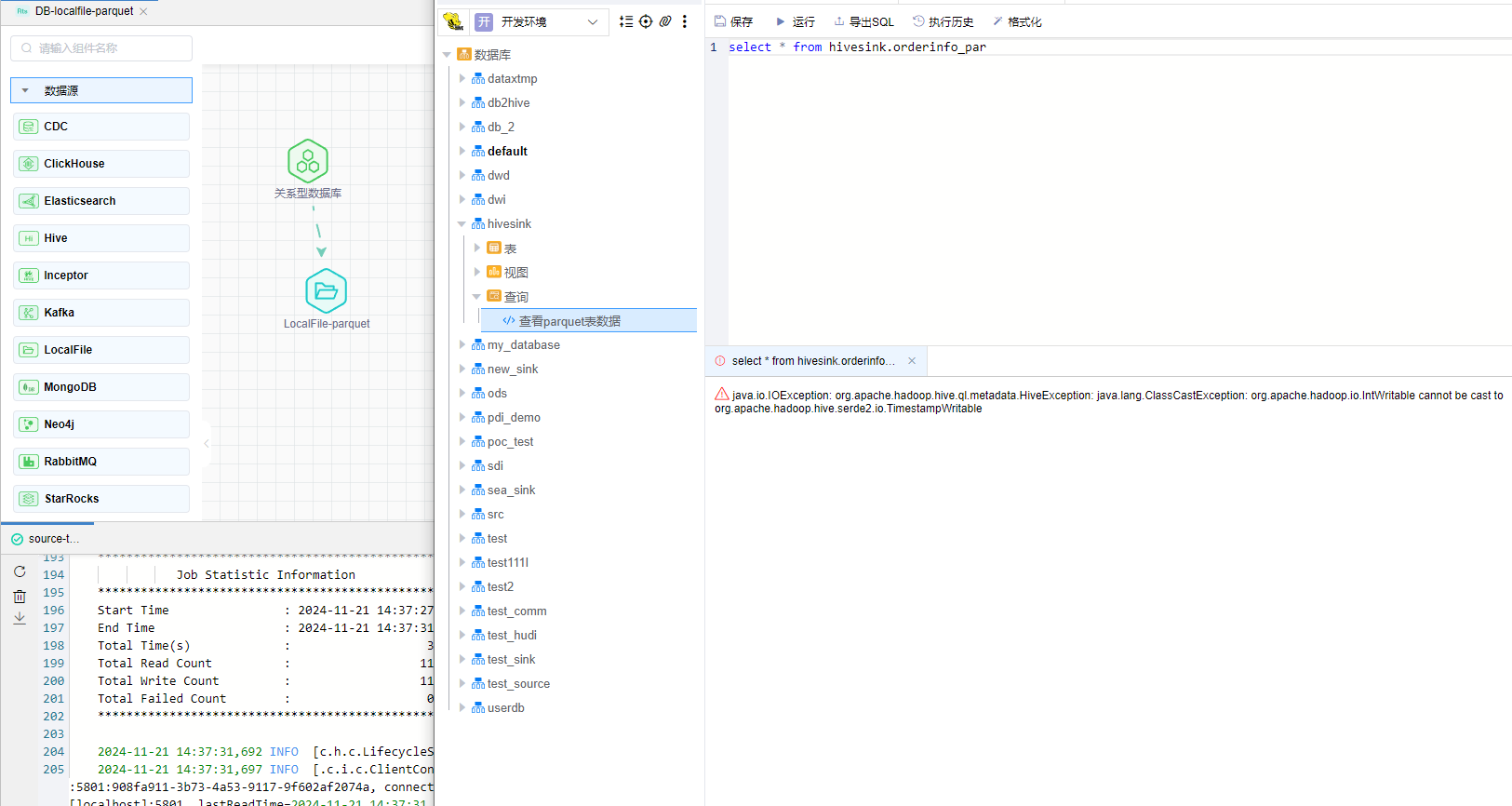
A: 实时组件 LocalFile Sink,使用parquet格式,时间戳timestamp类型需要配置:write_timestamp_as_int96=true