
# 目标
本章节详细说明目标组件的功能及属性,具体如下:
# ClickHouse
功能介绍:ClickHouse Sink 连接器。用于将数据写入 ClickHouse。
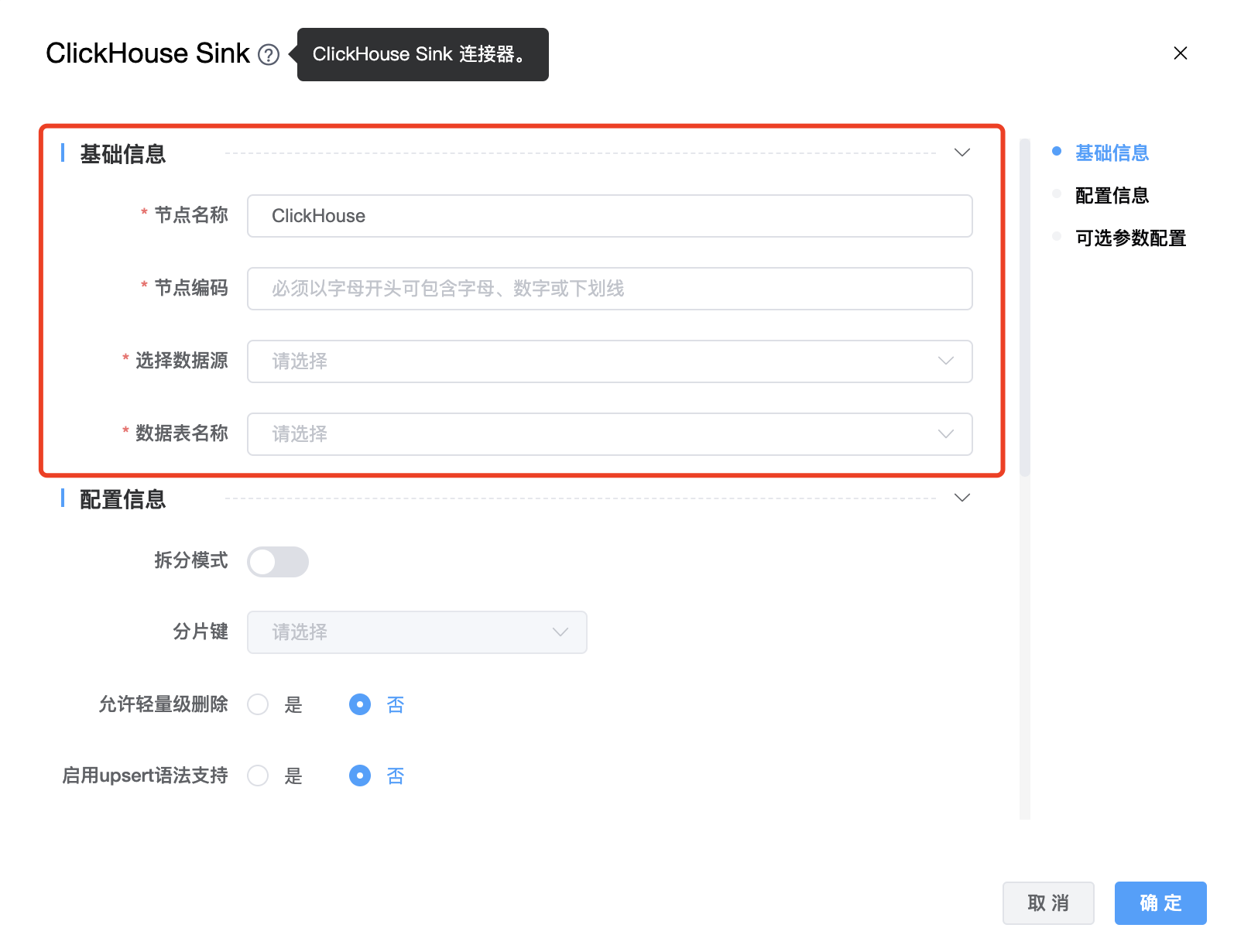
组件界面:
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 ClickHouse Sink 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 ClickHouse Sink 节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | ClickHouse Sink 的数据源名称,从下拉选项中列出的当前项目已经关联的 ClickHouse 数据源进行选择。 |
| 数据表名称 | ClickHouse Sink 的数据表名称。 |
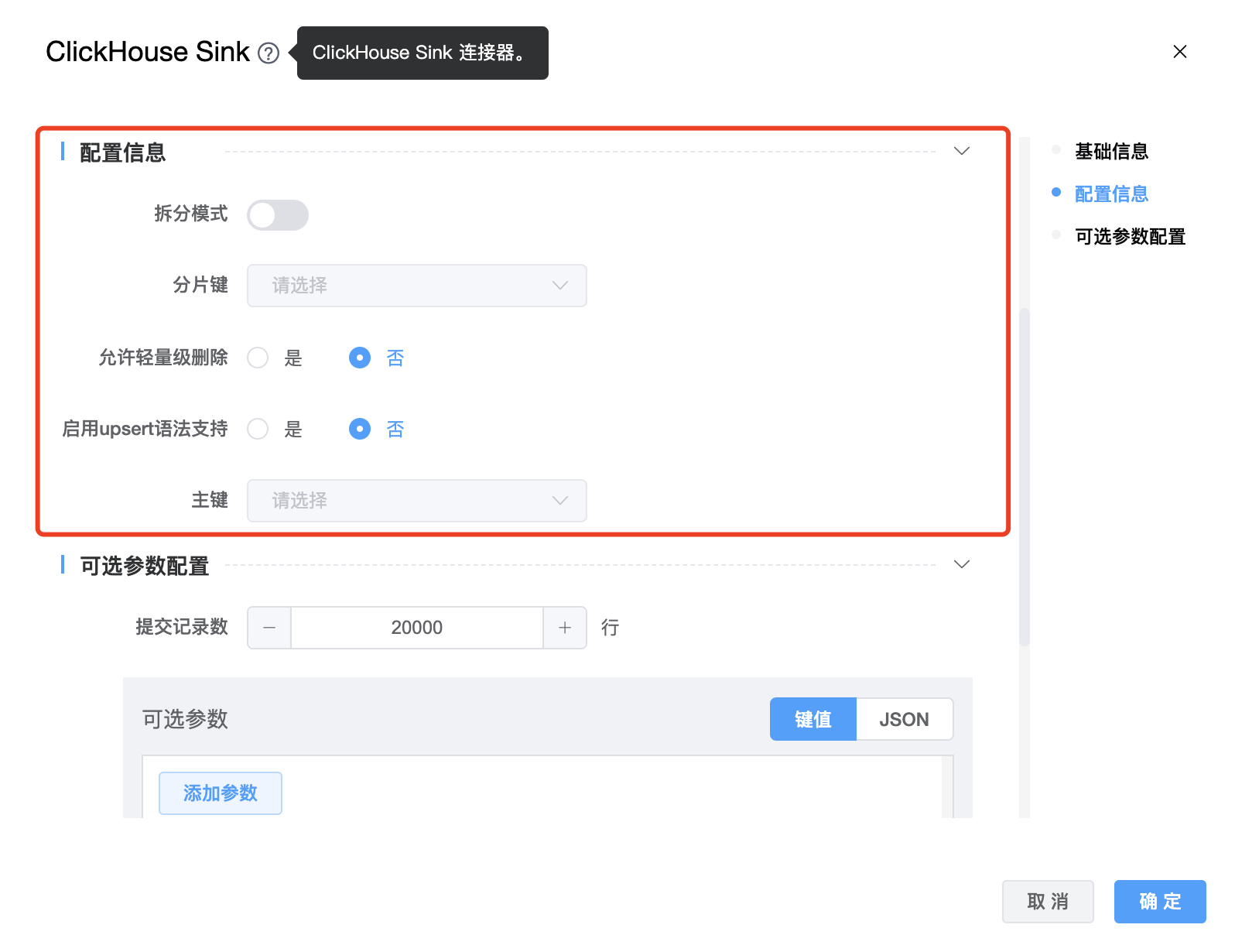
| 拆分模式 | boolean 类型,启用(true),默认禁用(false)。此模式仅支持引擎为:“Distributed”的 ClickHouse 表并且 internal_replication 选项为 true。它将会在 seatunnel 中拆分引擎为“Distributed”的表数据,并直接在每个分片上执行写操作。分片权重定义为 ClickHouse 将被计算在内。 |
| 分片键 | 此选项仅在“拆分模式”为 true 时有效。启用拆分模式时,向哪个节点发送数据是个问题,默认是随机选择,但可以使用“分片键”参数指定分片算法的字段。 |
| 允许轻量级删除 | 默认false。允许基于 MergeTree 表引擎的实验性轻量级删除。轻量级删除原理参见:https://blog.csdn.net/weixin_39992480/article/details/128462618 |
| 启用 upsert 语法支持 | boolean 类型,默认为 false。UPSERT 是 INSERT 与 UPDATE 的结合体,表示行存在时执行 UPDATE,不存在时执行 INSERT。执行 UPSERT 时必须要指定完全的 PRIMARY KEY 的相关列信息。 |
| 主键 | 标记 ClickHouse 表的主键列,并根据主键对 ClickHouse 表执行INSERT/UPDATE/DELETE |
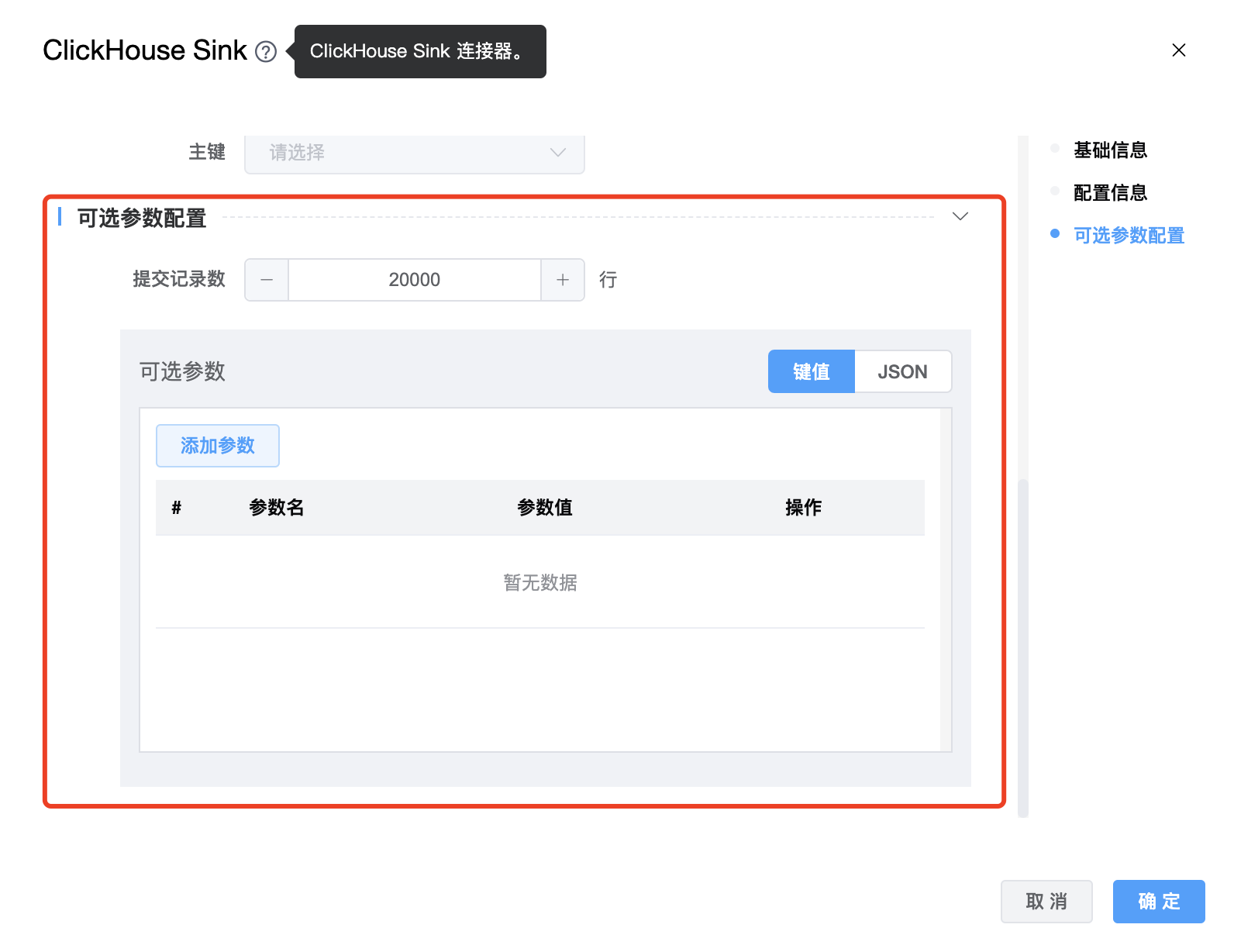
| 提交记录数 | 每次通过 ClickHouse Jdbc 写入的行数,默认值:20000。 |
| 可选参数 | ClickHouse Sink 的其他参数,用户可以根据需求进行配置。 |
目前可选参数可配置
clickhouse.config: 用户可以指定多个可选参数,这些参数涵盖了clickhouse-jdbc提供的所有参数。如:{ "clickhouse.config": { "max_rows_to_read": "100", "read_overflow_mode": "throw" } }
# Elasticsearch
功能介绍:Elasticsearch Sink 连接器。用于将数据写入 Elasticsearch。
组件界面:
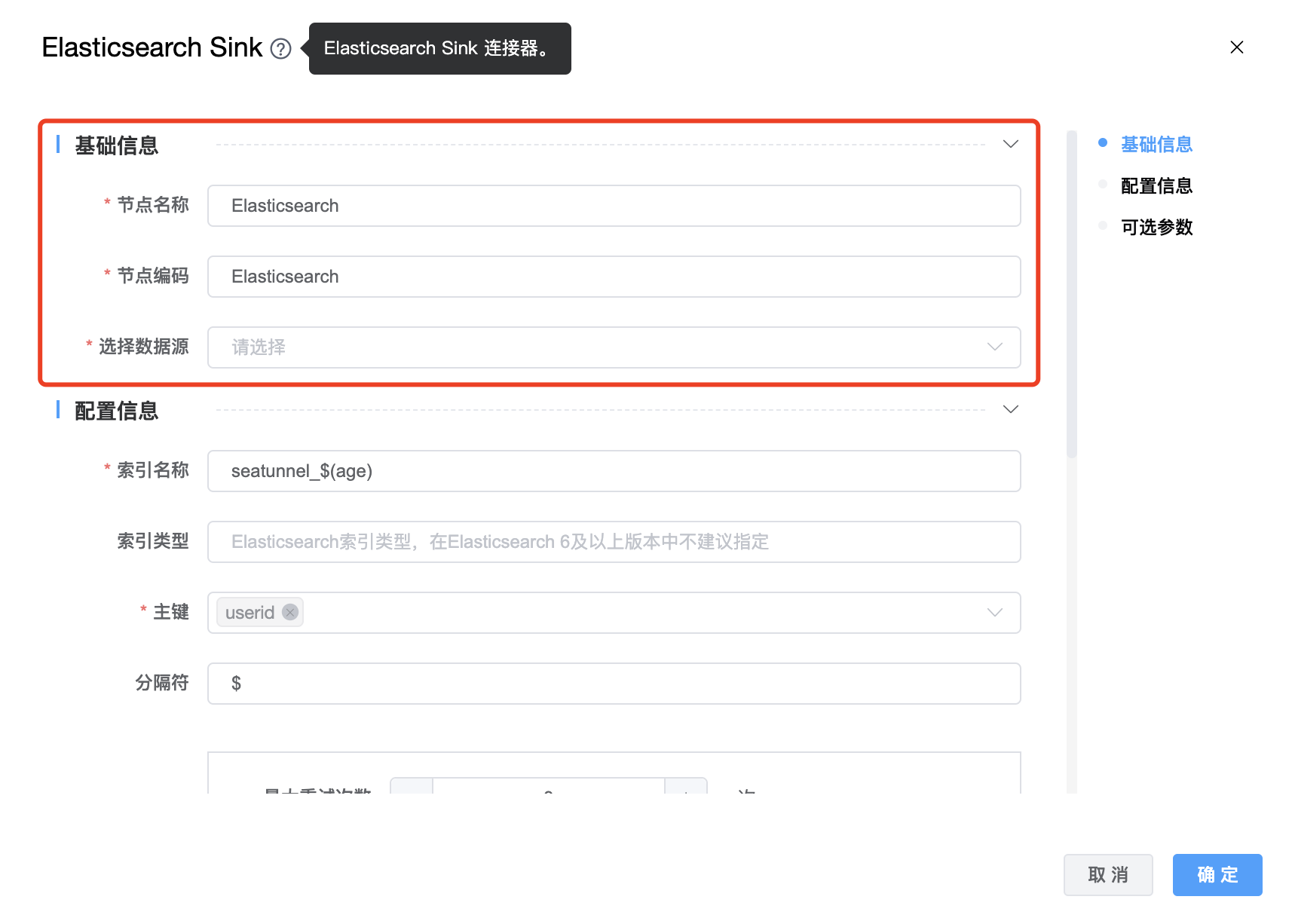
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 Elasticsearch Sink 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 Elasticsearch Sink 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | Elasticsearch Sink 的数据库名称,从下拉选项中列出的当前项目已经关联的 Elasticsearch 数据源进行选择。 |
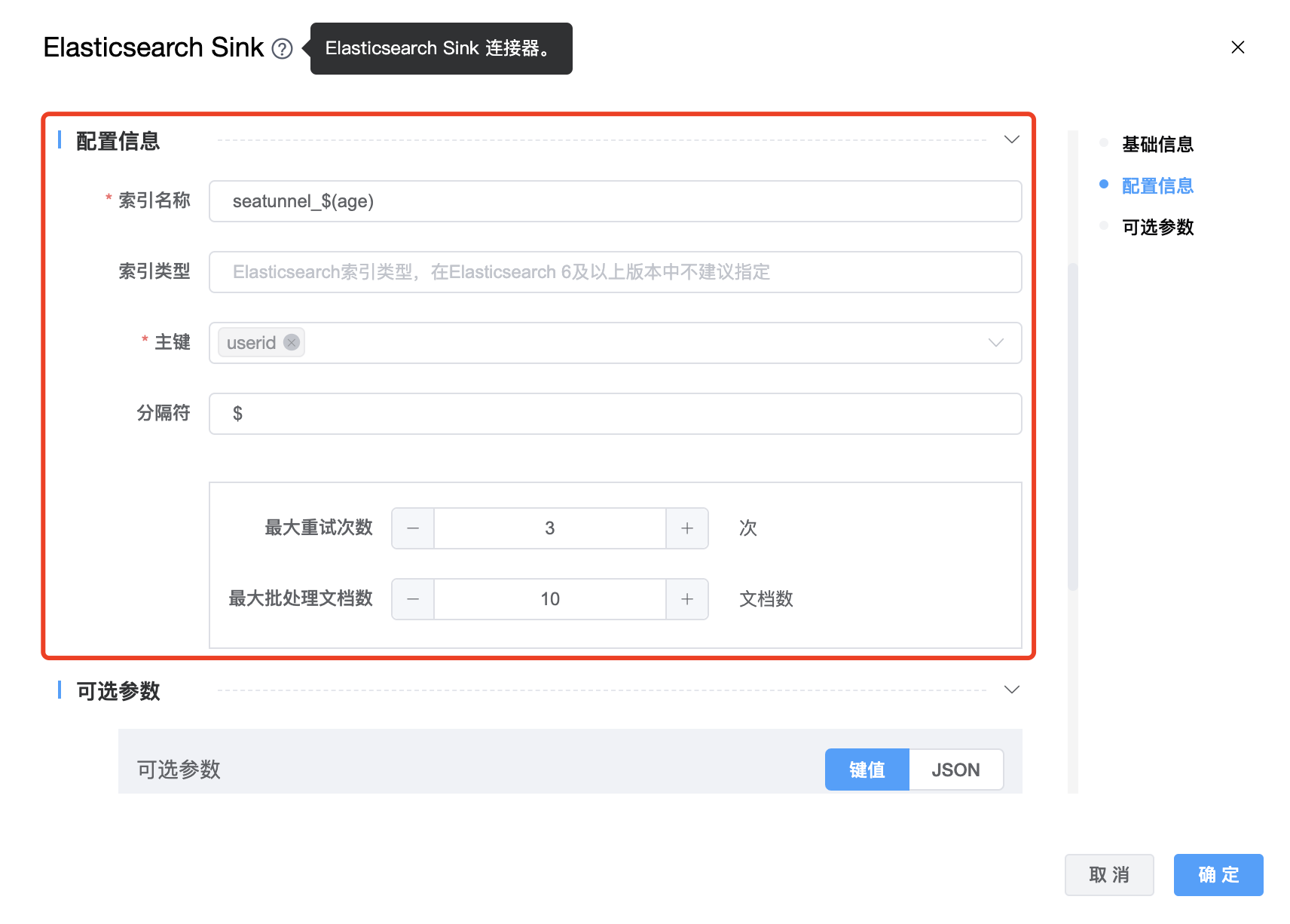
| 索引名称 | Elasticsearch 索引名称,支持 * 模糊匹配。索引名称必须是小写的,不能用下划线开头,不能包含逗号,例如:seatunnel_${age} |
| 索引类型 | 在Elasticsearch 6及以上版本中不建议指定。 |
| 主键 | 用于生成 document _id 的主键字段,这是 cdc 必需的选项。 |
| 分隔符 | 复合键的分隔符(默认为“_”),例如,以“$”为分隔符,document _id 的结果:“KEY1$KEY2$KEY3”。 |
| 最大重试次数 | 请求的最大重试次数 |
| 最大批量处理文档数 | 最大批量处理文档的大小。 |
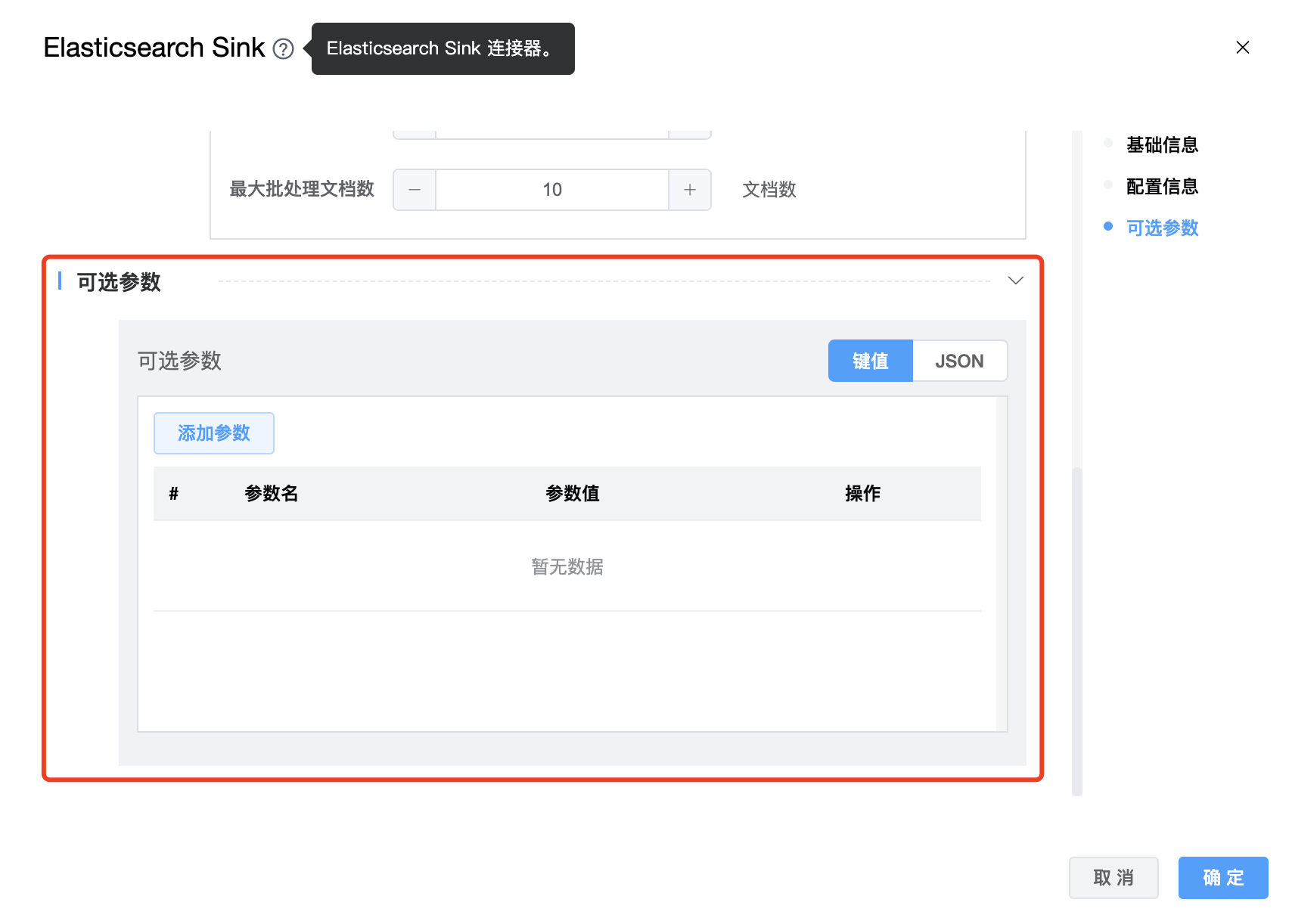
| 可选参数 | Elasticsearch Sink 的其他参数,用户可以根据需求进行配置。 |
目前可选参数可配置如下:schema_save_mode、data_save_mode
schema_save_mode参数值如下:
- RECREATE_SCHEMA:当索引不存在时,将创建索引;当索引已存在时,将删除原索引并重新创建。
- CREATE_SCHEMA_WHEN_NOT_EXIST:当索引不存在时,将创建索引;当索引已存在时,跳过创建步骤。
- ERROR_WHEN_SCHEMA_NOT_EXIST:当索引不存在时,将报告错误。
data_save_mode参数值如下:
- DROP_DATA:删除数据
- APPEND_DATA:追加数据
- ERROR_WHEN_DATA_EXISTS:数据存在时报告错误
# Kafka
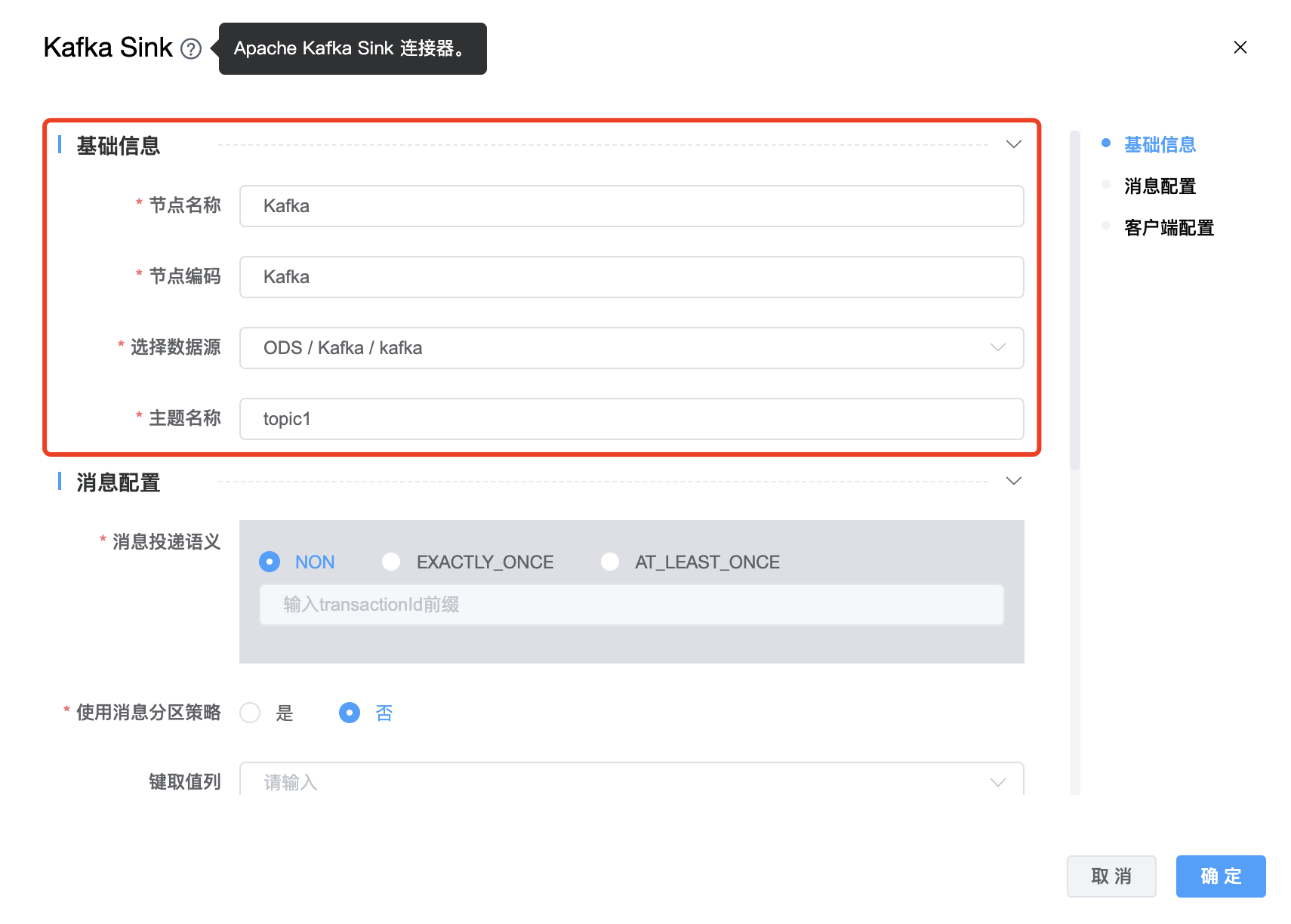
功能介绍: Kafka Sink 连接器。用于将数据写入 Kafka。
组件界面:

参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 Kafka Sink 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 Kafka Sink 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | Kafka Sink 的数据库名称,从下拉选项中列出的当前项目已经关联的 Kafka 数据源进行选择。 |
| 主题名称 | Kafka Topic 名称。如果有多个 topics,使用英文符号"," 进行拆分,例如:"tpc1,tpc2" |
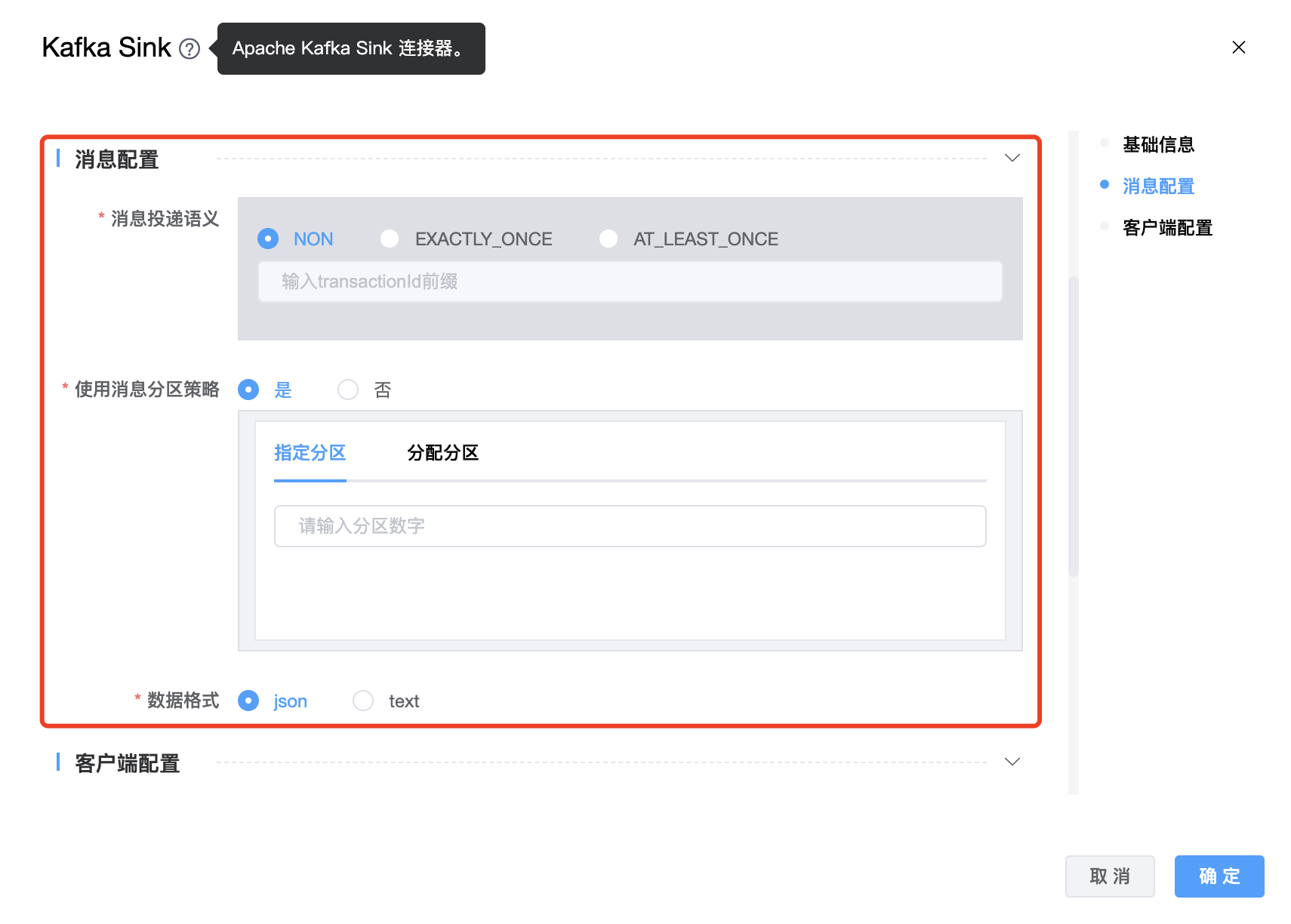
| 消息投递语义 | 消息投递语义支持三种:NON、EXACTLY_ONCE、AT_LEAST_ONCE,默认 NON。 EXACTLY_ONCE,生产者将在 Kafka 事务中写入所有消息,这些消息将在检查点上提交给 Kafka。 AT_LEAST_ONCE,生产者将等待 Kafka 缓冲区中所有未完成的消息被 Kafka 生产者在检查点上确认。 NON 不提供任何保证:如果 Kafka 代理出现问题,消息可能会丢失,并且消息可能会重复。 |
| 键取值列 | 配置哪些字段作为 kafka 消息的 key。如果你想使用来自上游数据的字段值作为键,你可以为这个属性分配字段名称。 如果未设置分区键字段,则将发送空消息键。 消息 key 的格式为 json,如果 key 设置为 name,例如'{"name":"Jack"}'。 所选字段必须是上游中的现有字段。 |
| 指定分区 | 可以指定分区,所有消息都会发送到这个分区。 |
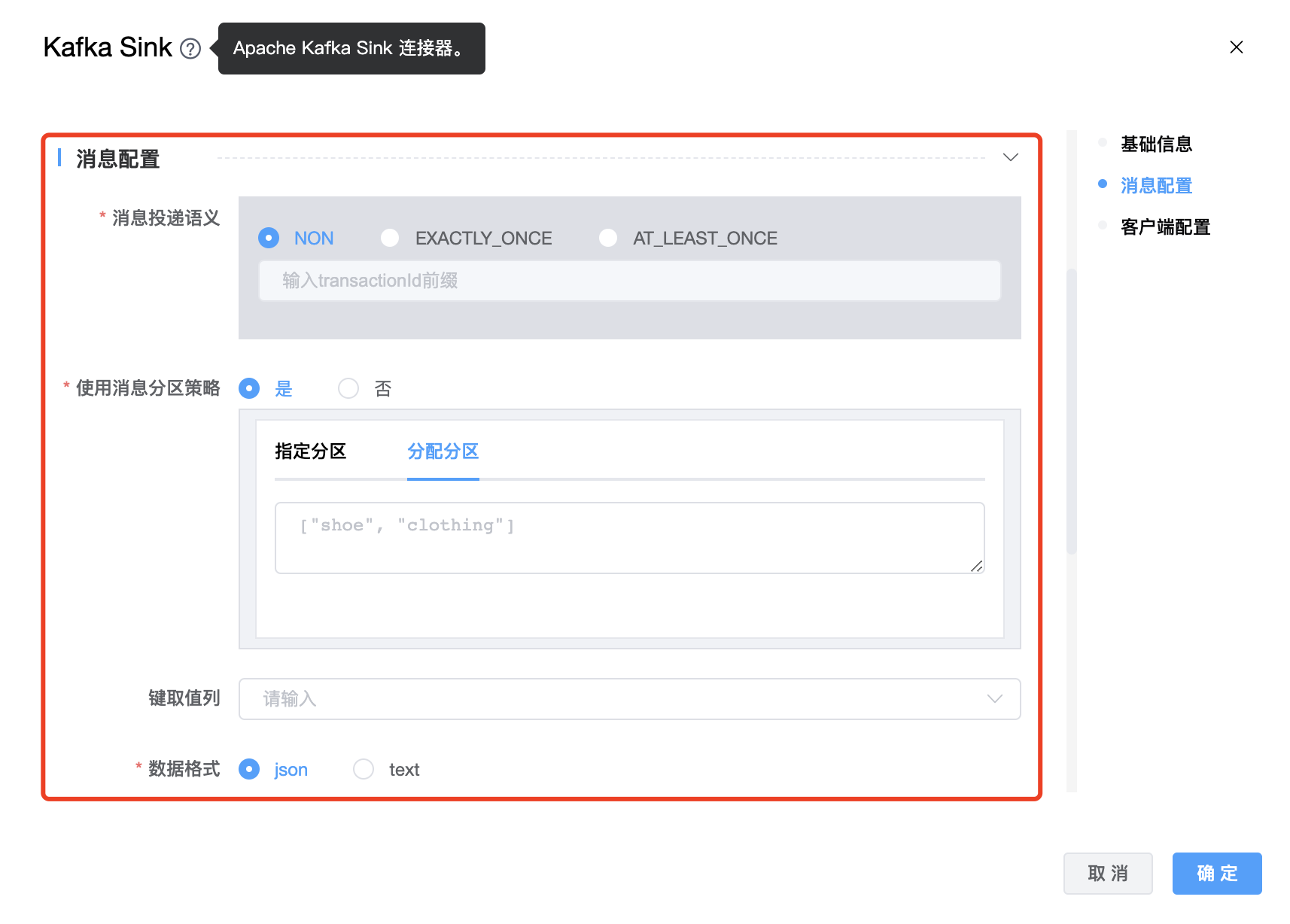
| 分配分区 | 可以根据消息的内容来决定发送哪个 partition。该参数的作用是分发信息。 比如一共有五个分区,config中的assign_partitions字段如下:assign_partitions = ["shoe", "clothing"] 然后包含“shoe”的消息将被发送到分区0,因为“shoe”在assign_partitions中被订阅为0,而包含“clothing”的消息将被发送到分区1。对于其他消息,将使用哈希算法来将它们分成剩余的分区。 这个函数按MessageContentPartitioner类实现了org.apache.kafka.clients.producer.Partitioner接口。如果我们需要自定义分区,我们也需要实现这个接口。 ⚠️ 当“分区“、”分配分区字段“ 配置项同时设置时,消息发送到那个分区,以”分区“配置项设置的分区为准,所有消息都会发送到”分区“配置项所指定的那个分区。 ⚠️ 当没有设置 “分区“ 配置项时,设置”分配分区“ 才会生效。 |
| 数据格式 | 数据格式支持:json、text。默认格式为 json。默认的字段分隔符是","。如果自定义分隔符,请添加“字段分隔符”选项。 |
| 可选参数 | Kafka Sink 的其他参数,用户可以根据需求进行配置。 |
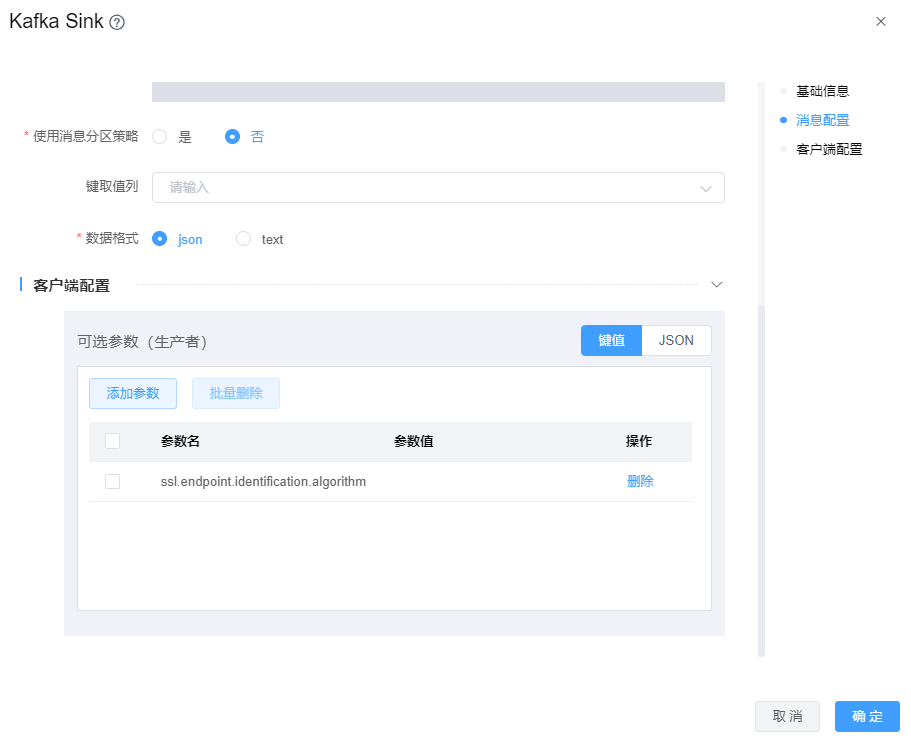
当kafka数据源使用的SSL认证时,Kafka Sink组件需要在【可选参数】中增加配置项:ssl.endpoint.identification.algorithm=,如下图
当kafka数据源使用的Kerberos认证时,Kafka Sink组件需要在【可选参数】中增加配置项:sasl.kerberos.service.name=kafka,其值
kafka为kafka服务的serviceName。如下图

# StarRocks
功能介绍: StarRocks Sink 连接器。用于将数据写入 StarRocks。
组件界面:


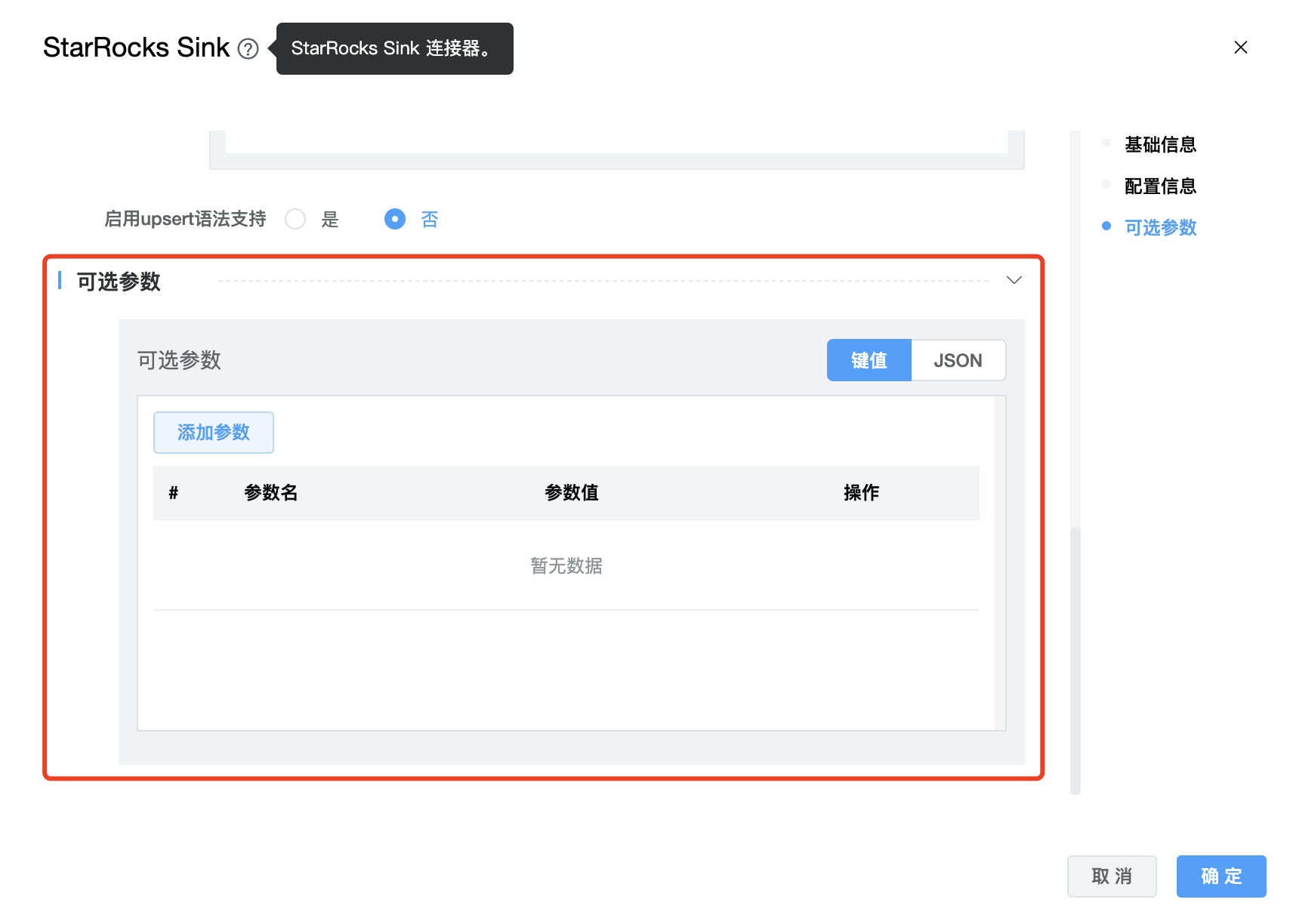
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 StarRocks Sink 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 StarRocks Sink 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | StarRocks Sink 的数据源名称,从下拉选项中列出的当前项目已经关联的 StarRocks 数据源进行选择。 |
| 数据库名称 | StarRocks Sink 的数据库名称。 |
| 数据表名称 | StarRocks Sink 的数据表名称。 |
| 流加载标签前缀 | StarRocks Stream Load (流加载)导入作业的标签的前缀。 |
| 批量提交最大缓存行数 | 对于批处理写入,当缓冲区数达到 batch_max_rows 数或 batch_max_bytes 字节大小或时间达到 batch_interval_ms 时,数据将被刷新到StarRocks中。 |
| 批量提交最大缓存 | 对于批处理写入,当缓冲区数达到 batch_max_rows 数或 batch_max_bytes 字节大小或时间达到 batch_interval_ms 时,数据将被刷新到 StarRocks 中。 |
| 最大重试次数 | 失败的最大重试次数。 |
| 重试乘数 | 用作产生下一个重试延迟的乘数,详细说明参考:http://beginners-java.blogspot.com/2015/03/customize-volley-default-retry-policy.html |
| 重试等待时间 | 尝试重试 StarRocks 请求之前等待的时间。 |
| 启用upsert语法支持 | 是否启用 upsert/delete,只支持 PrimaryKey 模式。 false: |
| 可选参数 | stream load 数据描述的参数,支持的格式包括CSV和JSON。默认值:JSON。 |
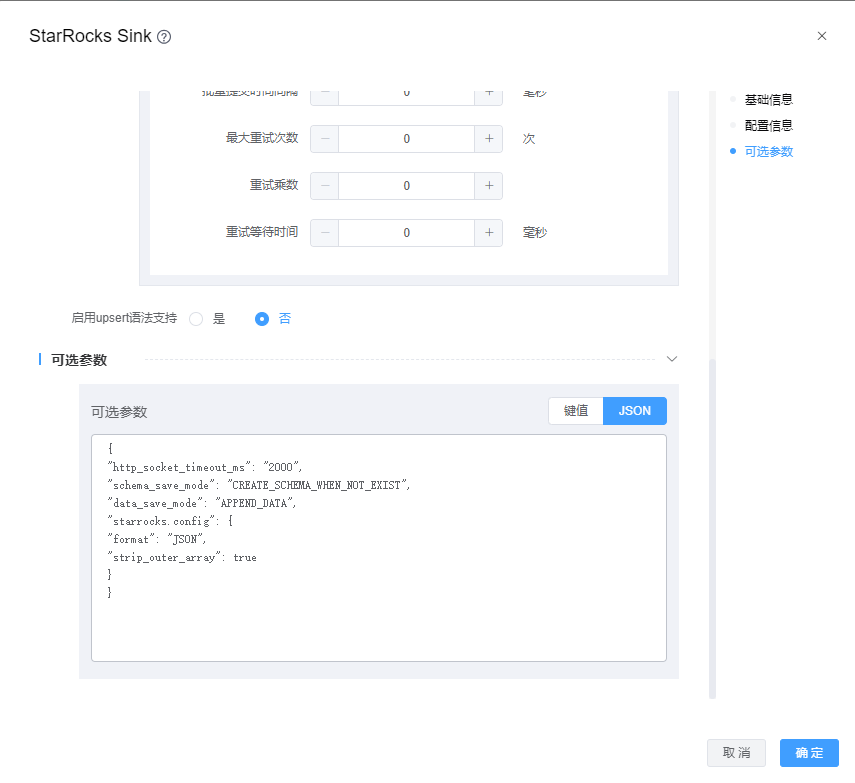
目前可选参数可配置如下:schema_save_mode、data_save_mode、http_socket_timeout_ms、starrocks.config
schema_save_mode参数值如下:
RECREATE_SCHEMA:当表不存在时,将创建表;当表已存在时,将删除原表并重新创建。
CREATE_SCHEMA_WHEN_NOT_EXIST:当表不存在时,将创建表;当表已存在时,跳过创建步骤。
ERROR_WHEN_SCHEMA_NOT_EXIST:当表不存在时,将报告错误。
data_save_mode参数值如下:
DROP_DATA:删除数据
APPEND_DATA:追加数据
ERROR_WHEN_DATA_EXISTS:数据存在时报告错误
CUSTOM_PROCESSING:用户自定义处理
http_socket_timeout_ms参数:设置http socket超时,默认3min
starrocks.config:stream load data_desc 的参数。
data_desc是一个 JSON 字符串,它包含了关于数据格式、列映射等的信息。
# 关系型数据库
功能介绍: 关系型数据库 JDBC Sink 连接器。通过 JDBC 写入数据。
组件界面:

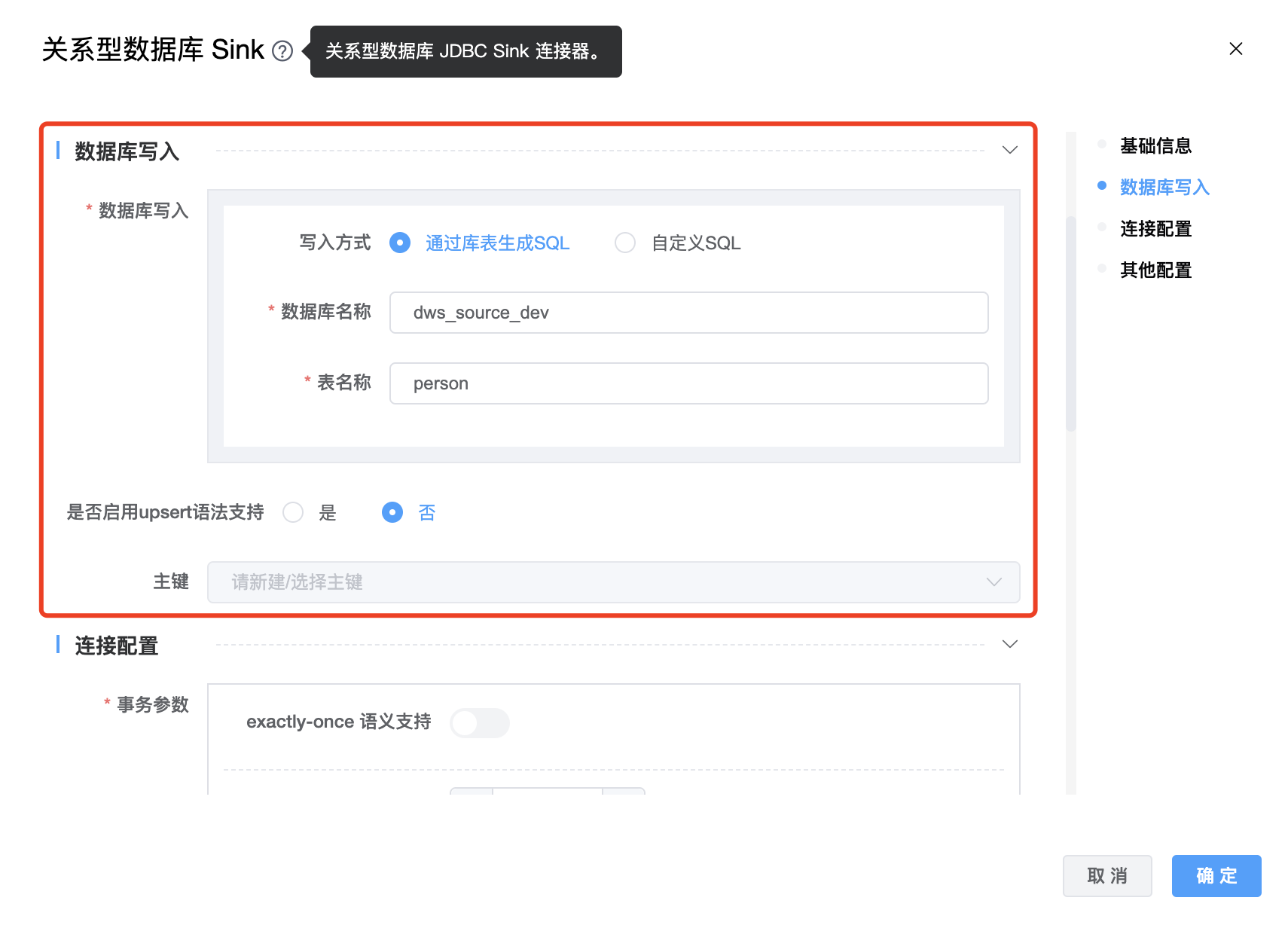
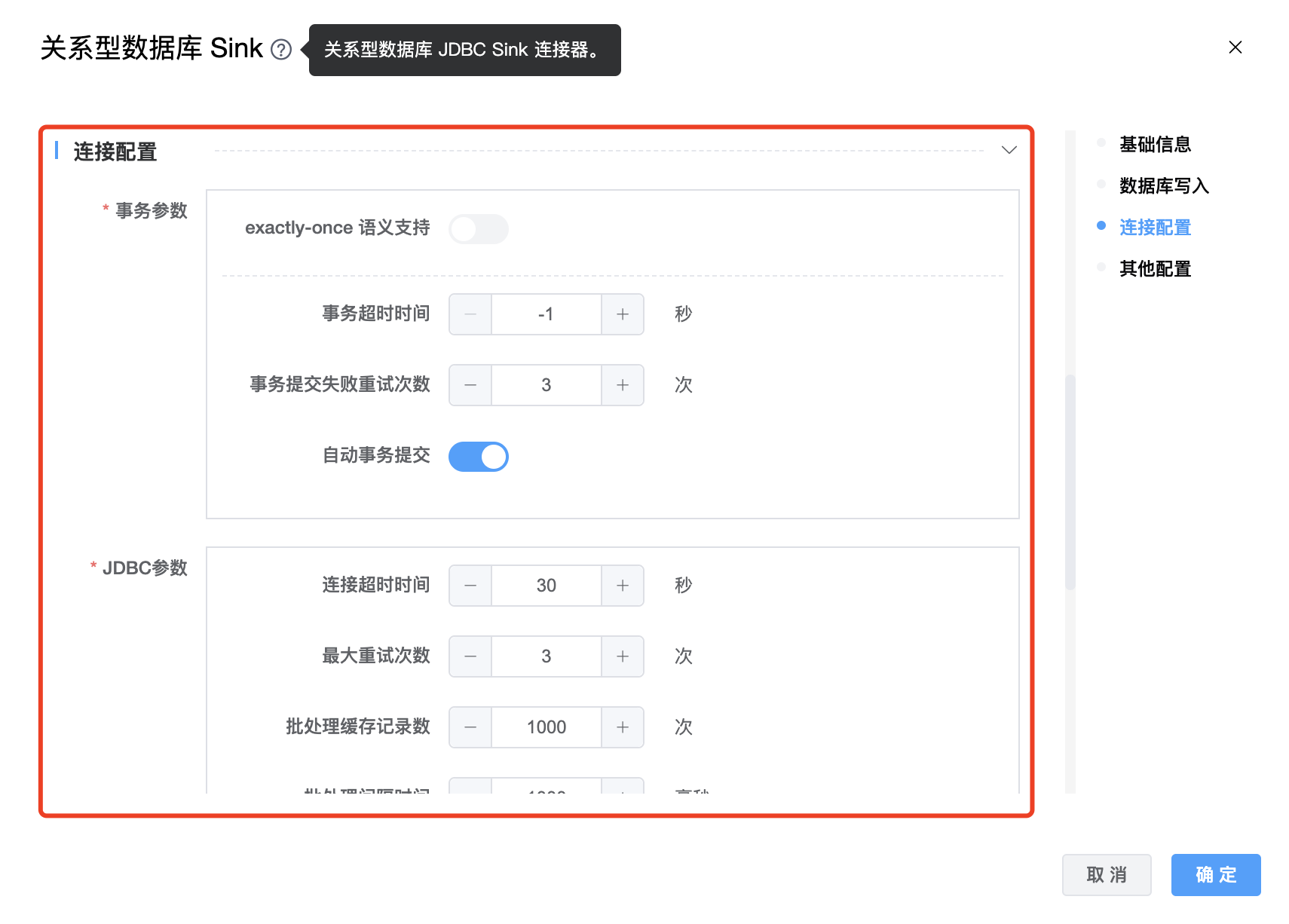
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的关系型数据库 Sink 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的关系型数据库 Sink 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 关系型数据库 Sink 的数据源名称,从下拉选项中列出的当前项目已经关联的关系型数据库数据源进行选择。 |
| 写入方式 | boolean类型。 选择"通过库表生成 SQL"时需要设置"数据库名称"和"表名称"。选择"自定义 SQL"时需要用户编写 SQL 语句。 |
| 数据库名称 | 关系型数据库 Sink 的数据库名称。 |
| 表名称 | 关系型数据库 Sink 的数据表名称。 |
| 是否启用upsert语法支持 | boolean 类型。如果选择"是",需要设置"主键",如果选择"否",则不需要设置"主键"。根据查询主键是否存在,选择使用INSERT sql、UPDATE sql来处理更新事件(INSERT、UPDATE_AFTER)。此配置仅在数据库不支持 upsert 语法时使用。 注意:此方法性能低下 |
| exactly-once 语义支持 | 启用 exactly-once 语义,将使用 Xa 事务。则需要设置xa_data_source_class_name。 |
| 事务超时时间 | 事务开启后的超时时间,默认为 -1(永不超时)单位为:秒。请注意,设置超时可能会影响 exactly-once 语义。 |
| 事务提交失败重试次数 | 事务提交失败的重试次数。 |
| 自动事务提交 | 默认情况下启用自动事务提交。 |
| 连接超时时间 | 等待用于验证连接完成的数据库操作的时间,单位为:秒。 |
| 最大重试次数 | 最大重试次数 |
| 批处理缓存记录数 | 批处理缓存记录数 |
| 批处理间隔时间 | 对于批量写入,当缓冲区数量达到数量 batch_size 或者时间达到时 batch_interval_ms,数据将被刷新到数据库中,单位为:毫秒。 |
| 可选参数 | 关系型数据库 Sink 的其他参数,用户可以根据需求进行配置。 |
# HBase
功能介绍: HBase Sink 连接器。用于将数据写入 HBase。
组件界面:

参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 HBase Sink 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 HBase Sink 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | HBase Sink 的数据源名称,从下拉选项中列出的当前项目已经关联的 HBase 数据源进行选择。 |
| 表名称 | HBase Sink 的数据表名称。 |
| Rowkey取值列 | 配置列名列表作为生成行键的数据取值列,例如:["id", "uuid"]。 |
| Rowkey分隔符 | 连接多行键的分隔符,默认为""。 |
| 映射配置 | 字段与列族的映射,例如:Id作为行键和其他字段写入到不同的列族,您可以分配 family_name { name = "info1" age = "info2" } name将写入列族info1,age将写入列族info2 如果您希望将所有字段写入同一列族,你可以分配 family_name { all_columns = "info" } 所有字段都将写入列族info。 |
| 空值写入模式 | 空值写入方式,支持[skip, empty],默认跳过 skip:当字段为 null 时,连接器不会将此字段写入 hbase empty:当字段为null时,连接器将写入并为此字段生成空值。 |
| 缓冲区大小 | HBase,默认810241024。 |
| 编码 | 字符串类型字段的编码,支持[utf8,gbk],默认为utf8。 |
| 可选参数 | HBase Sink 的其他参数,用户可以根据需求进行配置。 |
# Console
功能介绍: Console Sink 连接器。用于将数据输出到控制台,支持 streaming 和 batch 模式。例如,如果上游数据是 [age: 12, name: jared],则控制台会输出 {"name":"jared","age":17}
组件界面:
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 Console Sink 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 Console Sink 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 可选参数 | HBase Sink 的其他参数,用户可以根据需求进行配置。 |
# Http
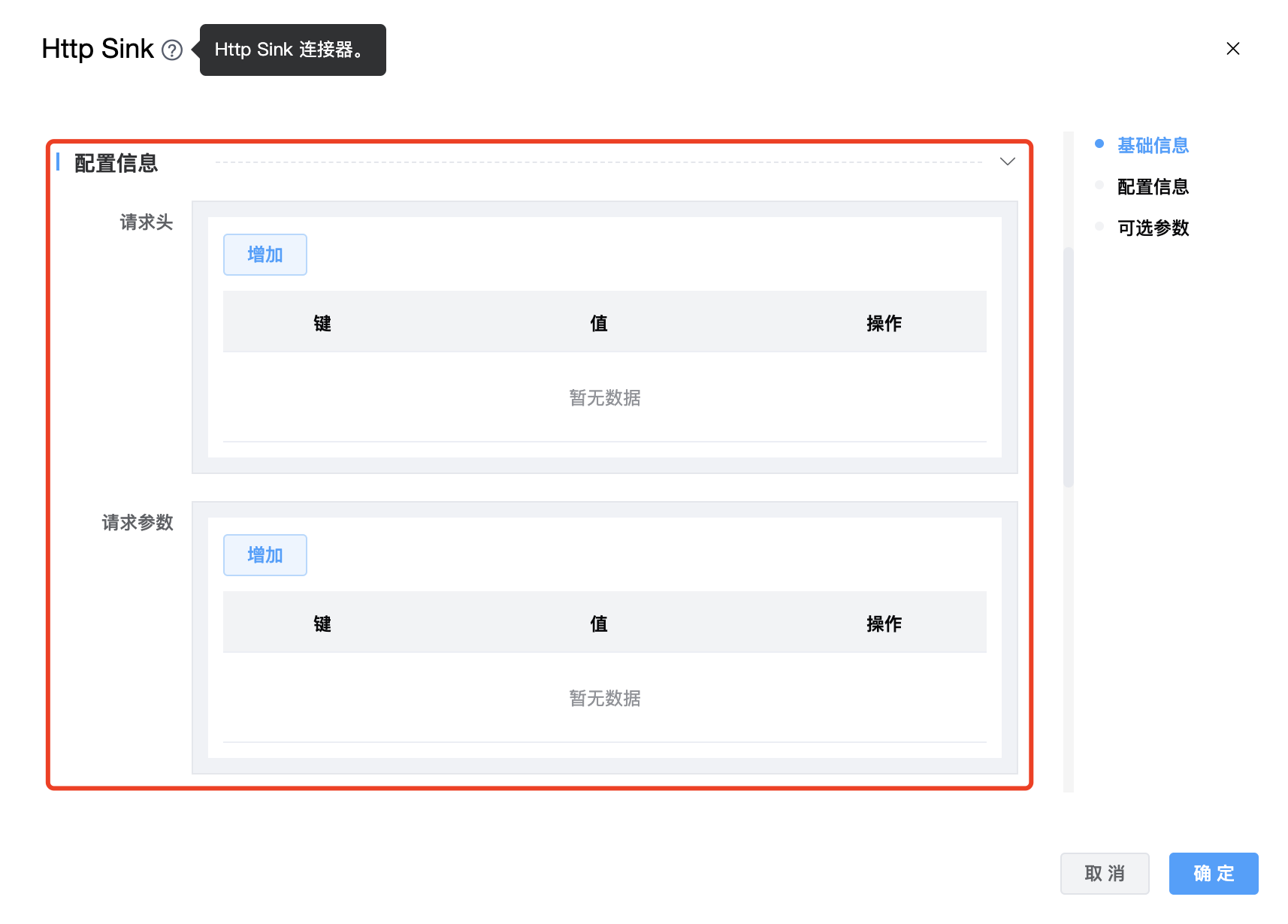
功能介绍: Http Sink 连接器。用于接收 Http 数据。
组件界面:

参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 Http Sink 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 Http Sink 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 请求URL | Http 请求的 URL 地址。 |
| 请求方式 | 只支持 POST 方式。 |
| 请求头 | 请求头参数。 |
| 请求参数 | 请求体参数。 |
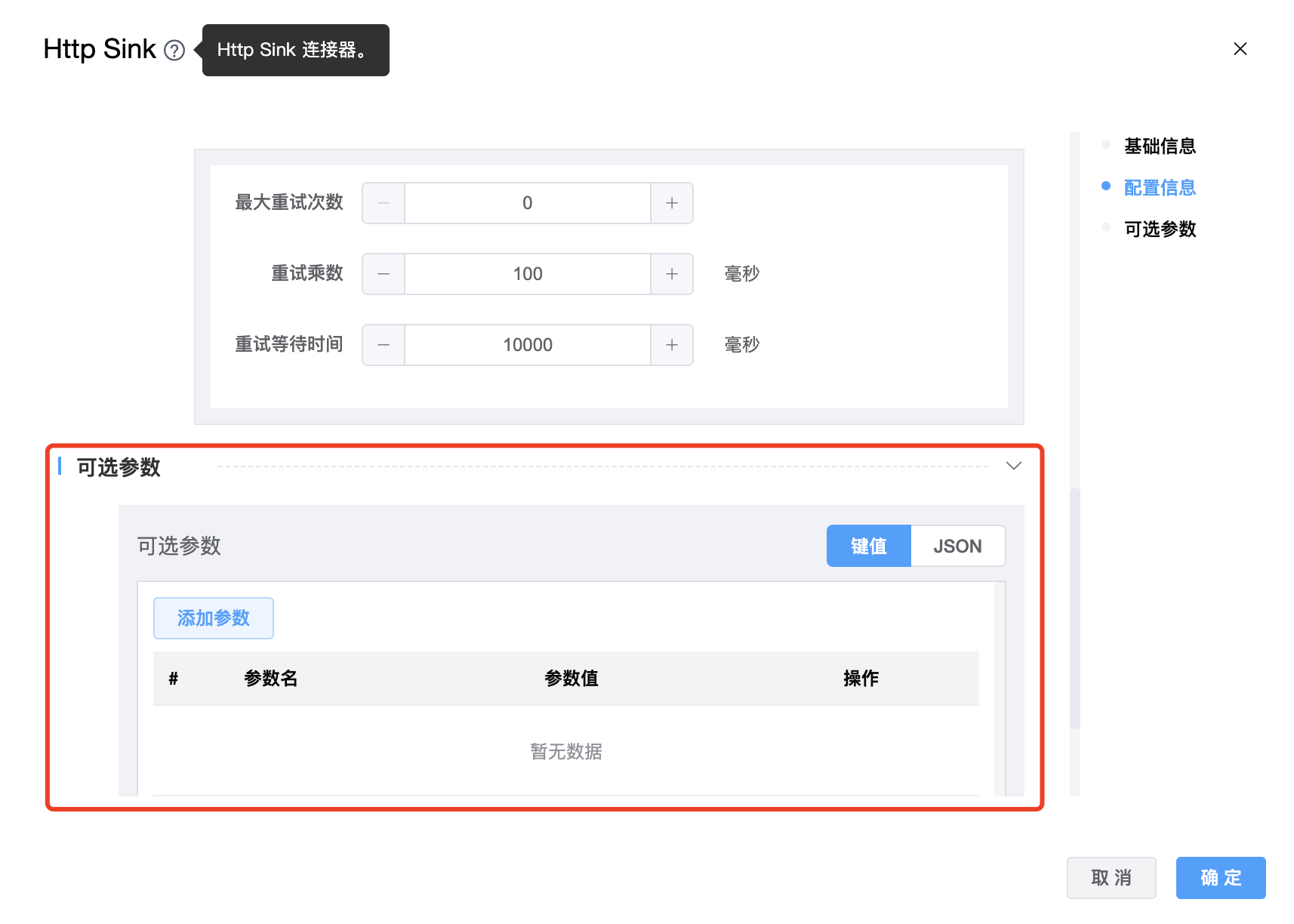
| 最大重试次数 | 请求失败最大重试次数。 |
| 重试乘数 | 如果请求 Http 失败,重试回退次数(毫秒)乘数。 |
| 可选参数 | Http Sink 的其他参数,用户可以根据需求进行配置。 |
| 重试等待时间 | 请求 Http 失败时,等待下次重试的时间(毫秒),默认 10000 毫秒 。 |
# Hive
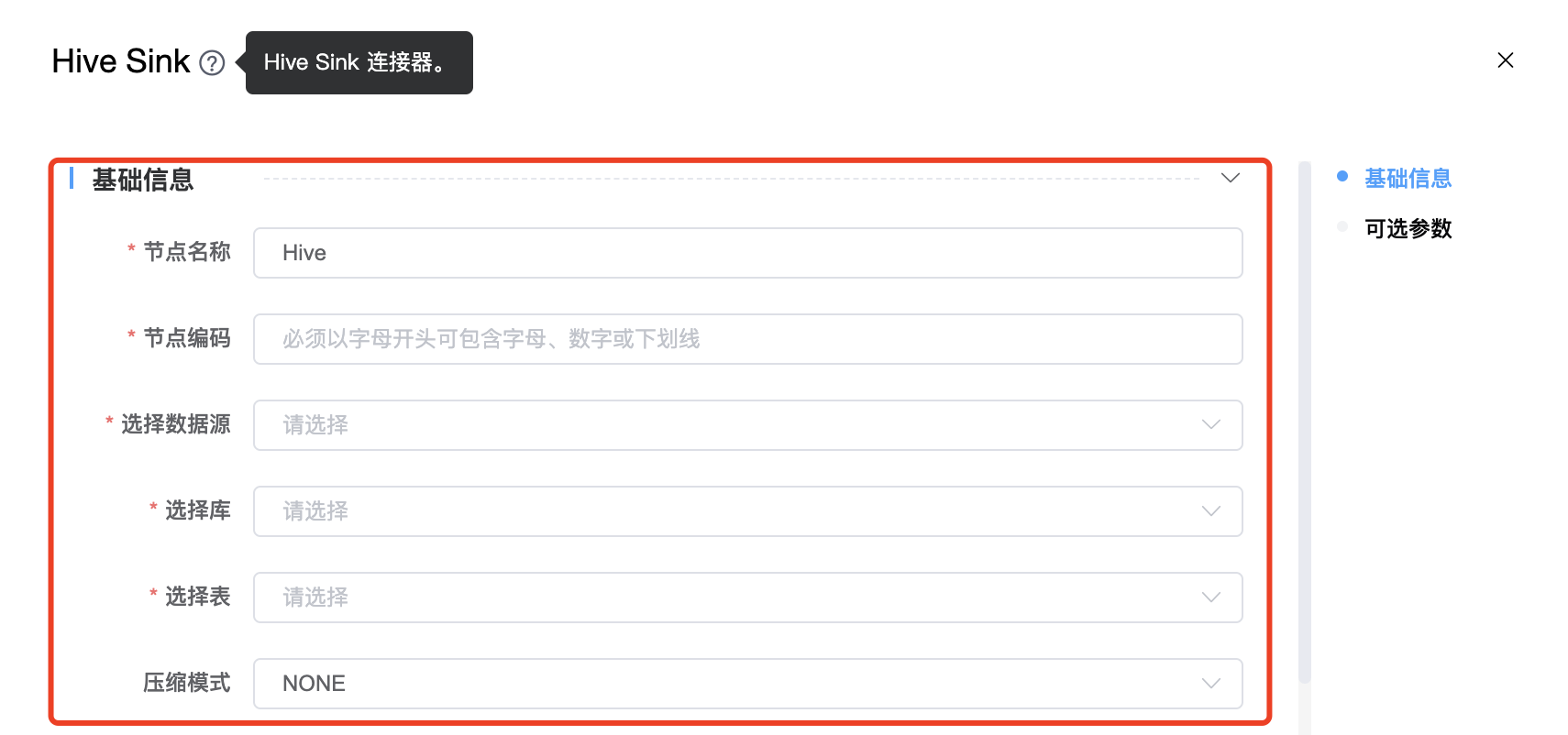
功能介绍: Hive Sink 连接器。用于接收 Hive 数据。
组件界面:
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 Hive Sink 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 Hive Sink 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | Hive Sink 的数据源名称,从下拉选项中列出的当前项目已经关联的 Hive 数据源进行选择。 |
| 选择库 | Hive Sink 的数据库名称。 |
| 选择表 | Hive Sink 的数据表名称。 |
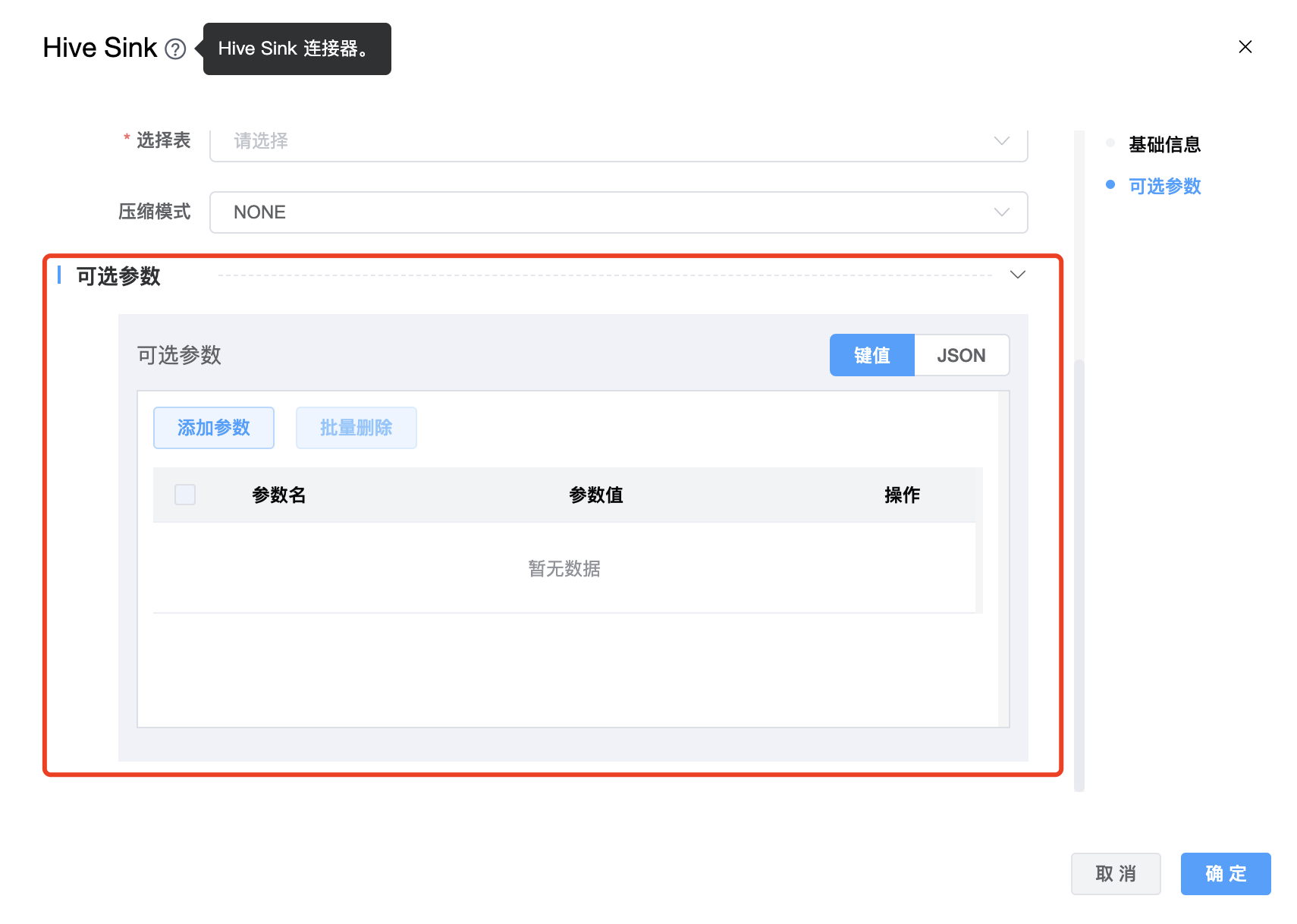
| 压缩模式 | 有三种:NONE、SNAPPY、LZO。 |
| 可选参数 | Hive Sink 的其他参数,用户可以根据需求进行配置。 |
# Inceptor
功能介绍:星环 Inceptor Sink。用于将数据写入 Inceptor。
组件界面:
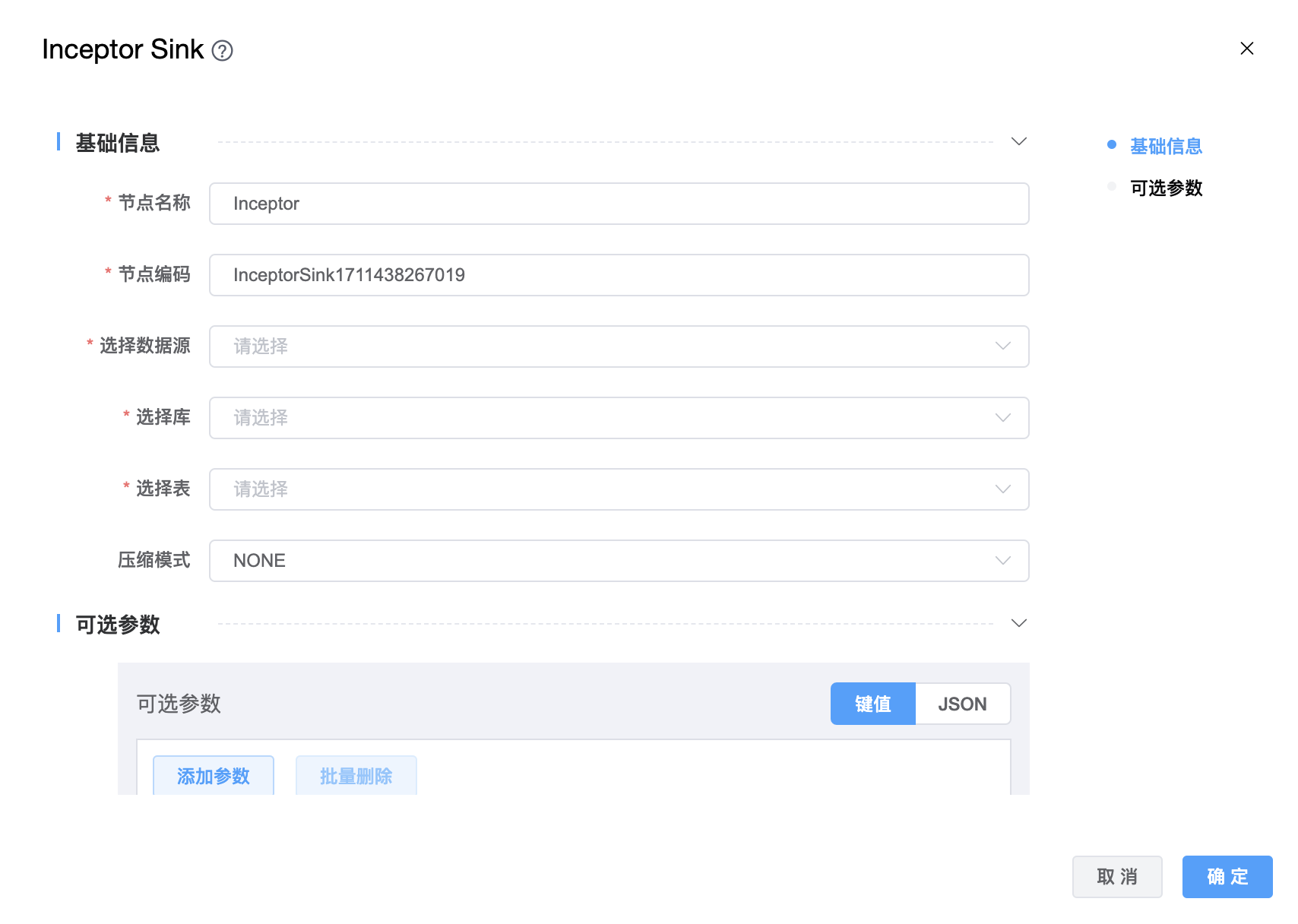
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 从下拉选项中选择列出的当前项目已经关联的 Hive 数据源。 |
| 选择库 | 选择数据库名称。 |
| 选择表 | 选择数据表名称。 |
| 压缩模式 | 有三种:NONE、SNAPPY、LZO。 |
| 可选参数 | Inceptor Sink 的其他参数,用户可以根据需求进行配置。 |
# LocalFile
功能介绍:LocalFile Sink。用于从本地文件系统读取数据。
组件界面:
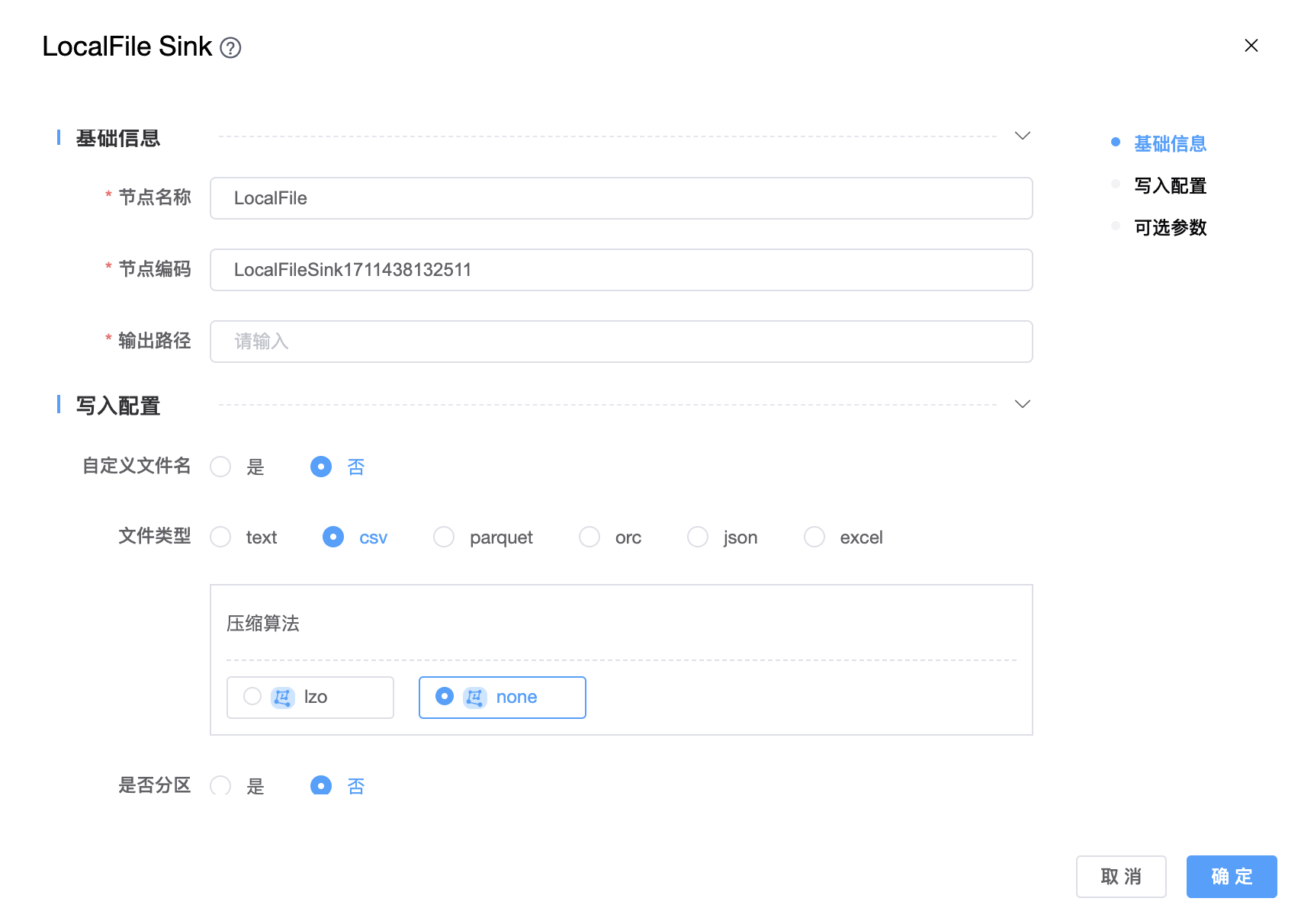
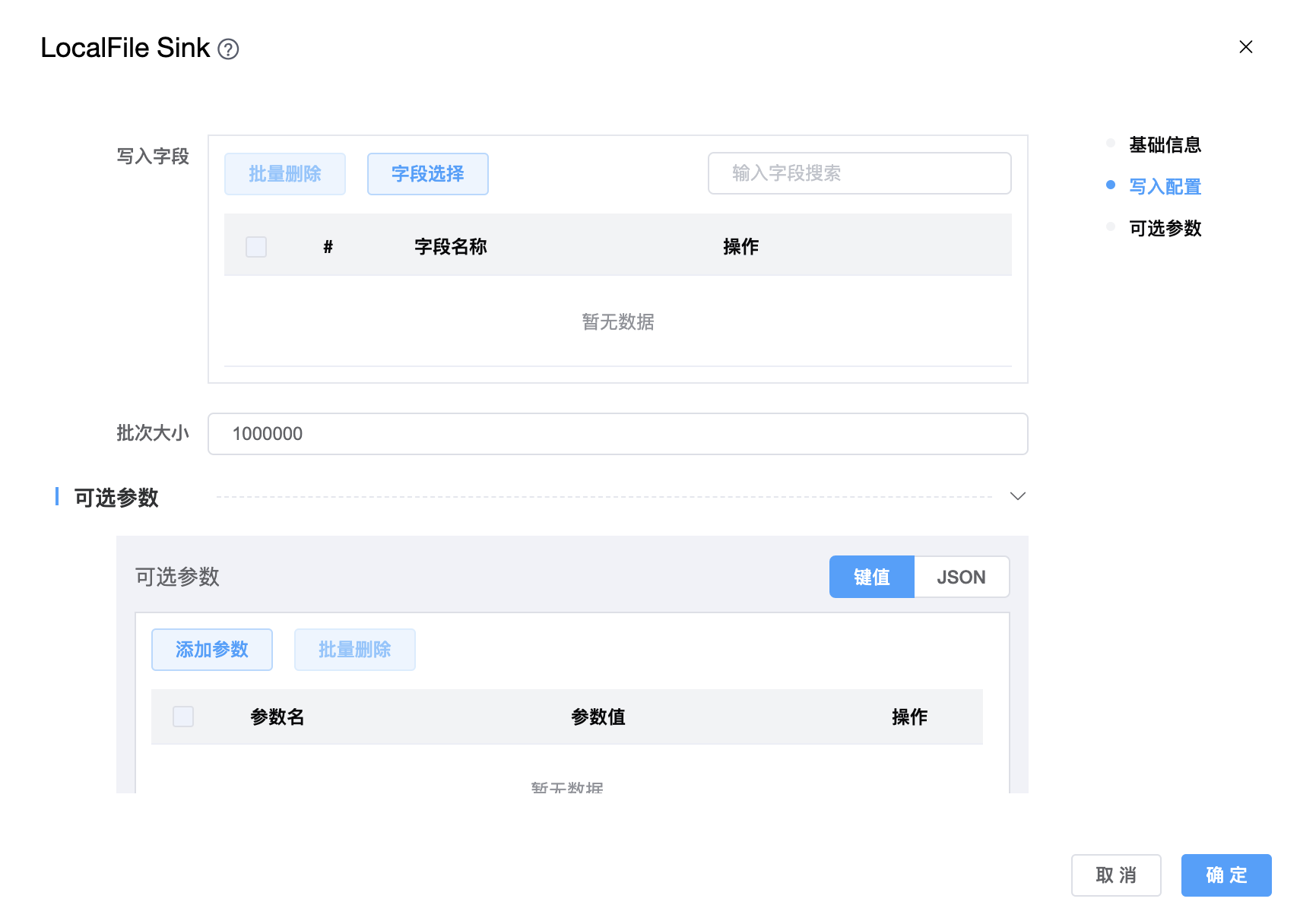
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 输出路径 | 目标文件路径。 |
| 自定义文件名 | 是否自定义文件名。 |
| 文件类型 | 支持:text、csv、parquet、orc、json、excel 六种文件类型。 |
| 压缩算法 | 支持文件的压缩算法:txt: lzo、none;json: lzo、none;csv: lzo、none;orc: lzo、snappy、lz4、zlib、none;parquet: lzo、snappy、lz4、gzip、brotli、zstd、none;excel 不支持任何压缩算法。 |
| 添加头部行 | 当"是否分区"为 "是" 时使用。如果设置为"是",则分区字段及其值将写入数据文件。 |
| 字段分隔符 | 数据行中列之间的分隔符。仅文本文件格式需要。 |
| 行分隔符 | 文件中行之间的分隔符。仅文本文件格式需要。 |
| 是否分区 | 是否需要处理分区。默认为"否"。 |
| 分区字段 | 当"是否分区"为 "是" 时使用。根据所选字段对数据进行分区。 |
| 分区目录表达式 | 当"是否分区"为 "是" 时使用。如果指定了"分区字段",将根据分区信息生成相应的分区目录,最终文件将放置在分区目录中。默认"分区目录表达式"为${k0}=${v0}/${k1}=${v1}//${kn}=${vn}/。k0是第一个分区字段,v0是第一分区字段的值。 |
| 分区字段及其值是否写入文件 | 当"是否分区"为 "是" 时使用。如果"分区字段及其值是否写入文件"为"是",则分区字段及其值将写入数据文件。例如,如果要编写配置单元数据文件,其值应为"否"。 |
| 写入字段 | 哪些列需要写入文件,默认值是从"转换"或"数据源"获取的所有列。字段的顺序决定了文件实际写入的顺序。 |
| 批次大小 | 文件中的最大行数。对于 SeaTunnel Engine,文件中的行数由batch_size和checkpoint.interval共同决定。如果checkpoint.interval的值足够大,则接收器写入程序将在文件中写入行,直到文件中的行大于batch_size。如果checkpoint.interval很小,则当触发新的检查点时,接收器写入程序将创建一个新文件。 |
| 可选参数 | 其他配置参数,用户可以根据需求进行配置。 |
# Neo4j
功能介绍:Neo4j Sink。用于将数据写入 Neo4j。
组件界面:
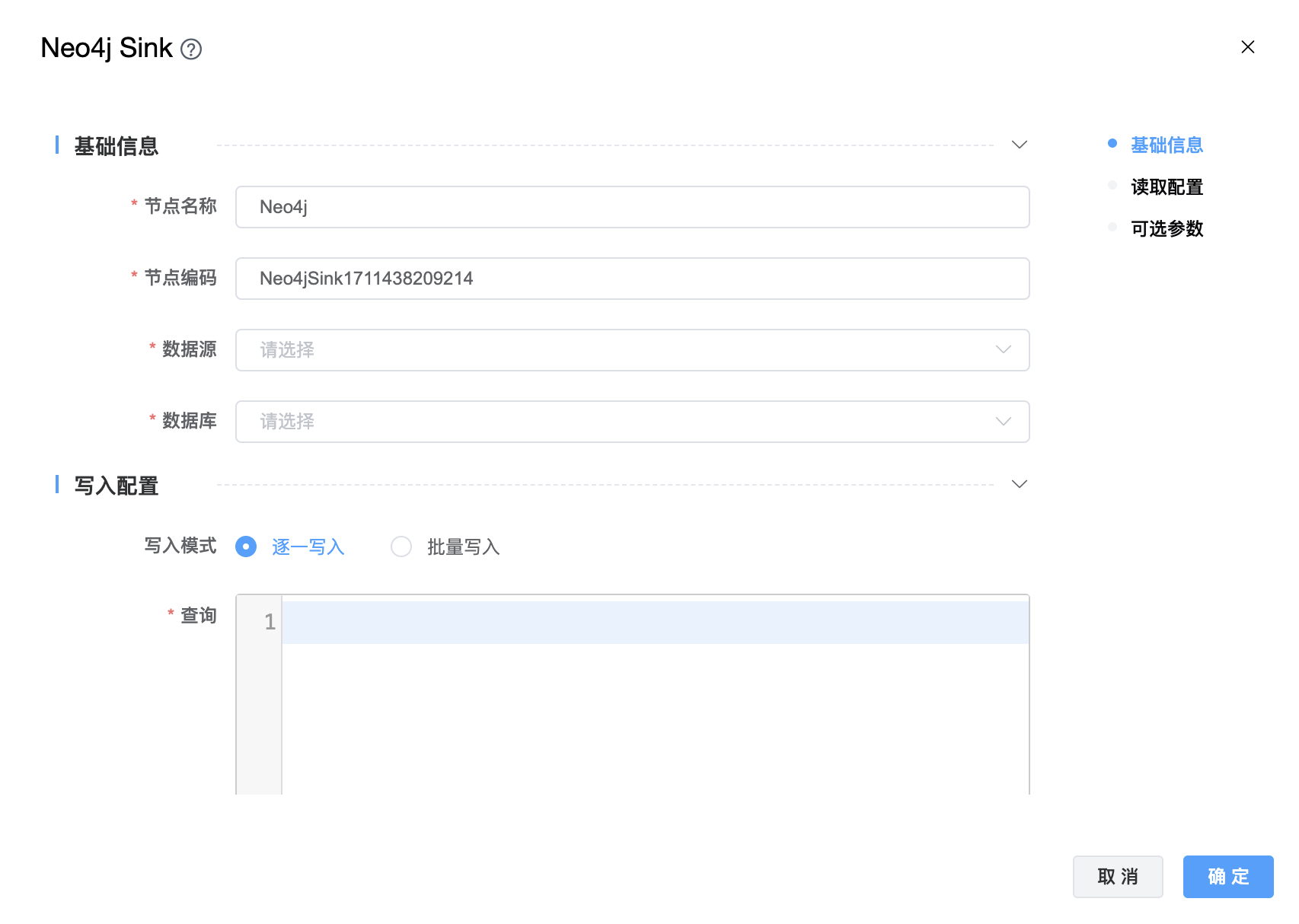
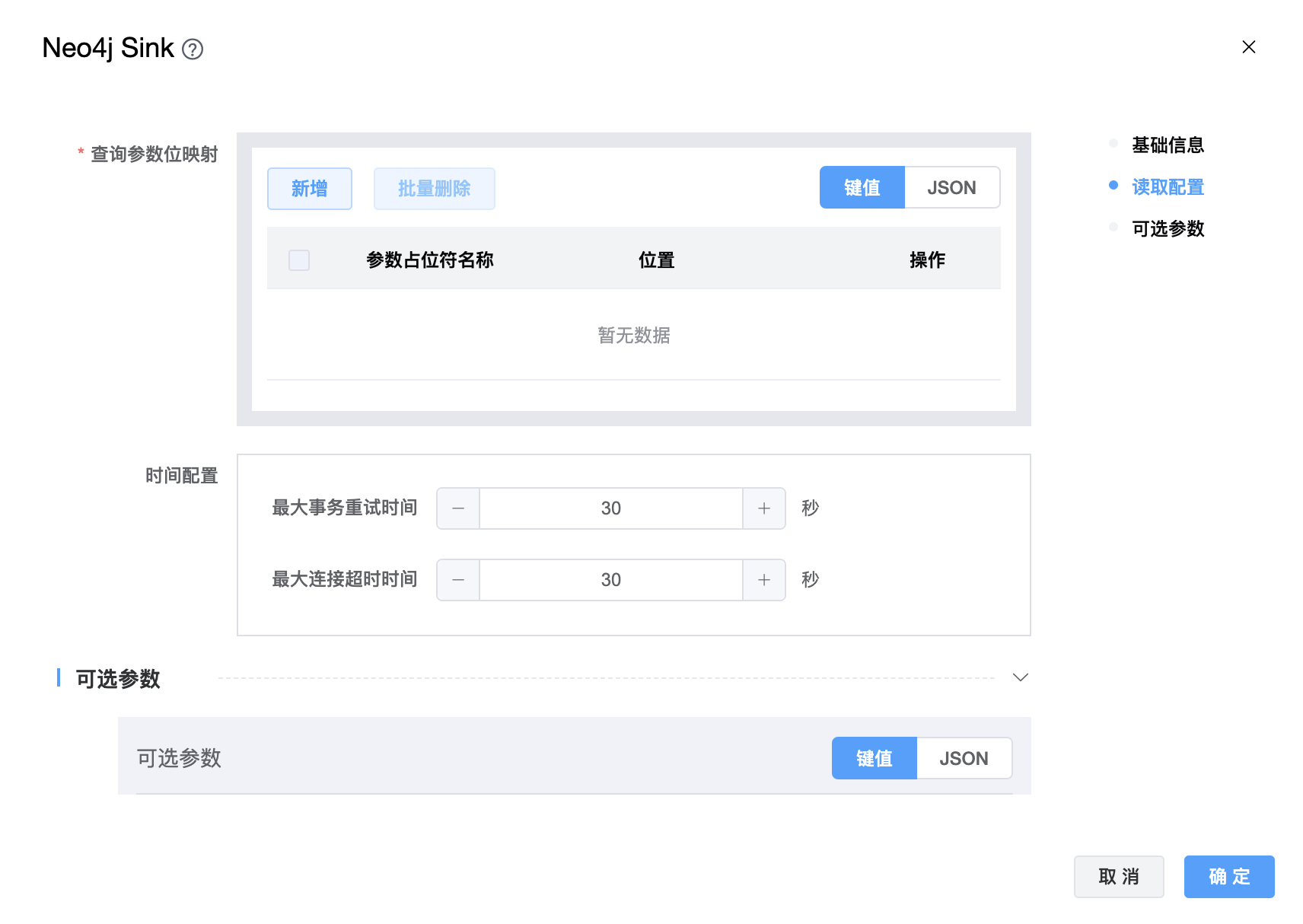
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 数据源 | 从下拉选项中选择列出的当前项目已经关联的 Neo4j 数据源。 |
| 数据库 | 从下拉选项中选择数据库名称。 |
| 写入模式 | 默认值为"逐一写入",如果您希望能够批量写入,请将其设置为“批量写入”。 |
| 查询 | 查询语句。 |
| 查询参数位映射 | 查询参数的位置映射信息。关键字名称是参数占位符名称。关联值是输入数据行中字段的位置。 |
| 最大事务重试时间 | 最大事务重试时间(秒)。如果超过,事务将失败。 |
| 最大连接超时时间 | 等待建立TCP连接的最长时间(秒)。 |
| 可选参数 | 其他配置参数,用户可以根据需求进行配置。 |