
# Kafka 到 PostgreSQL 的数据同步示例
本示例主要介绍 Kafka 到 PostgreSQL 的数据同步示例场景开发,该场景根据 Kafka 接收到的消息内容向 PostgreSQL 数据源的表 person 执行 INSERT操作。主要步骤如下:
# 准备数据
在 PostgreSQL 数据源中创建一个表 person。
CREATE TABLE public.person (
pkid varchar NULL,
id varchar NULL,
name varchar NULL,
loading_date varchar NULL,
delete_flag varchar NULL,
mod_user varchar NULL,
mod_user_id varchar NULL
);
在 Kafka 数据源中创建名称为 person 的 Topic。并创建一个需要 INSERT 的消息,具体如下:
{
"_source_schema": "PUBLIC",
"_source_table": "PERSON",
"_committime": "2023-03-14 14:57:35.863",
"_optype": "INSERT",
"_seqno": "2261",
"PKID": "815",
"ID": "20211128",
"NAME": "陈丽",
"LOADING_DATE": "2023-03-14 00:00:00.0",
"DELETE_FLAG": "1",
"MOD_USER": "annoy",
"MOD_USER_ID": "75589"
}
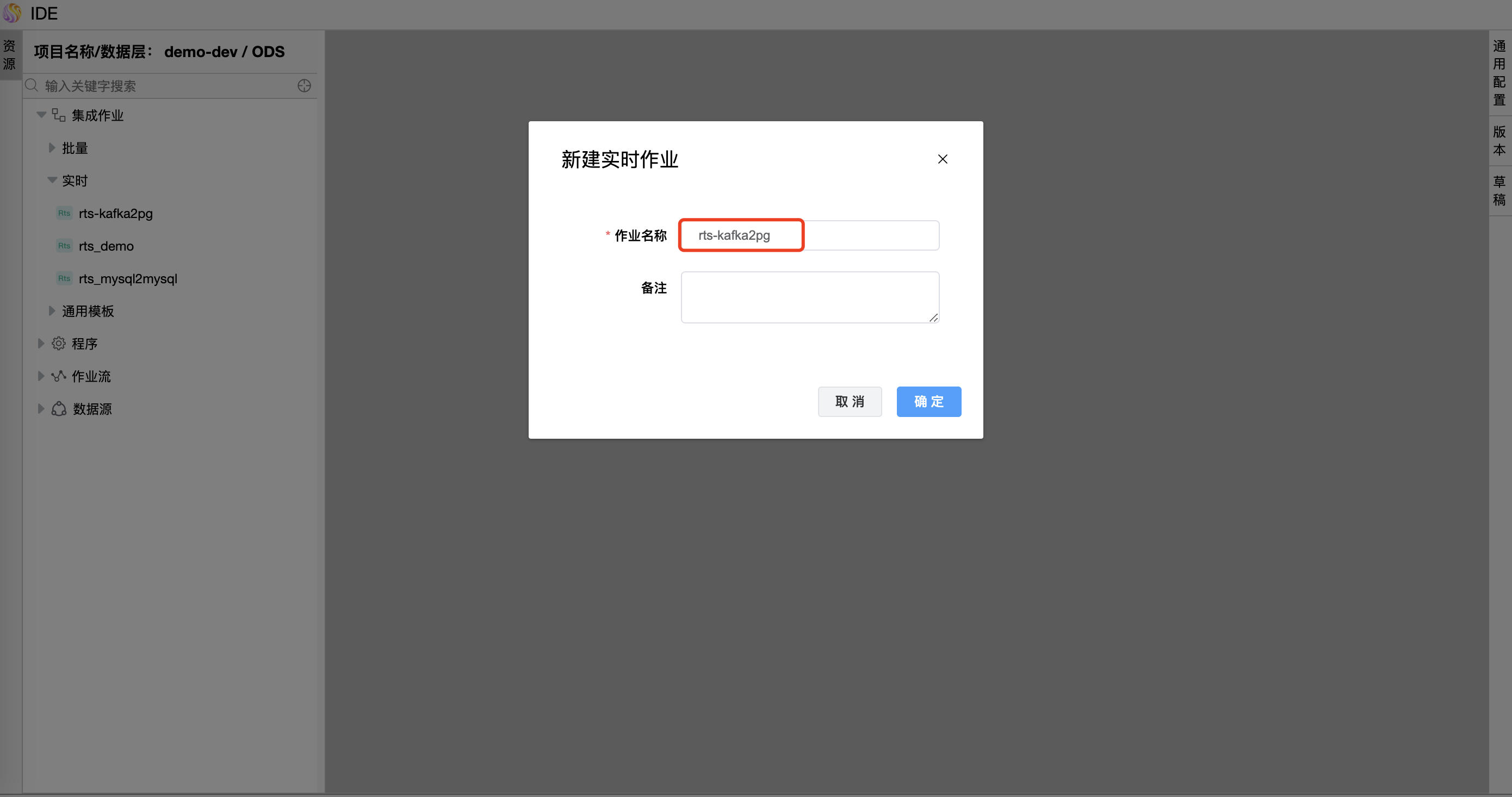
# 新建实时作业
点击资源树节点上的【...】,选择弹出菜单【新建实时作业】,填写作业名称,点击【确定】按钮。

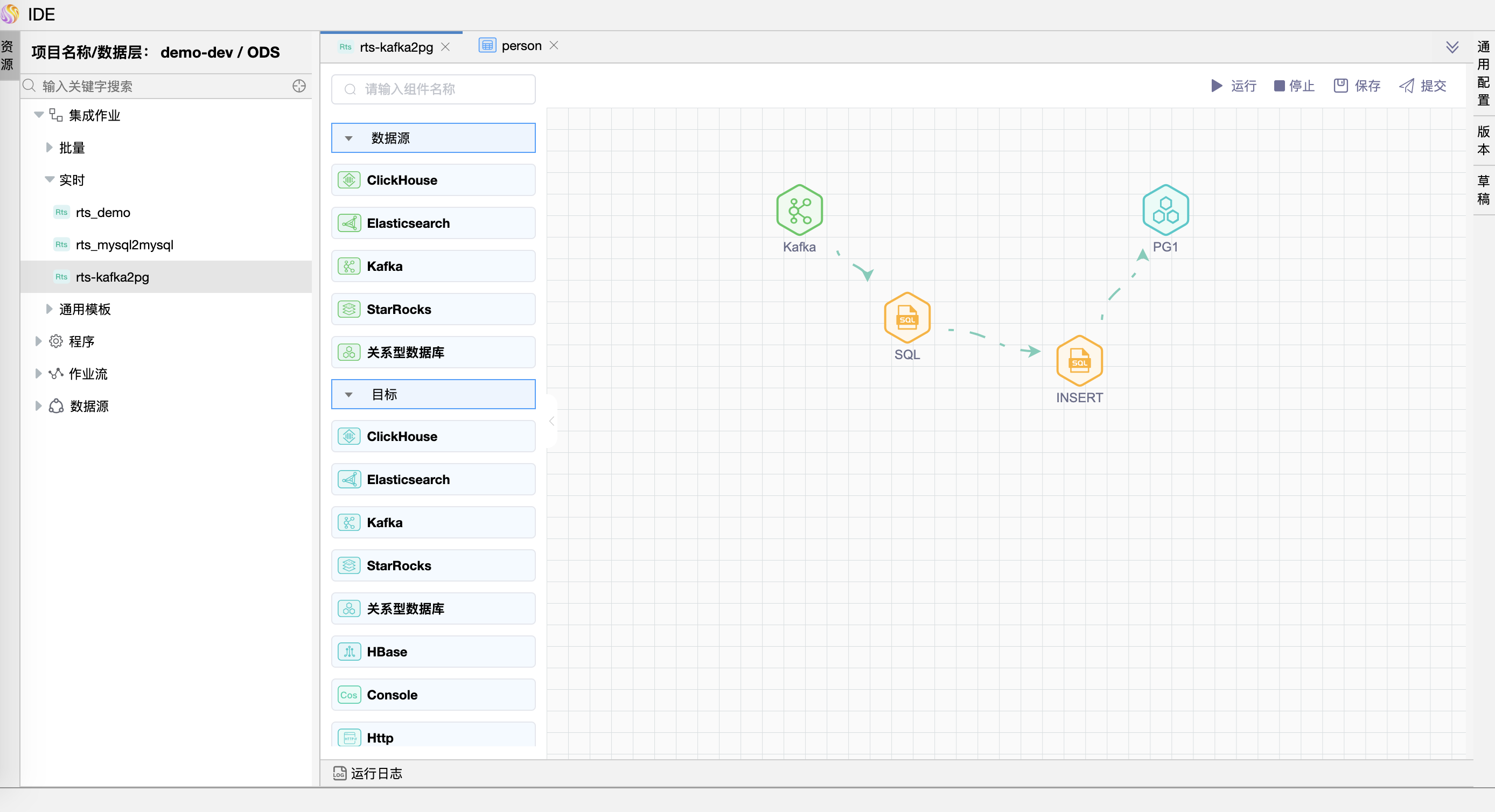
# 画布中拖拽图元
在画布中分别拖拽 1 个"Kafka"数据源图元、2 个"SQL"图元、1 个"关系型数据库"目标图元,并建立连线。
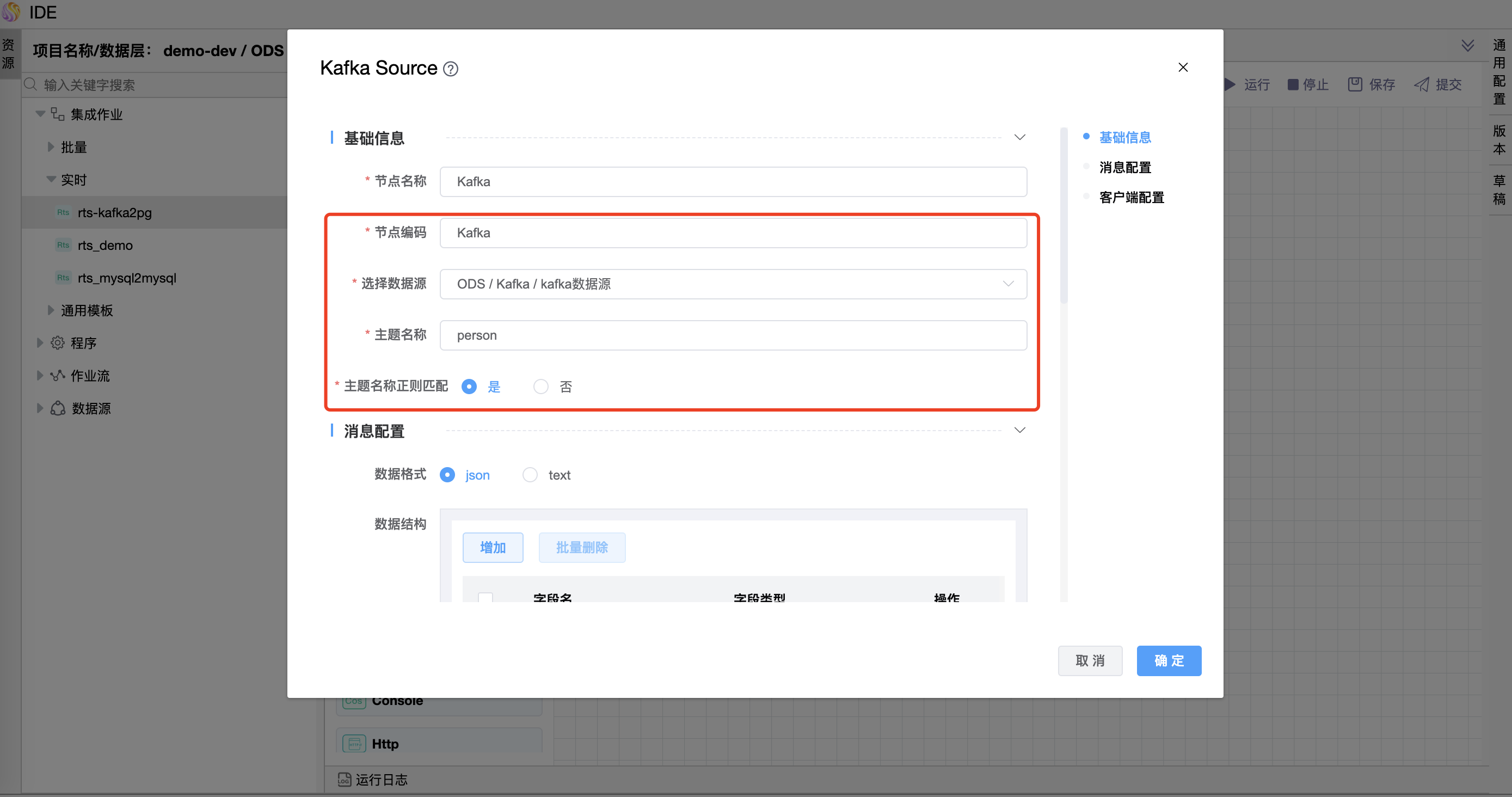
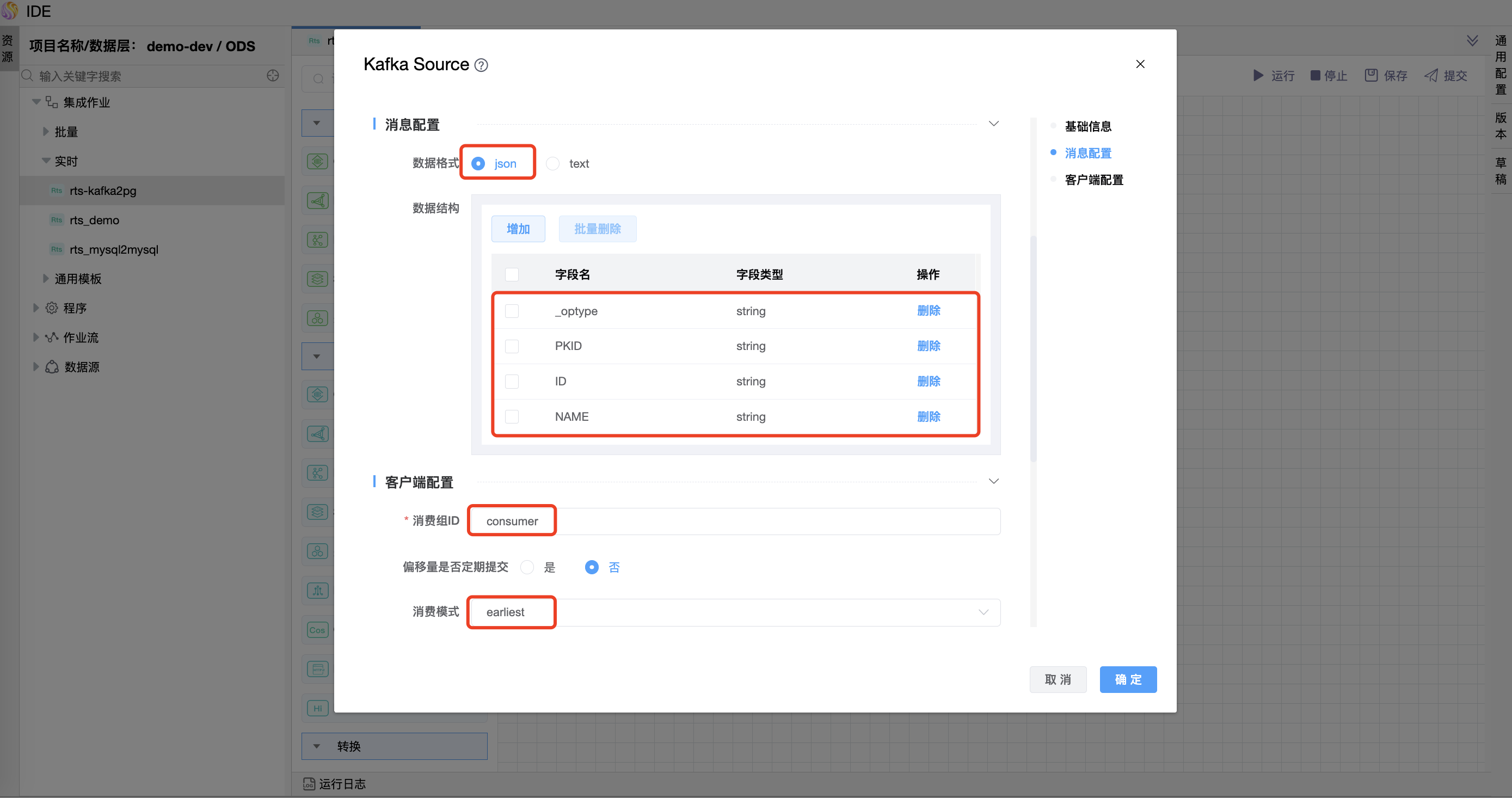
# 配置"Kafka数据源"组件属性
在"Kafka"数据源图元上右键,点击【编辑】按钮,弹出"Kafka"数据源图元的弹窗。按照需求进行属性设置,点击【确定】按钮。
# 配置"SQL"组件属性
在"SQL"图元上右键,点击【编辑】按钮,弹出"SQL"图元的弹窗。分别设置"SQL"、"INSERT"图元的属性。
⚠️ 提示:
查询 SQL 定义的含义是过滤出"Kafka数据源"的"person"主题中 _optype 为 INSERT 的数据。
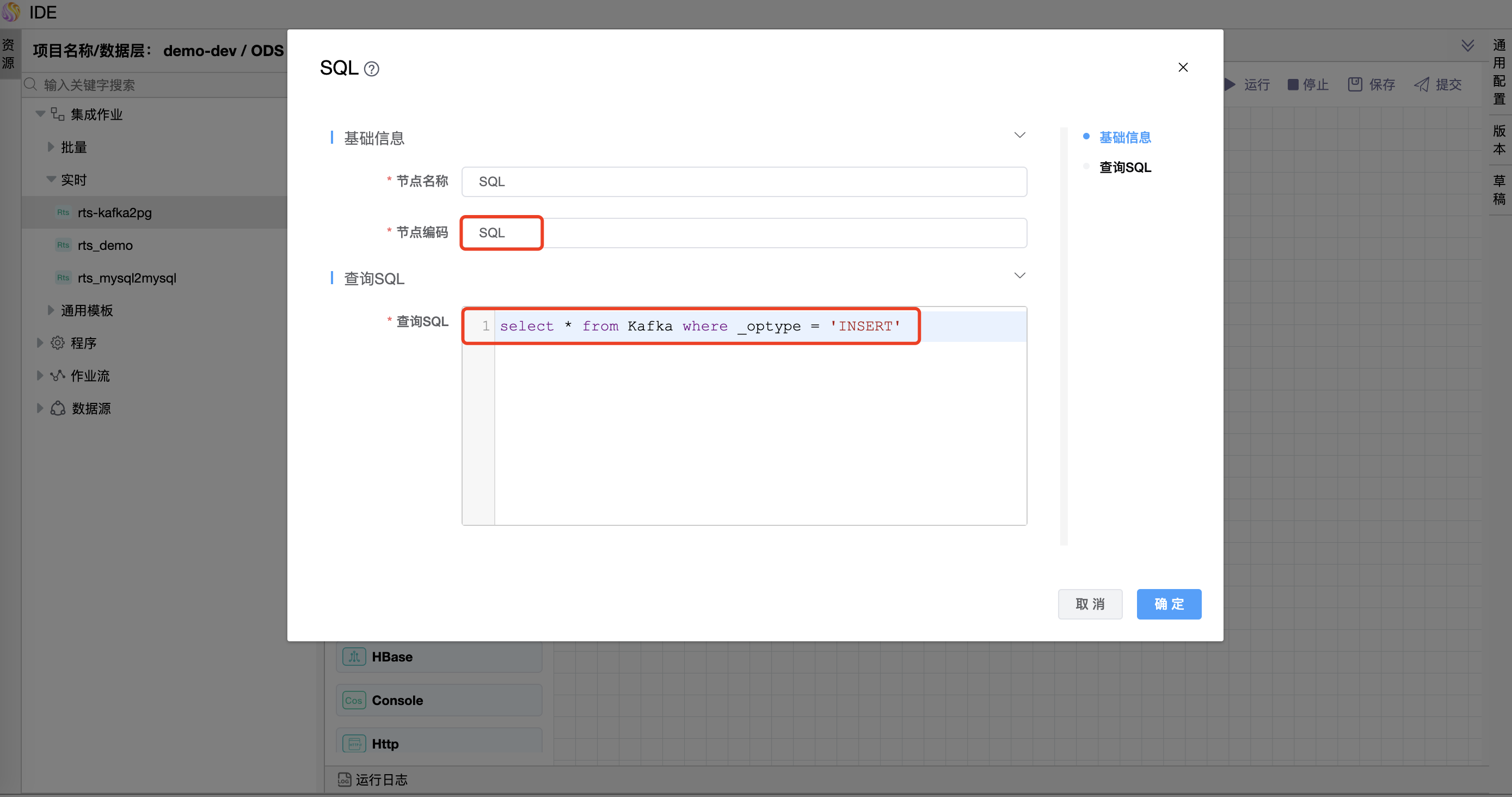
节点编码为"SQL"图元的查询 SQL 中编写语句如下:
select * from Kafka where _optype = 'INSERT'
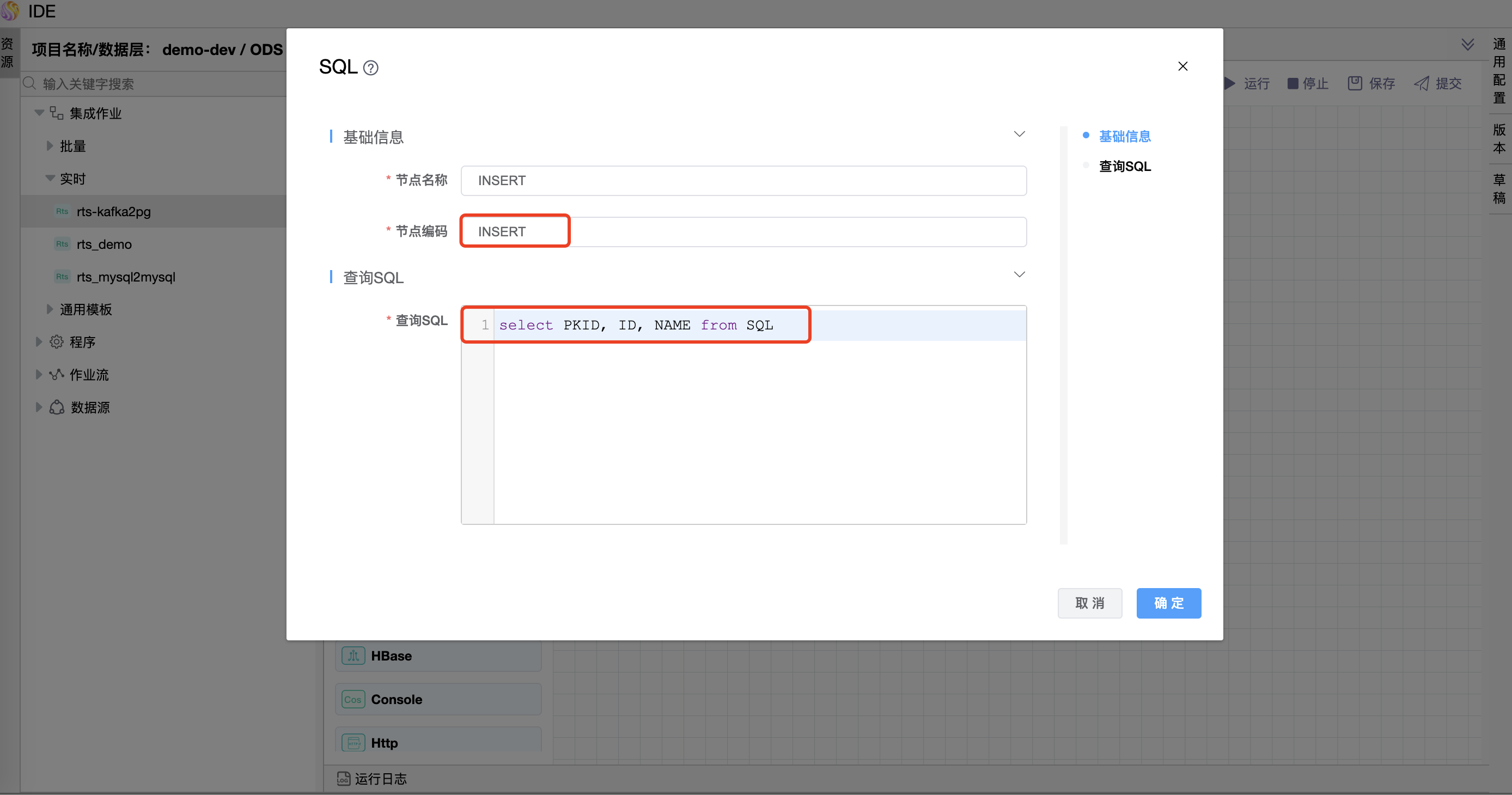
节点编码为"INSERT"图元的查询 SQL 中编写语句如下:
select PKID,ID,NAME from SQL
⚠️ 提示:查询 SQL 中 from 后边的参数值是与其连接的前一个图元的"节点编码"。
# 配置"关系型数据库目标"组件属性
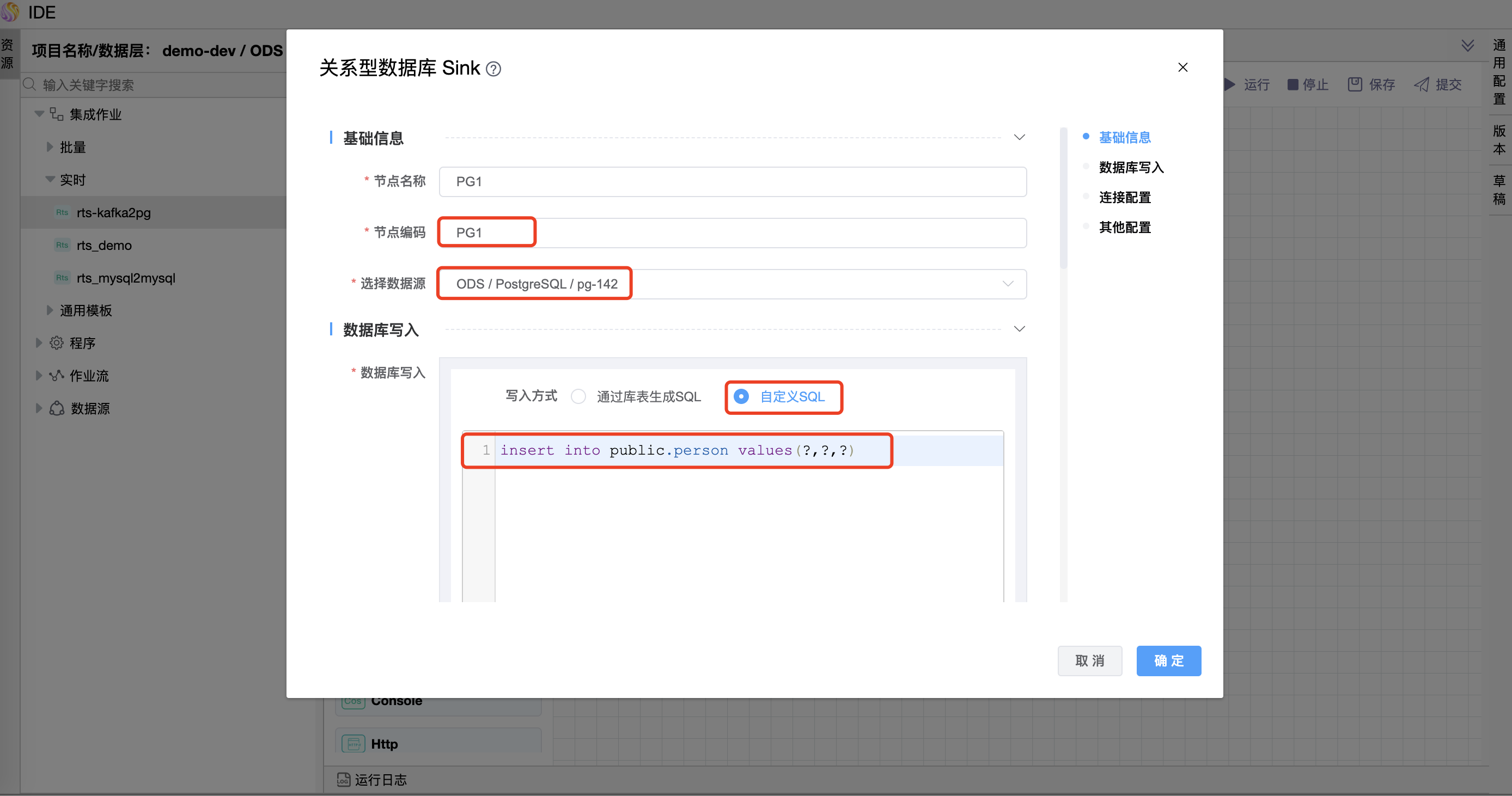
在"关系型数据库"目标图元上右键,点击【编辑】按钮,弹出"关系型数据库"目标图元的弹窗。设置"PG1"图元的属性。 其他属性使用默认值。
节点编码为"PG1"的图元数据库写入 SQL 中编写语句如下:
insert into public.person values(?,?,?)
# 通用配置
在通用配置中可以配置任务优先级、Worker 分组、本地参数、超时告警、选择引擎、部署方式、引用参数。 修改属性后请务必点击【确定】按钮。
# 保存草稿
如果所有组件属性都已设置完毕,点击【保存】按钮,可以看到保存过的历史草稿,并可以随意切换草稿。(草稿只保存最近 10 个)
可以参考示例关系型表数据同步示例 中的"保存草稿"说明。
# 运行
点击【运行】按钮,可以运行已经开发完毕的场景,在日志栏可以看运行日志及运行结果。
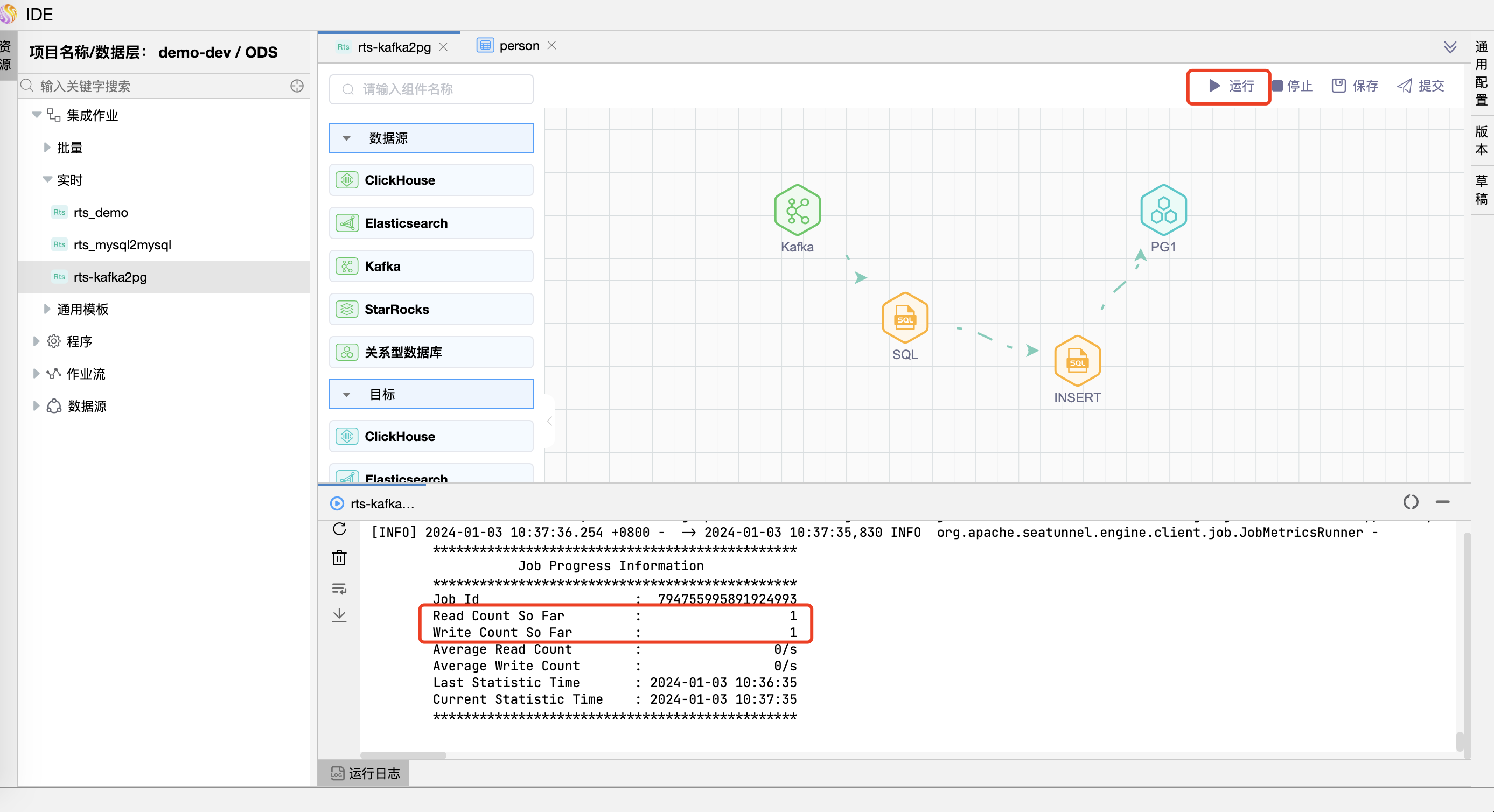
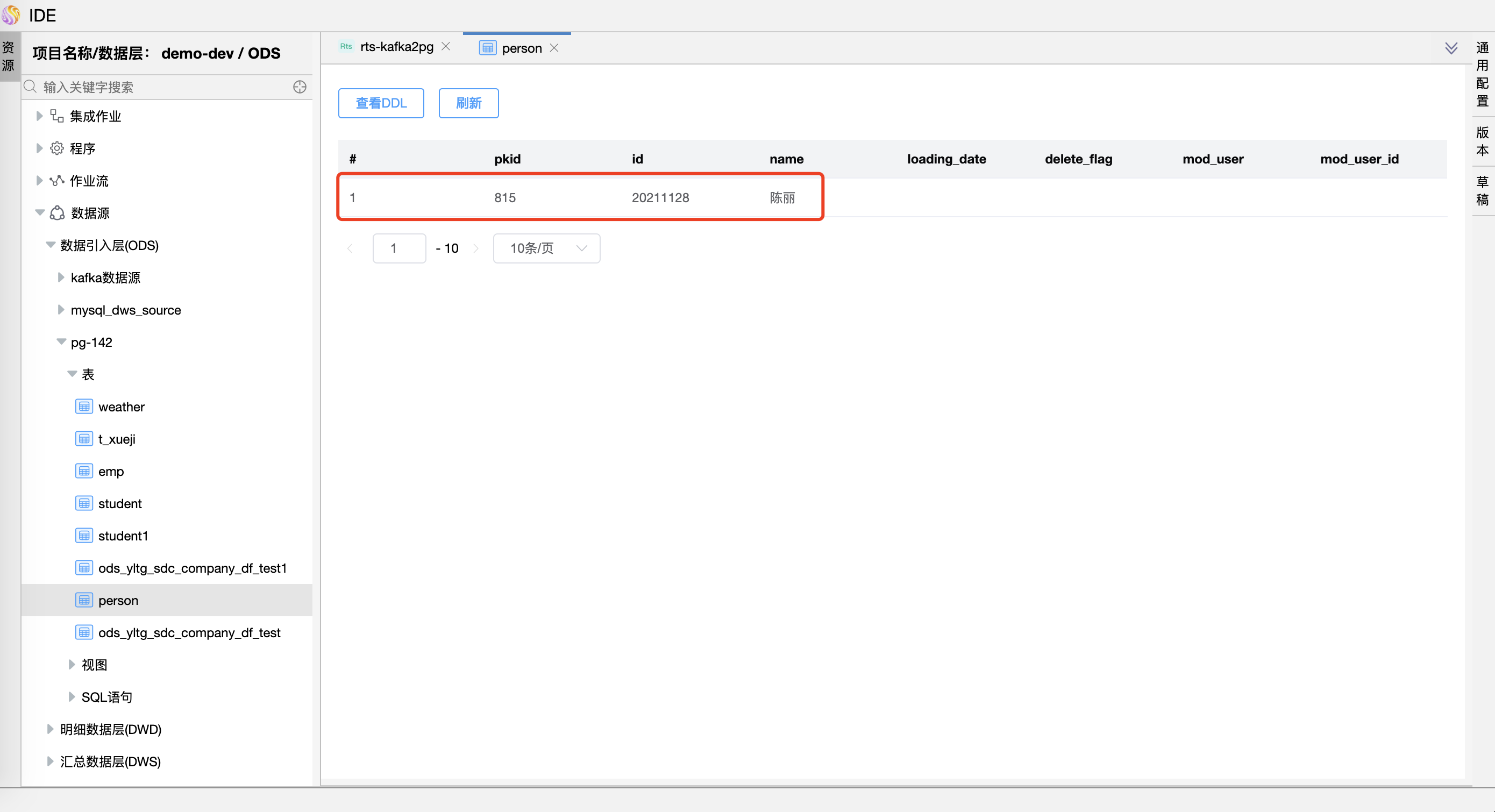
可以在 PostgreSQL 数据库表 person 中看到 INSERT 的数据,pkid 为 815 的数据已经被 INSERT。
# 提交版本
当草稿运行正常后,点击【提交】按钮可以将该版本提交到作业调度,每次修改提交都会生成新的版本,可以看到提交的历史版本,并可以随意切换版本。
提交后的版本,可以在作业调度中进行"定时"调度配置。
可以参考示例关系型表数据同步示例 中的"提交版本"说明。