
# 数据源
本章节详细说明数据源组件的功能及属性,具体如下:
# ClickHouse
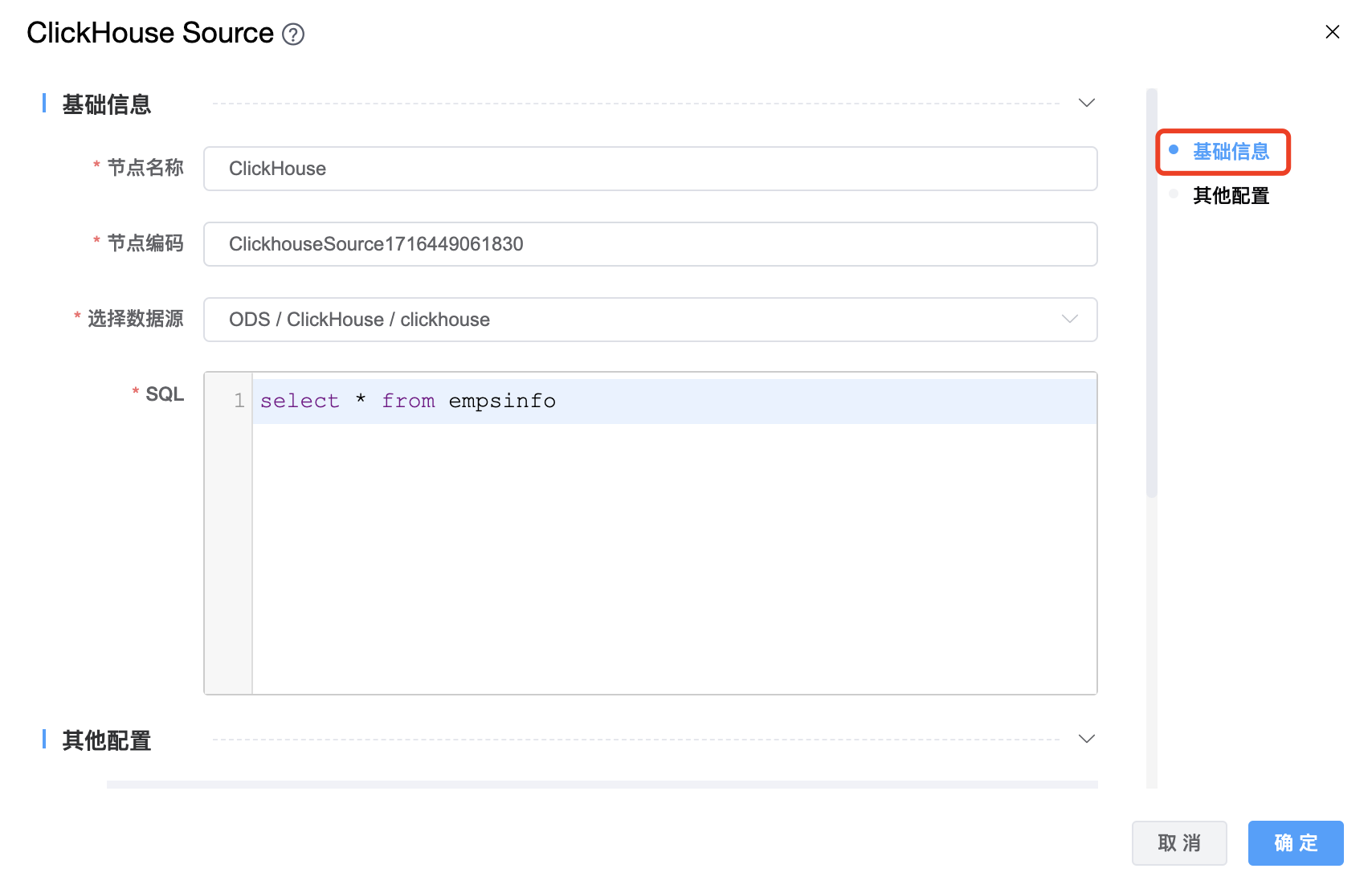
功能介绍:ClickHouse Source 连接器。用于从 ClickHouse 读取数据。
组件界面:
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 ClickHouse Source 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 ClickHouse Source 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | ClickHouse Source 的数据库名称,下拉选项中会列出当前项目已经关联的 ClickHouse 数据源。 |
| SQL | 用于通过 Clickhouse Source 搜索数据的查询 SQL 语句,用户可以根据需求编写。 |
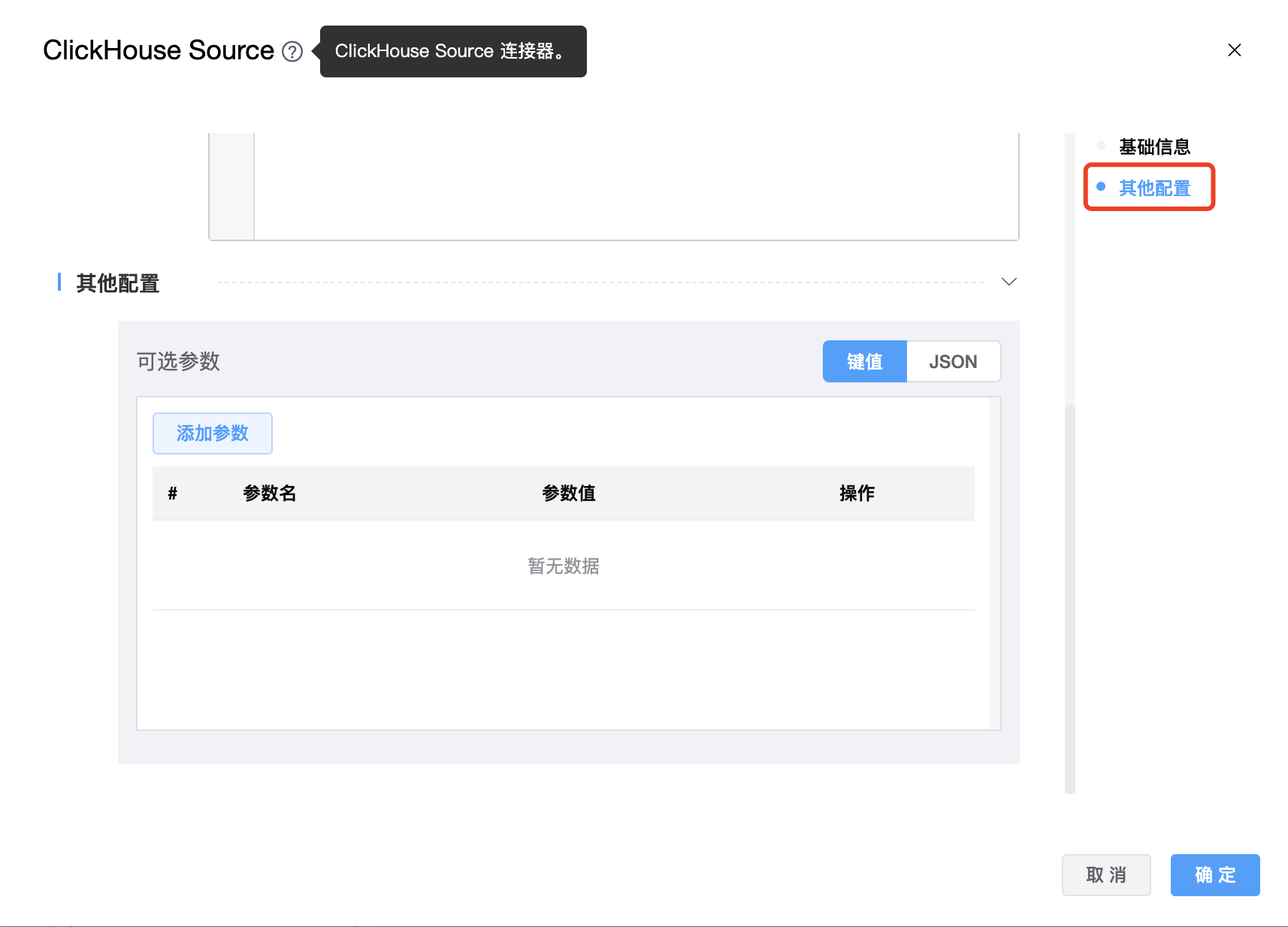
| 可选参数 | ClickHouse Source 的其他参数,配置后即会启用该配置,不会再使用环境默认参数,用户可以根据需求进行配置。 比如:result_table_name、parallelism |
# Elasticsearch
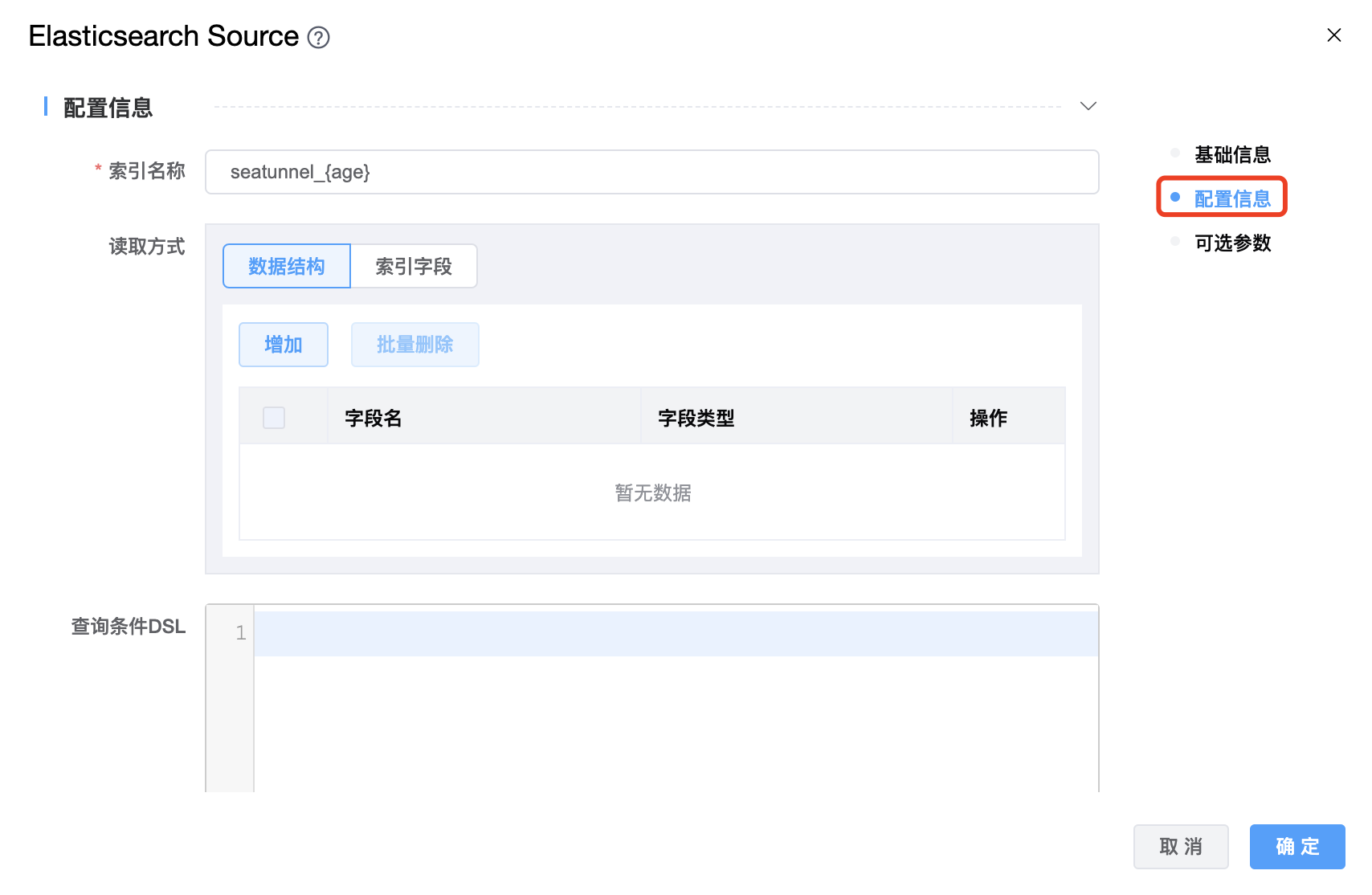
功能介绍: Elasticsearch Source 连接器。用于从 Elasticsearch 读取数据。支持版本>=2.x和<=8.x。
组件界面:

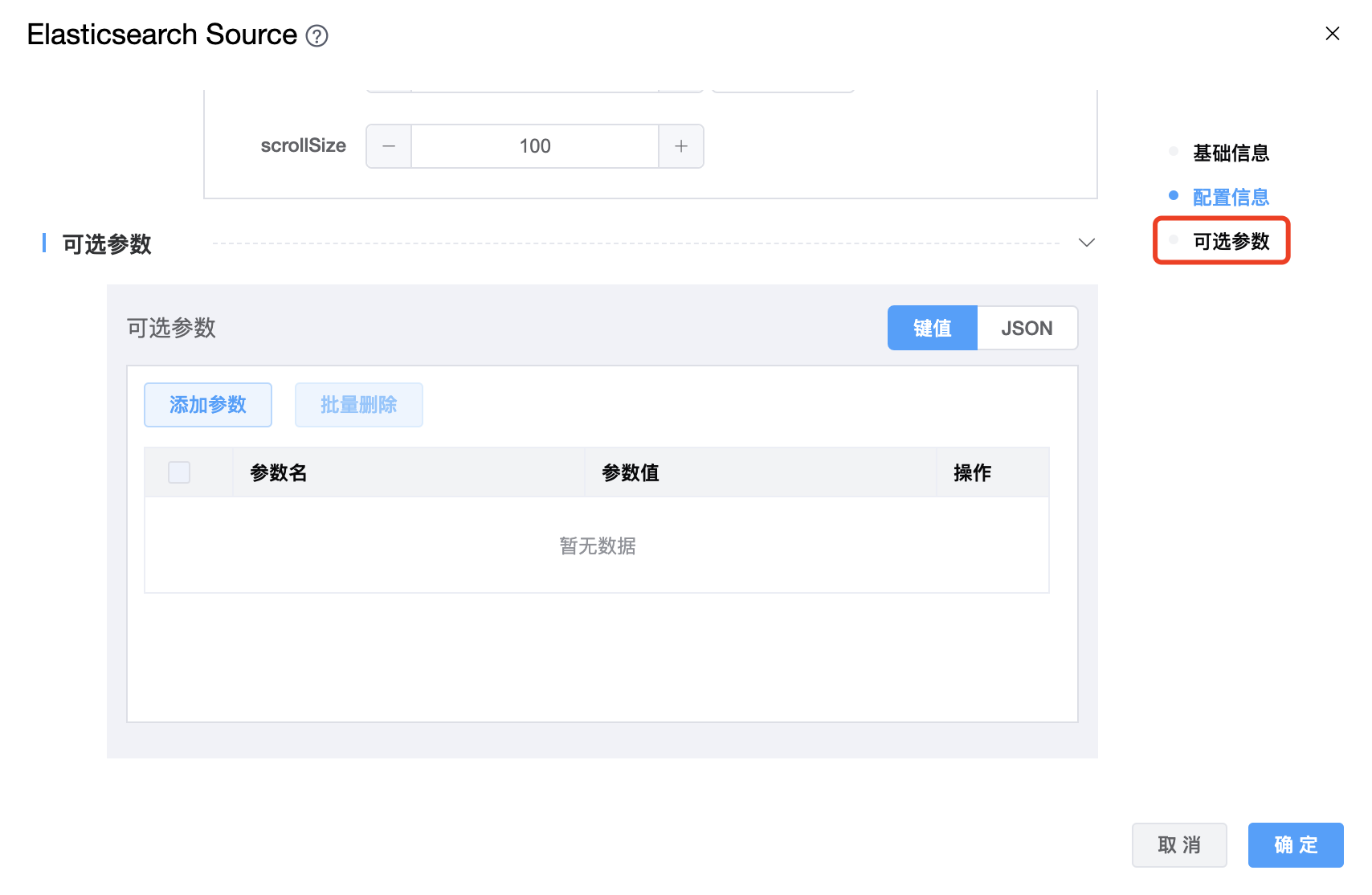
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 Elasticsearch Source 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 Elasticsearch Source 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | Elasticsearch Source 的数据库名称,从下拉选项中列出的当前项目已经关联的 Elasticsearch 数据源进行选择。 |
| 索引名称 | Elasticsearch索引名称,支持 * 模糊匹配。索引名称必须是小写的,不能用下划线开头,不能包含逗号,例如:seatunnel_${age} |
| 读取方式 | 读取方式有两种:数据结构、索引字段,必须二选一进行配置。采用"索引字段"时,用户可以通过指定字段 _id 来获取文档 id。如果将 _id 下沉到其他索引,由于 Elasticsearch 的限制,需要为 _id 指定别名。 |
| 查询条件 DSL | 用户可以通过编写 DSL 语句控制读取数据的范围。Elasticsearch 提供了一个基于 JSON 的完整查询DSL(域特定语言)来定义查询。具体参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html |
| scrollTime | Elasticsearch 请求保持搜索上下文活动的时间量。 单位:天(-d),小时(-h),分钟(-m),秒(-s),毫秒(-ms),微秒(-micros),纳秒(-nanos) 例如:1d,1h,1m,1s,1ms,1micros,1nanos |
| scrollSize | 每个 Elasticsearch 请求返回的最大点击数。 |
| 可选参数 | Elasticsearch Source 的其他参数,用户可以根据需求进行配置。 |
# Kafka
功能介绍: Kafka Source 连接器。用于从 Kafka 读取数据。
组件界面:
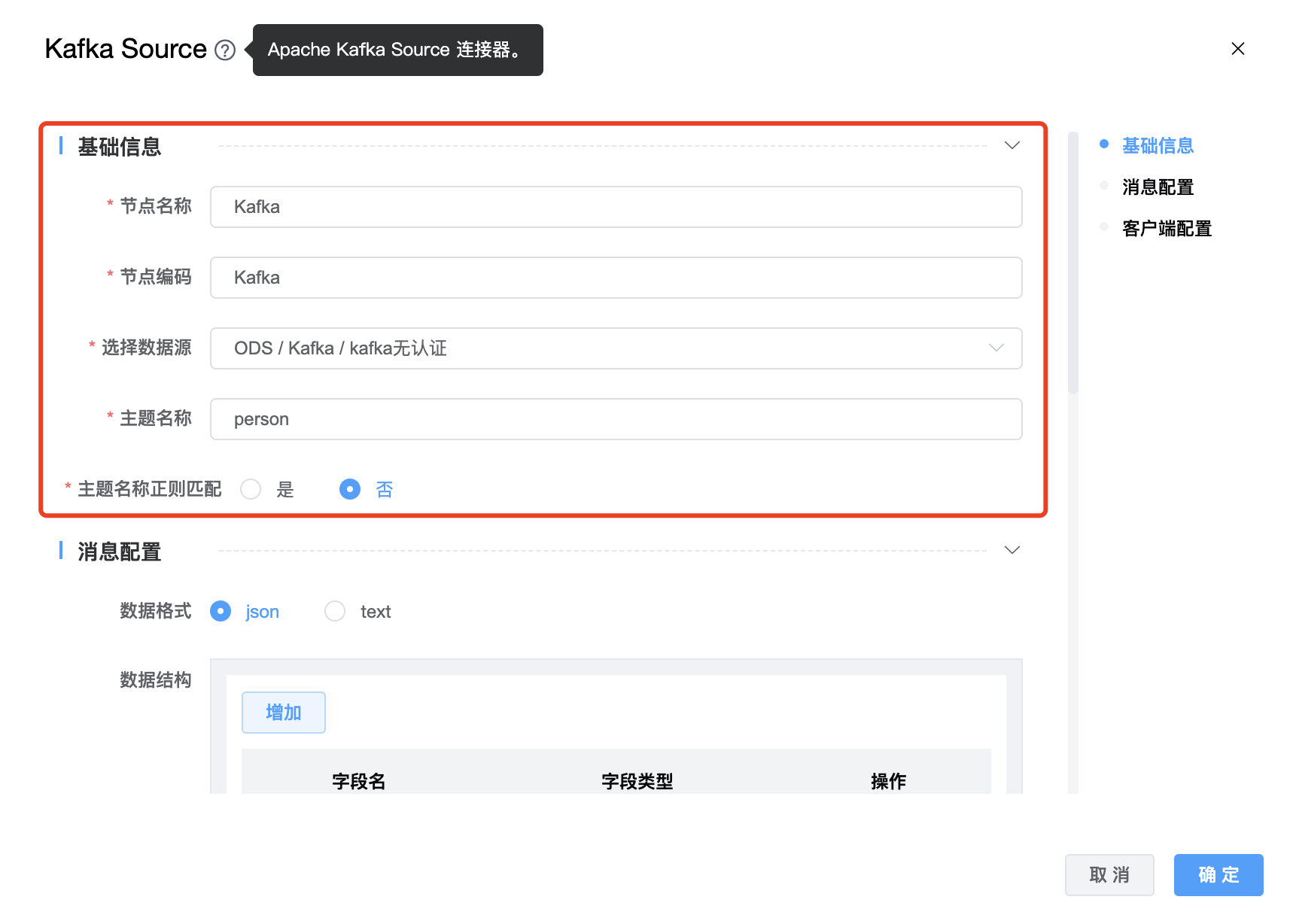
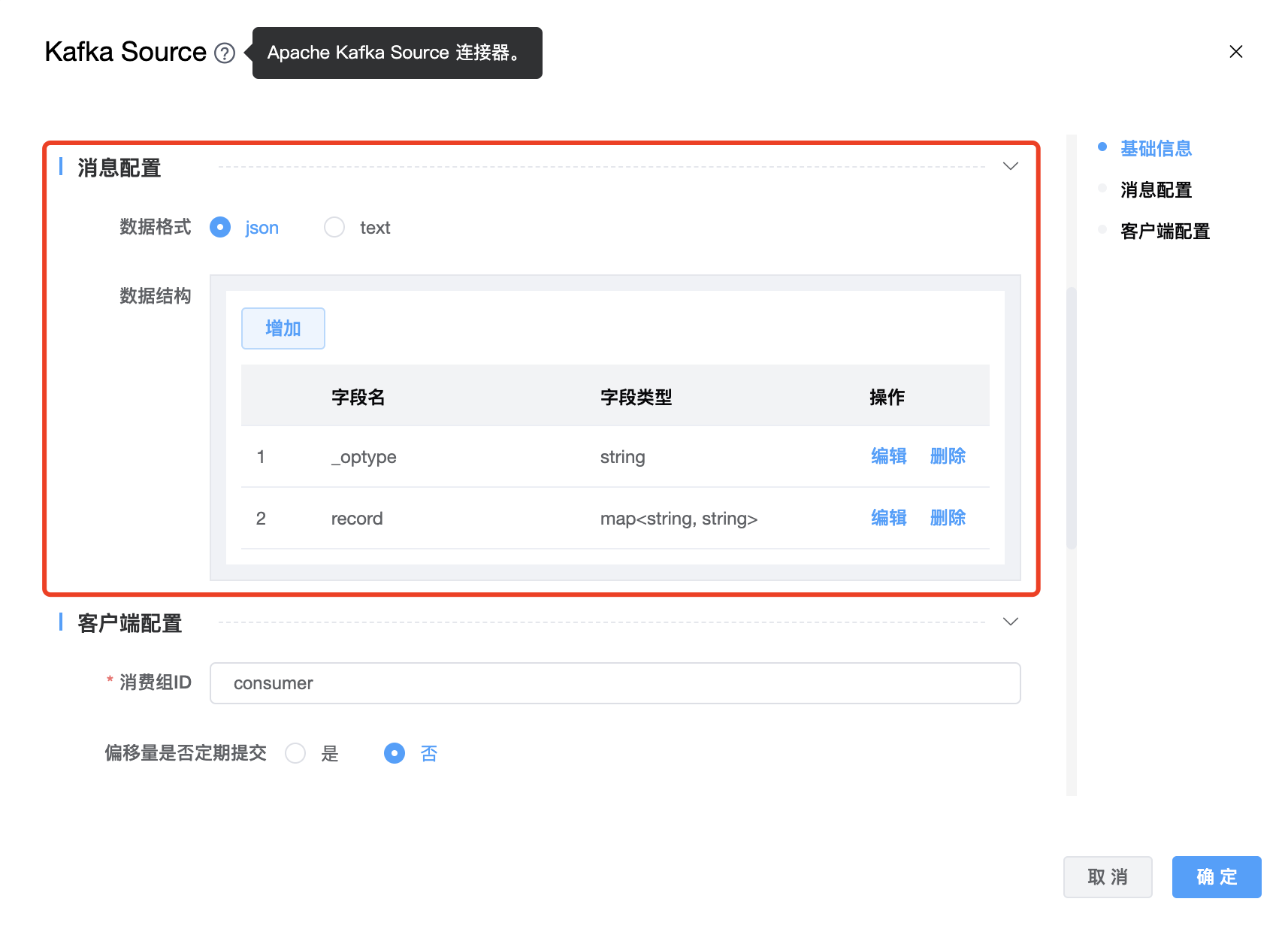
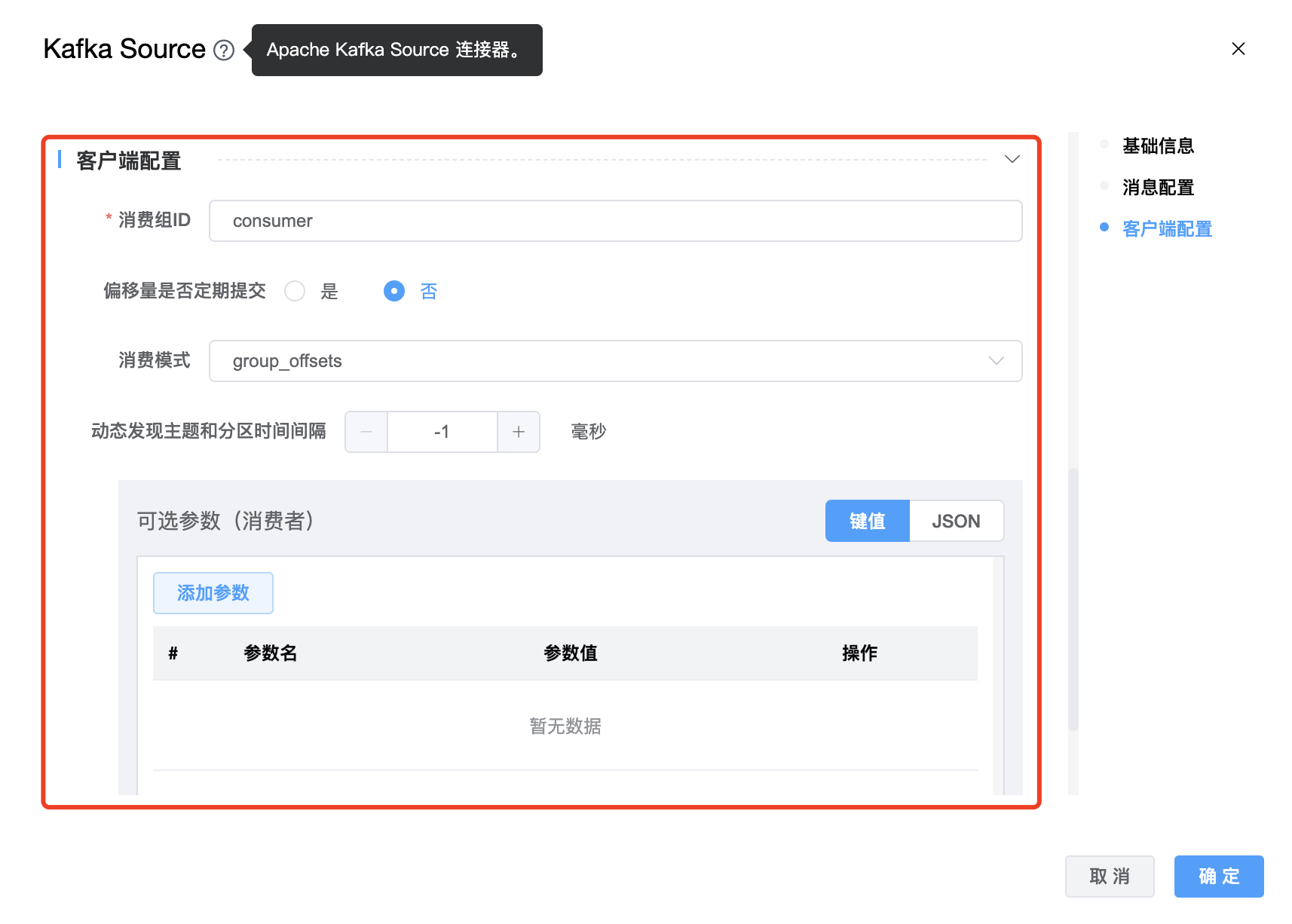
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 Kafka Source 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 Kafka Source 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | Kafka Source 的数据库名称,从下拉选项中列出的当前项目已经关联的 Kafka 数据源进行选择。 |
| 主题名称 | Kafka Topic 名称。如果有多个topics,使用英文符号"," 进行拆分,例如:"tpc1,tpc2" |
| 主题名称正则匹配 | boolean 类型,如果设置为true,客户端中主题名称与指定正则表达式匹配的所有主题都将被消费者订阅。 |
| 数据格式 | 数据格式支持:json、text。默认格式为 json。默认的字段分隔符是","。如果自定义分隔符,请添加“字段分隔符”选项。 |
| 数据结构 | 字段的数据结构(包括字段名称和字段类型)。 支持的类型如下: 字段类型:
更多 key 类型: int、string、boolean、tinyint、smallint、bigint、float、double、decimal、date、time、timestamp、null 更多 value 类型:int、string、boolean、tinyint、smallint、bigint、float、double、decimal、date、time、timestamp、null、array
|
| 消费组ID | Kafka 消费者的 group id,用来区分不同的消费群体。 |
| 偏移量是否定期提交 | boolean 类型,如果为 true,消费者的偏移量将在后台定期提交。 |
| 消费模式 | 消费者的初始消费模式,有 5 种:earliest、group_offsets、latest、specific_offsets、timestamp |
| 动态发现主题和分区时间间隔 | 动态发现主题和分区的时间间隔。 |
| 可选参数 | Kafka Source 的其他参数,用户可以根据需求进行配置。 |
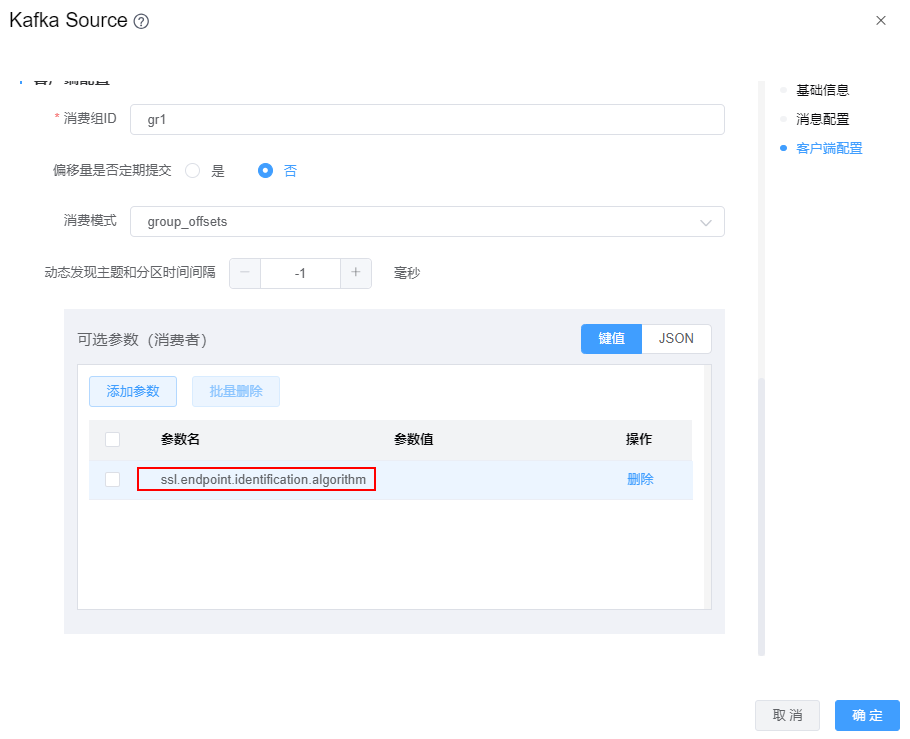
当kafka数据源使用的SSL认证时,Kafka Source组件需要在【可选参数】中增加配置项:ssl.endpoint.identification.algorithm=,如下图
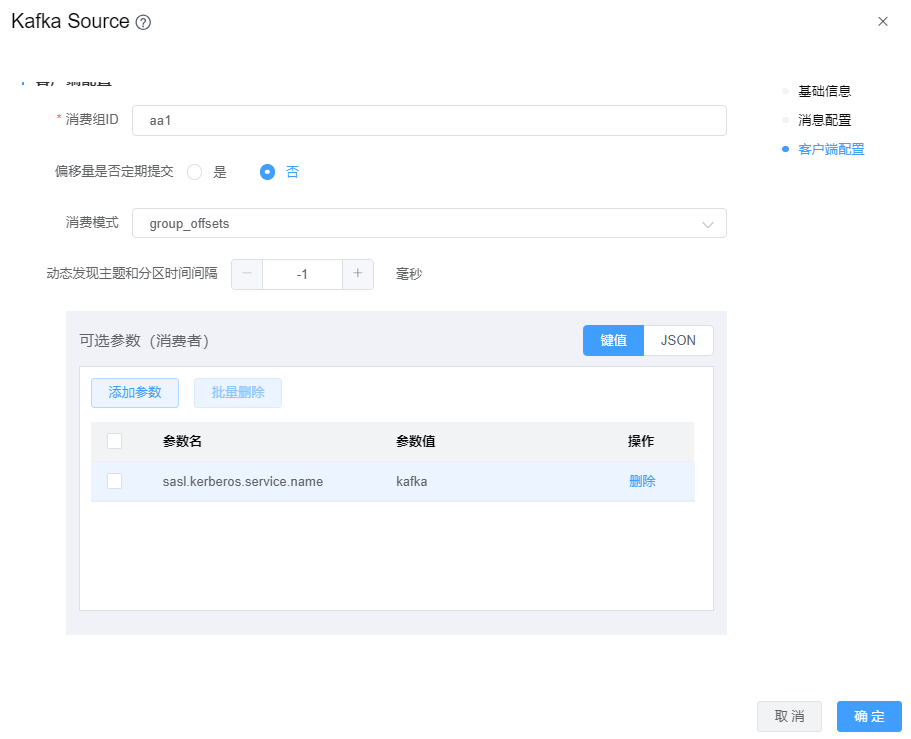
当kafka数据源使用的Kerberos认证时,Kafka Source组件需要在【可选参数】中增加配置项:sasl.kerberos.service.name=kafka,其值
kafka为kafka服务的serviceName。如下图
# StarRocks
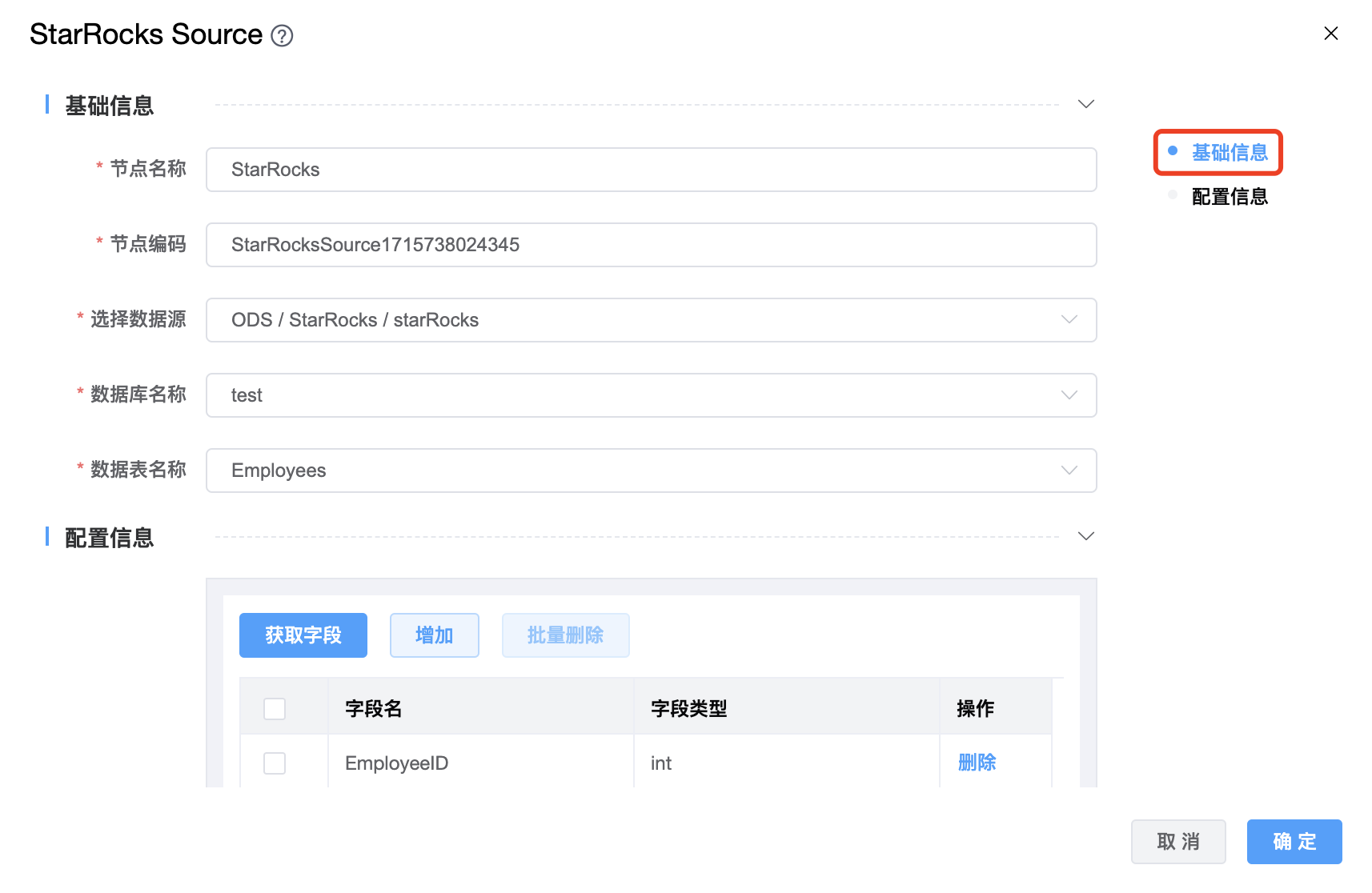
功能介绍: StarRocks Source 连接器。用于从 StarRocks 读取数据。
组件界面:
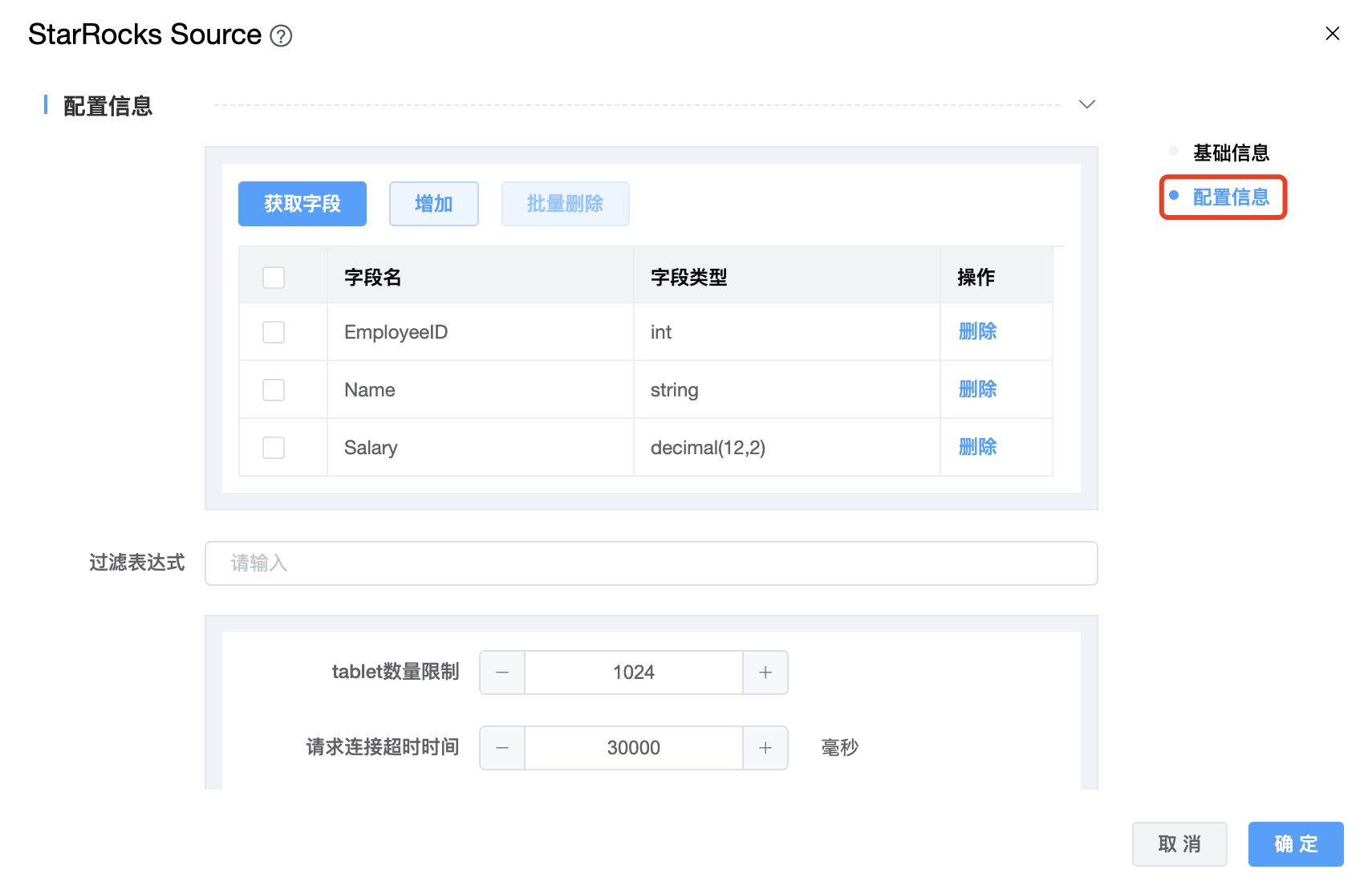
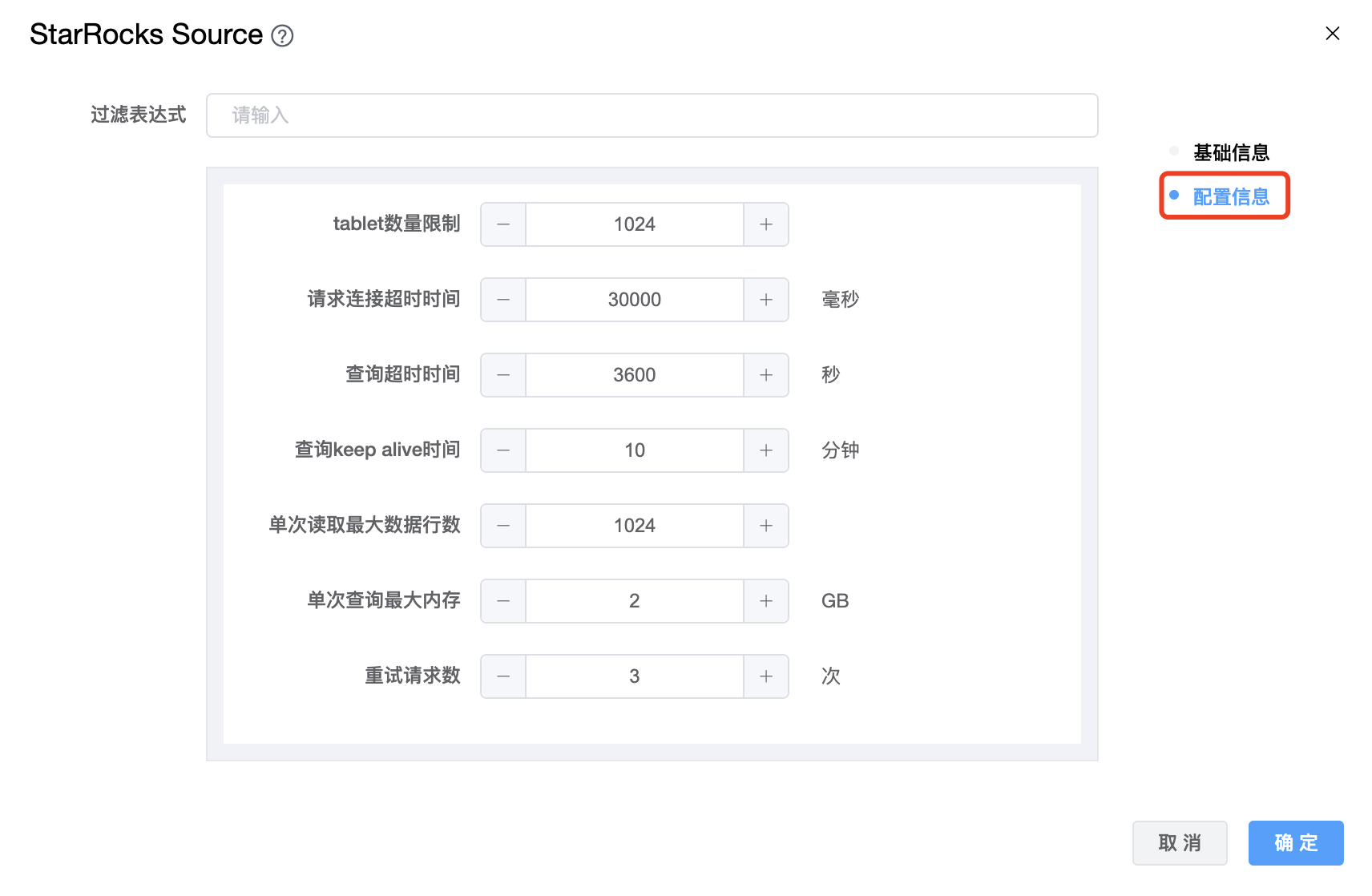
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的 StarRocks Source 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的 StarRocks Source 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | StarRocks Source 的数据源名称,从下拉选项中列出的当前项目已经关联的 StarRocks 数据源进行选择。 |
| 数据库名称 | StarRocks Source 的数据库名称。 |
| 数据表名称 | StarRocks Source 的数据表名称。 |
| 字段数据结构 | 要生成的 StarRocks 的字段数据结构,包括:字段名称和字段类型。 |
| 过滤表达式 | 查询的过滤表达式,StarRocks 使用这个表达式来完成源端数据过滤。 |
| table 数量限制 | 与分区相对应的 StarRocks table 的数量。这个值设置得越小,生成的分区就越多。这将增加引擎方面的并行性,但同时也会给 StarRocks 带来更大的压力。 |
| 请求连接超时时间 | 请求连接超时发送到 StarRocks,单位为毫秒。 |
| 查询超时时间 | 查询 StarRocks 的超时时间,默认值为 1 小时,-1 表示不限制,单位为秒。 |
| 查询 keep alive 时间 | 查询任务的持续时间,单位为分钟。默认值值为 10。建议将该参数设置为大于等于 5 的值。 |
| 单次读取最大数据行数 | 一次从 BE 读取的最大数据行数。增加此值可以减少引擎和 StarRocks 之间建立的连接数量,从而减轻网络延迟造成的开销。 |
| 单次查询最大内存 | BE 节点中单个查询允许的最大内存空间,以字节为单位。默认值为2147483648 (2GB)。 |
| 重试请求数 | 发送到 StarRocks 的重试请求数。 |
# 关系型数据库
功能介绍: 关系型数据库 JDBC Source 连接器。通过 JDBC 读取各类关系型数据库数据。
组件界面:
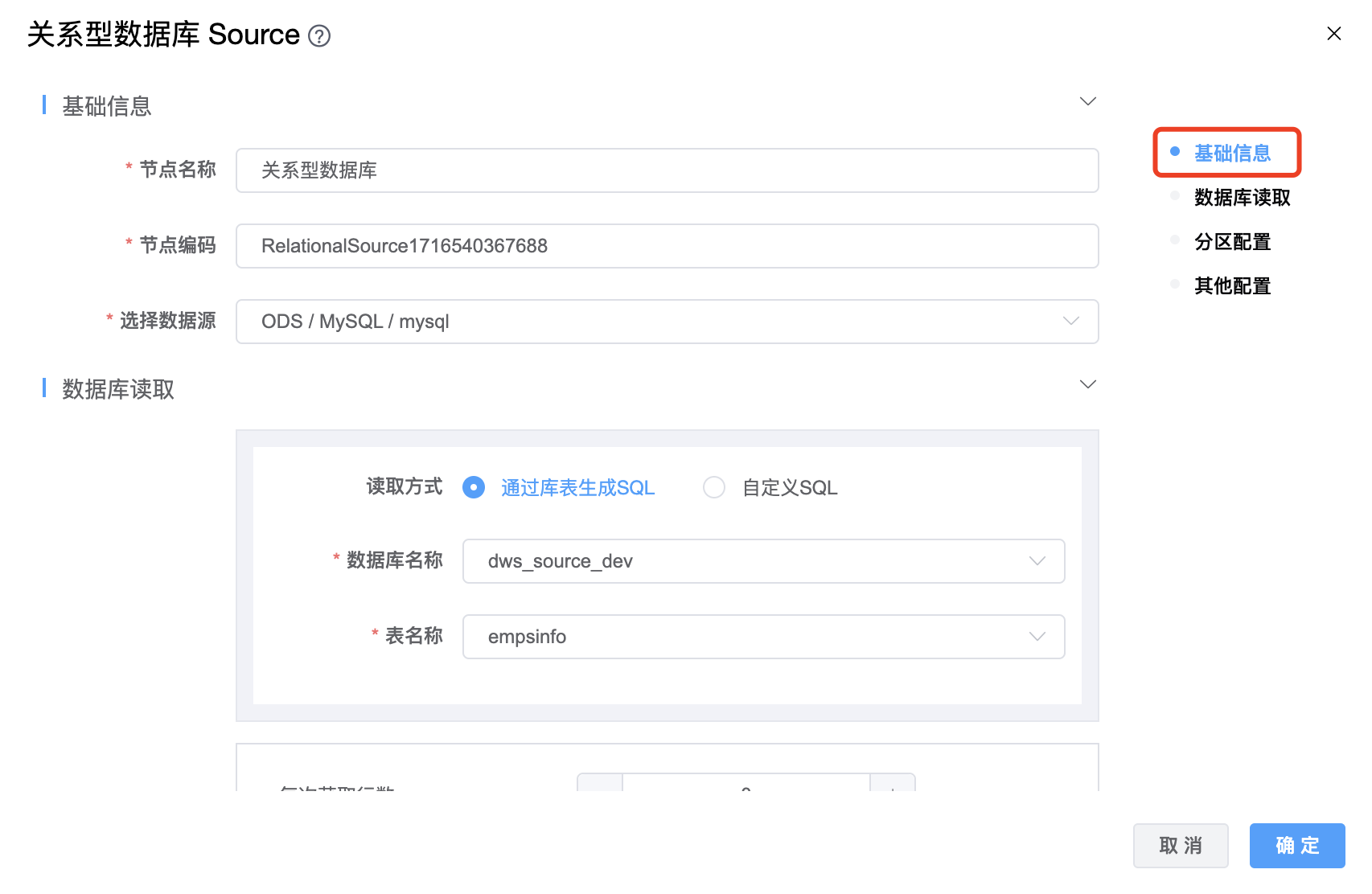
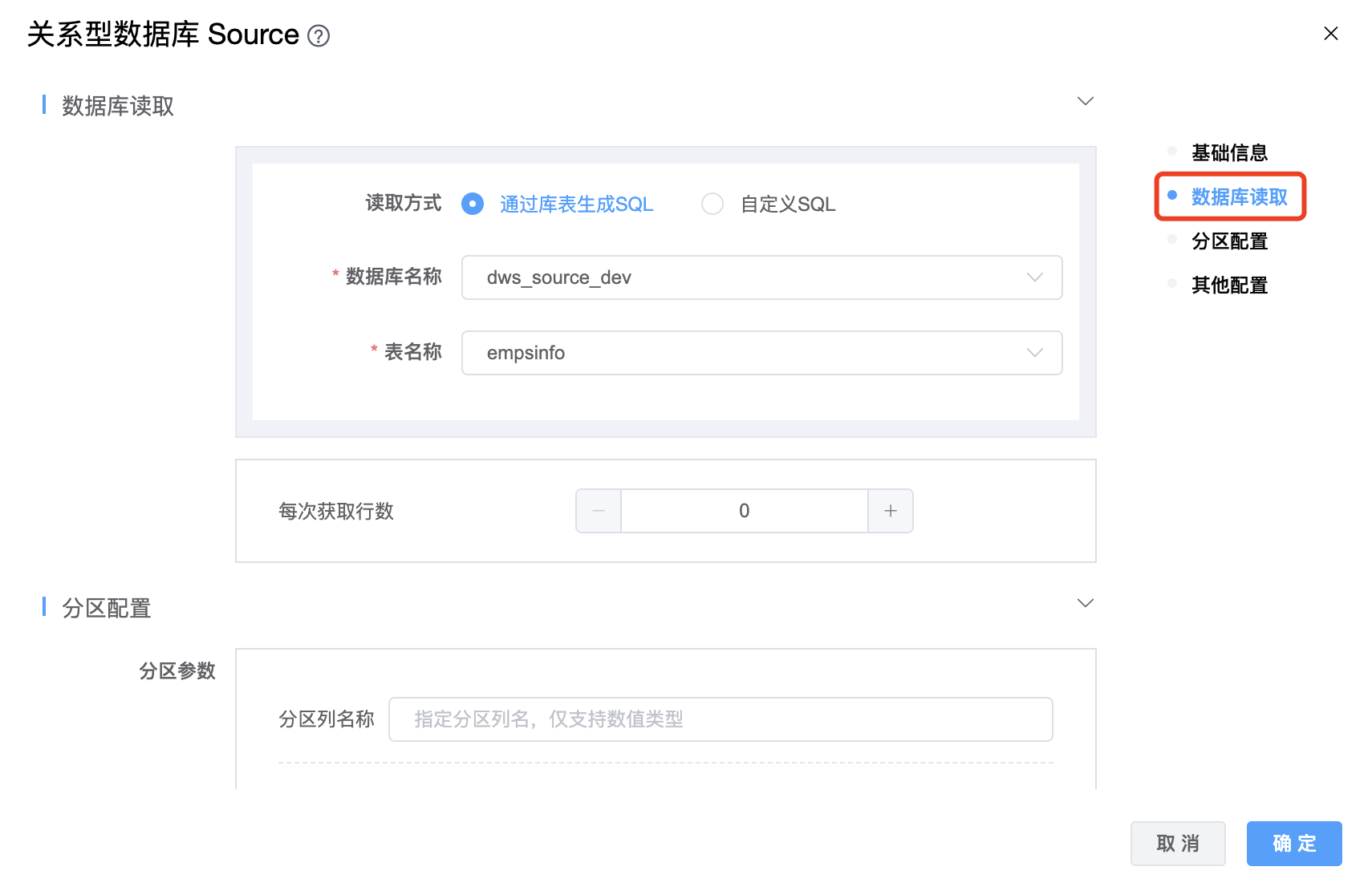
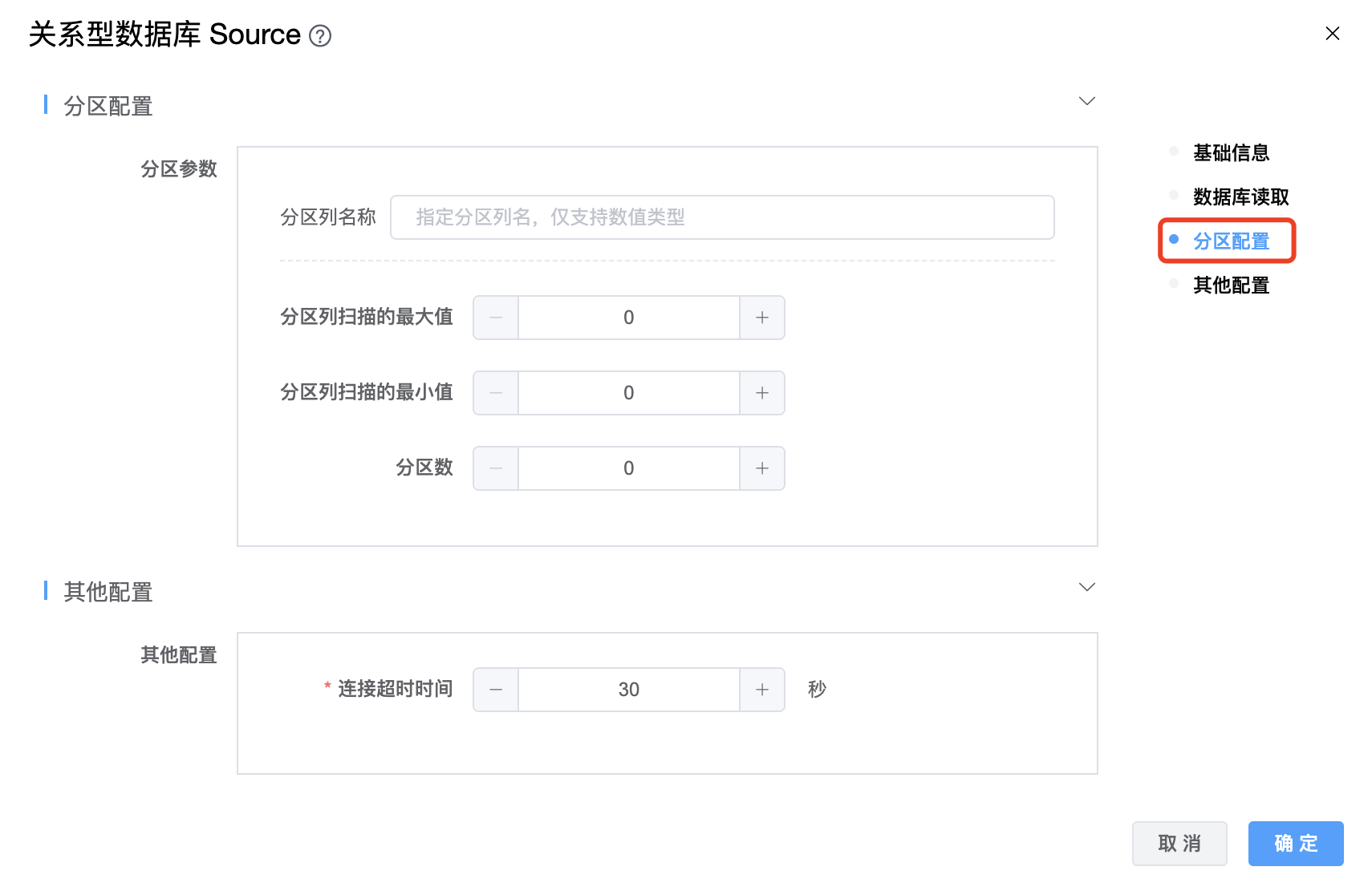
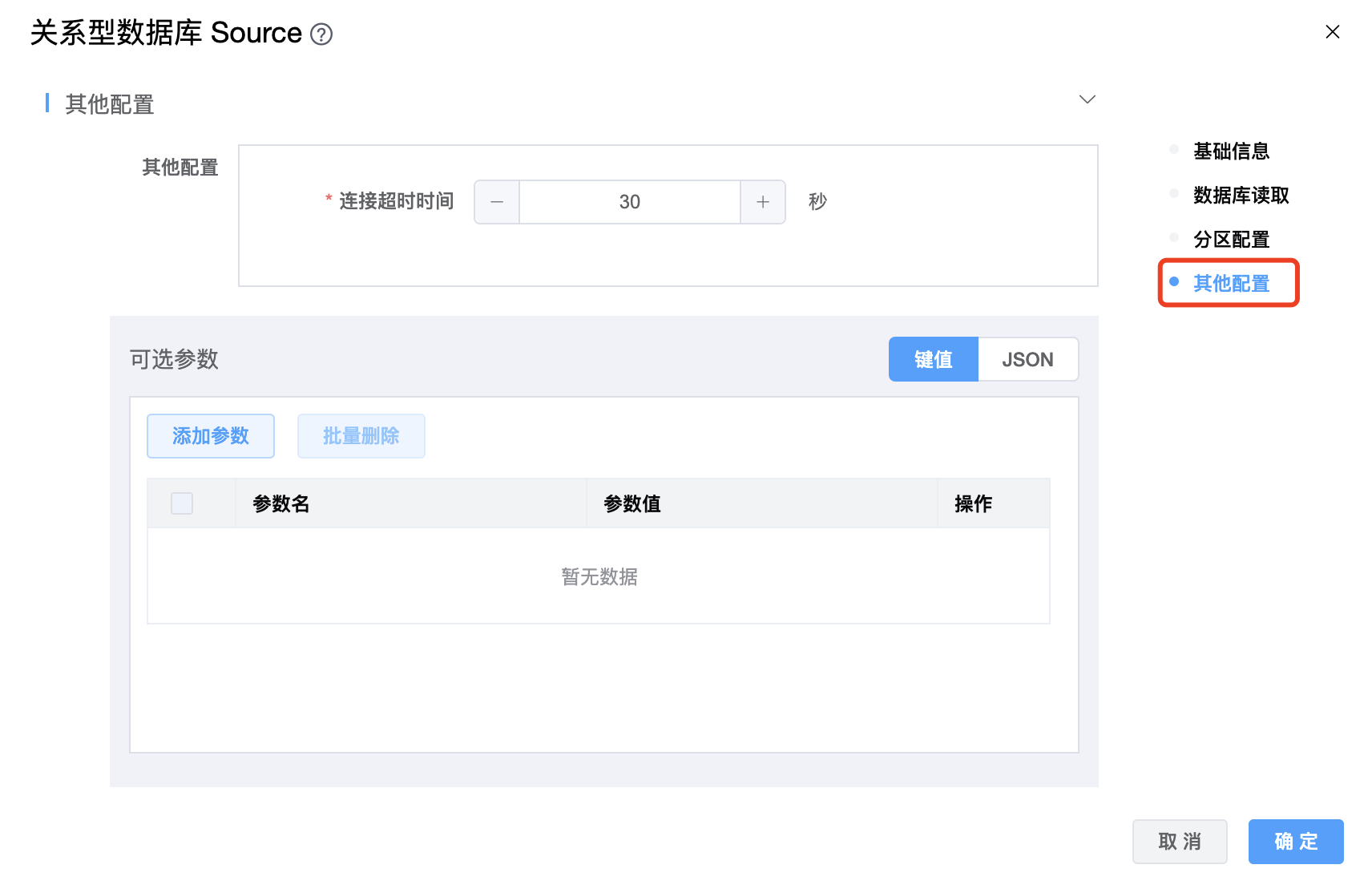
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的关系型数据库 Source 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的关系型数据库 Source 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 关系型数据库 Source 的数据源名称,从下拉选项中列出的当前项目已经关联的关系型数据库数据源进行选择。 |
| 查询 SQL | 采集数据的SQL。 |
| 提取行数 | JDBC 默认每执行一次检索,会从游标中提取行记录,通过设置 row fetch size,可以改变每次和数据库交互,提取出来的记录行总数。 |
| 分区列名称 | 并行分区的列名,只支持数值类型。 |
| 分区列扫描的最大值 | 如果不设置,SeaTunnel 将查询数据库获取最大值。 |
| 分区列扫描的最小值 | 如果不设置,SeaTunnel 将查询数据库获取最小值。 |
| 分区数 | 只支持正整数,默认值为作业并发数。 |
| 连接超时时间 | 连接超时时间,单位为:秒。 |
| 可选参数 | 关系型数据库 Source 的其他参数,用户可以根据需求进行配置。 |
# CDC
功能介绍: CDC Source 连接器。支持从 MySQL、SQL Server、PostgreSQL、MongoDB 数据库读取数据。
组件界面:
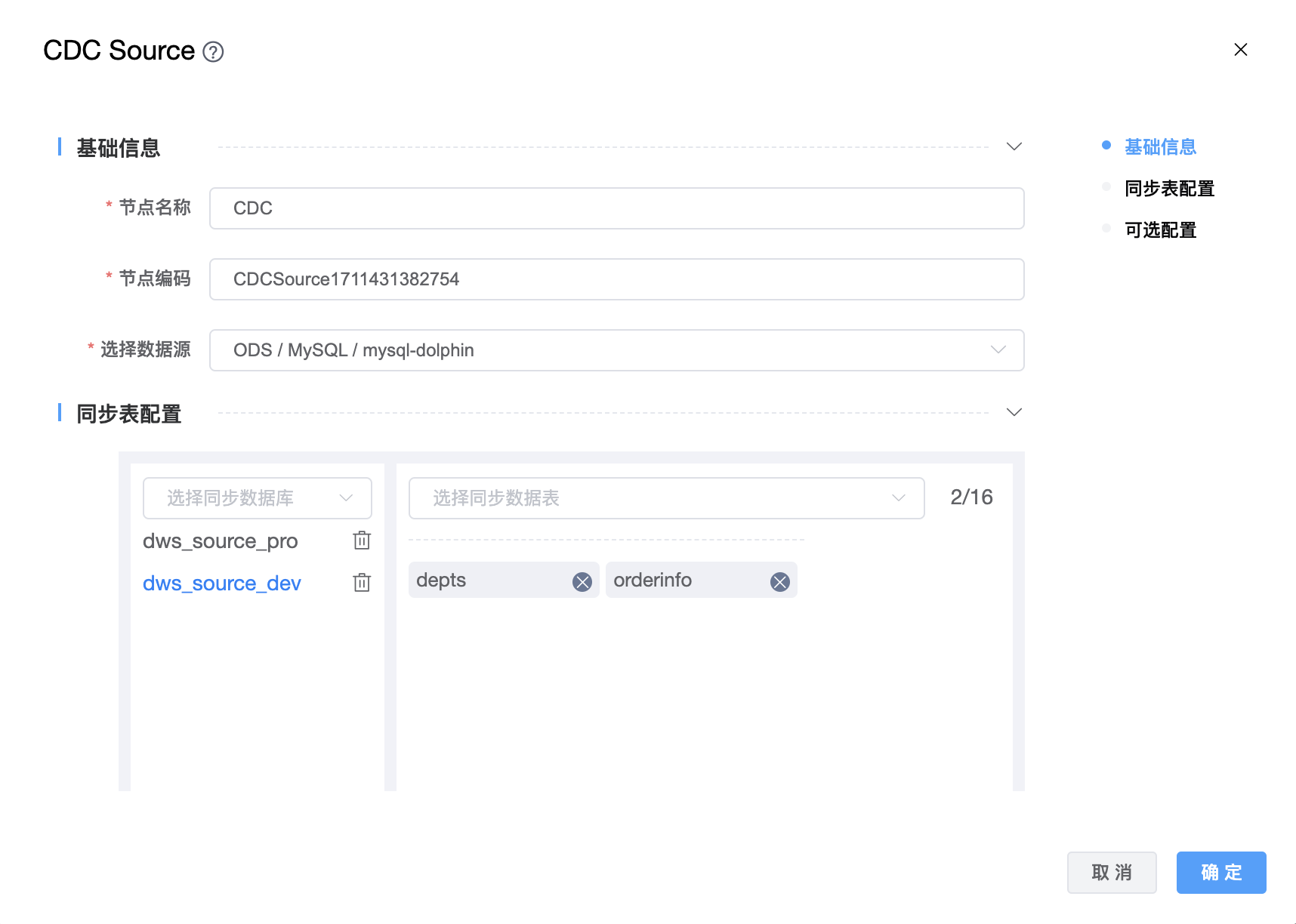
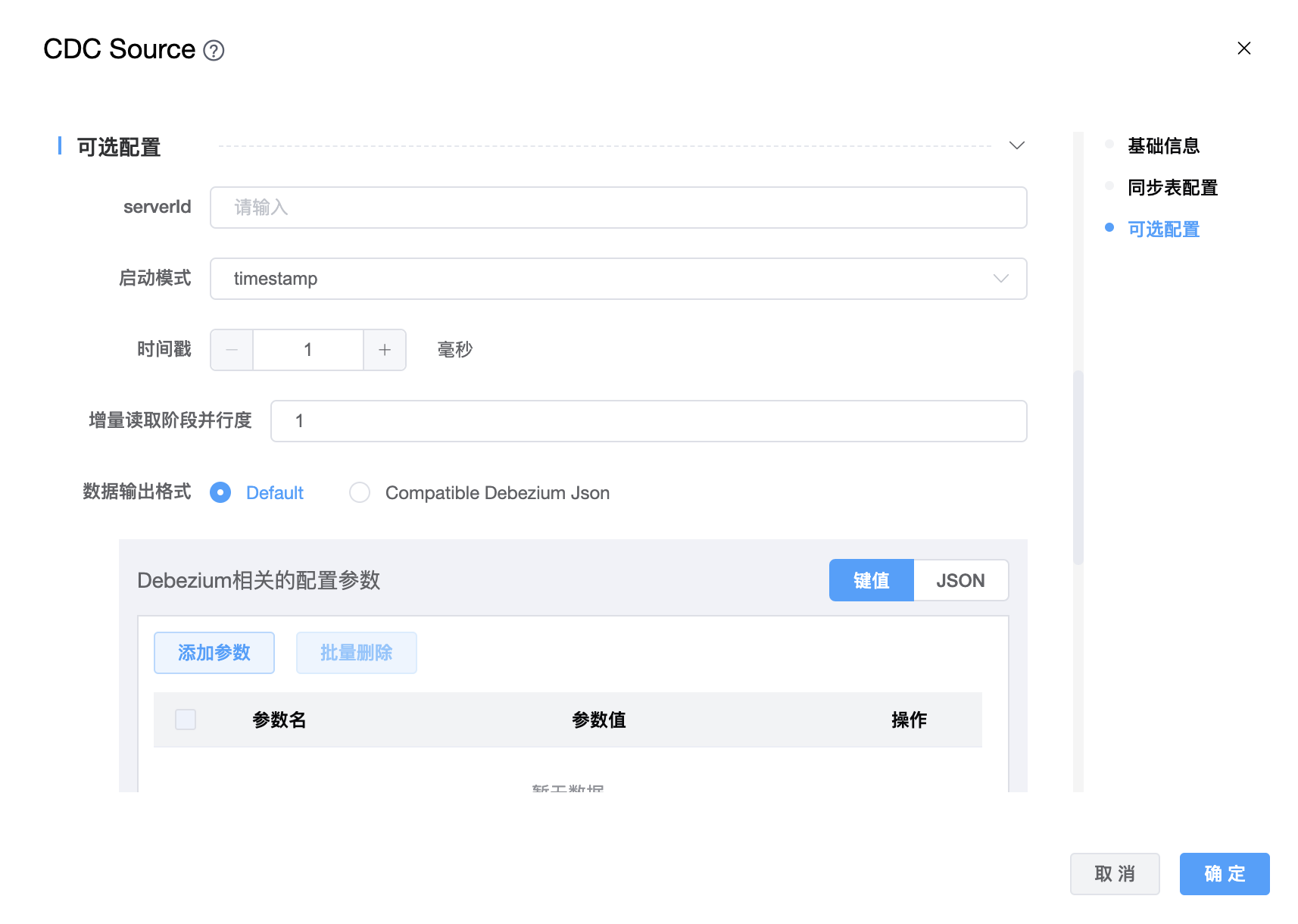
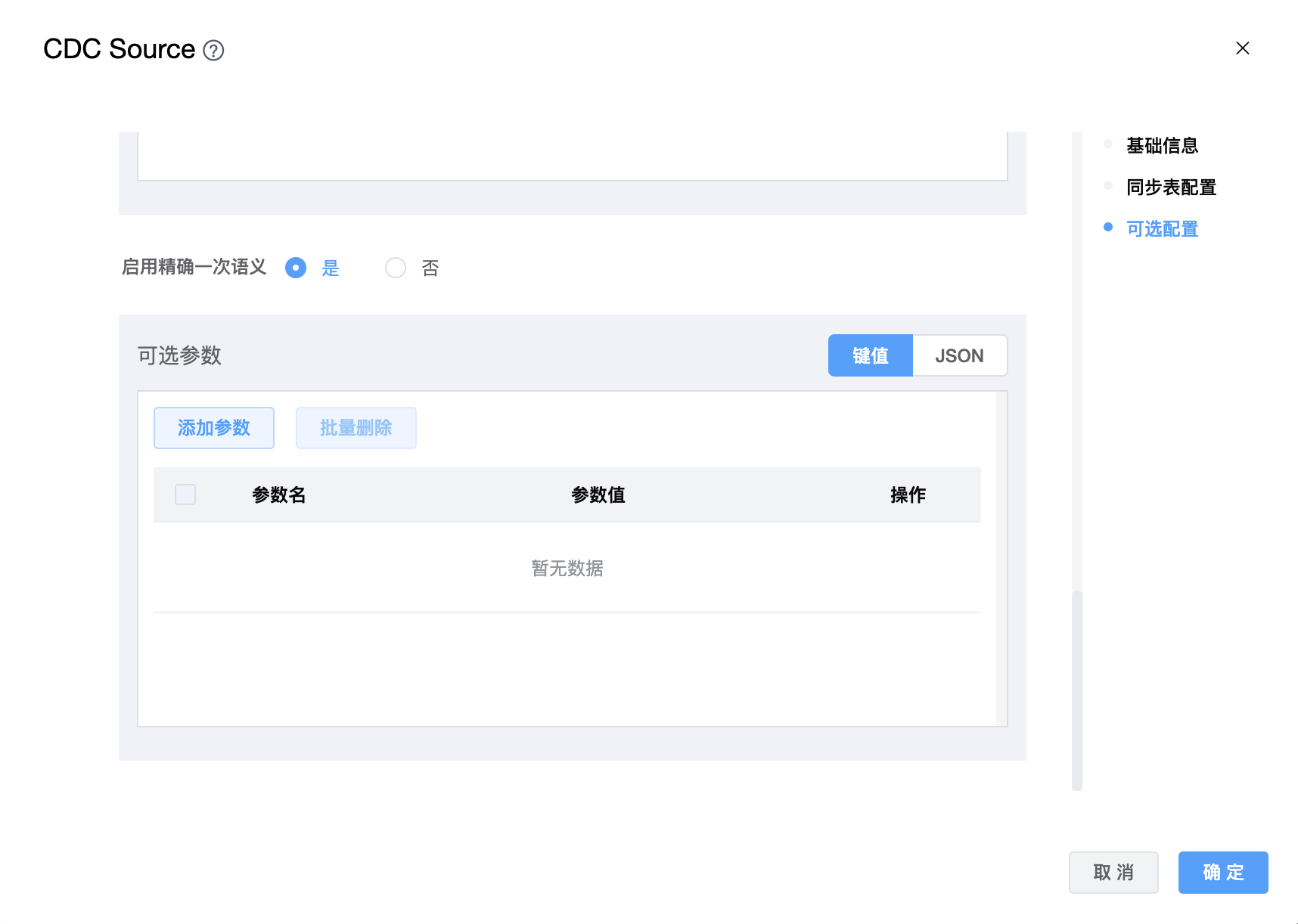
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的关系型数据库 Source 节点名称,由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 当前创建的关系型数据库 Source 节点编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 从下拉选项中选择列出的当前项目已经关联的数据源。 |
| 选择同步数据库 | 从下拉列表中选择数据源下的数据库,可以多选。 |
| 选择同步数据表 | 从下拉列表中选择数据库下的表,可以多选。 |
| serverid | 数据库客户端的数字ID或数字ID范围,语法类似“5400”,数字ID范围语法类似“5400-5408”。在数据库集群中所有当前运行的数据库进程中,每个ID都必须是唯一的。默认生成的随机数介于5400和6400之间。 |
| 启动模式 | 有五种:initial、earliest、latest、specific、timestamp。 |
| 时间戳 | 从指定的时间戳开始(以毫秒为单位)。当“启动模式”选择“timestamp”时,此选项是必需的。 |
| 增量读取阶段并行度 | 增量阶段中的并行读卡器的数量。 |
| 数据输出格式 | Default、Compatible Debezium Json |
| Debezium 相关的配置参数 | 将 Debezium 的属性传递到 Debezium 嵌入式引擎,该引擎用于从数据库服务器捕获数据更改。用户可以根据需求进行配置。 |
| 启用精确一次语义 | Boolean类型:是、否。是否启用一次语义。 |
| 可选参数 | CDC 其他参数,用户可以根据需求进行配置。 |
# Hive
功能介绍:Hive Source 连接器。用于从 Hive 读取数据。
组件界面:
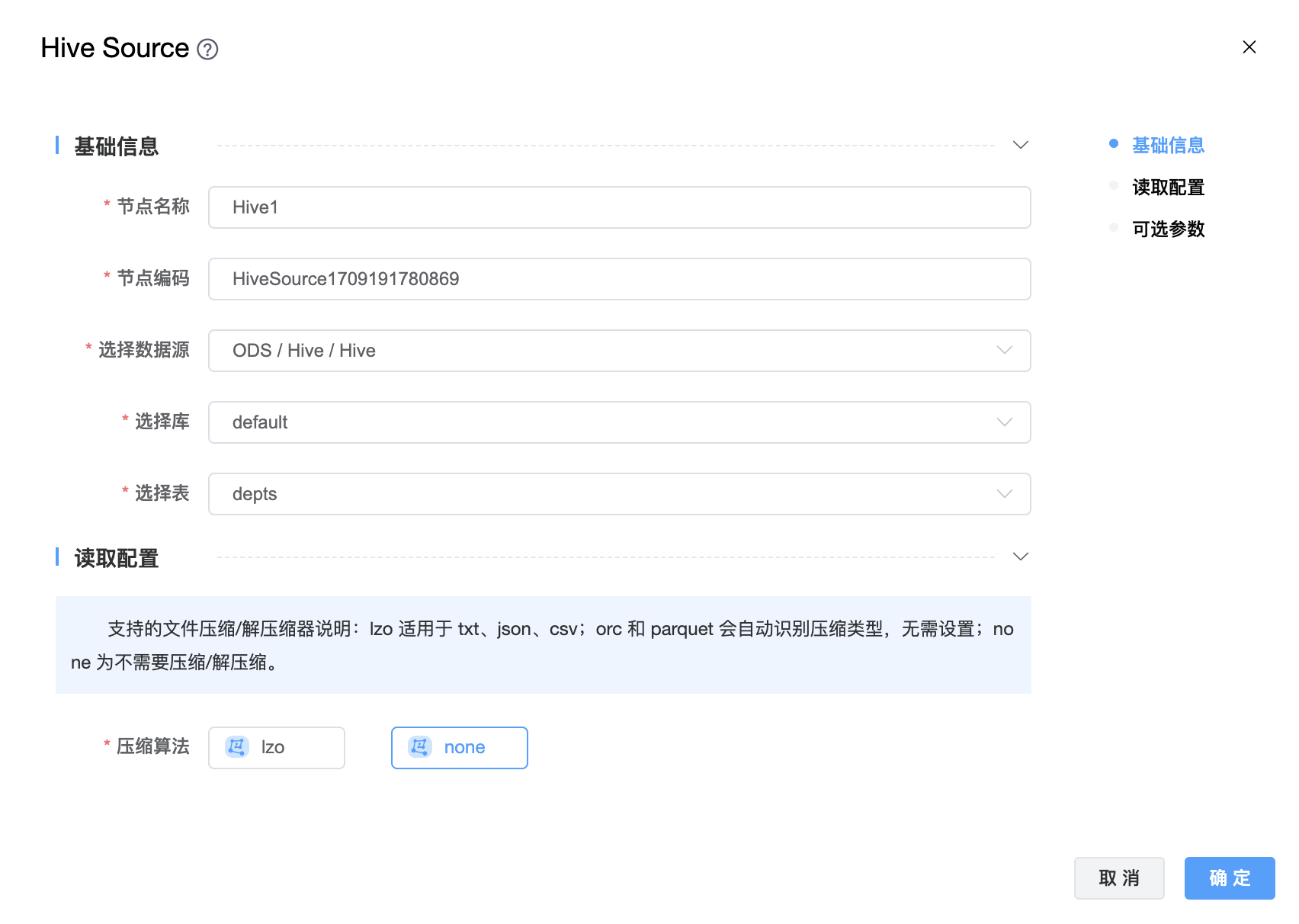
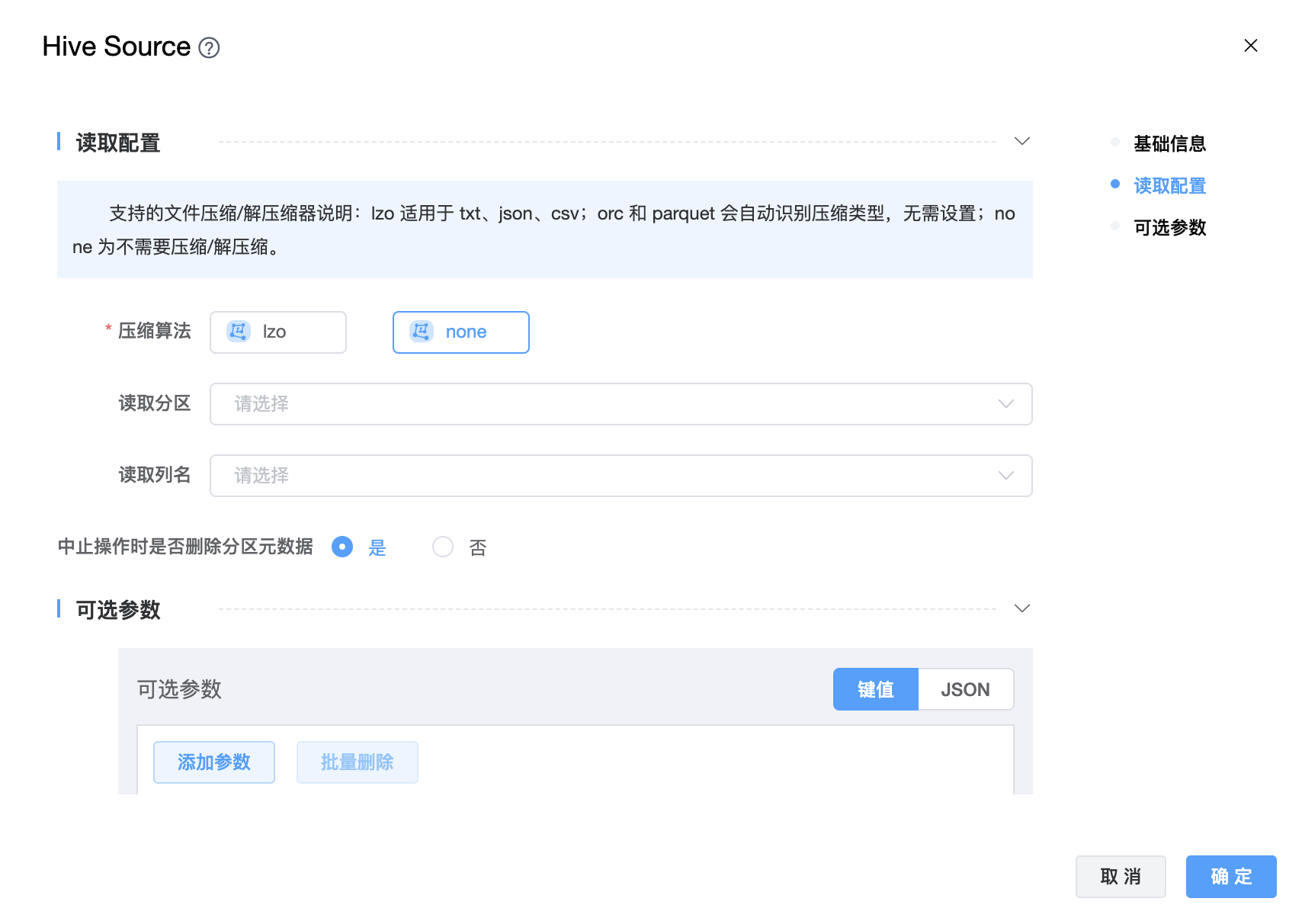
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 从下拉选项中选择列出的当前项目已经关联的 Hive 数据源。 |
| 选择库 | 选择数据库名称。 |
| 选择表 | 选择数据表名称。 |
| 压缩算法 | lzo 适用于 txt、json、csv;orc 和 parquet 会自动识别压缩类型,无需设置;none 为不需要压缩/解压缩。 |
| 读取分区 | 从配置单元表中读取的目标分区,如果不设置此参数,将从配置单元中读取所有数据。 |
| 读取列名 | 读取数据源的列,可以使用它来实现字段投影。 |
| 中止操作时是否删除分区元数据 | 在中止操作期间是否从配置单元元存储中删除分区元数据的标志。注意:这只会影响元存储中的元数据,分区中的数据将始终被删除(同步过程中生成的数据)。 |
| 可选参数 | 其他配置参数,用户可以根据需求进行配置。 |
# Inceptor
功能介绍:星环 Inceptor 连接器。用于从 Inceptor 读取数据。
组件界面:
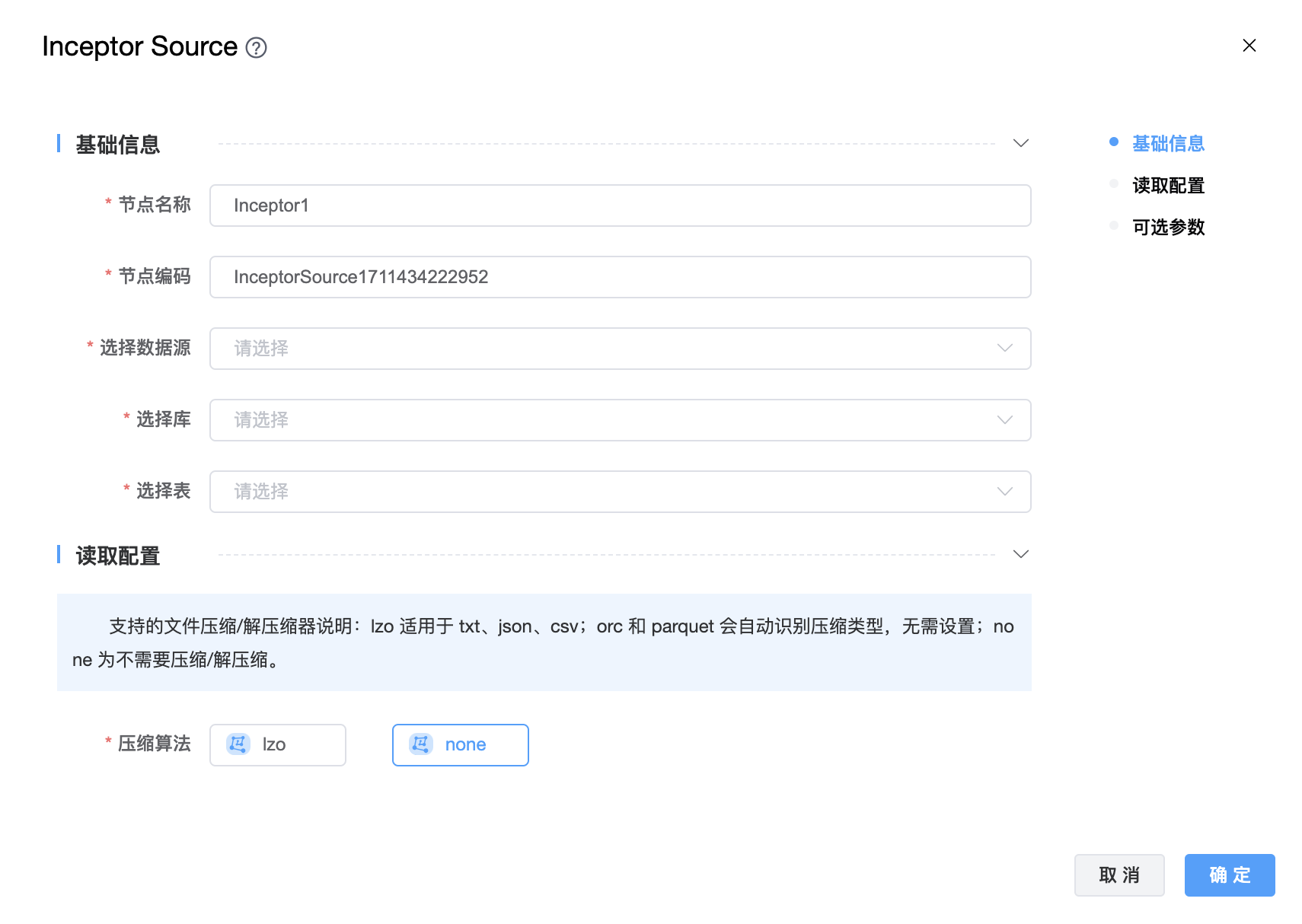
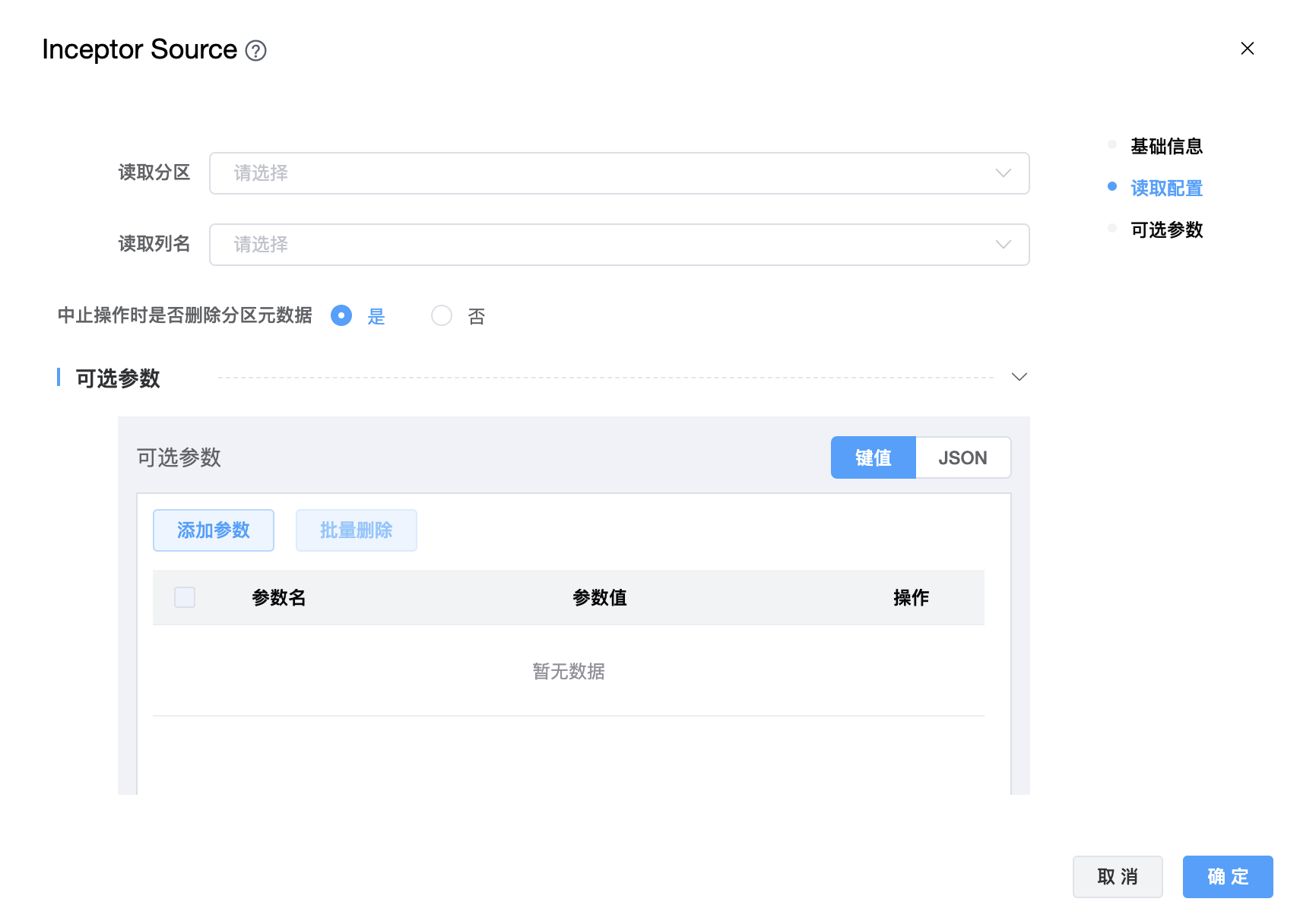
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 从下拉选项中选择列出的当前项目已经关联的 Hive 数据源。 |
| 选择库 | 选择数据库名称。 |
| 选择表 | 选择数据表名称。 |
| 压缩算法 | lzo 适用于 txt、json、csv;orc 和 parquet 会自动识别压缩类型,无需设置;none 为不需要压缩/解压缩。 |
| 读取分区 | 从配置单元表中读取的目标分区,如果不设置此参数,将从配置单元中读取所有数据。 |
| 读取列名 | 读取数据源的列,可以使用它来实现字段映射。 |
| 中止操作时是否删除分区元数据 | 在中止操作期间是否从配置单元元存储中删除分区元数据的标志。注意:这只会影响元存储中的元数据,分区中的数据将始终被删除(同步过程中生成的数据)。 |
| 可选参数 | 其他配置参数,用户可以根据需求进行配置。 |
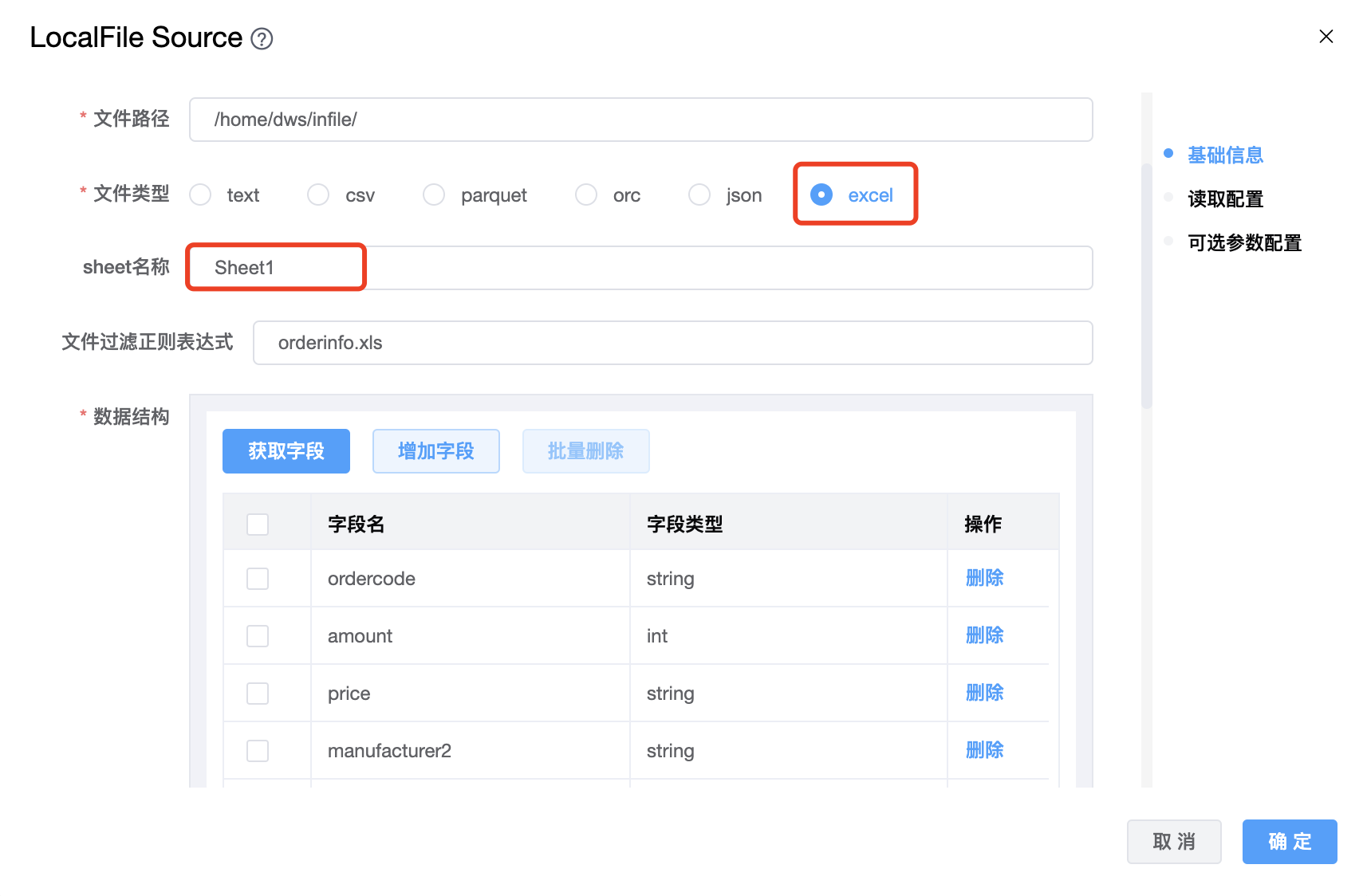
# LocalFile
功能介绍:LocalFile 连接器。用于从本地文件系统读取数据。
组件界面:
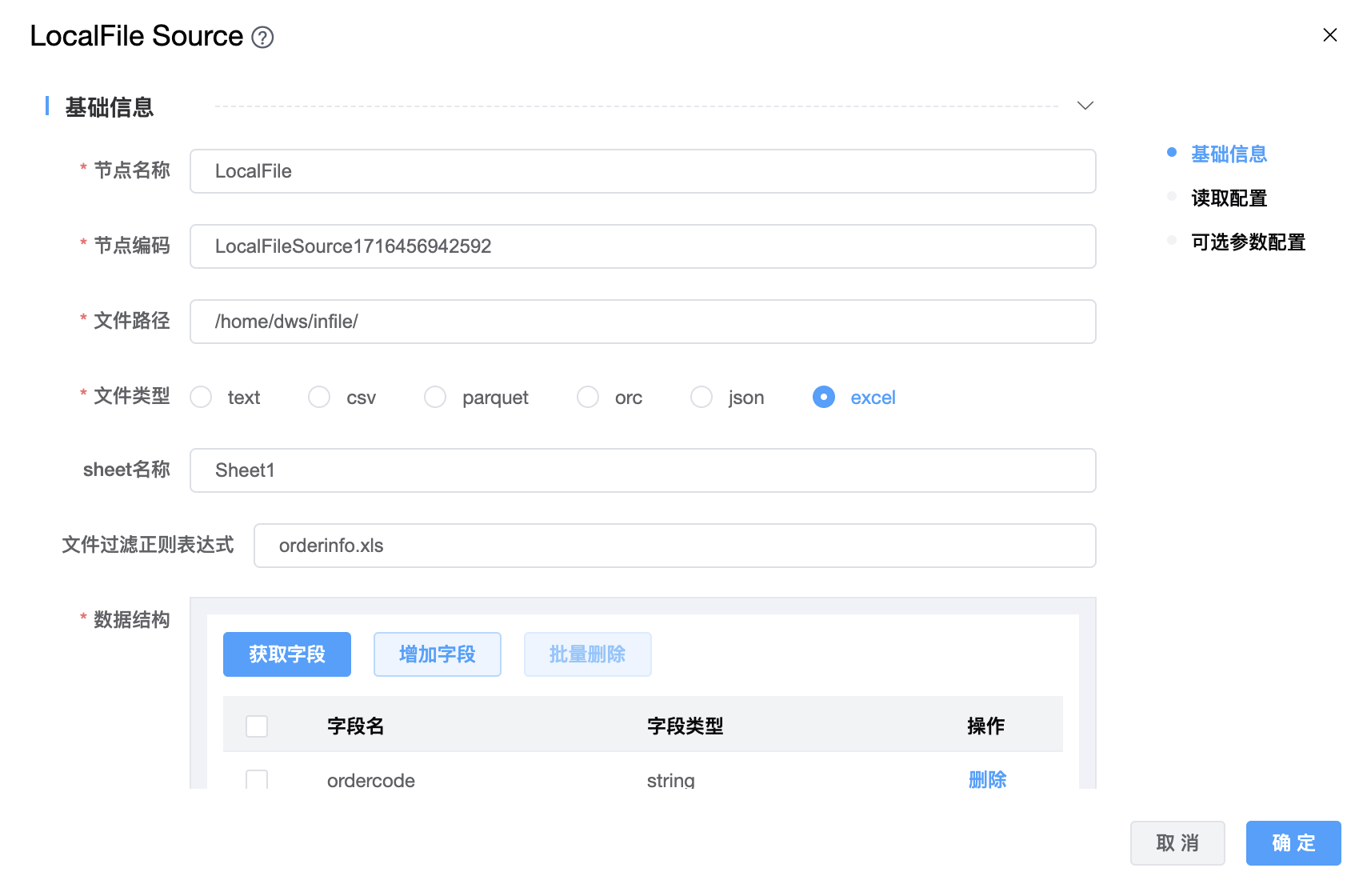
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 文件路径 | 源文件路径。 |
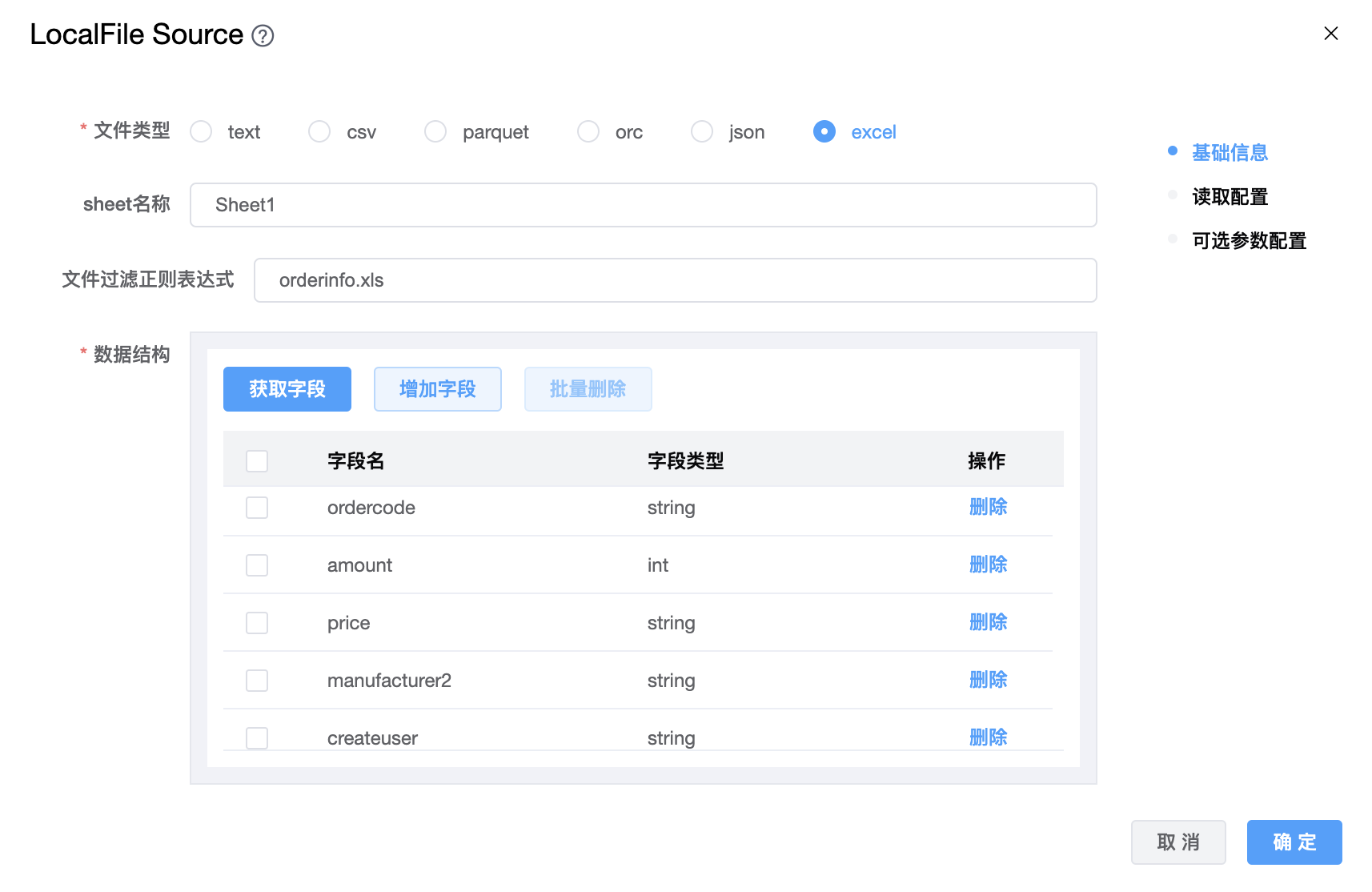
| 文件类型 | 支持:text、csv、parquet、orc、json、excel 六种文件类型。 注意:选择 excel 文件时,请务必删除表头,只保留数据。 |
| 文件过滤正则表达式 | 过滤器模式,用于过滤文件。 |
| 数据结构 | 获取的上游字段的信息。 |
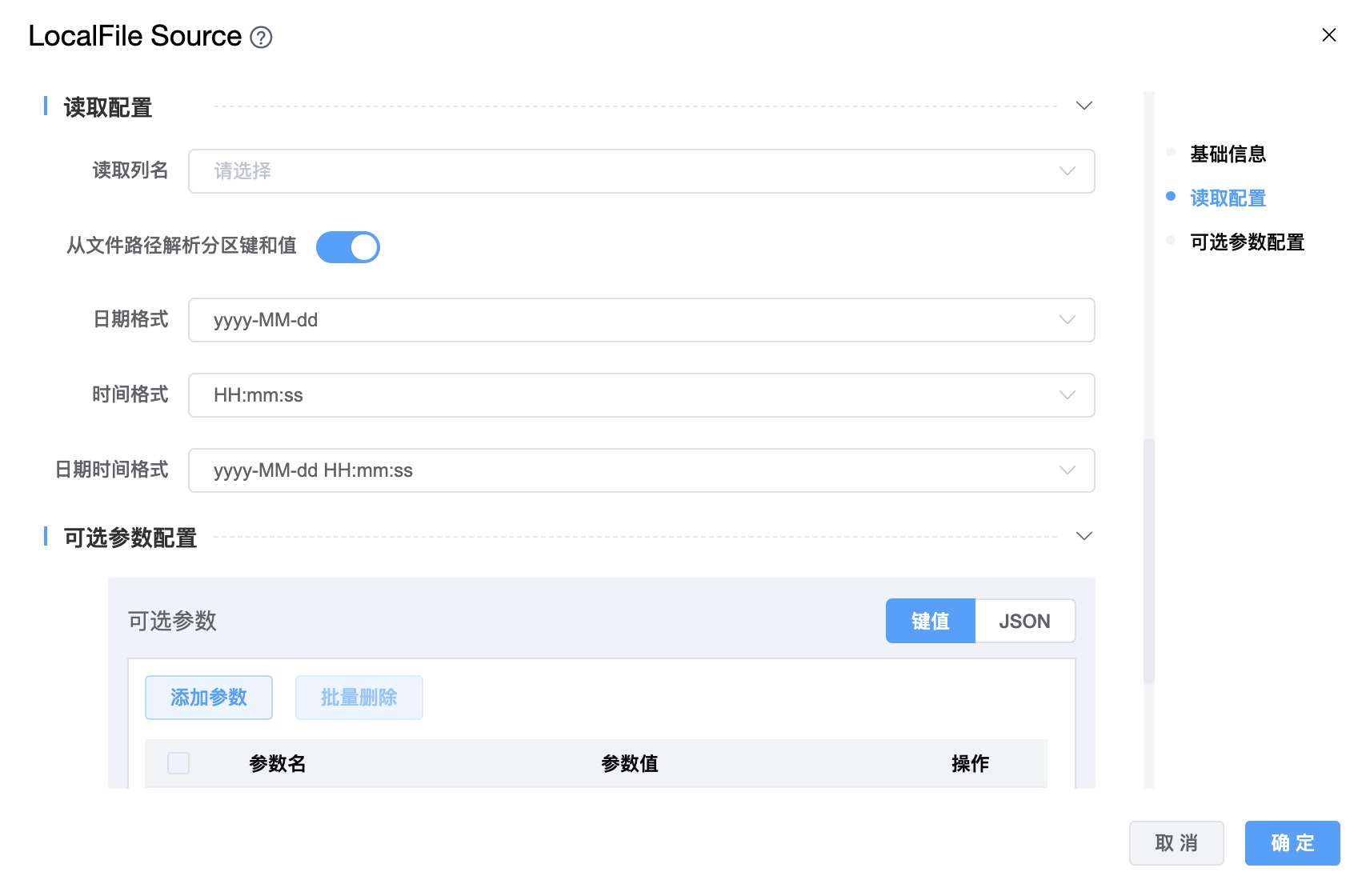
| 读取列名 | 读取数据源的列,可以使用它来实现字段映射。 |
| 分隔符 | 用于告诉连接器在读取文本文件时如何分割字段,默认值是 \001,与配置单元的默认分隔符相同。 |
| 从文件路径解析分区键和值 | 控制是否从文件路径解析分区键和值。例如,如果从路径读取文件file://hadoop-cluster/tmp/seatunnel/parquet/name=tyrantlucifer/age=26。 |
| 日期格式 | 将字符串转换为日期,支持格式:yyyy-MM-dd、yyyy.MM.dd、yyyy/MM/dd,默认是 yyyy-MM-dd。 |
| 时间格式 | 将字符串转换为时间,支持格式:HH:mm:ss、HH:mm:ss.SSS,默认是 HH:mm:ss。 |
| 日期时间格式 | 将字符串转换为日期时间,支持格式:yyyy-MM-dd HH:mm:ss、yyyy.MM.dd HH:mm:ss、yyyy/MM/dd HH:mm:ss、yyyyMMddHHmmss,默认是 yyyy-MM-dd HH:mm:ss。 |
| 可选参数 | 其他配置参数,用户可以根据需求进行配置。 |
选择不同文件类型时的参数配置注意事项:
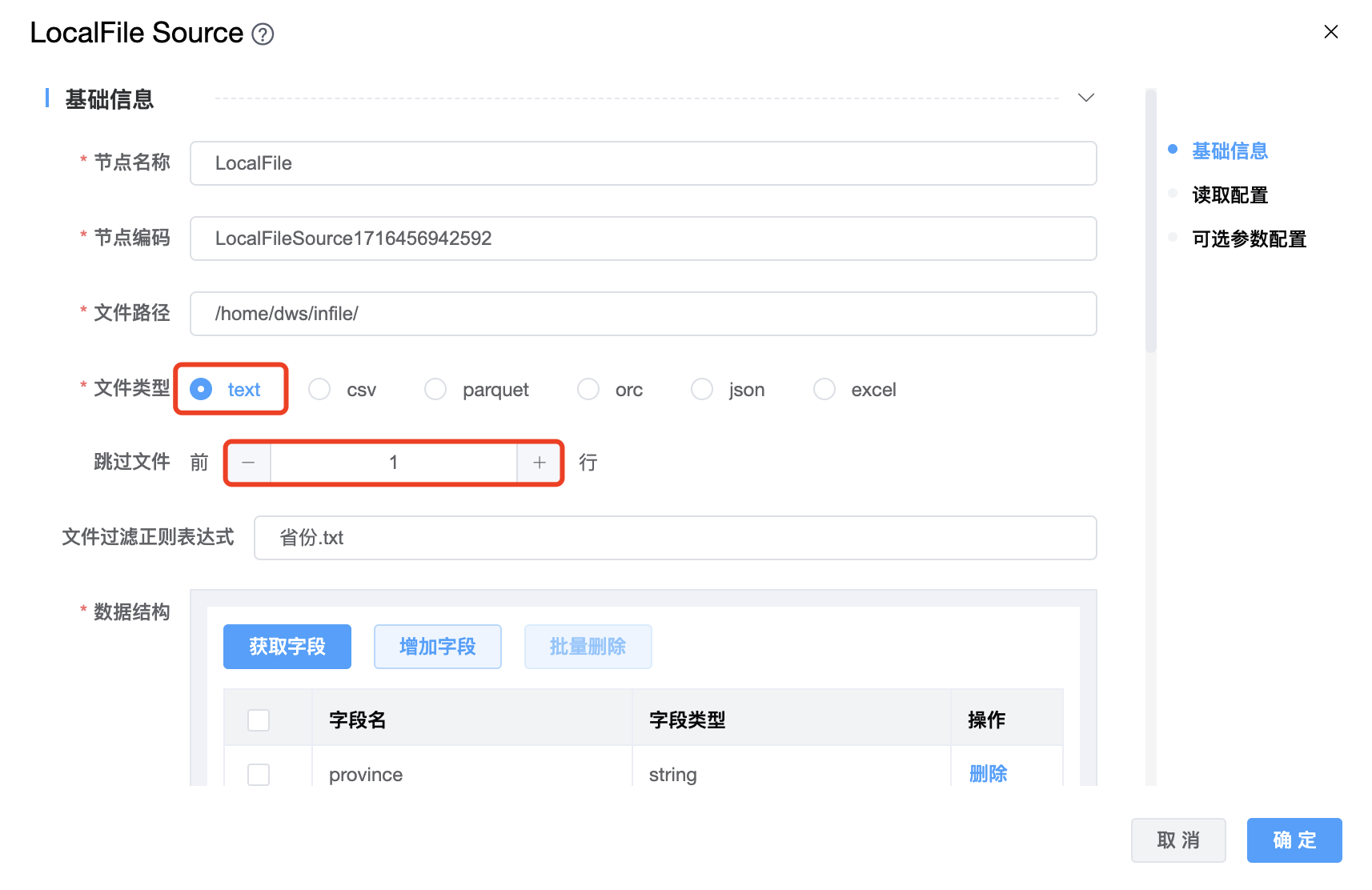
1、文件类型为 text 时:
如果 txt 文件第一行是表头时,需要配置"跳过文件前的行数",需要跳过多少行就配置相应的行数。
例如:province 是表头
province
黑龙江
吉林
辽宁
内蒙古
2、文件类型为 csv 时:
如果 csv 文件第一行是表头时,需要配置"跳过文件前的行数",需要跳过多少行就配置相应的行数。
例如:id,name,gender 是表头
id,name,gender
100,Jack,male
101,John,male
102,Joan,female
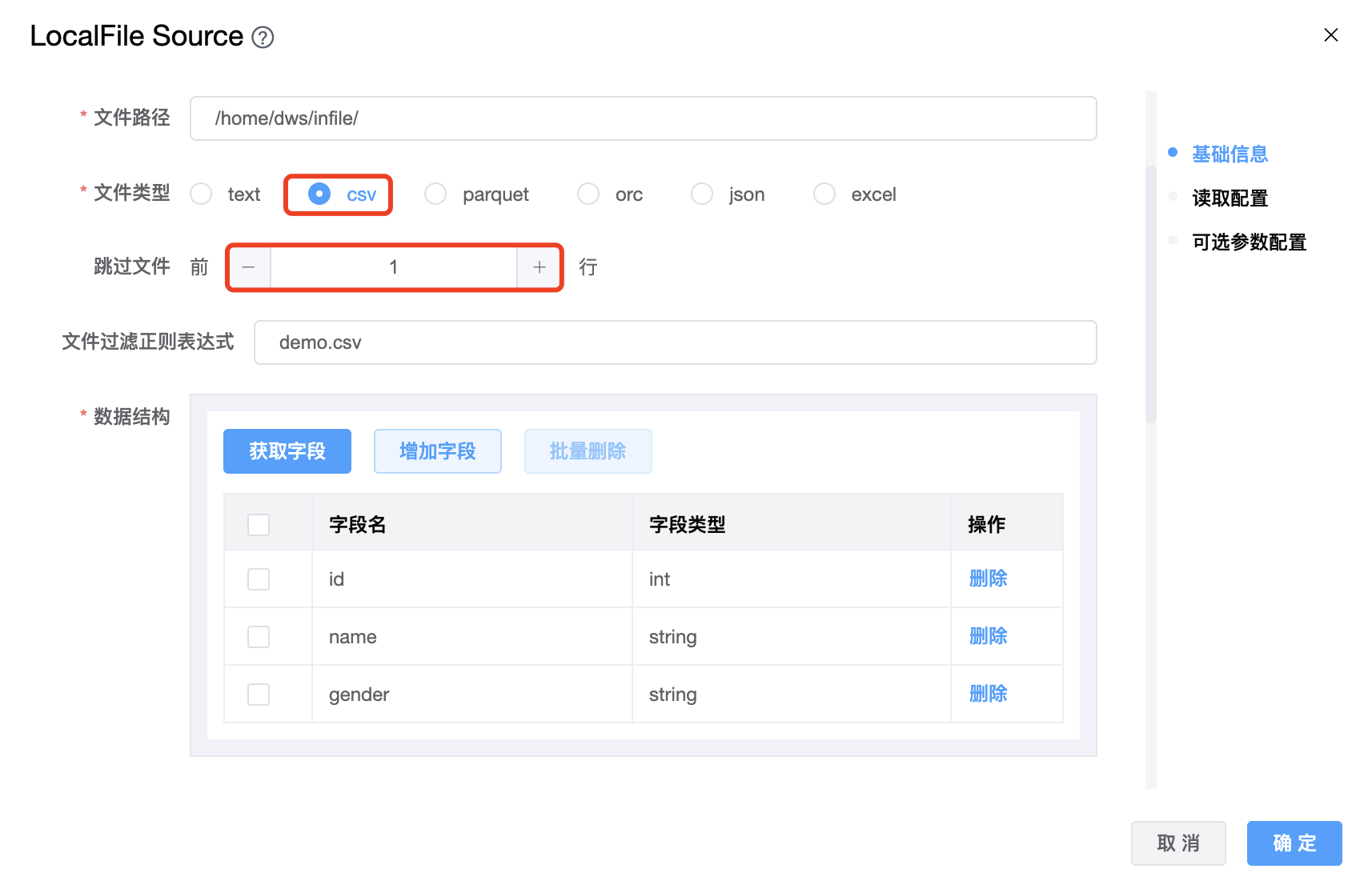
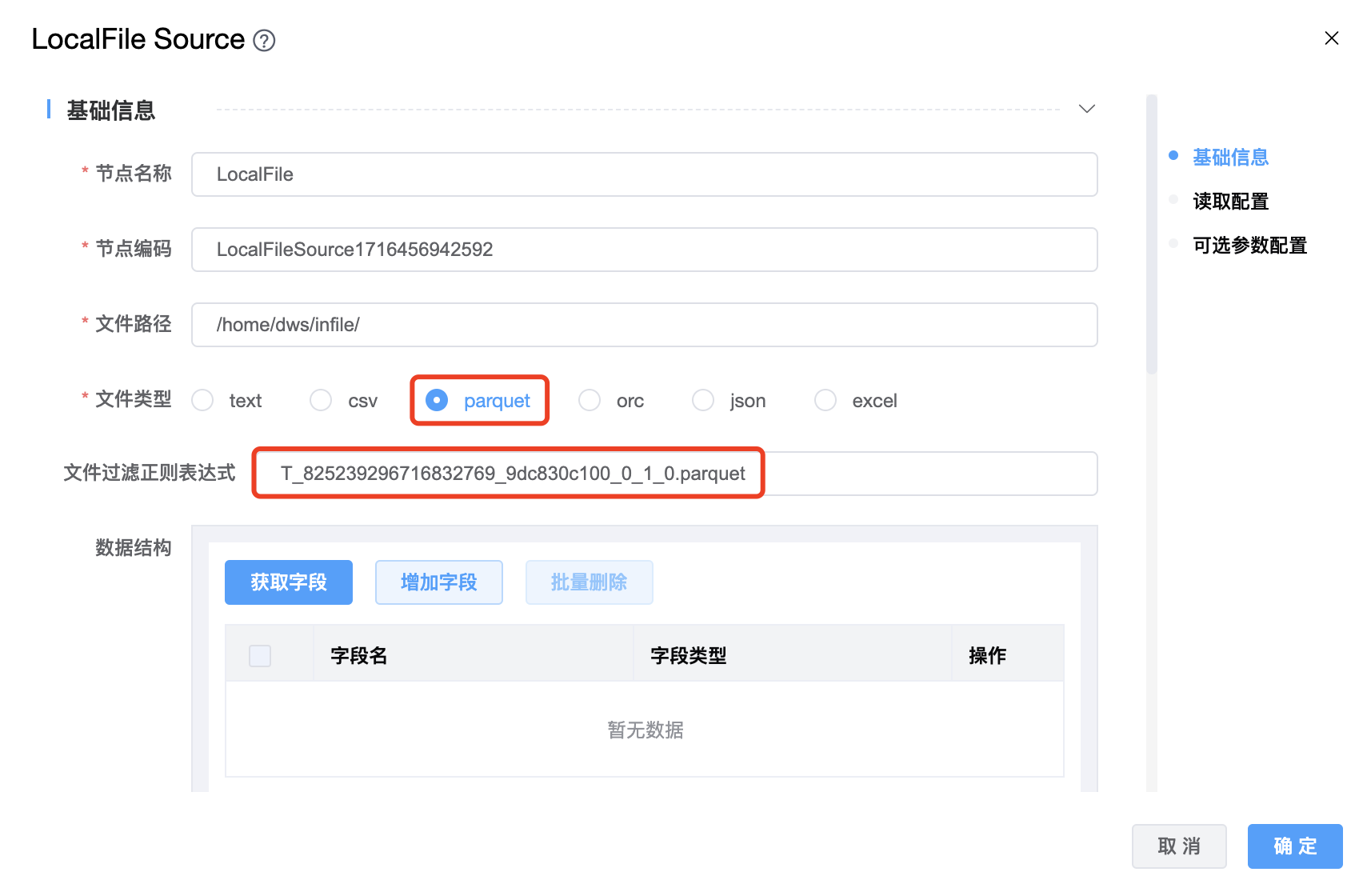
3、文件类型为 parquet 时:
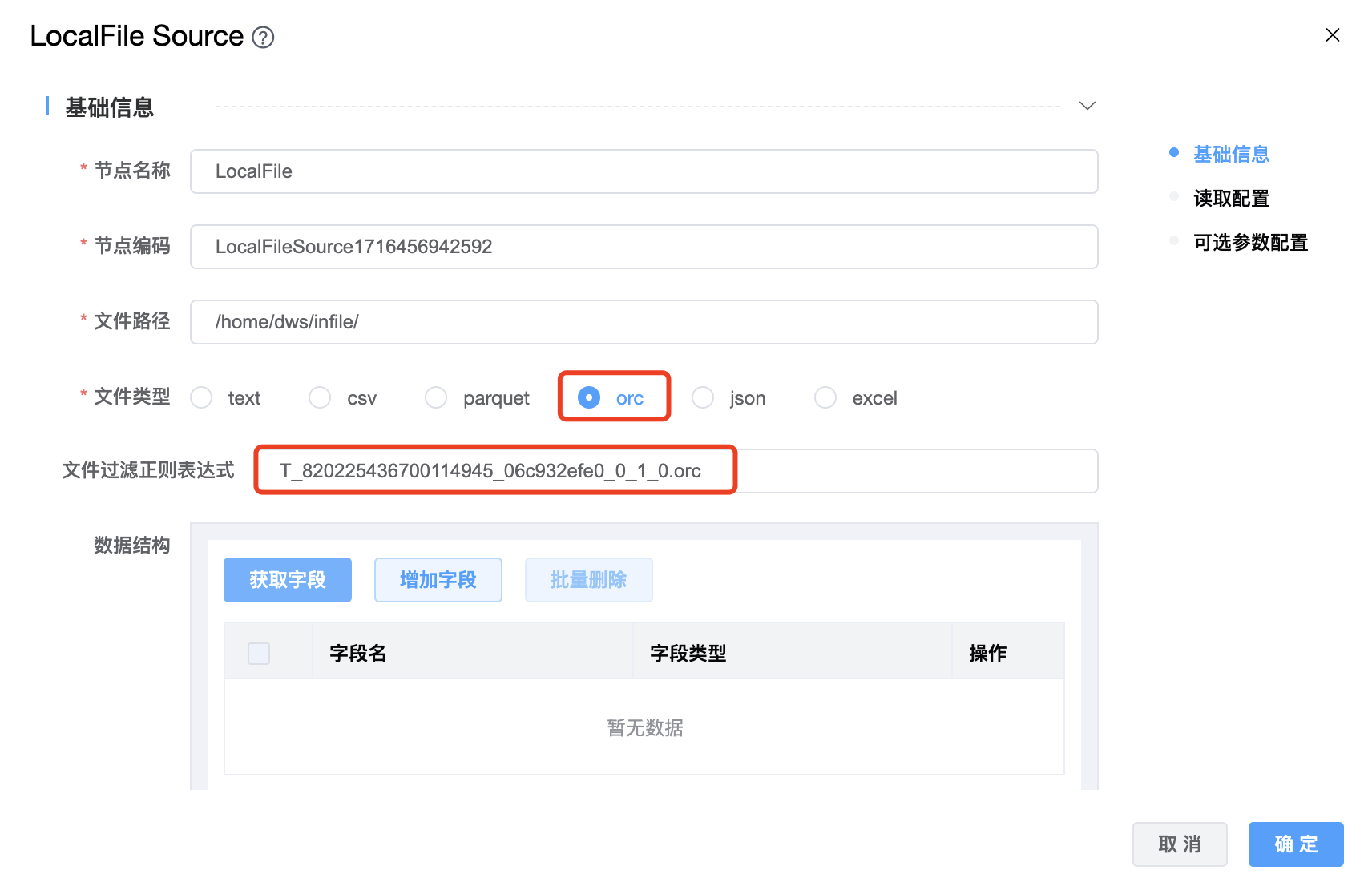
4、文件类型为 orc 时:
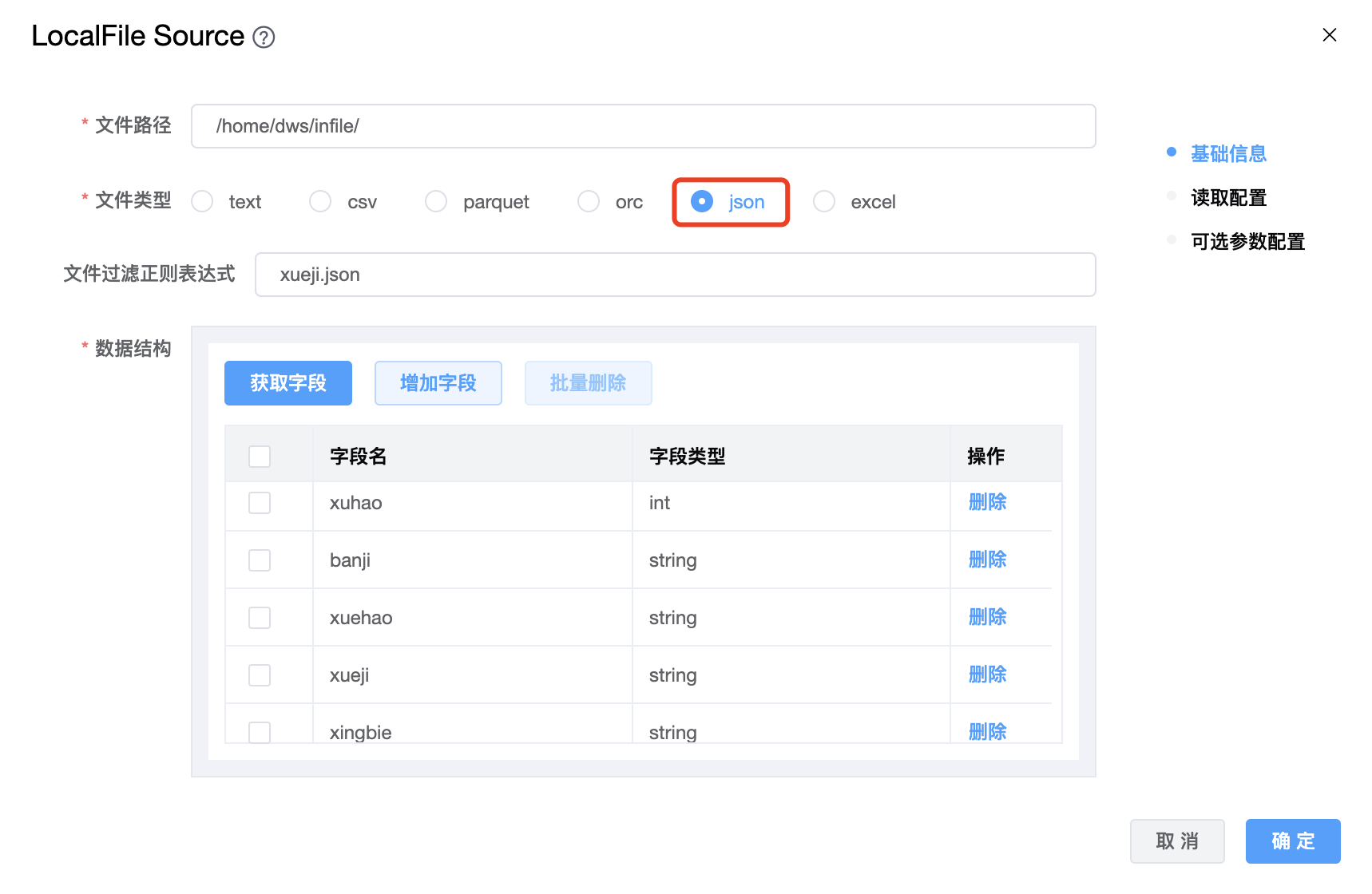
5、文件类型为 json 时:
例如:
{"xuhao": 1,"banji": "1班","xuehao": "2023-0001","xueji": "陕西","xingbie": "男"}
{"xuhao": 2,"banji": "2班","xuehao": "2023-0002","xueji": "河南","xingbie": "女"}
{"xuhao": 3,"banji": "3班","xuehao": "2023-0003","xueji": "陕西","xingbie": "男"}
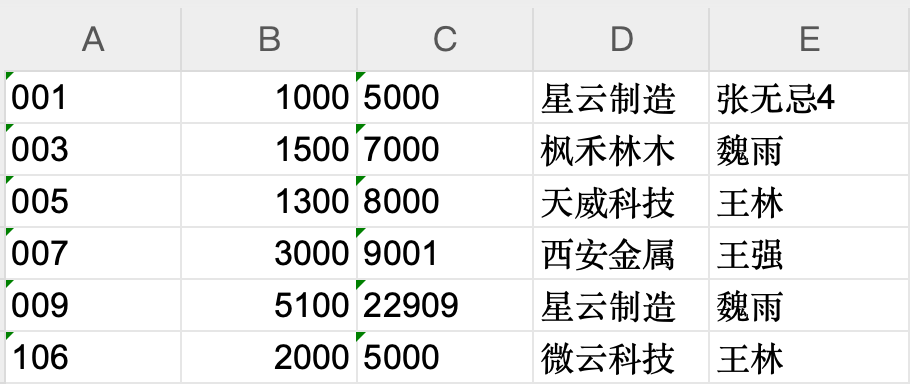
6、文件类型为 excel 时:
如果 excel 文件第一行是表头时,需要手工先删除表头或其他要删除的行,只保留数据。
# Neo4j
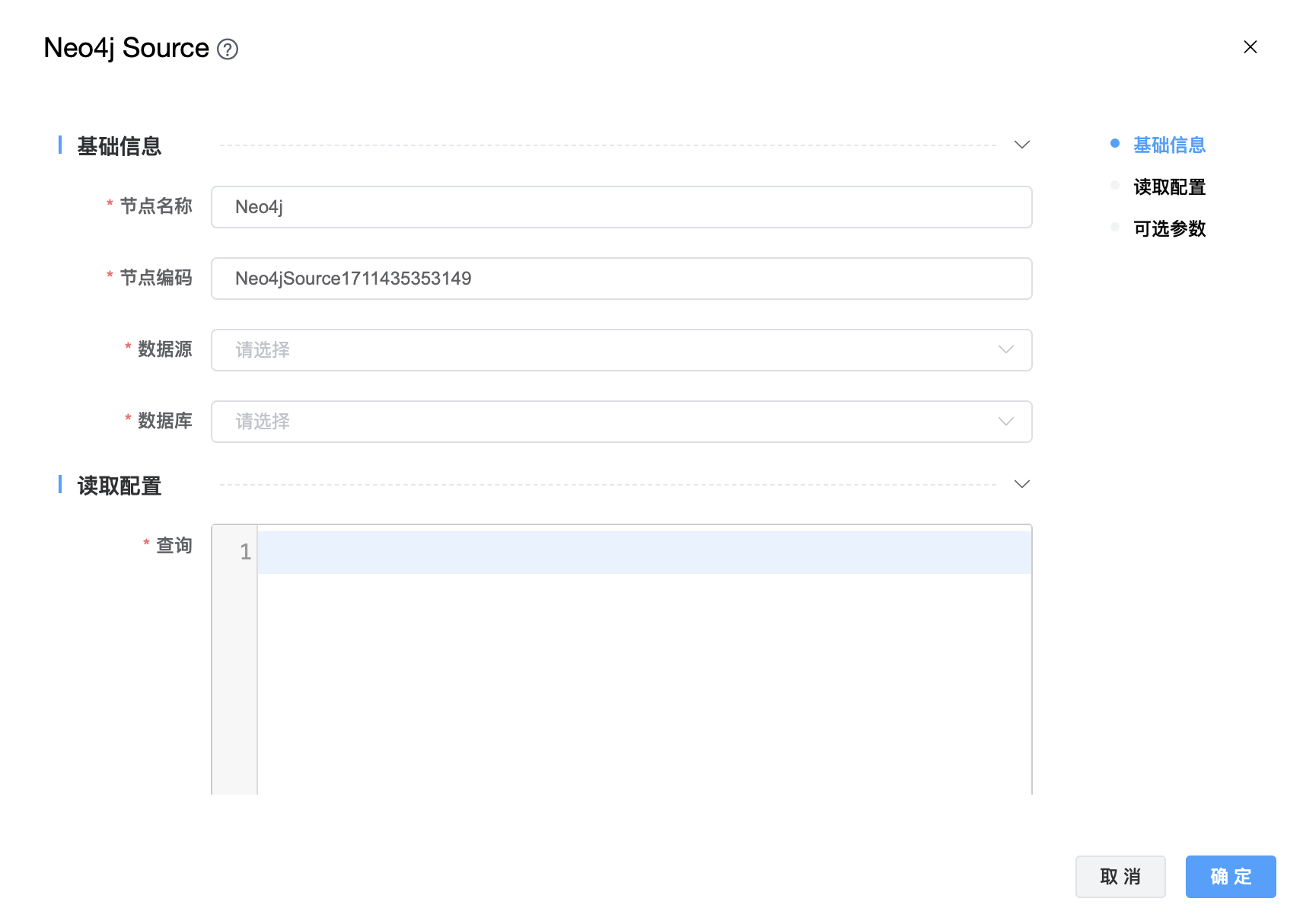
功能介绍:Neo4j 连接器。用于从 Neo4j 读取数据。
组件界面:
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 由用户自定义且不可为空。命名可包含汉字、字母、数字、下划线。 |
| 节点编码 | 由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 数据源 | 从下拉选项中选择列出的当前项目已经关联的 Hive 数据源。 |
| 数据库 | 从下拉选项中选择数据库名称。 |
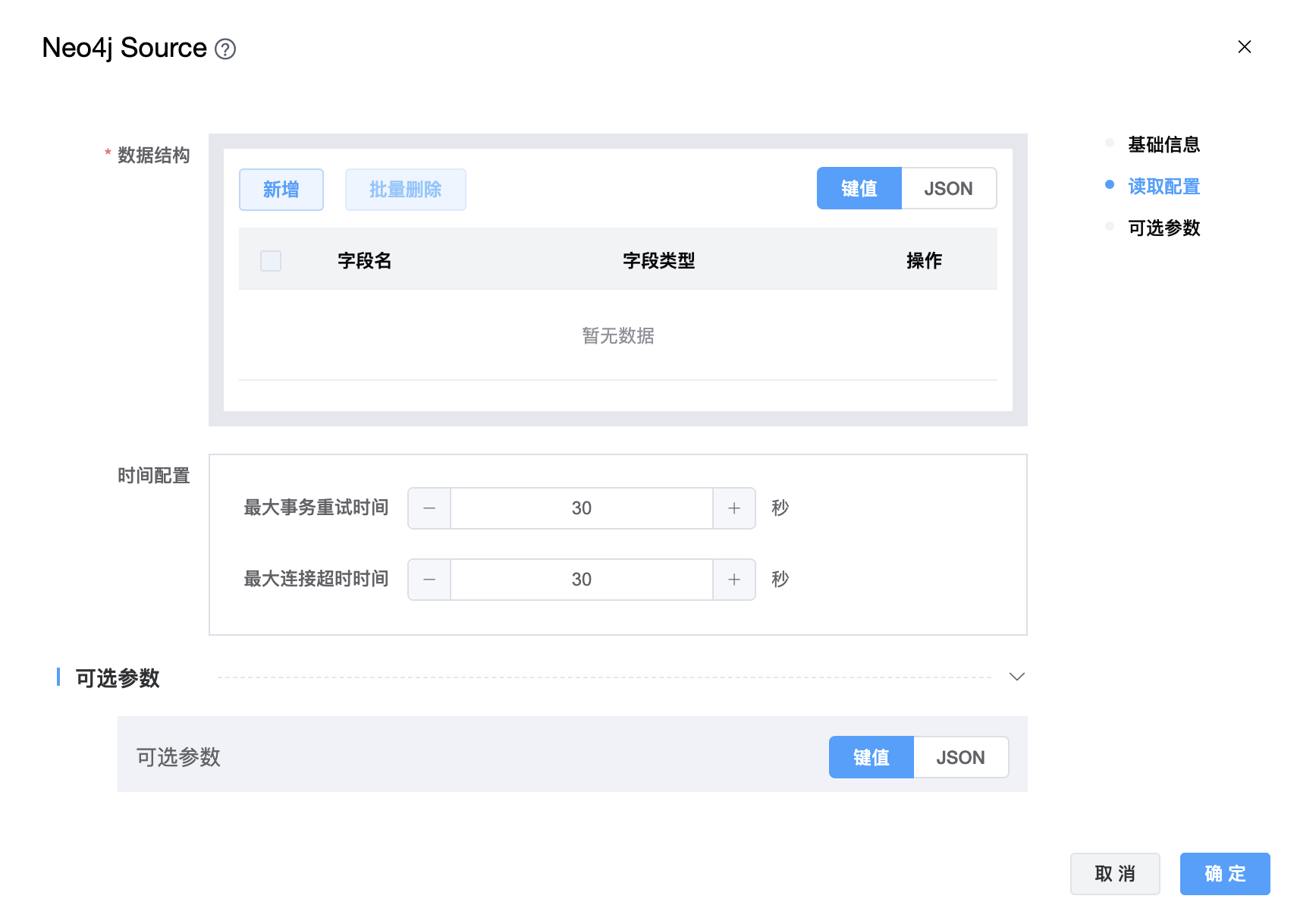
| 查询 | 查询语句。 |
| 数据结构 | 查询字段。 |
| 最大事务重试时间 | 最大事务重试时间(秒)。如果超过,事务将失败。 |
| 最大连接超时时间 | 等待建立TCP连接的最长时间(秒)。 |
| 可选参数 | 其他配置参数,用户可以根据需求进行配置。 |