
# 文档提取节点
工作流中的文档提取节点能够从文件中提取内容,并将其保存为文本文件。
# 节点说明
文档提取节点是 AI 智能体AI工作流中的核心数据处理节点,专注于从各类基于文本的文档格式中精准提取纯文本内容。该功能可广泛应用于文档内容分析、文本数据挖掘、智能检索、自动化办公等场景,帮助用户快速剥离文档的格式外壳,获取可直接用于后续处理(如 AI 分析、数据存储、内容生成)的结构化文本数据,无需手动解析文档格式,大幅提升文本处理效率。
# 核心功能
- 多格式文档兼容:支持主流文本类文档格式,包括但不限于 TXT、DOCX、PDF、PPTX、XLSX(文本类数据)、Markdown(MD)、CSV 等,覆盖日常办公与业务场景中常见的文档类型。
- 精准文本提取:智能识别文档中的有效文本内容,自动过滤格式标记、页眉页脚、水印、空白字符等冗余信息,保留核心可读文本。
- 低代码快速配置:无需复杂编码,仅需设置输入文档参数与输出规则,即可完成节点配置,适配AI工作流的高效开发需求。
- 灵活数据流转:提取的文本可直接作为下游节点(如 AI 分析节点、文本存储节点、内容编辑节点)的输入,支持与工作流中的变量(用户变量、系统变量)无缝衔接。
# 配置文档提取节点
# 输入参数
输入参数固定为 “文档”,表示从指定文档中提取文本内容,参数类型为 file 或 Array<file>,支持输入方式:
- 变量引用:引用开始节点的输入、上游节点的输出、用户变量、系统变量,实现文档的动态输入。
- 支持同时处理多个文档,节点将批量提取文本并返回数组形式的结果。
# 输出参数
节点执行完成后,输出参数固定为以下 3 项,支持下游节点直接引用:
text:提取到的纯文本内容(核心输出参数),格式为 string 或 string [](批量处理时)。
# 使用示例
文档提取一般是需要从文件中获取数据交给大模型处理时才会使用的节点。
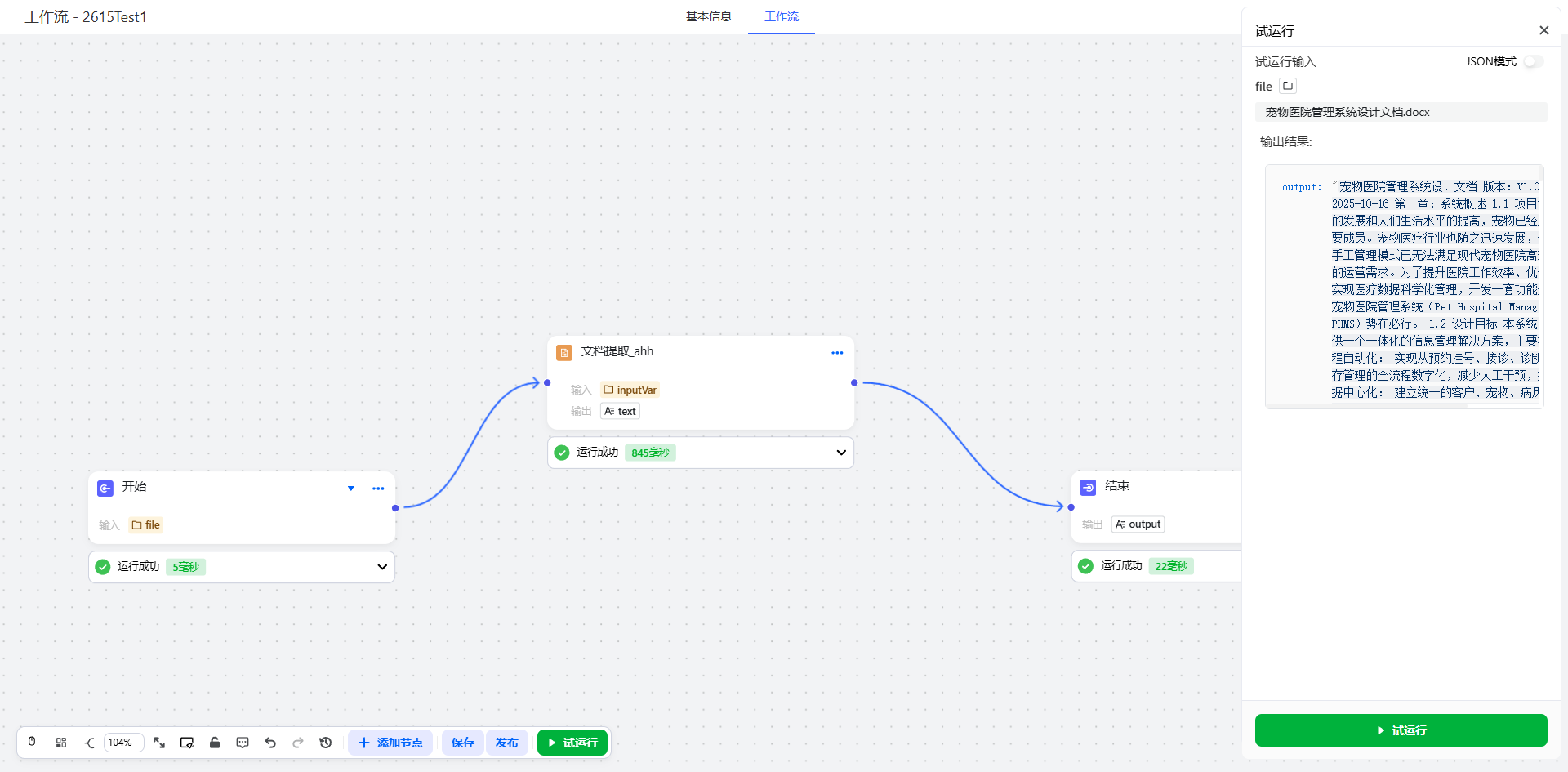
运行结果如下:
# 常见问题
(此处保留,用于后续补充常见问题与解答)