
# Kafka 到 PostgreSQL 的数据同步示例
本示例主要介绍 Kafka 到 PostgreSQL 的数据同步示例场景开发,该场景根据 Kafka 接收到的消息内容向 PostgreSQL 数据源的表 person 分别执行 INSERT、UPDATE、DELETE 的操作。主要步骤如下:
# 准备数据
在 PostgreSQL 数据源中创建一个表 person,并初始化一些数据,比如:要同步 UPDATE、DELETE 的数据。
CREATE TABLE public.person (
pkid varchar NULL,
id varchar NULL,
name varchar NULL,
loading_date varchar NULL,
delete_flag varchar NULL,
mod_user varchar NULL,
mod_user_id varchar NULL
);
INSERT INTO person(pkid,id,name,loading_date,delete_flag,mod_user,mod_user_id)
VALUES('279', '20211128', '陈丽', '2023-03-14 00:00:00.0', '1','annoy','75589');
INSERT INTO person(pkid,id,name,loading_date,delete_flag,mod_user,mod_user_id)
VALUES('5', '20211128', '测试', '2023-03-14 00:00:00.0', '1','test','00001');
在 Kafka 数据源中创建名称为 person 的 Topic。并创建三个消息,具体如下:
消息一:表示 INSERT 操作的数据
{
"_source_schema": "PUBLIC",
"_source_table": "PERSON",
"_committime": "2023-03-14 14:57:35.863",
"_optype": "INSERT",
"_seqno": "2261",
"record": {
"PKID": "825",
"ID": "20211128",
"NAME": "陈丽",
"LOADING_DATE": "2023-03-14 00:00:00.0",
"DELETE_FLAG": "1",
"MOD_USER": "annoy",
"MOD_USER_ID": "75589"
}
}
消息二:表示 UPDATE 操作的数据
{
"_source_schema": "PUBLIC",
"_source_table": "PERSON",
"_committime": "2023-03-14 18:13:43.622",
"_optype": "UPDATE",
"_seqno": "2264",
"record": {
"PKID": "279",
"ID": "20210582",
"NAME": "赵欣",
"LOADING_DATE": "2023-03-14 00:00:00.0",
"DELETE_FLAG": "1",
"MOD_USER": "admin",
"MOD_USER_ID": "94950"
},
"key": {
"PKID": "279"
}
}
消息三:表示 DELETE 操作的数据
{
"_source_schema": "PUBLIC",
"_source_table": "PERSON",
"_committime": "2023-03-17 15:02:05.19",
"_optype": "DELETE",
"_seqno": "2267",
"record": {
"PKID": "5"
},
"key": {
"PKID": "5"
}
}
# 新建实时作业
点击资源树节点上的【...】,选择弹出菜单【新建实时作业】,填写作业名称,点击【确定】按钮。

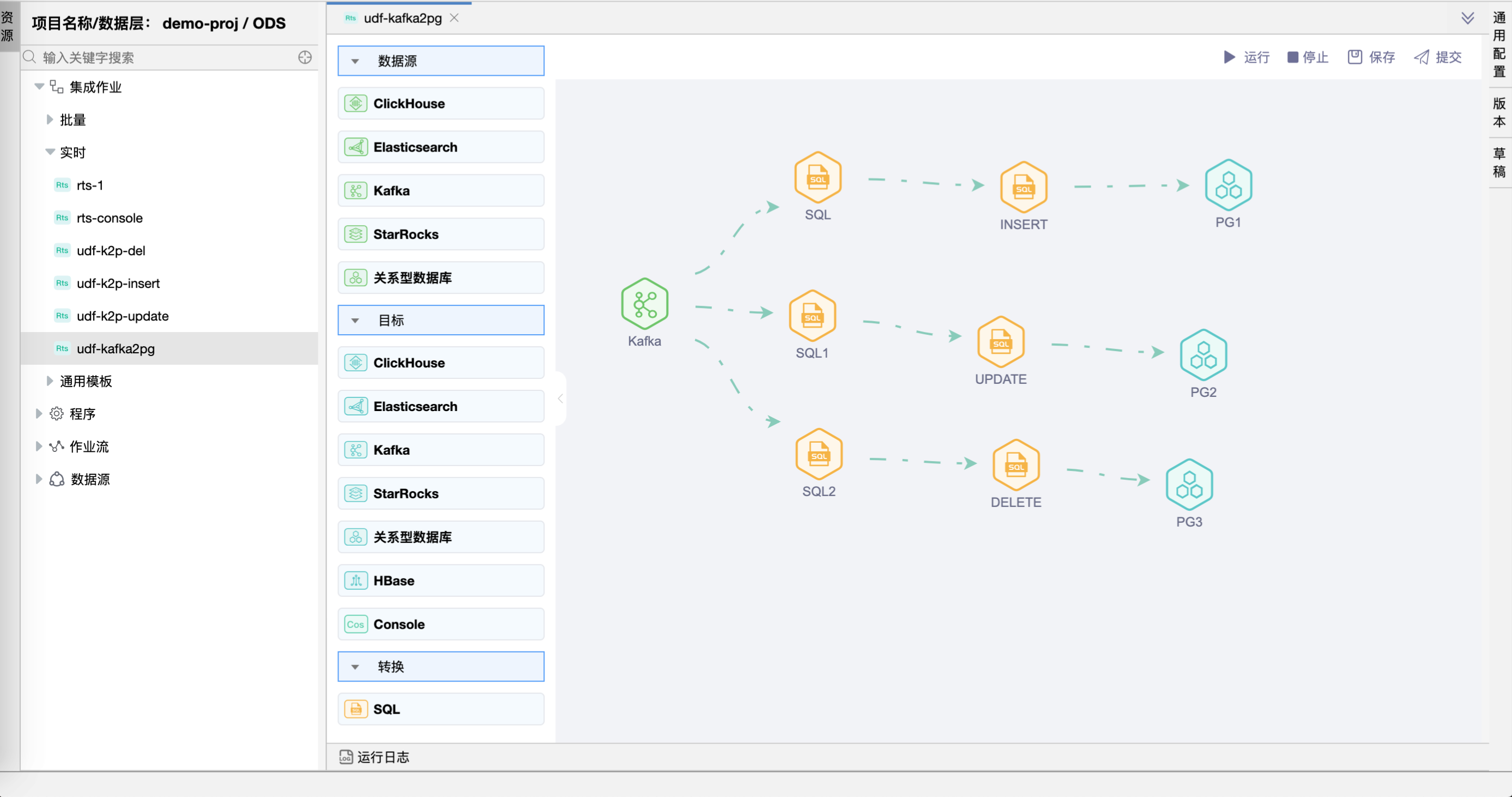
# 画布中拖拽图元
在画布中分别拖拽 1 个"Kafka数据源"图元、6 个"SQL"图元、3 个"关系型数据库目标"图元,并建立连线。
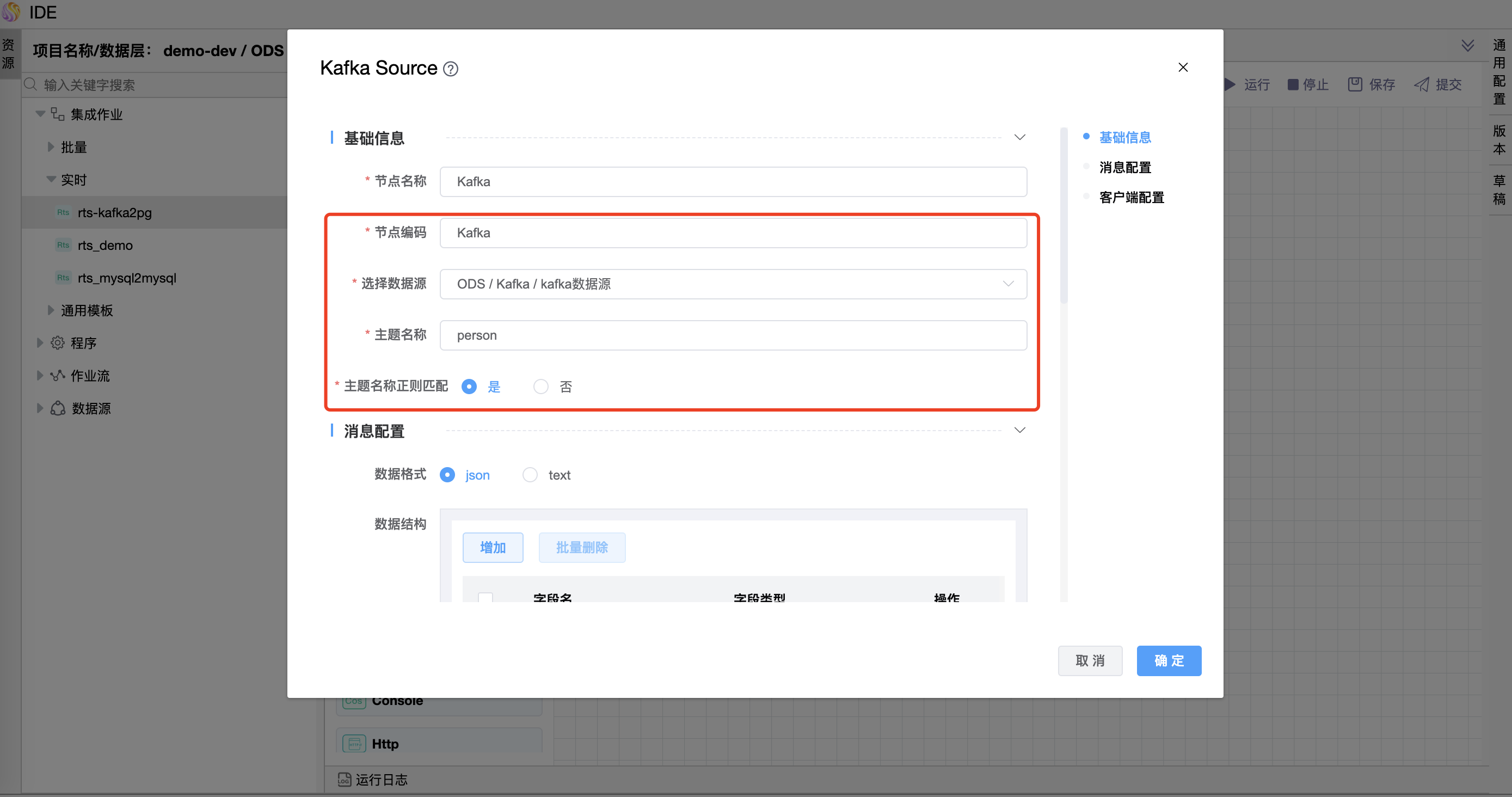
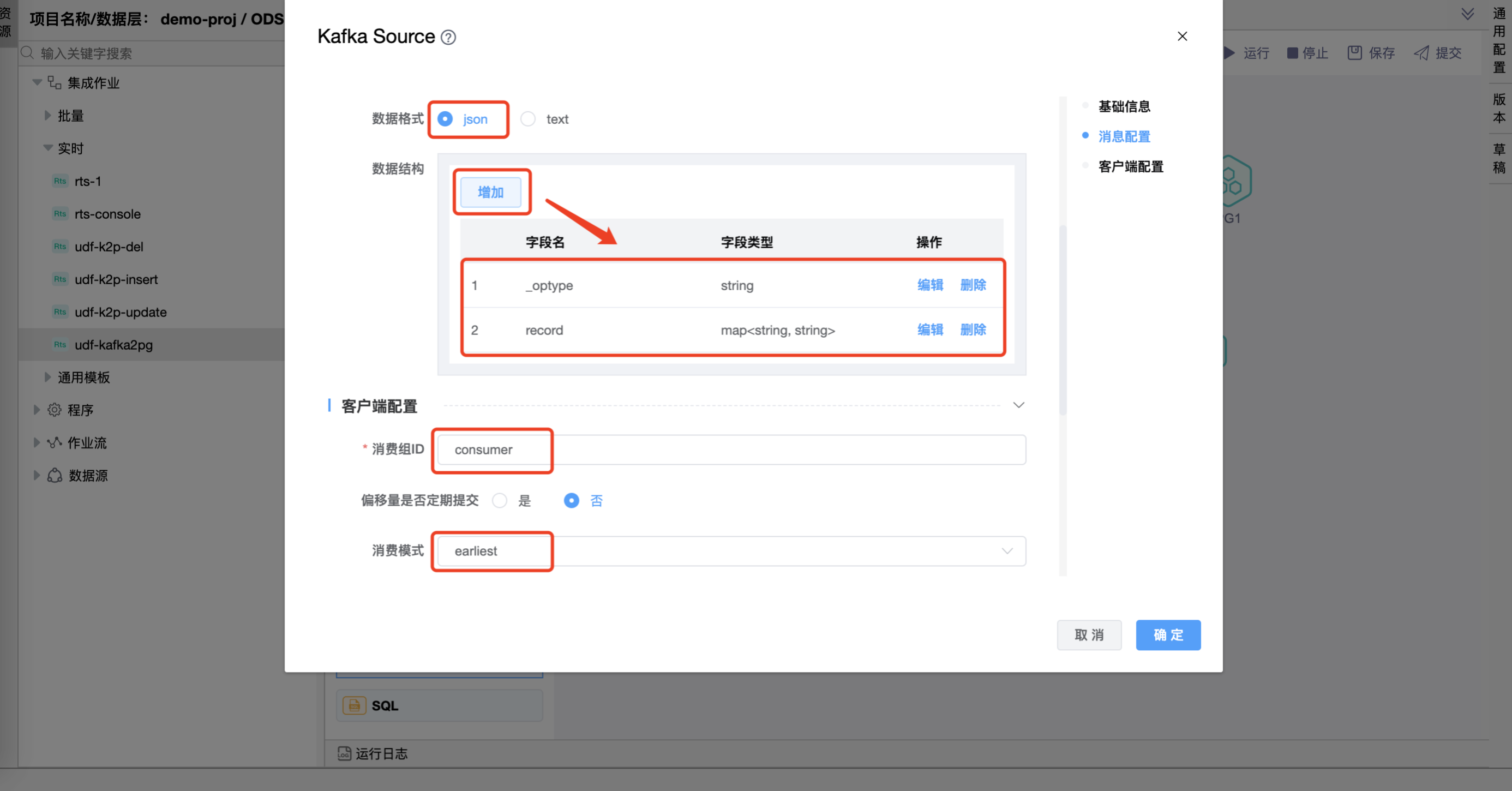
# 配置"Kafka数据源"组件属性
在"Kafka数据源"图元上右键,点击【编辑】按钮,弹出"Kafka数据源"组件的弹窗。按照需求进行属性设置,点击【确定】按钮。
# 配置"SQL"组件属性
在"SQL"图元上右键,点击【编辑】按钮,弹出"SQL"组件的弹窗。分别设置"SQL"、"SQL1"、"SQL2"、"INSERT"、"UPDATE"、"DELETE"图元的属性。
⚠️ 提示:
查询 SQL 中 select 后边的 record 是"Kafka数据源"属性中"数据结构"中定义的字段。查询 SQL 定义的含义是过滤出"Kafka数据源"的"person"主题中 _optype 为 INSERT 的数据。
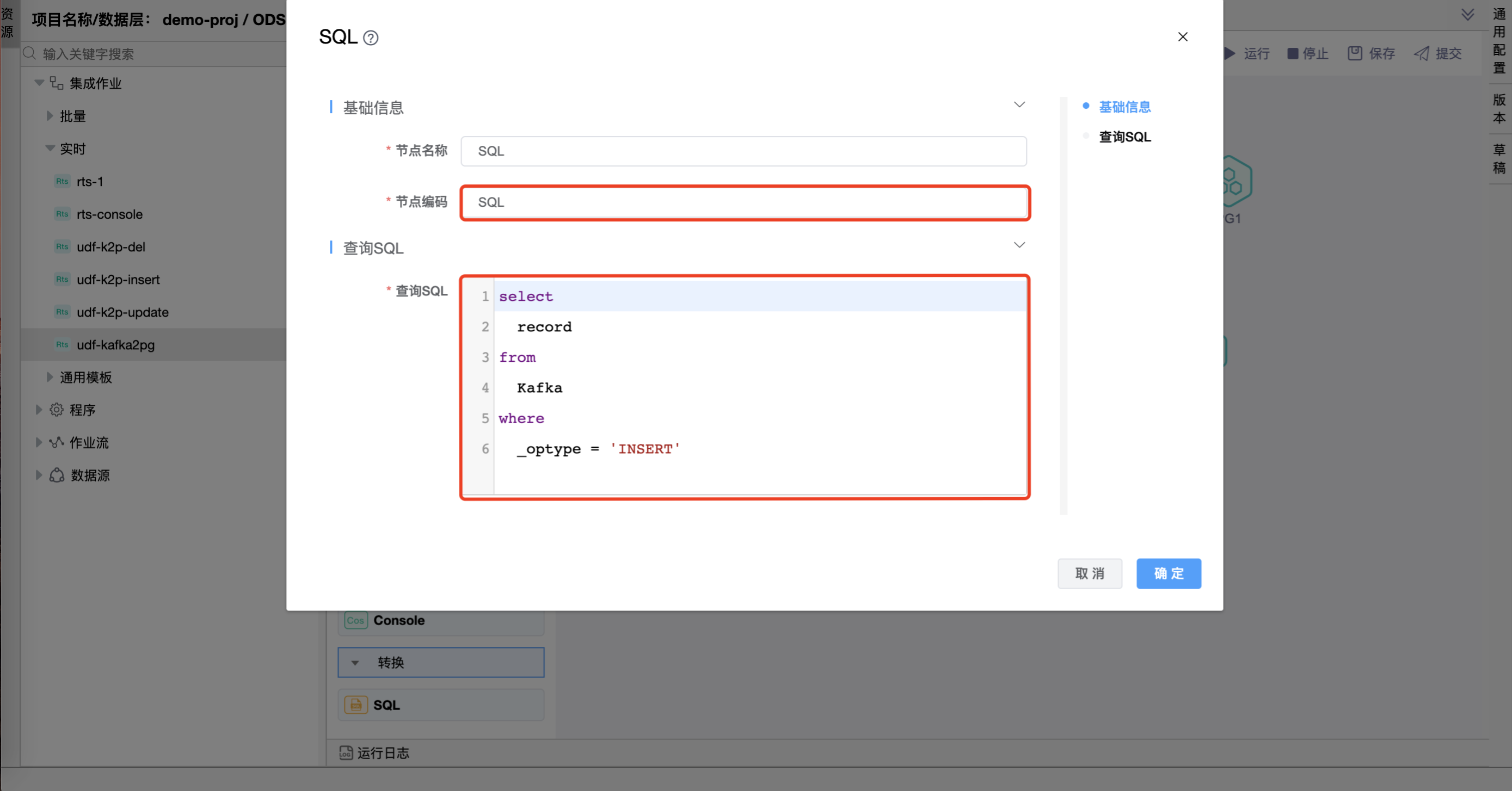
⚠️ 提示:查询 SQL 定义的含义是过滤出"Kafka数据源"的"person"主题中 _optype 为 UPDATE 的数据。
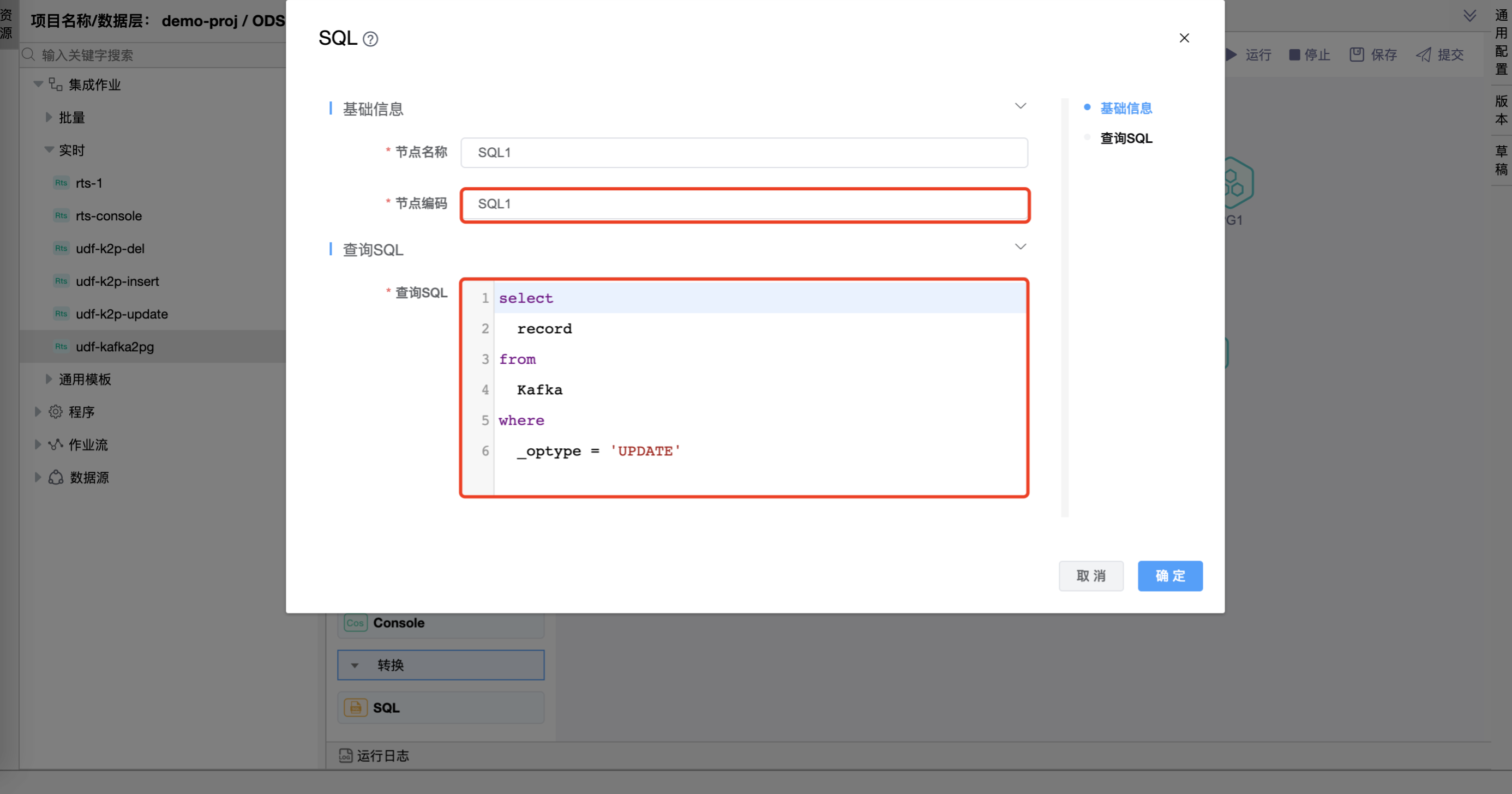
⚠️ 提示:查询 SQL 定义的含义是过滤出"Kafka数据源"的"person"主题中 _optype 为 DELETE 的数据。
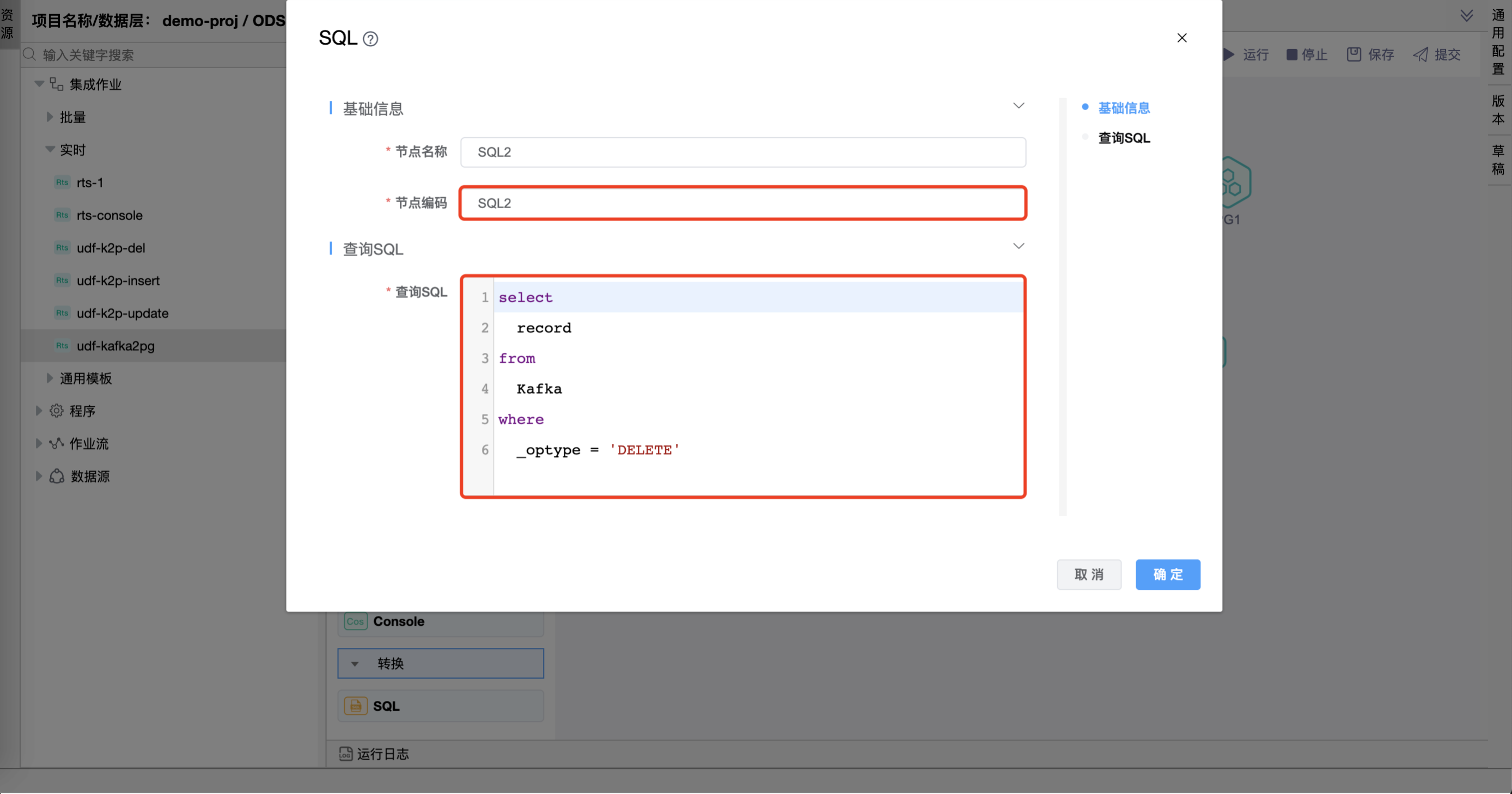
后续三个节点编码分别为"INSERT"、"UPDATE"、"DELETE"的组件中,自定义查询 SQL 时用到了自定义函数 QDMX和hutool-all-5.8.20.jar将两个 jar 文件放至 ${seatunnel部署路径}/apache-seatunnel-2.3.3/lib/ 下。
函数具体编码如下:
package org.apache.seatunnel.example.engine;
import cn.hutool.core.util.StrUtil;
import com.google.auto.service.AutoService;
import org.apache.seatunnel.api.table.type.BasicType;
import org.apache.seatunnel.api.table.type.SeaTunnelDataType;
import org.apache.seatunnel.transform.sql.zeta.ZetaUDF;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author primeton
* @create 2023-08-18
*/
@AutoService(ZetaUDF.class)
public class QdmxUDF implements ZetaUDF {
@Override
public String functionName() {
return "QDMX";
}
@Override
public SeaTunnelDataType<?> resultType(List<SeaTunnelDataType<?>> list) {
return BasicType.STRING_TYPE;
}
//list 参数实例:(也就是kafka 解析过来的数据)
//SeaTunnelRow{tableId=, kind=+I, fields=[{key1=value1,key2=value2,.....}]}
@Override
public Object evaluate(List<Object> list) {
String str = list.get(0).toString();
//1 Remove the prefix
str = StrUtil.replace(str, "SeaTunnelRow{tableId=, kind=+I, fields=[{", "");
//2 Remove the suffix
str = StrUtil.sub(str, -1, 0);
//3 build Map key value
Map<String, String> map = parseToMap(str);
if ("null".equals(map.get(list.get(1).toString())))
return "";
//4 return the value of the key
return map.get(list.get(1).toString());
}
public static Map<String, String> parseToMap(String input) {
Map<String, String> map = new HashMap<>();
//去除大括号 在字符串阶段去除
input = input.replaceAll("[{}]", "");
//拆分键值对
String[] pairs = input.split(", ");
for (String pair : pairs) {
String[] keyValue = pair.split("=");
if (keyValue.length == 2) {
String key = keyValue[0].trim();
String value = keyValue[1].trim();
map.put(key, value);
}
}
return map;
}
}
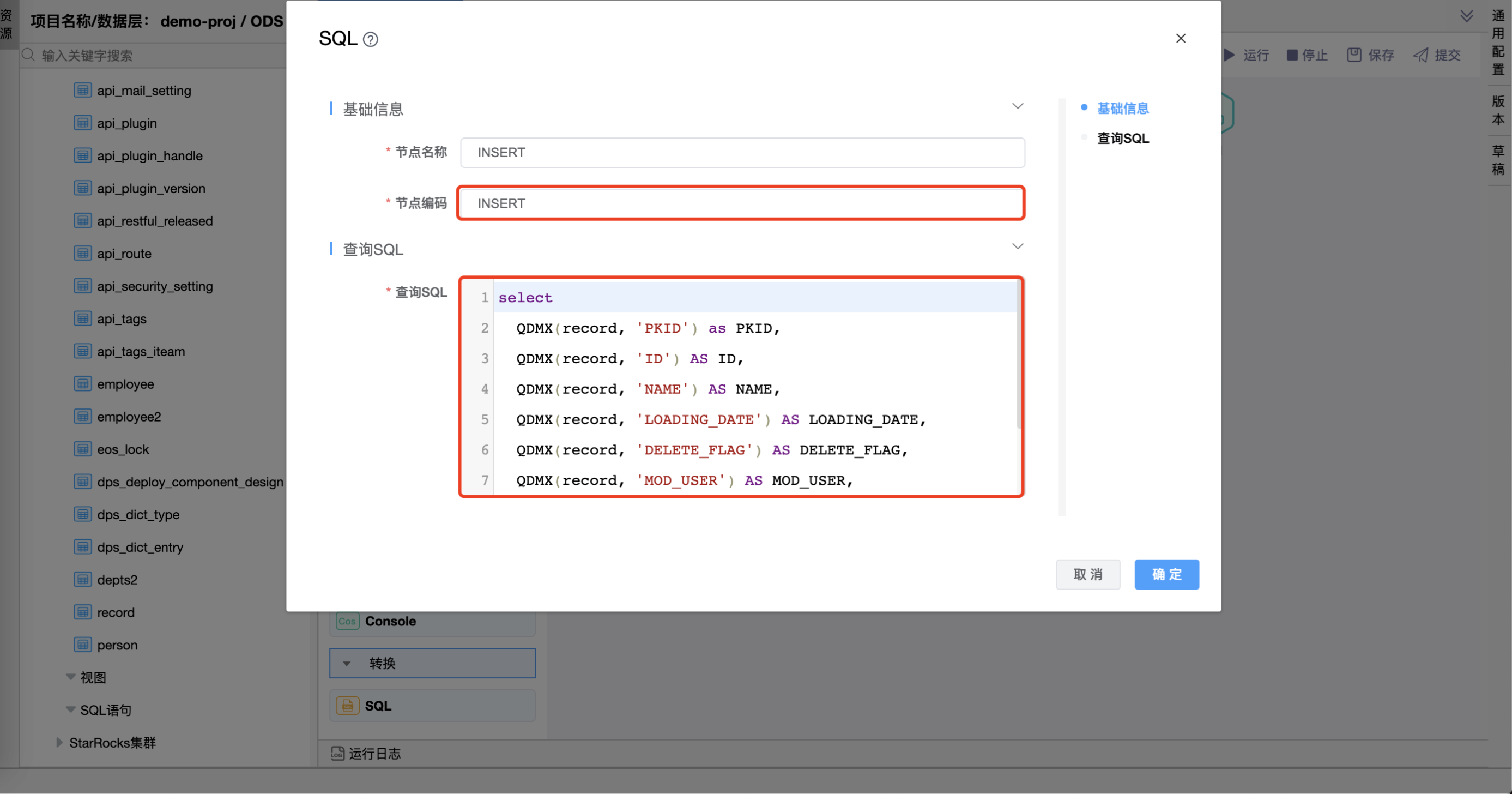
节点编码为"INSERT"的查询 SQL 中编写的 SQL 语句如下:
select
QDMX(record, 'PKID') as PKID,
QDMX(record, 'ID') AS ID,
QDMX(record, 'NAME') AS NAME,
QDMX(record, 'LOADING_DATE') AS LOADING_DATE,
QDMX(record, 'DELETE_FLAG') AS DELETE_FLAG,
QDMX(record, 'MOD_USER') AS MOD_USER,
QDMX(record, 'MOD_USER_ID') AS MOD_USER_ID
from
SQL
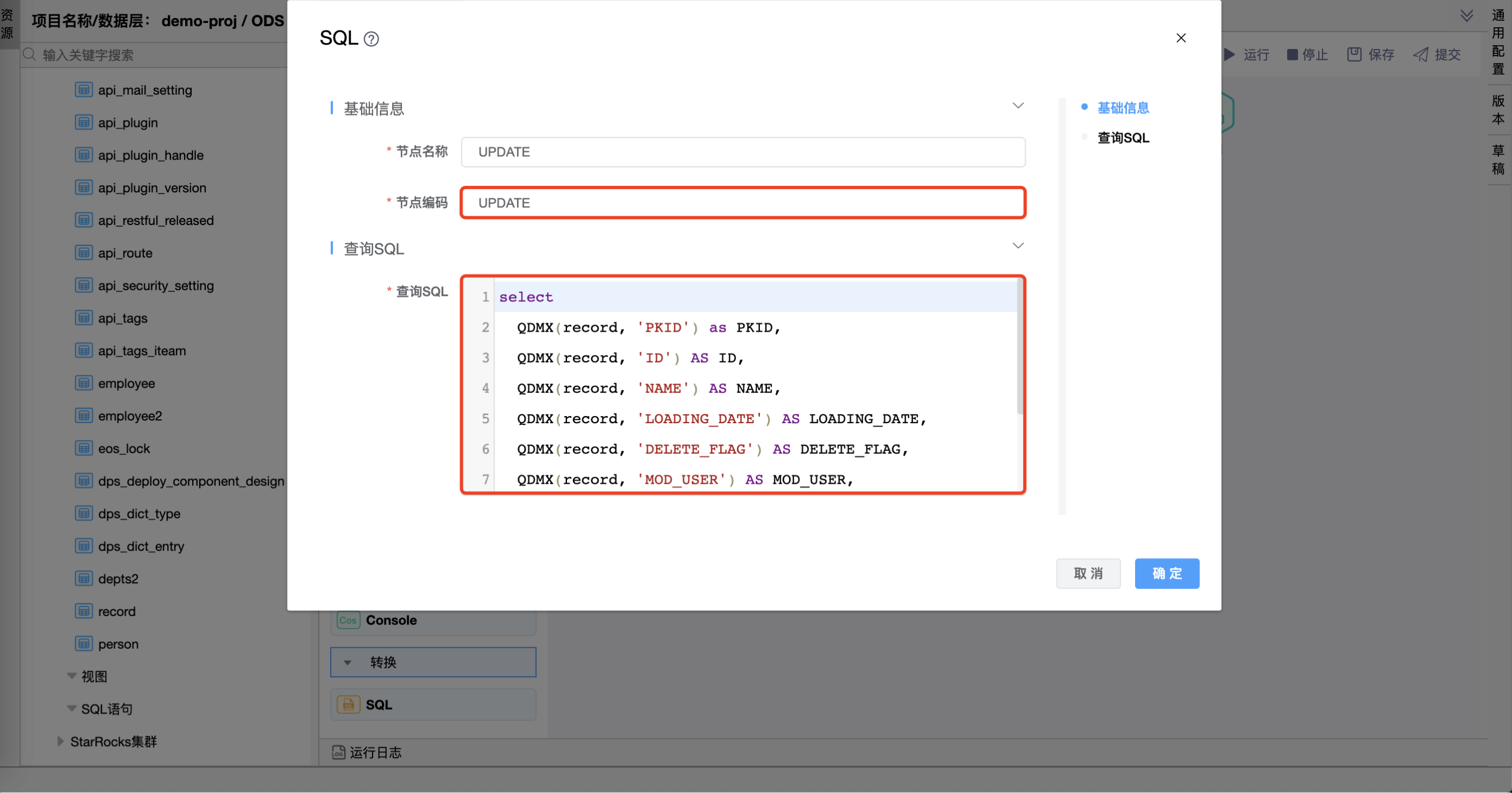
节点编码为"UPDATE"的查询 SQL 中编写的 SQL 语句如下:
select
QDMX(record, 'PKID') as PKID,
QDMX(record, 'ID') AS ID,
QDMX(record, 'NAME') AS NAME,
QDMX(record, 'LOADING_DATE') AS LOADING_DATE,
QDMX(record, 'DELETE_FLAG') AS DELETE_FLAG,
QDMX(record, 'MOD_USER') AS MOD_USER,
QDMX(record, 'MOD_USER_ID') AS MOD_USER_ID,
QDMX(record, 'PKID') as PKID
from
SQL1
节点编码为"DELETE"的查询 SQL 中编写的 SQL 语句如下:
select
QDMX(record, 'PKID') as PKID
from
SQL2
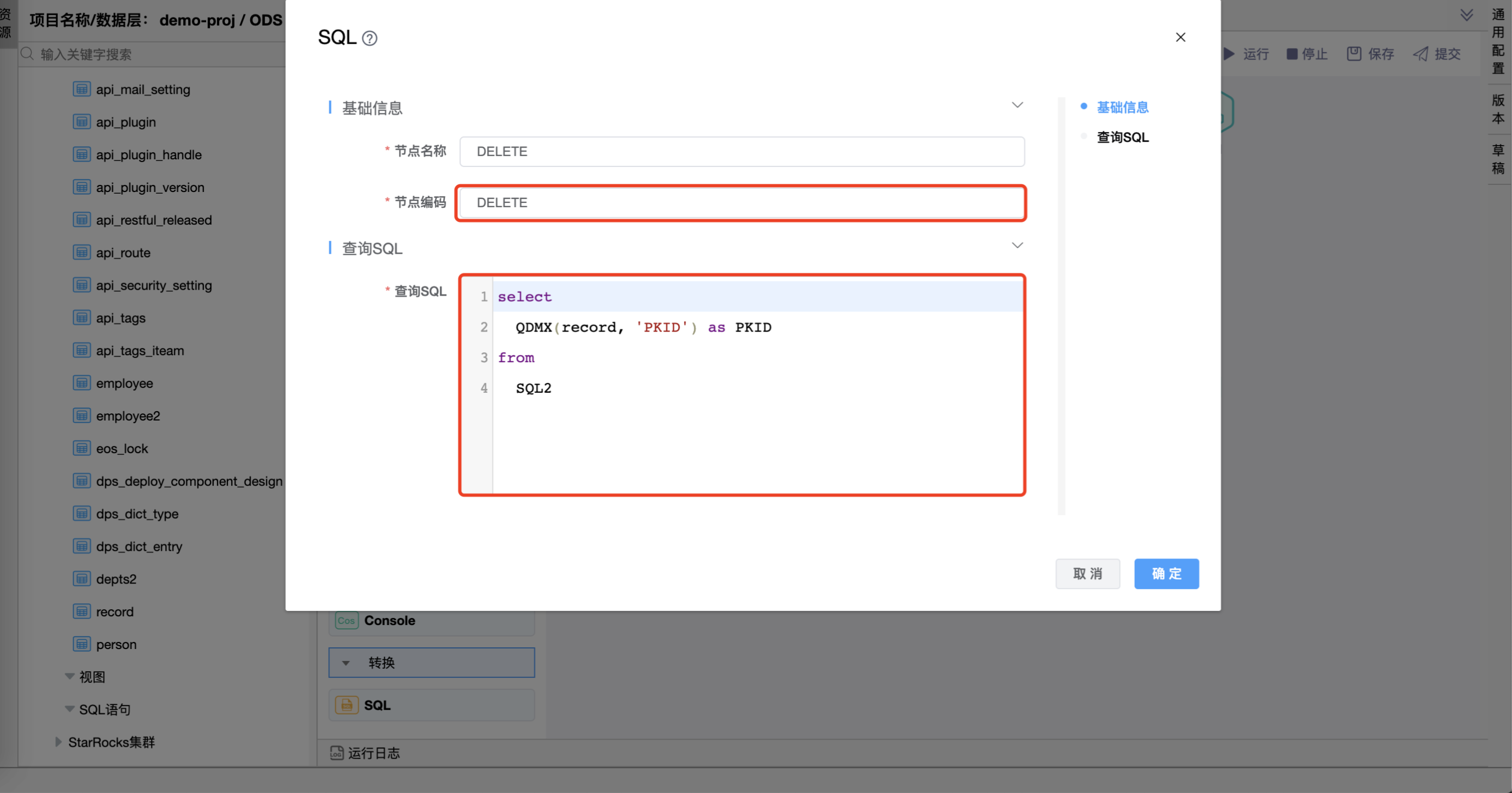
⚠️ 提示:查询 SQL 中 from 后边的参数值是与其连接的前一个组件的"节点编码"。
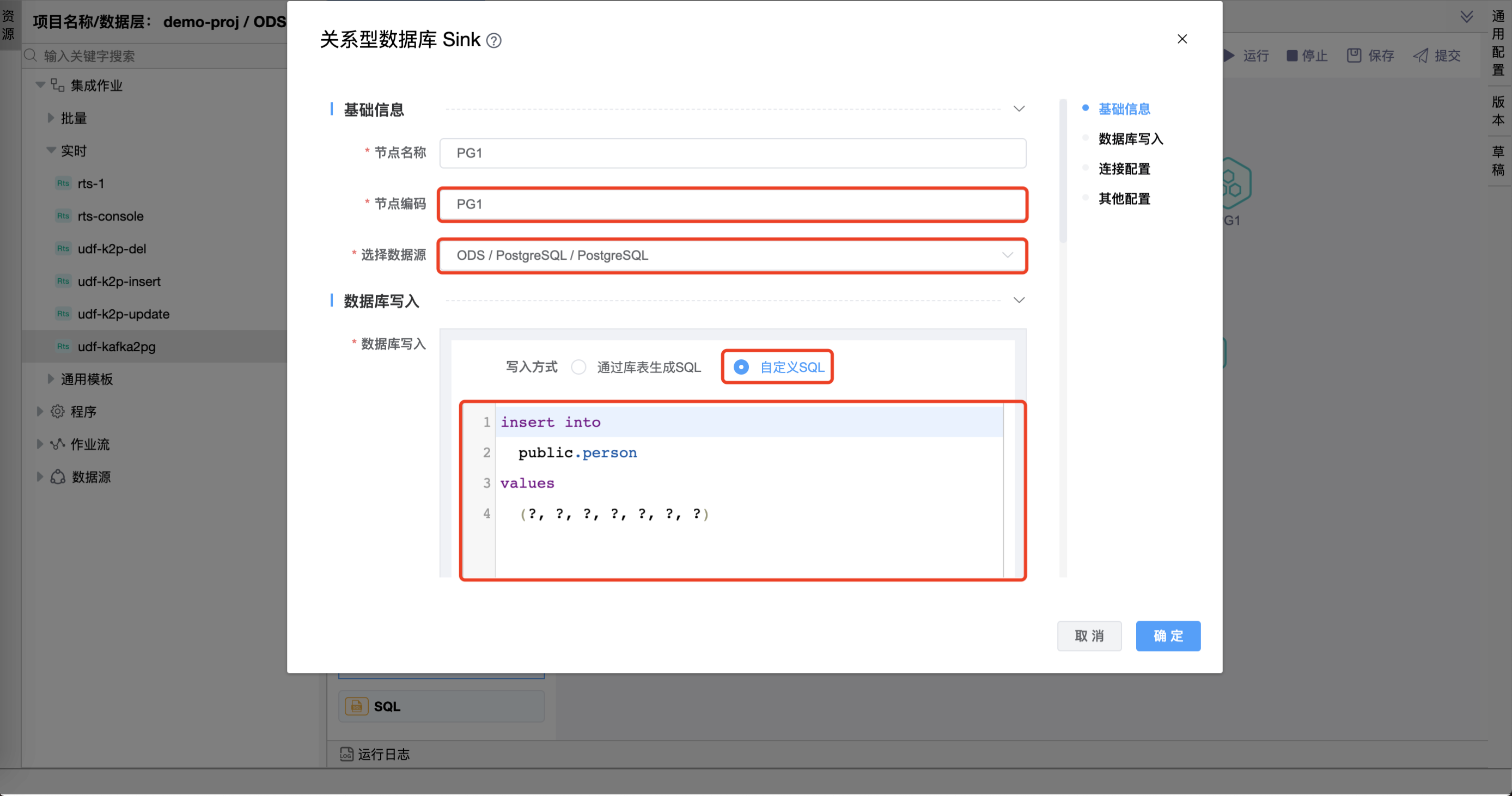
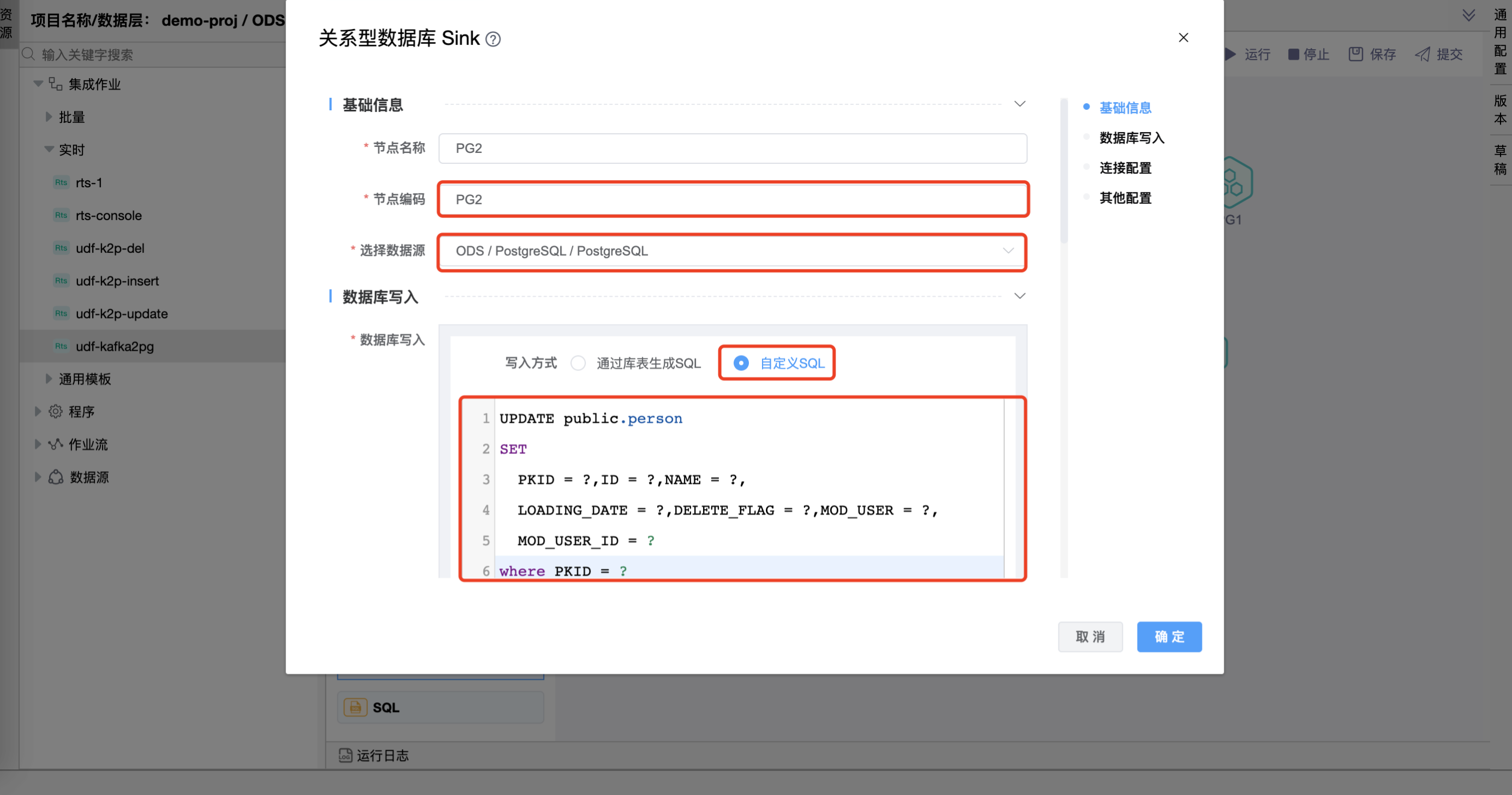
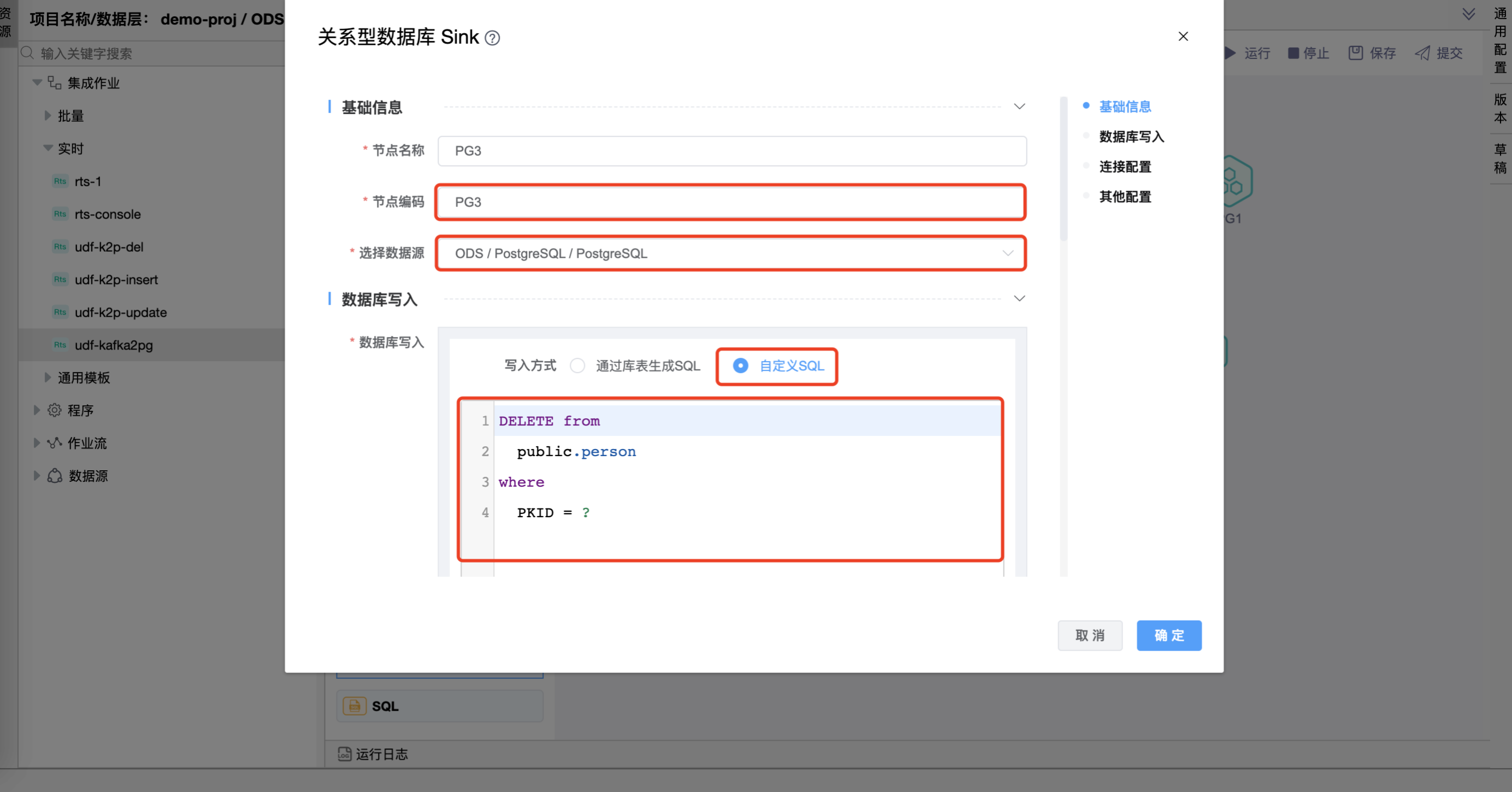
# 配置"关系型数据库目标"组件属性
在"关系型数据库目标"图元上右键,点击【编辑】按钮,弹出"关系型数据库目标"组件的弹窗。分别设置"PG1"、"PG2"、"PG3"图元的属性。 其他属性使用默认值。
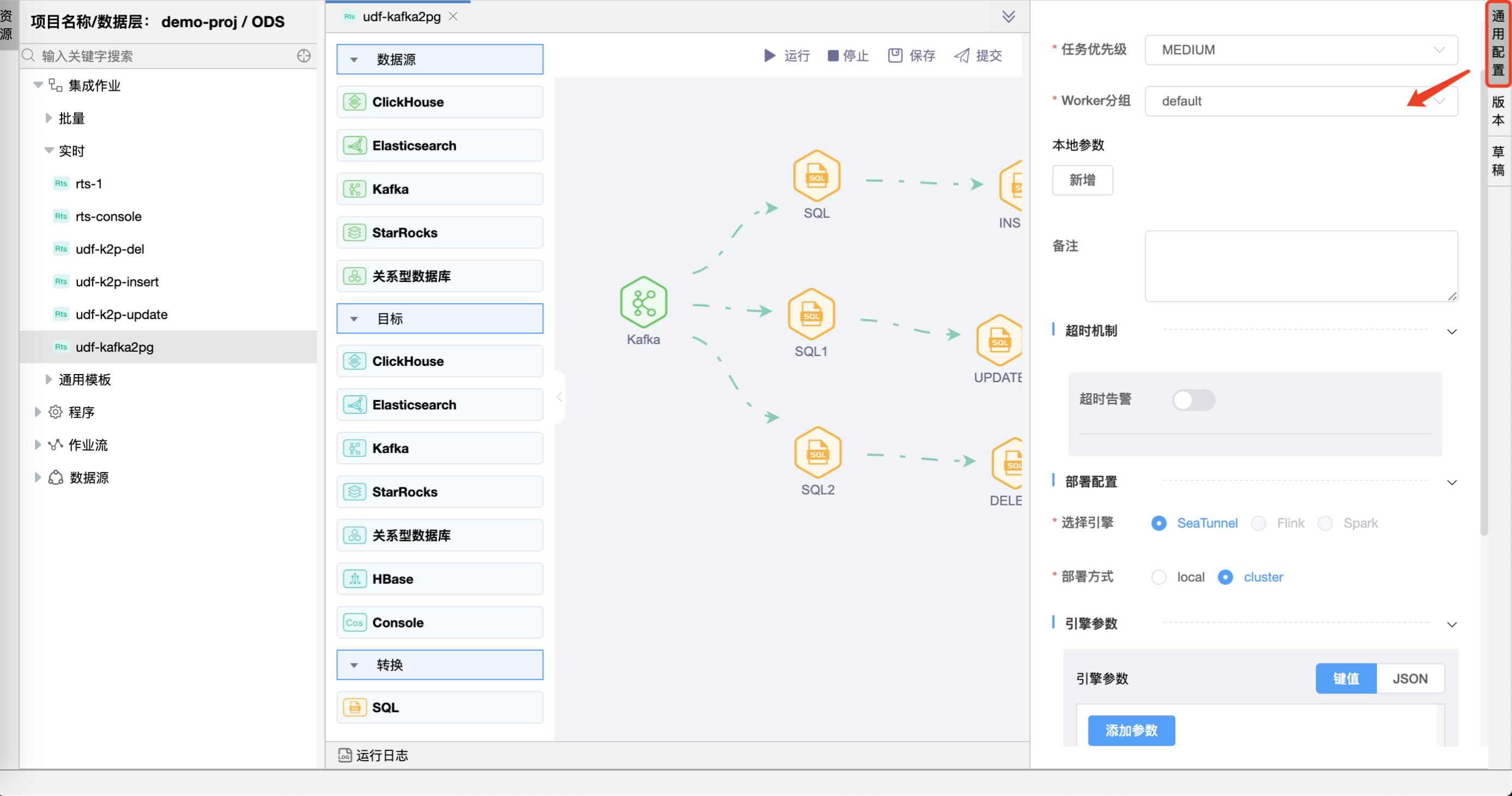
# 通用配置
在通用配置中可以配置任务优先级、Worker 分组、本地参数、超时告警、选择引擎、部署方式、引用参数。 修改属性后请务必点击【确定】按钮。
# 保存草稿
如果所有组件属性都已设置完毕,点击【保存】按钮,可以看到保存过的历史草稿,并可以随意切换草稿。(草稿只保存最近 10 个)
可以参考示例关系型表数据同步示例 中的"保存草稿"说明。
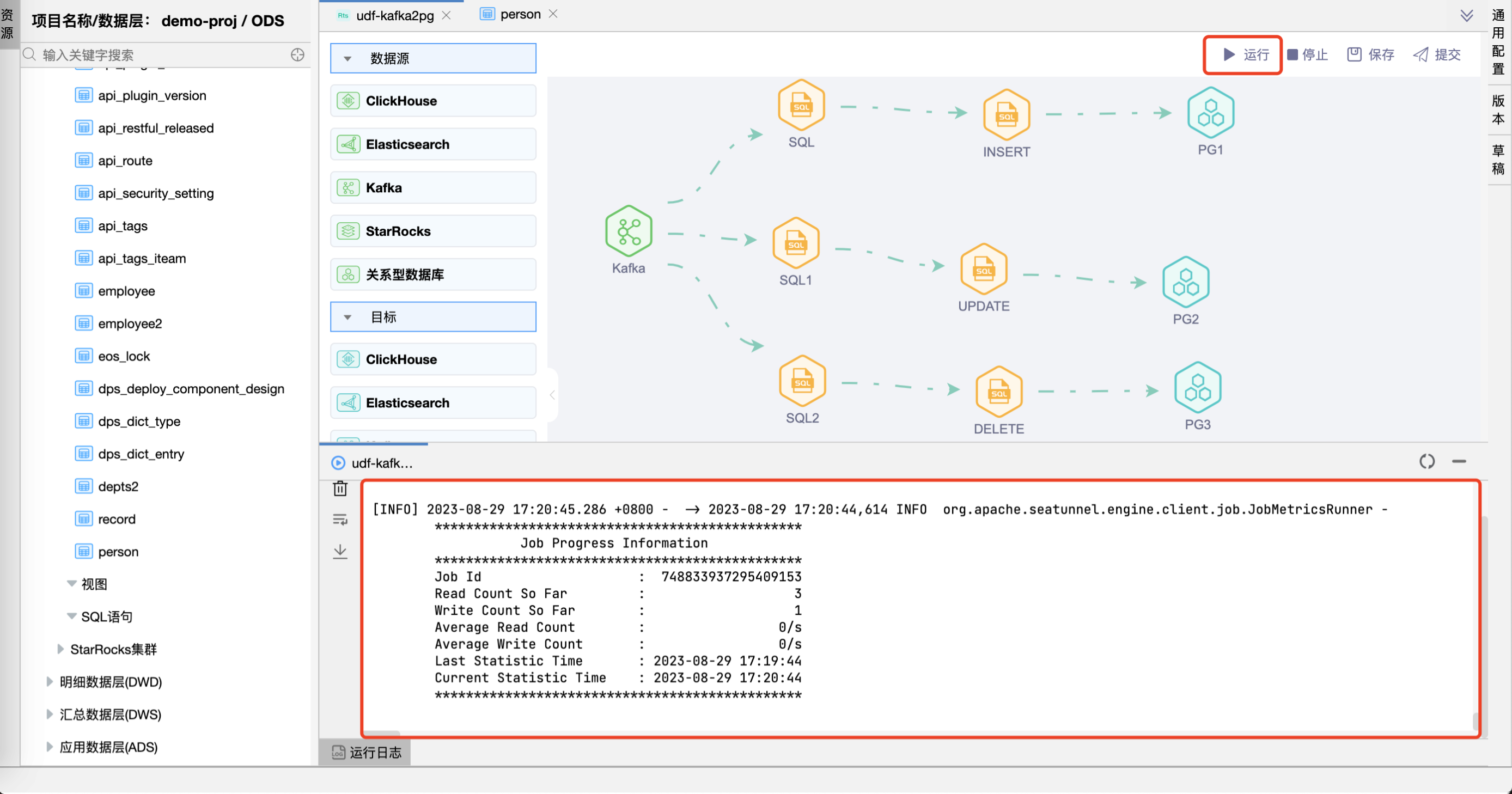
# 运行
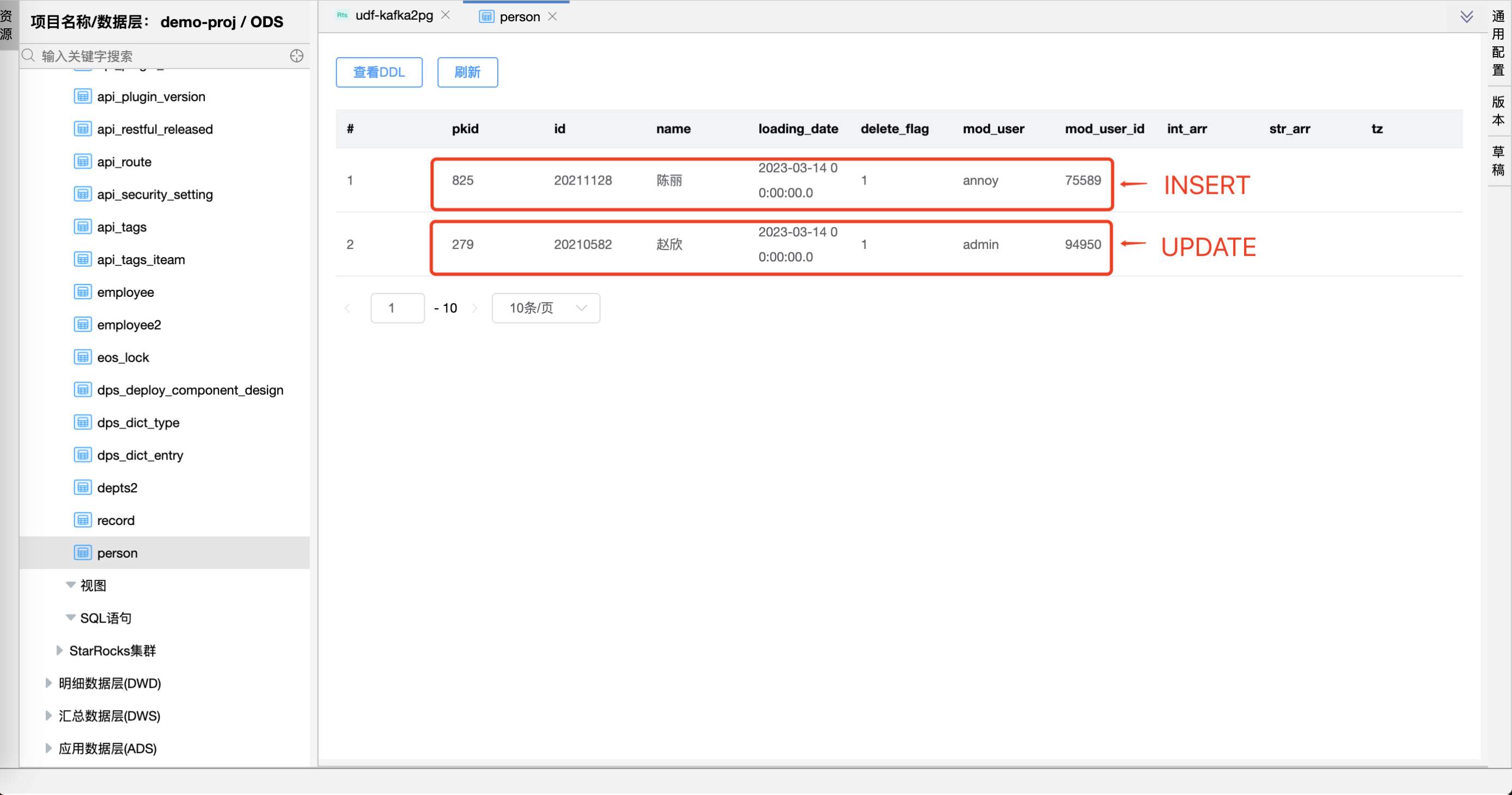
点击【运行】按钮,可以运行已经开发完毕的场景,在日志栏可以看运行日志及运行结果。
可以在 PostgreSQL 数据库表 person 中看到 UPDATE、INSERT 的数据,pkid 为 5 的数据已经被删除。
# 提交版本
当草稿运行正常后,点击【提交】按钮可以将该版本提交到作业调度,每次修改提交都会生成新的版本,可以看到提交的历史版本,并可以随意切换版本。
提交后的版本,可以在作业调度中进行"定时"调度配置。
可以参考示例关系型表数据同步示例 中的"提交版本"说明。