# Kafka Sink组件使用说明
使用示例
# 组件说明
Kafka Sink 用于将数据行写入 Kafka Topic,并默认通过两阶段提交(2PC)保证“Exactly Once”语义。
# 配置项说明
| 配置名称 | 数据类型 | 是否必填 | 默认值 | 描述 |
|---|---|---|---|---|
| 节点名称 | String | 是 | Kafka | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。确保唯一性。 |
| 节点编码 | String | 是 | 自动生成 | 当前创建的节点编码,以此标识此组件,由用户自定义且不可为空。命名可包含字母、数字、下划线。确保唯一性。 |
| 选择数据源 | String | 是 | - | 从下拉选项中选择列出的当前项目已经关联的数据源。 |
| 主题名称 | String | 是 | - | 填写主题名称。 |
| 消息投递语义 | String | 是 | NON | 消息投递语义支持三种:NON、EXACTLY_ONCE、AT_LEAST_ONCE。 EXACTLY_ONCE,生产者将在 Kafka 事务中写入所有消息,这些消息将在检查点上提交给 Kafka。 AT_LEAST_ONCE,生产者将等待 Kafka 缓冲区中所有未完成的消息被 Kafka 生产者在检查点上确认。 NON 不提供任何保证:如果 Kafka 代理出现问题,消息可能会丢失,并且消息可能会重复。 |
| 使用消息分区策略 | Boolean | 是 | 否 | 分为两种,指定分区和分配分区。 |
| 指定分区 | String | 否 | - | 固定写入指定分区,所有消息都会发送到这个分区。 |
| 分配分区 | String | 否 | - | 可以根据消息的内容来决定发送哪个 partition。该参数的作用是分发信息。 比如一共有五个分区,config中的assign_partitions字段如下:assign_partitions = ["shoe", "clothing"] 然后包含“shoe”的消息将被发送到分区0,因为“shoe”在assign_partitions中被订阅为0,而包含“clothing”的消息将被发送到分区1。对于其他消息,将使用哈希算法来将它们分成剩余的分区。 这个函数按MessageContentPartitioner类实现了org.apache.kafka.clients.producer.Partitioner接口。如果我们需要自定义分区,我们也需要实现这个接口。 ⚠️ 当“分区“、”分配分区字段“ 配置项同时设置时,消息发送到那个分区,以”分区“配置项设置的分区为准,所有消息都会发送到”分区“配置项所指定的那个分区。 ⚠️ 当没有设置 “分区“ 配置项时,设置”分配分区“ 才会生效。 |
| 键取值列 | String | 否 | - | 配置哪些字段作为 kafka 消息的 key。如果你想使用来自上游数据的字段值作为键,你可以为这个属性分配字段名称。 如果未设置分区键字段,则将发送空消息键。 消息 key 的格式为 json,如果 key 设置为 name,例如'{"name":"Jack"}'。 所选字段必须是上游中的现有字段。 |
| 数据格式 | String | 是 | json | 数据格式支持:json、text、canal_json、debezium_json、maxwell_json、ogg_json、avro、protobuf。默认格式为 json。默认的字段分隔符是","。如果自定义分隔符,请添加“字段分隔符”选项。 如果使用 canal 格式,请参考 canal-json (opens new window) 了解详细信息。如果使用 debezium 格式,请参考 debezium-json (opens new window)。一些Format的详细信息请参考 formats (opens new window) |
| 可选参数 | Map | 否 | - | 可以根据需求进行配置。可选参数名称可以参考 Seatunnel 官方手册。 json 格式如: { "kafka.config": "{ "acks" :"all", "request.timeout.ms": 60000, "buffer.memory": 33554432 }" } |
# FAQ
Q:是否支持动态Topic?
A:支持。使用topic = "${field_name}"语法,从上游数据提取字段值作为Topic名 。
Q:如何保证不丢数据?
A:推荐配置semantics = EXACTLY_ONCE + kafka.acks = "all" + transaction_prefix唯一前缀。注意:事务会有性能开销 。
Q:partition_key_fields 和 assign_partitions 冲突吗?
A:不冲突。partition_key_fields决定消息Key,assign_partitions是一种自定义分区器实现。若同时指定,以assign_partitions分区策略为准 。
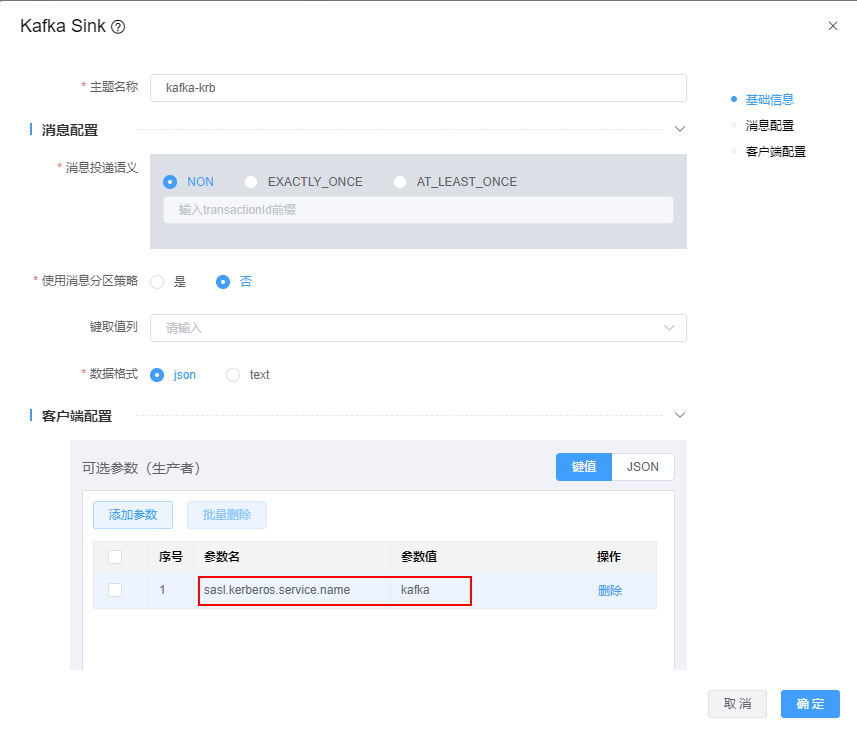
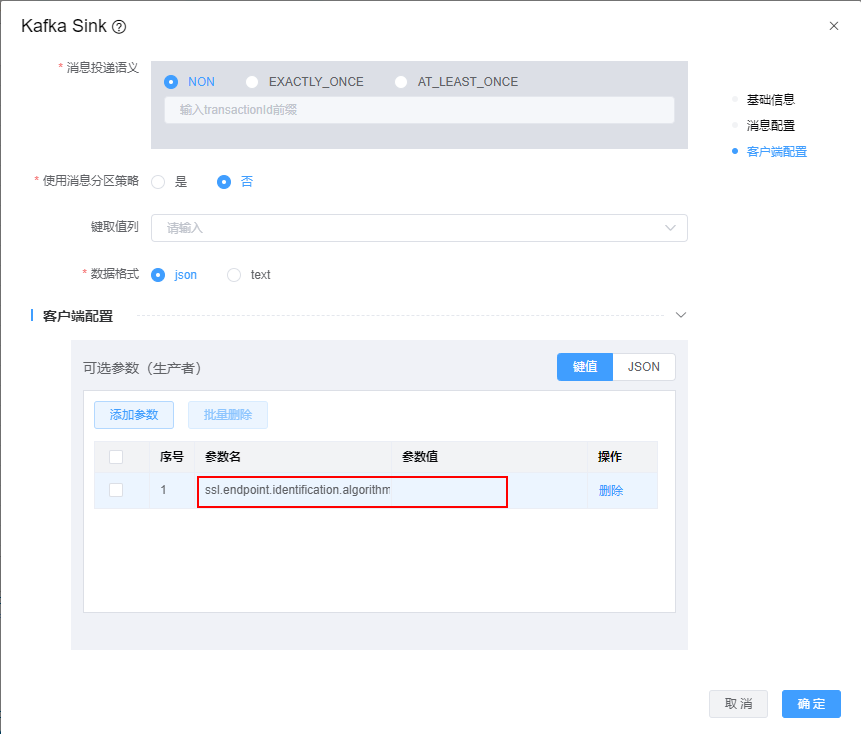
Q: kafka使用SSL认证或者kerberos认证时,模型应该怎么配置?
A: 当kafka使用认证后,还需要在可选参数中做如下配置
kafka使用SSL认证,增加参数 ssl.endpoint.identification.algorithm =
kafka使用kerberos认证,增加参数 sasl.kerberos.service.name= kafka