# Primeton DI 安装指南
Primeton DI 是数据加工作业的处理引擎,后续简称:DI。
1、DI 内部有两个模块:DI Server 和 DI Client。DI Server 是常驻进程;DI Client 用于与
Dolphinscheduler 的 worker进行通讯,然后将任务下发到 DI Server 执行。2、单节点部署时,DI 必须和
Dolphinscheduler 的 worker 节点部署在同一台服务器上;3、集群部署时,可以将多套 DI 部署在多个服务器上;只需要其中一套 DI (作为客户端)和
Dolphinscheduler 的 worker 节点>部署在同一台服务器上;4、Dolphinscheduler 的 PDI_HOME 的配置路径,要配置成 ${Primeton DI安装目录}/diclient 所在路径,如下所示:
export PDI_HOME=${PDI_HOME:-/home/DI/Primeton_DI_7.2.0/diclient}
Dolphinscheduler 的安装配置参见:DolphinScheduler安装指南
Primeton DI提供两种使用方式:
- 解压安装:单节点安装时推荐使用
- 集群部署安装:多节点安装时推荐使用
# 单节点解压安装
DI单节点部署时需要和 DolphinScheduler 的worker节点部署在同一台服务器。(DI既作为客户端提交任务也作为服务端运行任务)
# 1. 解压介质包
mkdir -p /home/DI/Primeton_DI_7.2.0
tar -zxvf Primeton_DI_7.2.0.tar.gz -C /home/DI/Primeton_DI_7.2.0
# 2. 修改di-server-config.yaml配置文件。
编辑 Primeton_DI_7.2.0/diserver/config/di-server-config.yaml 文件。
vi di-server-config.yaml
修改 cluster-name、member-list、port,如果没有端口冲突可以使用默认值 port: 6000。
hazelcast:
cluster-name: DI
network:
rest-api:
enabled: true
endpoint-groups:
CLUSTER_WRITE:
enabled: true
DATA:
enabled: true
join:
tcp-ip:
enabled: true
member-list:
- 192.168.16.80
port:
auto-increment: true
port-count: 100
port: 6000
properties:
hazelcast.invocation.max.retry.count: 20
hazelcast.tcp.join.port.try.count: 30
hazelcast.logging.type: log4j
hazelcast.operation.generic.thread.count: 50
di.get.server.resouce.frequence: 60000 # 获取Server所在服务器资源频率 单位:毫秒
di.server.job.maxcount: unlimited # 任务运行最大并行数,unlimited:不限制
di.project.clear.corn: 0 0 1 * * ? # 项目日志清理运行时间,默认每天1点
di.project.save.days: 30 # 项目日志保存天数
| 配置项 | 说明 |
|---|---|
| cluster-name | 集群名称,默认值是 DI。该值需要和 DI Client 的 di-client-config.yaml 中配置的一样。 |
| member-list | DI Server 的 IP,如果是集群,可以配置多个。必须和 DI Client 的 di-client-config.yaml 中 cluster-members中的 IP 一致。建议配置真实 IP,避免配置 127.0.0.1、localhost。 |
| port | DI Server 的端口,默认值是 6000。该值需要和 DI Client 的 di-client-config.yaml 中配置的一样。 |
| di.get.server.resouce.frequence | 提取 DI Server 所在服务器资源频率 单位:毫秒 |
| di.server.job.maxcount | DI Server 任务运行最大并行数,unlimited:不限制 |
| di.project.clear.corn | DI Server project目录(项目日志)清理运行时间,默认每天1点 |
| di.project.save.days | DI Server project目录(项目日志)保存天数 |
# 3.修改di-client-config.yaml配置文件
编辑 Primeton_DI_7.2.0/diserver/config/di-client-config.yaml 文件。
vi diserver/config/di-client-config.yaml
修改 cluster-name、cluster-members。
hazelcast-client:
cluster-name: DI
properties:
hazelcast.logging.type: log4j2
server.cpu.maxusages.threshold: 90
server.memory.maxusages.threshold: 90
server.disk.maxusages.threshold: 90
server.cpu.usage.weight: 50
server.memory.usage.weight: 50
client.task.dispatch.strategy: RETRY # WAITING,REJECT,RETRY
client.task.dispatch.strategy.waiting.timeout: 30 # second
client.task.dispatch.strategy.retry.times: 3
client.task.dispatch.strategy.retry.interval: 3 # second
connection-strategy:
connection-retry:
cluster-connect-timeout-millis: 3000
network:
cluster-members:
- 192.168.16.80:6000
| 配置项 | 说明 |
|---|---|
| cluster-name | 集群名称,默认值是 DI。该值必须和 DI Server 的 di-server-config.yaml 中配置的一样。 |
| hazelcast.logging.type | 日志形式,默认值是 log4j2。 |
| server.cpu.maxusages.threshold | DI Server节点CPU使用率阙值,DI Server所在服务器CPU使用率超过此阙值该节点不参与任务执行,取值范围 0-100。 |
| server.memory.maxusages.threshold | DI Server节点内存使用率阙值,DI Server所在服务器内存使用率超过此阙值该节点不参与任务执行,取值范围 0-100。 |
| server.disk.maxusages.threshold | DI Server节点磁盘使用率阙值,DI Server所在服务器磁盘使用率超过此阙值该节点不参与任务执行,取值范围 0-100。 |
| server.cpu.usage.weight | 选择DI Server执行任务,计算DI Server权重时CPU使用率所占比例,数值越大,CPU使用率所占权重越高,相同CPU使用率下,DI Server被选中执行任务的概率越小,取值范围 0-100。 |
| server.memory.usage.weight | 选择DI Server执行任务时,计算DI Server权重时内存使用率所占比例,数值越大,内存使用率所占权重越高,相同内存使用率下,DI Server被选中执行任务的概率越小,取值范围 0-100。 |
| client.task.dispatch.strategy | 客户端下发任务失败时的策略:WAITING、REJECT、RETRY。 |
| client.task.dispatch.strategy.waiting.timeout | client.task.dispatch.strategy设置WAITING时的等待时长,默认30s。 |
| client.task.dispatch.strategy.retry.times | client.task.dispatch.strategy设置RETRY时的重试次数,默认3次。 |
| client.task.dispatch.strategy.retry.interval | client.task.dispatch.strategy设置RETRY时的重试间隔,默认3s。 |
| cluster-connect-timeout-millis | 连接超时时间,默认值是 3000 毫秒。 |
| cluster-members | DI 集群中 DI Server 的 IP、Port,可以配置多个。该值需要和 DI Server 的 di-server-config.yaml 中配置的一致。 当多个DI Server组成集群时,可配置一个或多个 DI Server地址 (建议容灾配置多个DI Server地址),客户端会通过内存使用率、CPU使用率计算各个DI Server的任务权重,选择权重最高的Server执行任务。 CPU使用率、磁盘使用率、内存使用率超过阙值的DI Server节点将不参与任务执行。 |
DI 集群部署时,cluster-members 的配置格式如下:
hazelcast-client:
cluster-name: DI
properties:
hazelcast.logging.type: log4j2
server.cpu.maxusages.threshold: 90
server.memory.maxusages.threshold: 90
server.disk.maxusages.threshold: 90
server.cpu.usage.weight: 50
server.memory.usage.weight: 50
client.task.dispatch.strategy: RETRY # WAITING,REJECT,RETRY
client.task.dispatch.strategy.waiting.timeout: 30 # second
client.task.dispatch.strategy.retry.times: 3
client.task.dispatch.strategy.retry.interval: 3 # second
connection-strategy:
connection-retry:
cluster-connect-timeout-millis: 3000
network:
cluster-members:
- 192.168.16.80:6000
- 192.168.16.81:6001
- 192.168.16.82:6002
# 4. 修改拥有者
chown -R dws:dws Primeton_DI_7.2.0/
# 5. 启动 DI Server。
sh start-standalone.sh或者 ./start-standalone.sh
[dws@node5 Primeton_DI]# ./start-standalone.sh
start project directory:/home/dws/diserver
diserver start detail log see /home/dws/Primeton_DI/diserver/logs/di_server.log
执行 start-standalone.sh 提示中将标注DI Server运行日志路径:${Primeton DI安装目录}/diserver/logs/di_server.log。
- 运行日志中出现如下信息
DI Server started successfully则表示DI Server启动成功。
[INFO][LifecycleService:57][Line:57] [192.168.16.80]:6001 [DI] [5.1.7] [192.168.16.80]:6001 is STARTED
[INFO][DIServer:119][Line:119] DI Server started successfully.
若运行日志停在「欢迎使用企业版」。未出现 DI Server started successfully信息,则需要检查 license 是否过期或被篡改。
License 文件路径:${Primeton DI安装目录}/diserver/config/primetonlicense.xml
[INFO][DIServer:119][Line:119] *******************************
[INFO][DIServer:119][Line:119] * Start The DI Server *
[INFO][DIServer:119][Line:119] *******************************
[INFO][ImprimaturStartUpListener:75][Line:75] 欢迎使用企业版。
# 集群安装部署
前置条件:集群机器已配置免密登录。安装必读
1. DI 集群部署时,集群作为服务端;需要在 DolphinScheduler 的
worker节点所在服务器部署DI客户端,DI客户端向集群提交任务,不需要启动。2. DI客户端配置文件:diserver/config/di-client-config.yaml文件中的`cluster-name`和`cluster-members`参数必须和集群服务端的参数保持一致(参考集群服务端的diserver/config/di-server-config.yaml中的参数)
# 1. 解压介质包
mkdir -p /opt/DI/
tar -zxvf Primeton_DI_7.2.0.tar.gz -C /opt/DI
chown -R dws:dws /opt/DI
# 2. 修改install_env.sh脚本
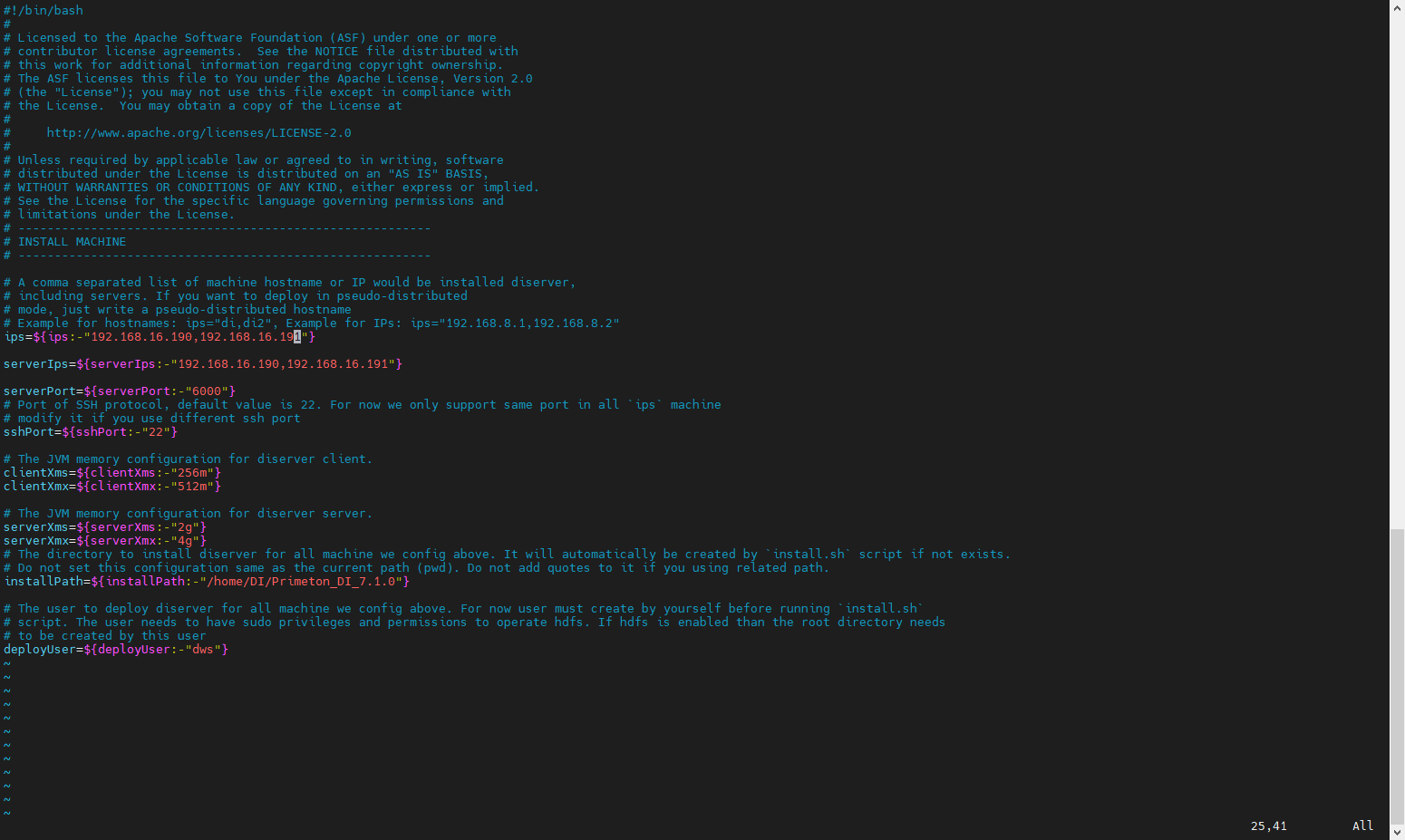
修改 install/install_env.sh 脚本中的ips 参数值为需要集群部署的机器地址。
修改 install/install_env.sh 脚本中的installPath 参数值为安装路径。
vim install/install_env.sh
ips=${ips:-"192.168.16.190,192.168.16.191"}
serverIps=${serverIps:-"192.168.16.190,192.168.16.191"} #指定哪些服务器作为server端
serverPort=${serverPort:-"6000"}
sshPort=${sshPort:-"22"}
clientXms=${clientXms:-"256m"}
clientXmx=${clientXmx:-"512m"}
serverXms=${serverXms:-"2g"}
serverXmx=${serverXmx:-"4g"}
deployUser=${deployUser:-"dws"}
installPath=${installPath:-"/home/DI/Primeton_DI_7.2.0"}
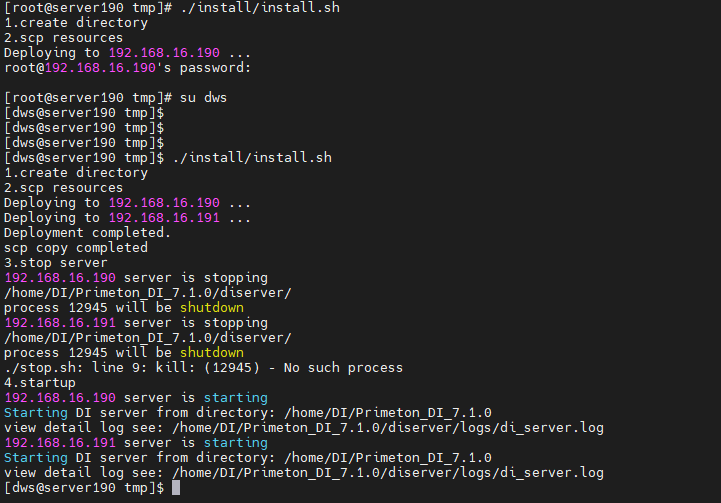
# 3. 集群安装
install/install.sh脚本,自动在集群机器上安装DI并启动。
su dws
./install/install.sh
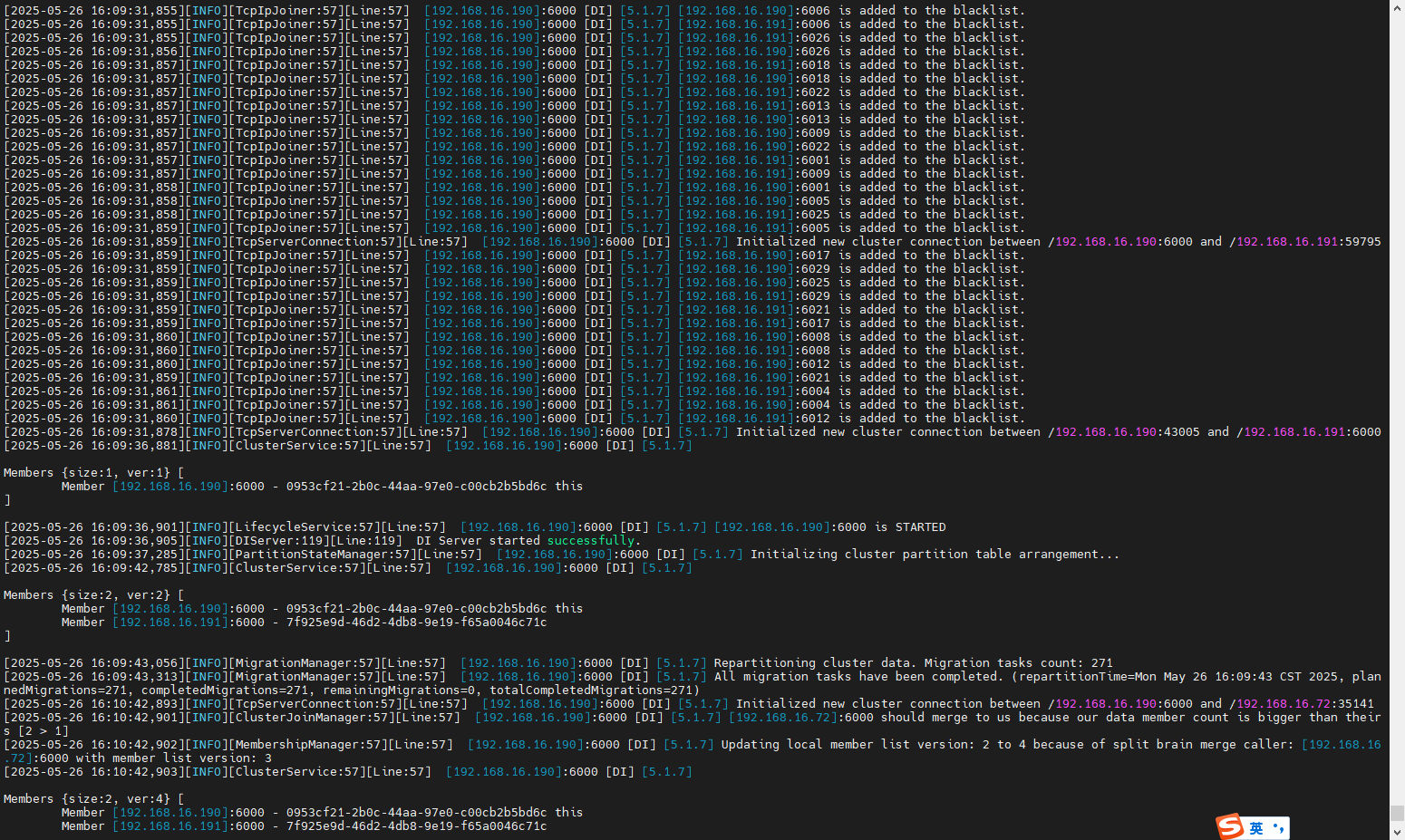
# 4.启动停止DI集群
启动DI集群命令:
su dws
cd /home/DI/Primeton_DI_7.2.0
./start-cluster.sh
停止DI集群命令:
su dws
cd /home/DI/Primeton_DI_7.2.0
./stop-cluster.sh
停止集群中的某个节点可以在对应服务器上执行./stop-standalone.sh脚本。
# 配置 Hadoop 集群环境(可选配置)
如果用户需要使用大数据环境,则需进行此配置,请详细阅读该章节并按照步骤进行配置。
Hadoop 集群支持的类型主要分为cdh、tdh。请在使用前先查看 Hadoop 集群的版本再进行下一步。
cdh版本:CDH6.3.1
tdh版本:transwarp-9.0.0
- 修改 Primeton_DI_7.2.0/diserver/plugins/plugin-bigdata/plugin.properties 配置文件。修改 plugin.library.path 参数值为所使用的集群类型,如 cdh、tdh。
这里修改的 cdh 即代表使用 Primeton_DI_7.2.0/diserver/plugins/plugin-bigdata/cdh 目录下的jar包。

- 需要将 Hadoop 服务器环境中的core-site.xml、hbase-site.xml、hdfs-site.xml等文件放到 Primeton_DI_7.2.0/diserver/plugins/plugin-bigdata/config 目录下。
通常情况下,core-site.xml、hbase-site.xml 文件中都是使用的域名,故需要在服务器 `/etc/hosts`文件中配置大数据环境的域名。
- 若大数据环境需要 kerberos 认证,则还需要做以下操作
在 Primeton_DI_7.2.0/diserver/config/kerberos 目录下放置以下文件:
├── krb5.conf ├── krb5.keytab ├── jaas.conf修改 diserver/config/kerberos.properties 中的 kerberos 认证信息。
#是否开启kerberos认证,需要开启时设置为true username.client.kerberos.enable=false #kerberos认证的principal username.client.kerberos.principal=hive/cdh01@DWS.COM #kerberos认证凭证刷新间隔时间,单位分钟 username.client.kerberos.relogin-delay=30 #是否开启tdc,星环大数据环境的一种模式 username.client.tdc.env=falsekrb5.conf、krb5.keytab以及principal信息请联系对应的服务提供商获取,此处仅供参考。
在 Primeton_DI_7.2.0 服务所在服务器上执行 kinit 命令初始化票据信息:
#kinit -kt /export/kerberos/1/a.keytab a/a@A.COM kinit -kt krb5.keytab hive/cdh01@DWS.COM
# DI 运维操作(可选操作)
使用 tail 命令动态查看 DI Server 运行日志。
tail -200f ${Primeton DI安装目录}/diserver/logs/di_server.log
DI Server 运行日志配置
如需修改运行日志相关配置,可编辑 Primeton_DI_7.2.0/diserver/config/di-server-log4j.properties 文件。
vi di-server-log4j.properties
可修改日志输出格式、日志文件路径及文件名称
name=Log4j2PropertiesConfig
property.baseDir=logs
property.appName=di_server
property.filePattern=${baseDir}/${appName}-%d{yyyy-MM-dd}-%i.log.gz
property.maxFileSize=10MB
property.maxHistory=30
property.totalSizeCap=500MB
appender.console.type=Console
appender.console.name=ConsoleAppender
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %highlight{%-5level} %logger{36} - %msg%n
appender.rolling.type=RollingFile
appender.rolling.name=RollingFileAppender
appender.rolling.fileName=${baseDir}/${appName}.log
appender.rolling.filePattern=${filePattern}
appender.rolling.layout.type=PatternLayout
appender.rolling.layout.pattern=%d{yyyy-MM-dd HH:mm:ss.SSS} [%tid] [%t] %-5level %logger{36}:%L - %msg%n
appender.rolling.policy.type=Policies
appender.rolling.policy.time.type=TimeBasedTriggeringPolicy
appender.rolling.policy.time.interval=1
appender.rolling.policy.time.modulate=true
appender.rolling.policy.size.type=SizeBasedTriggeringPolicy
appender.rolling.policy.size.size=${maxFileSize}
appender.rolling.strategy.type=DefaultRolloverStrategy
appender.rolling.strategy.max=${maxHistory}
appender.rolling.strategy.totalSizeCap=${totalSizeCap}
appender.rolling.strategy.delete.type=Delete
appender.rolling.strategy.delete.basePath=${baseDir}
appender.rolling.strategy.delete.maxDepth=1
appender.rolling.strategy.delete.ifLastModified.type=IfLastModified
appender.rolling.strategy.delete.ifLastModified.age=${maxHistory}d
appender.rolling.strategy.delete.ifFileName.type=IfFileName
appender.rolling.strategy.delete.ifFileName.glob=*.log.gz
rootLogger.level=INFO
rootLogger.appenderRefs=console, rolling
rootLogger.appenderRef.console.ref=ConsoleAppender
rootLogger.appenderRef.rolling.ref=RollingFileAppender
DI Server 运行日志默认路径: ${Primeton DI安装目录}/diserver/logs/di_server.log
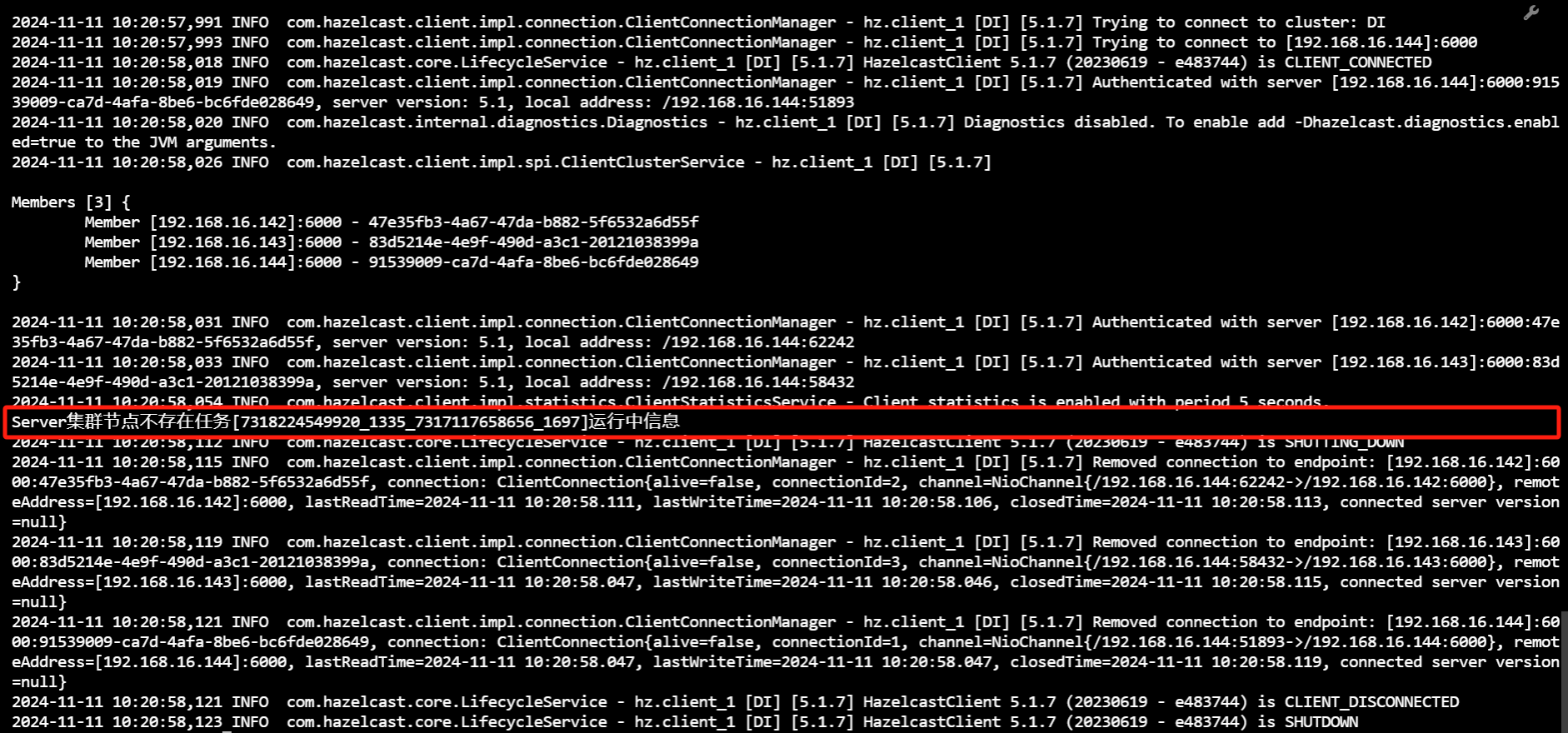
- 查询运行中任务列表
用户可进入${Primeton DI安装目录}/diclient 目录,执行 showtasks.sh 脚本查询 DI 集群中各个 Server 节点正在运行中的任务列表(获取任务执行 JobId 列表)。
sh showtasks.sh 或者 ./showtasks.sh
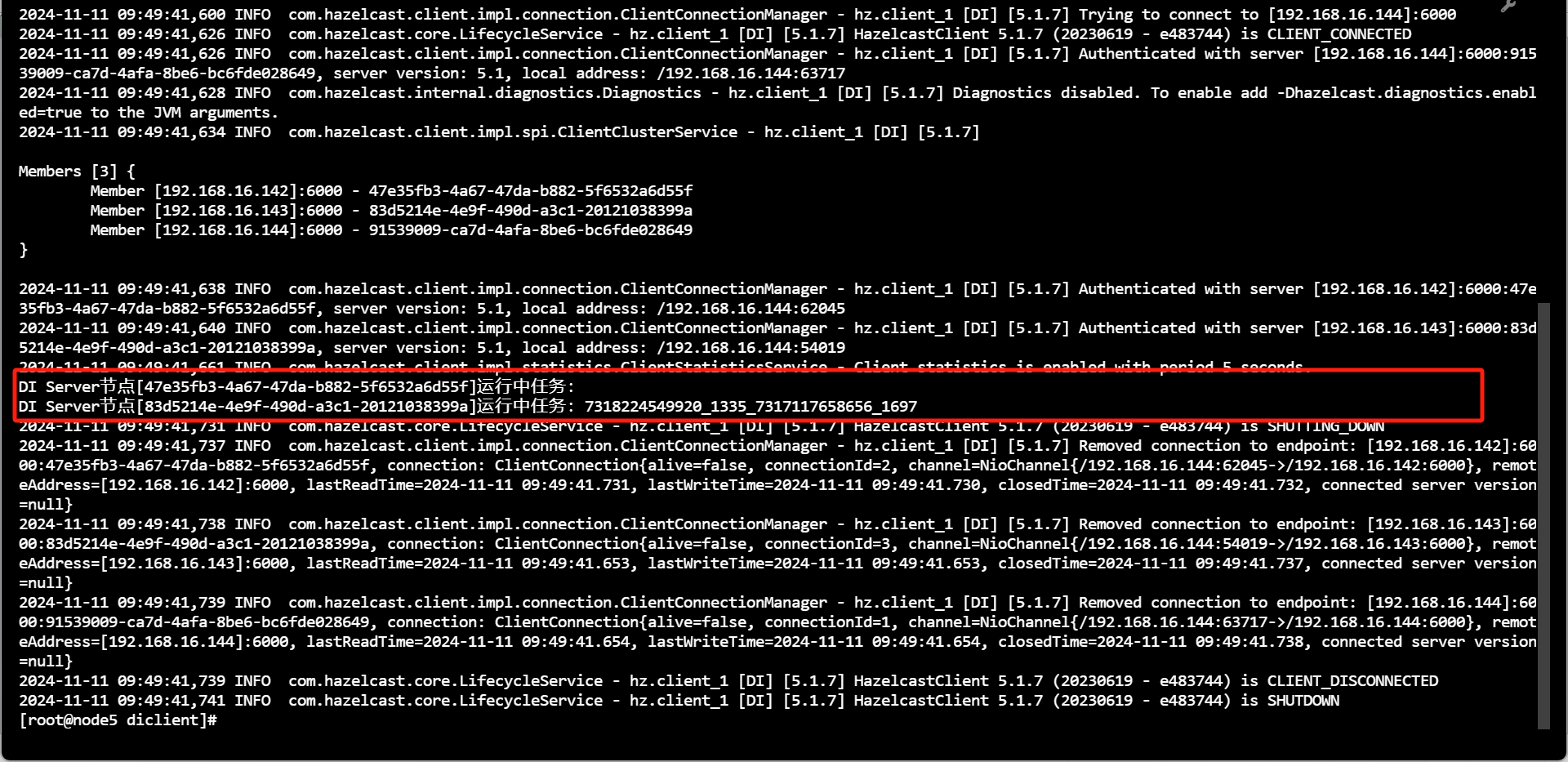
执行 showtasks.sh 命令获取的JobId组成逻辑:
jobId = system.workflow.definition.code_system.workflow.instance.id_system.task.definition.code_system.task.instance.id
- 停止运行中任务
用户可进入${Primeton DI安装目录}/diclient 目录,执行 stoptask.sh 脚本停止 DI 集群中正在运行的任务(参数为上一步骤查询获得的任务 JobId)。
sh stoptask.sh jobId 或者 ./stoptask.sh jobId
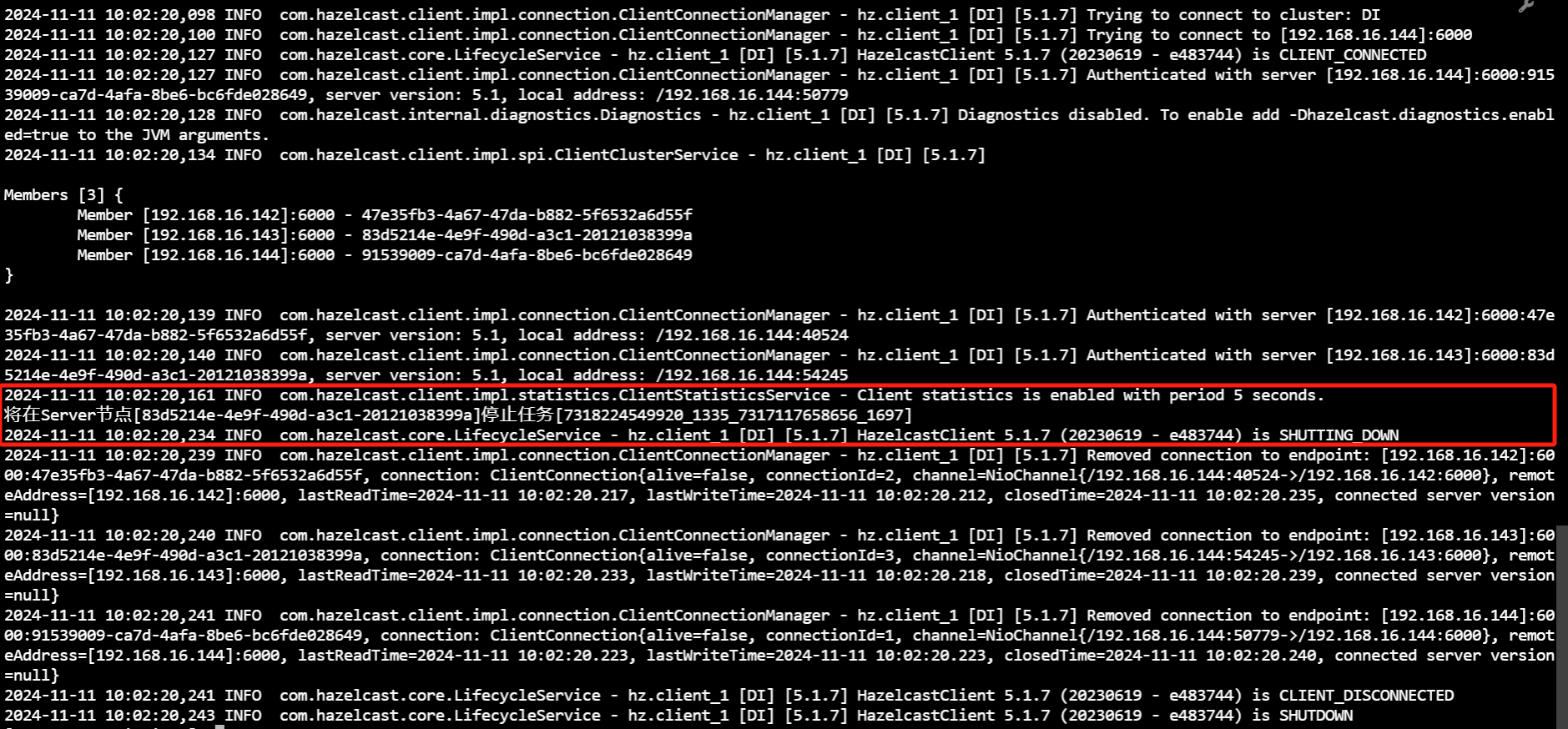
若 DI 集群中未运行 JobId 为传入参数的任务,则提示‘Server集群节点不存在任务[jobId]运行中信息’