# 调度引擎管理
调度引擎是一个分布式易扩展的作业流任务调度系统。调度引擎以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
调度引擎管理涉及的功能包括:
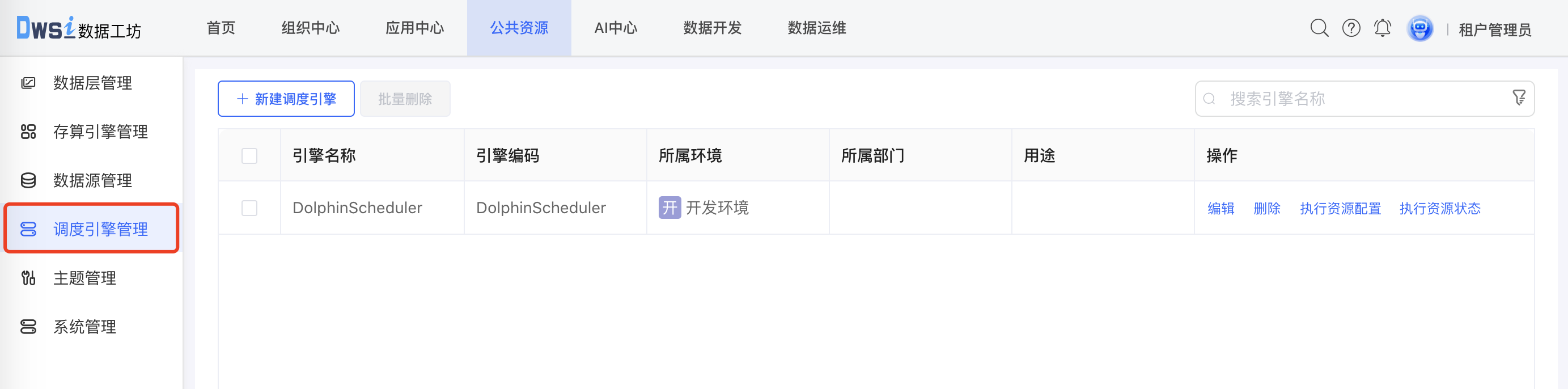
点击上方菜单栏“公共资源”,进入公共资源管理界面,再点击左侧菜单栏的"调度引擎管理",进入调度引擎管理界面。
# 新增调度引擎
新建之前,请确保「调度引擎」介质已经部署完毕,并正常启动。
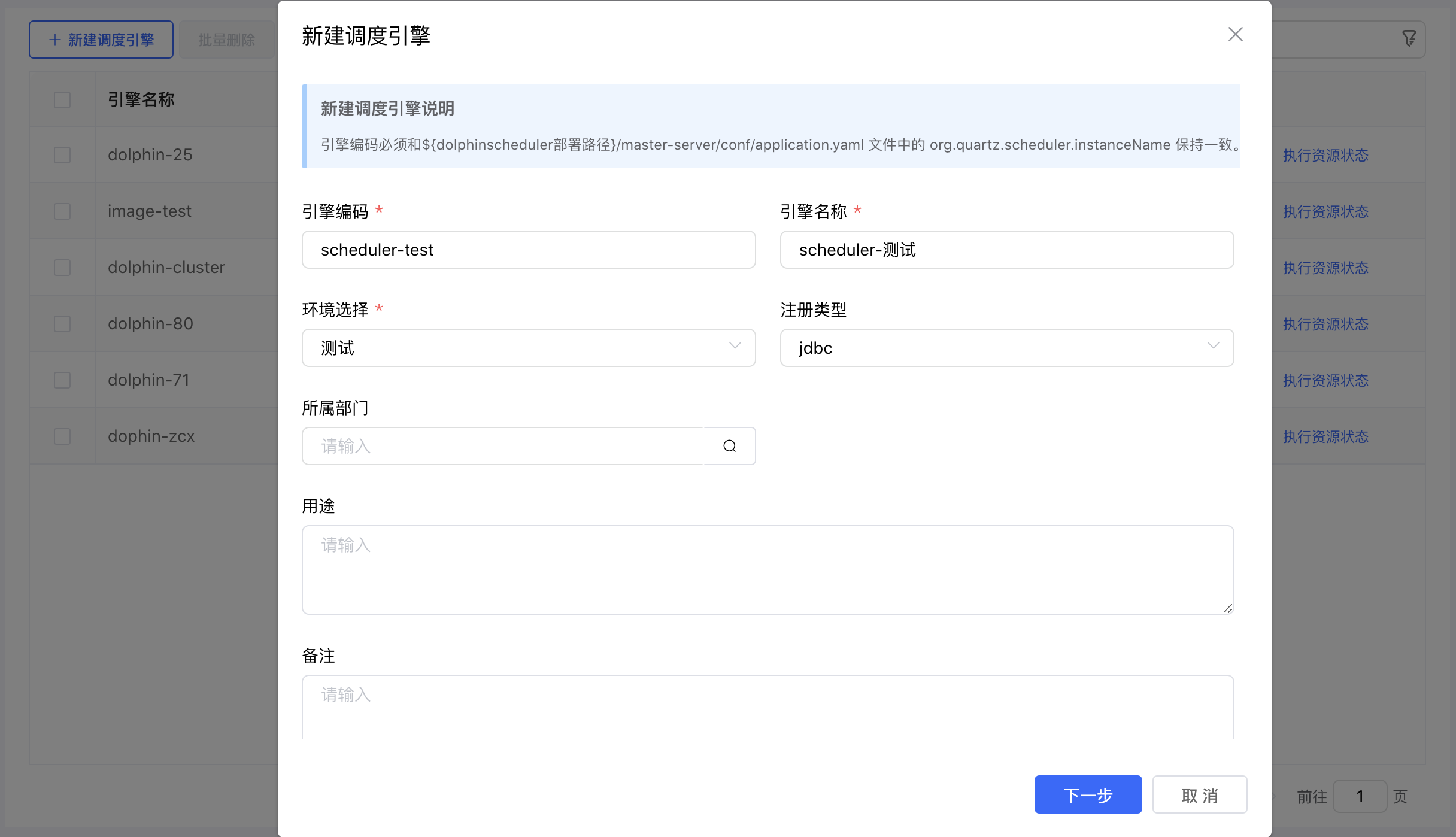
点击【+新建调度引擎】按钮,弹出"新建调度引擎"界面。按照向导页面要求录入调度引擎的参数配置信息。
1、「引擎编码」必须和配置文件中的 org.quartz.scheduler.instanceName: scheduler-test 保持一致(比如:scheduler-test)。用户可以自行修改配置文件的 instanceName ,然后再创建调度引擎。
2、如果 instanceName 不一致,会造成定时调度任务不执行的问题。
配置文件路径:/apache-dolphinscheduler-7.2.0-bin/master-server/conf/application.yaml
具体如下:
(略)
properties:
org.quartz.threadPool.threadPriority: 5
org.quartz.jobStore.isClustered: true
org.quartz.jobStore.class: org.springframework.scheduling.quartz.LocalDataSourceJobStore
org.quartz.scheduler.instanceId: AUTO
org.quartz.jobStore.tablePrefix: QRTZ_
org.quartz.jobStore.acquireTriggersWithinLock: true
org.quartz.scheduler.instanceName: scheduler-test
org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
org.quartz.jobStore.useProperties: false
org.quartz.threadPool.makeThreadsDaemons: true
org.quartz.threadPool.threadCount: 25
org.quartz.jobStore.misfireThreshold: 60000
org.quartz.scheduler.batchTriggerAcquisitionMaxCount: 1
org.quartz.scheduler.makeSchedulerThreadDaemon: true
org.quartz.jobStore.driverDelegateClass: org.quartz.impl.jdbcjobstore.PostgreSQLDelegate
org.quartz.jobStore.clusterCheckinInterval: 5000
(略)
点击【下一步】按钮,按照向导页面要求继续录入调度引擎参数配置。
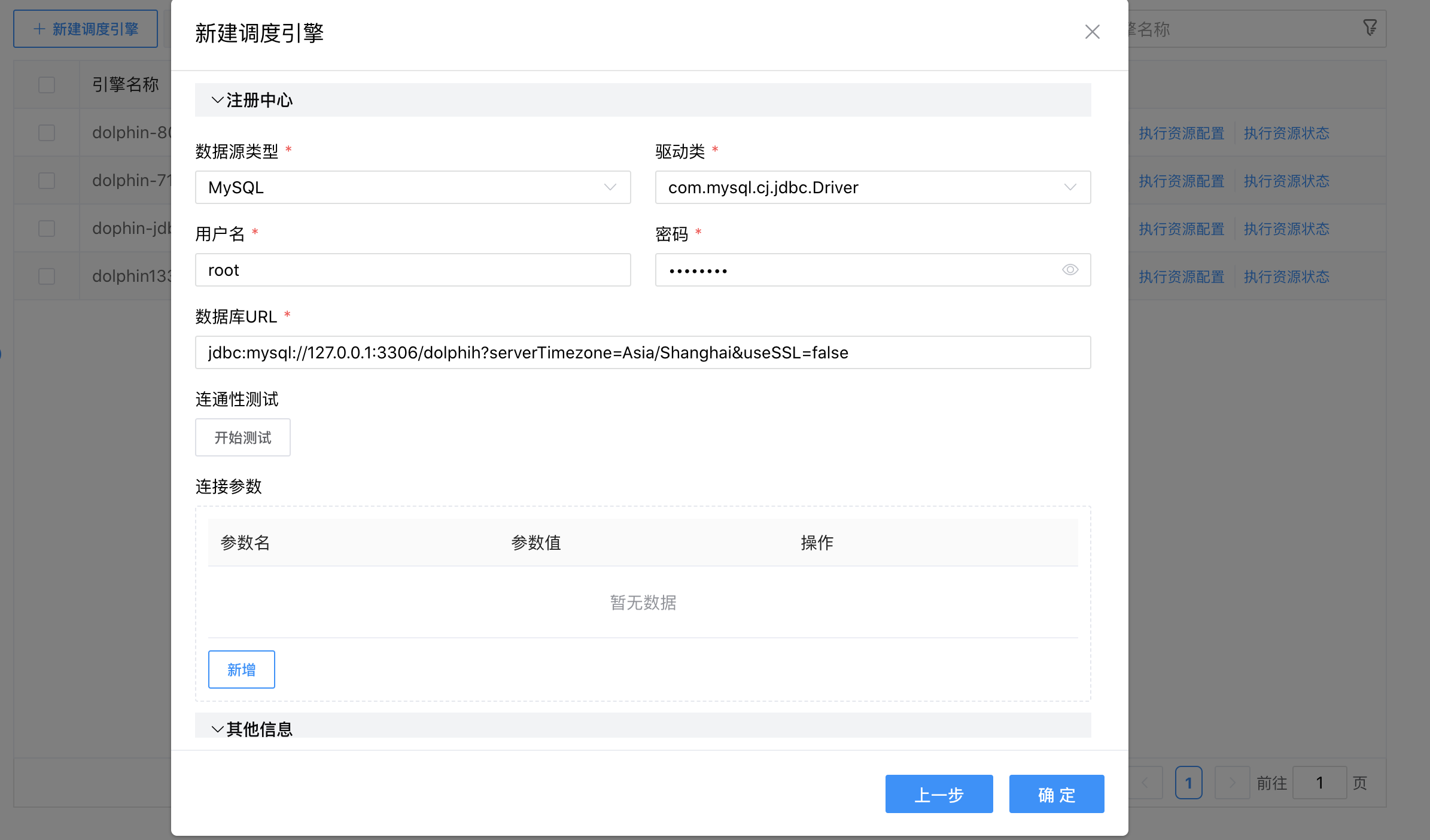
点击【确定】按钮,完成新建调度引擎的操作。
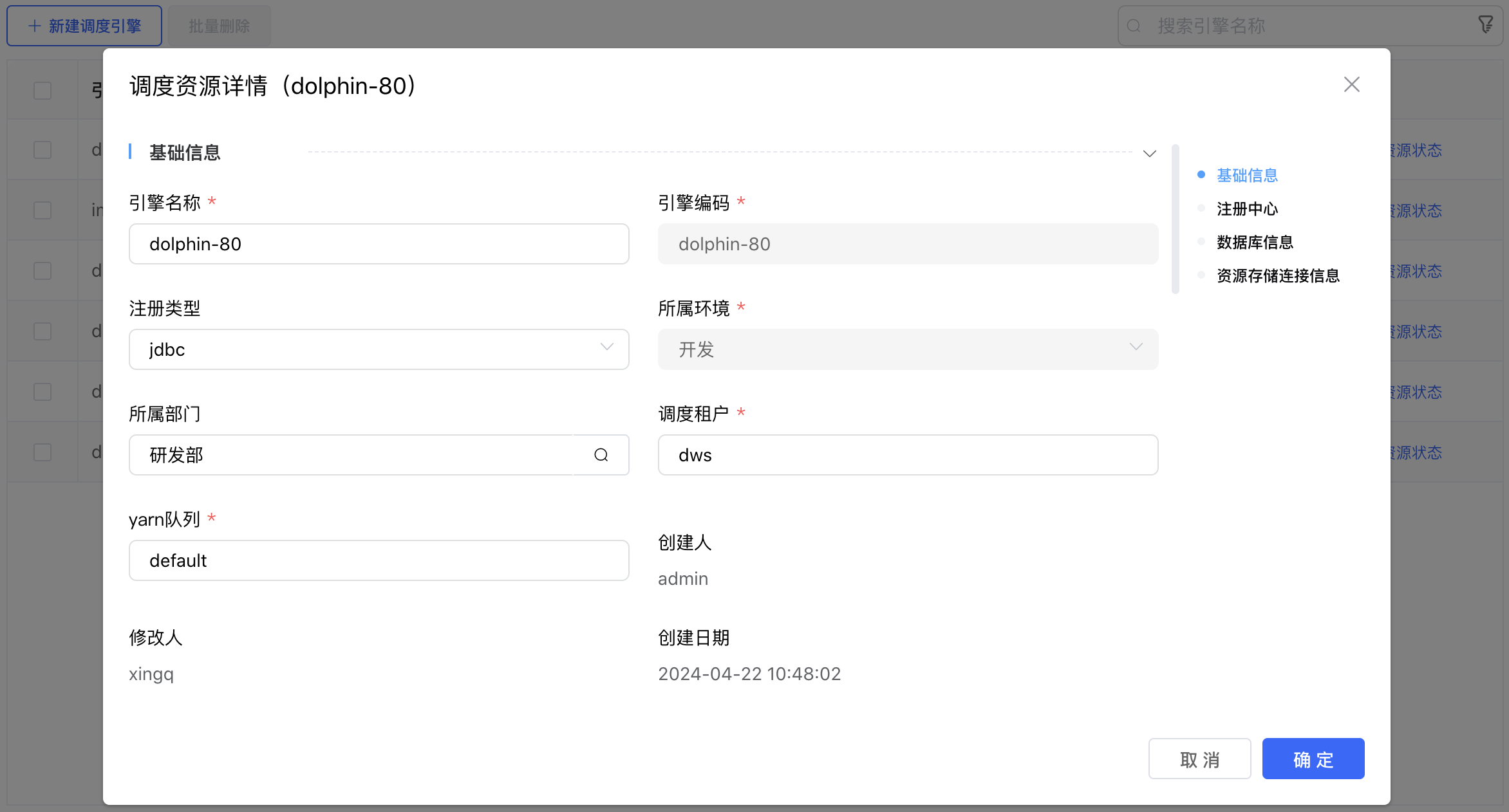
基础信息配置项说明:
| 参数 | 说明 |
|---|---|
| 引擎编码 | 当前创建的调度引擎编码,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 引擎名称 | 当前创建的调度引擎名称,由用户自定义且不可为空。命名可包含汉子、字母、数字、下划线。 |
| 环境选择 | 当前创建的调度引擎所属的环境,从下拉选项选择(数据字典)且不可为空。 |
| 注册类型 | 目前支持 jdbc 和 zookeeper 两种方式。默认是 jdbc 注册方式。 |
| 所属部门 | 当前创建的调度引擎所属部门,从机构选项进行选择。 |
| 用途 | 当前创建的调度引擎的用途说明。 |
| 备注 | 当前创建的调度引擎的备注信息,用于记录用户自定义内容。 |
注册中心配置项说明:
注册方式一: 当「注册类型」是 jdbc 时,是将调度引擎的配置信息存储在数据库中。配置项如下:
| 参数 | 说明 |
|---|---|
| 数据源类型 | 调度引擎信息存储的数据库类型。 |
| 驱动类 | 数据库类型对应的驱动类。 |
| 用户名 | 数据库名称。 |
| 密码 | 数据库密码。 |
| 数据库URL | 数据库连接 URL。 |
| 连接参数 | 额外的连接参数,根据实际需求进行配置。 |
| 调度租户 | 当前创建的调度引擎的调度租户信息。 DWS安装必读 时创建的免密用户,即在 bin/env/install_env.sh 中配置的 deployUser=${deployUser:-"dws"}。 |
| yarn队列 | 当前创建的调度引擎的 yarn 队列名称。 |
注册方式二: 当「注册类型」是 zookeeper 时,是将调度引擎的配置信息存储在 zookeeper 中。配置项如下:
| 参数 | 说明 |
|---|---|
| zookeeper 注册地址 | 当前创建的调度引擎的 zookeeper 注册地址。 |
| namespace | 当前创建的调度引擎的 namespace。 namespace 即部署 DolphinScheduler 时在 bin/env/install_env.sh 中配置的 zkRoot=${zkRoot:-"/dws"}。 |
| digest | 是 zookeeper 基于用户名 + 密码拼接的字符串。 |
| 连接参数 | 额外的连接参数,根据实际需求进行配置。 |
| 调度租户 | 当前创建的调度引擎的调度租户信息。 DWS安装必读 时创建的免密用户,即在 bin/env/install_env.sh 中配置的 deployUser=${deployUser:-"dws"}。 |
| yarn队列 | 当前创建的调度引擎的 yarn 队列名称。默认值是:default。 |
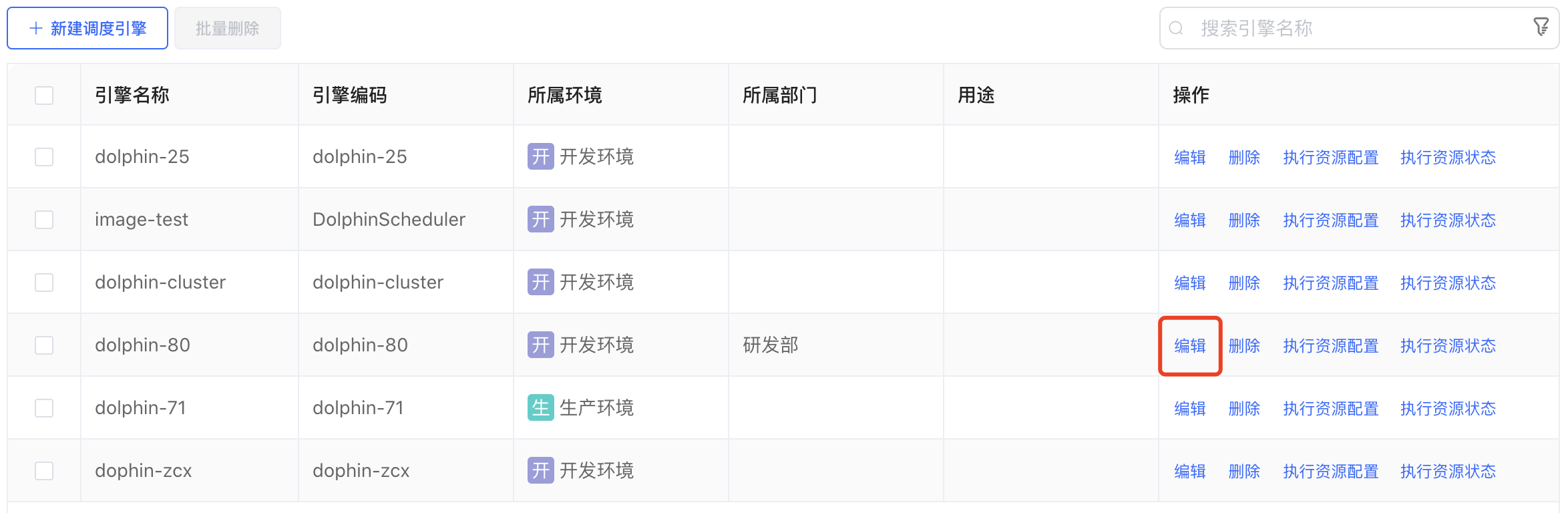
# 修改调度引擎
点击存算引擎列表右侧的【编辑】按钮,弹出"调度资源详情"弹窗,用户可以根据需求进行参数的修改。
点击【确定】按钮,完成参数的修改、保存。
点击【取消】按钮,取消本次修改操作。
# 删除调度引擎
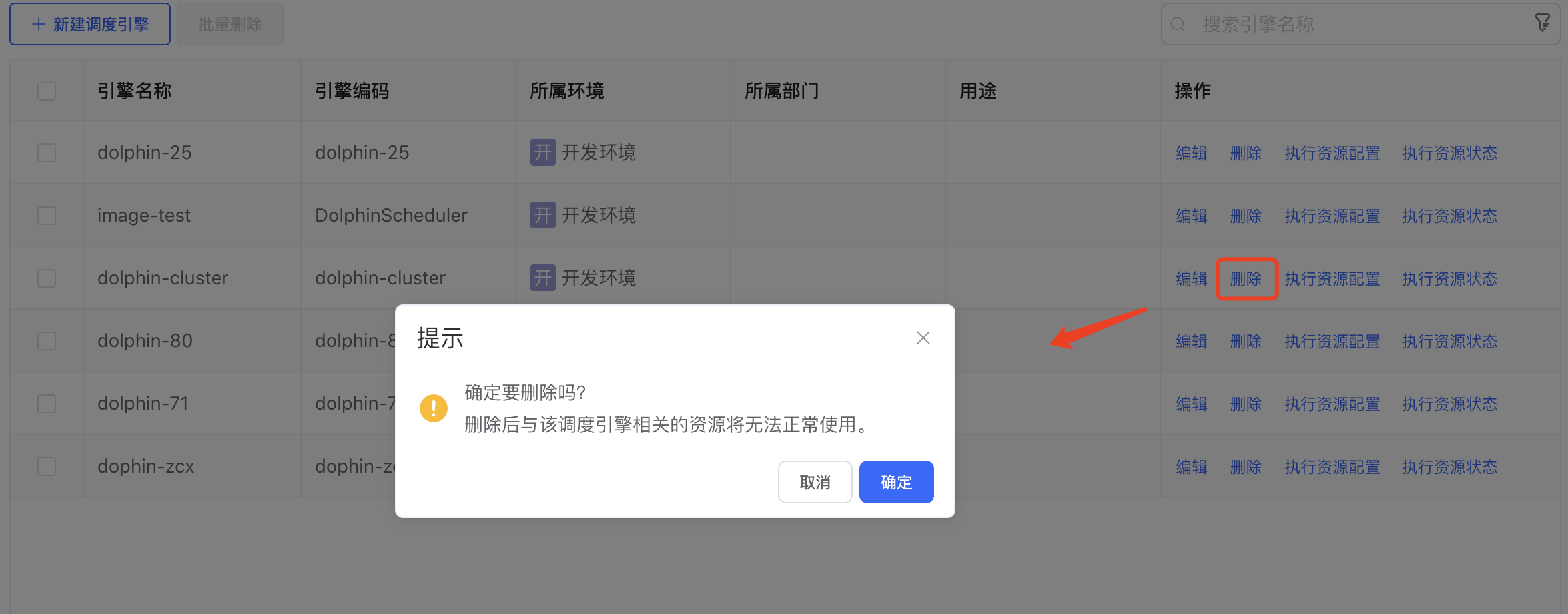
点击调度引擎列表后边的【删除】按钮,弹出"删除确认"信息。按照要求解绑后才能继续删除操作。
点击弹框的【确认】按钮,完成删除操作。
点击弹框的【取消】按钮,取消本次删除操作。
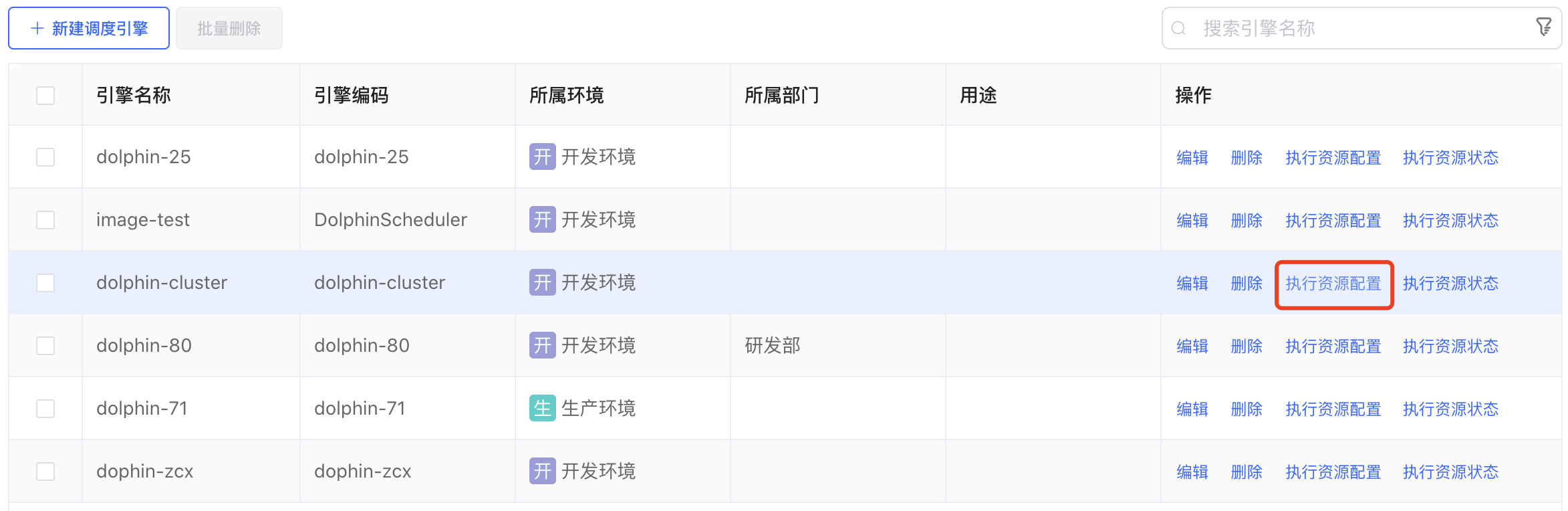
# 执行资源配置
点击调度引擎列表后边的【执行资源配置】按钮,弹出"执行资源配置"弹窗。
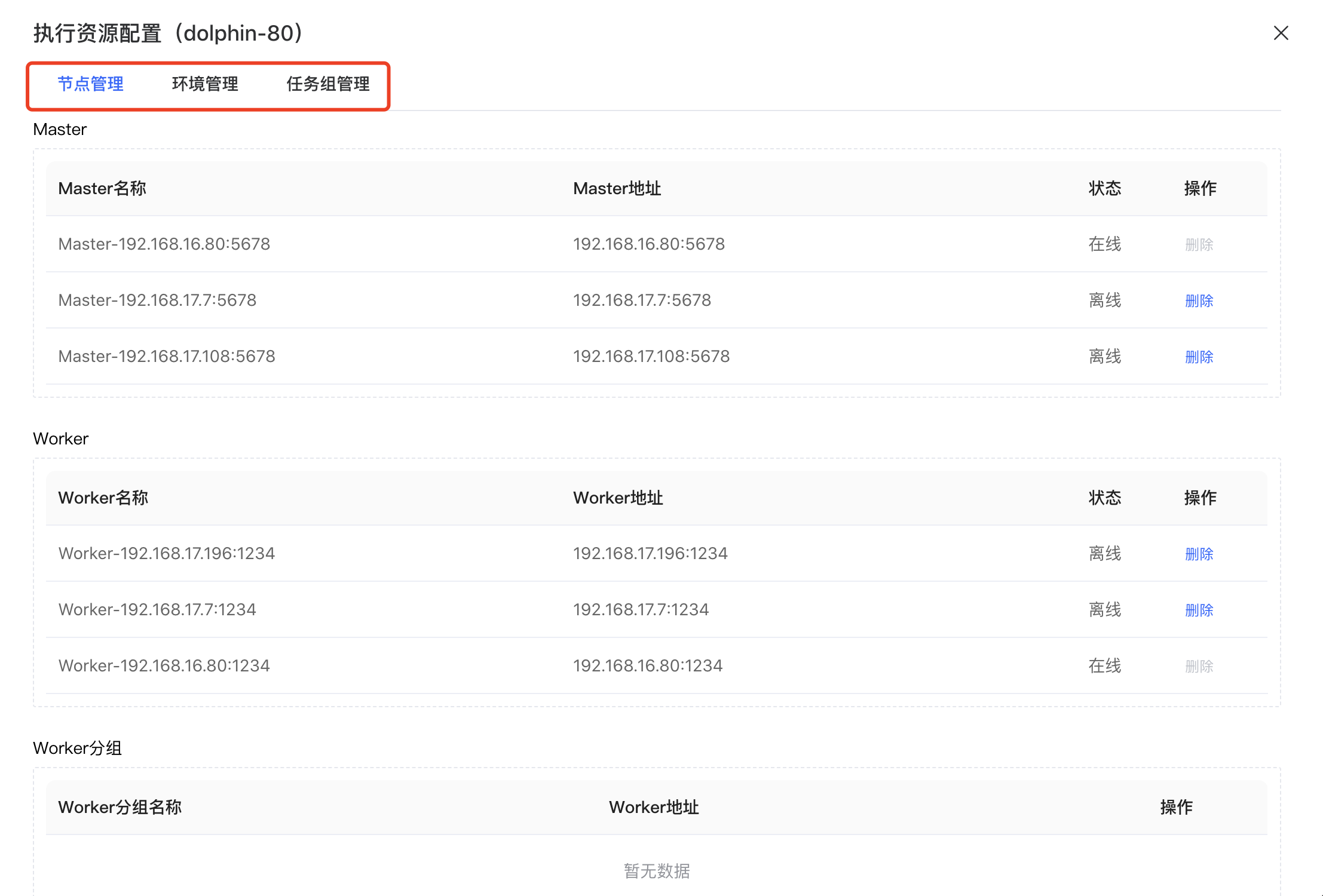
# 节点管理
选择“节点管理”,可以管理调度引擎的 Worker 节点。
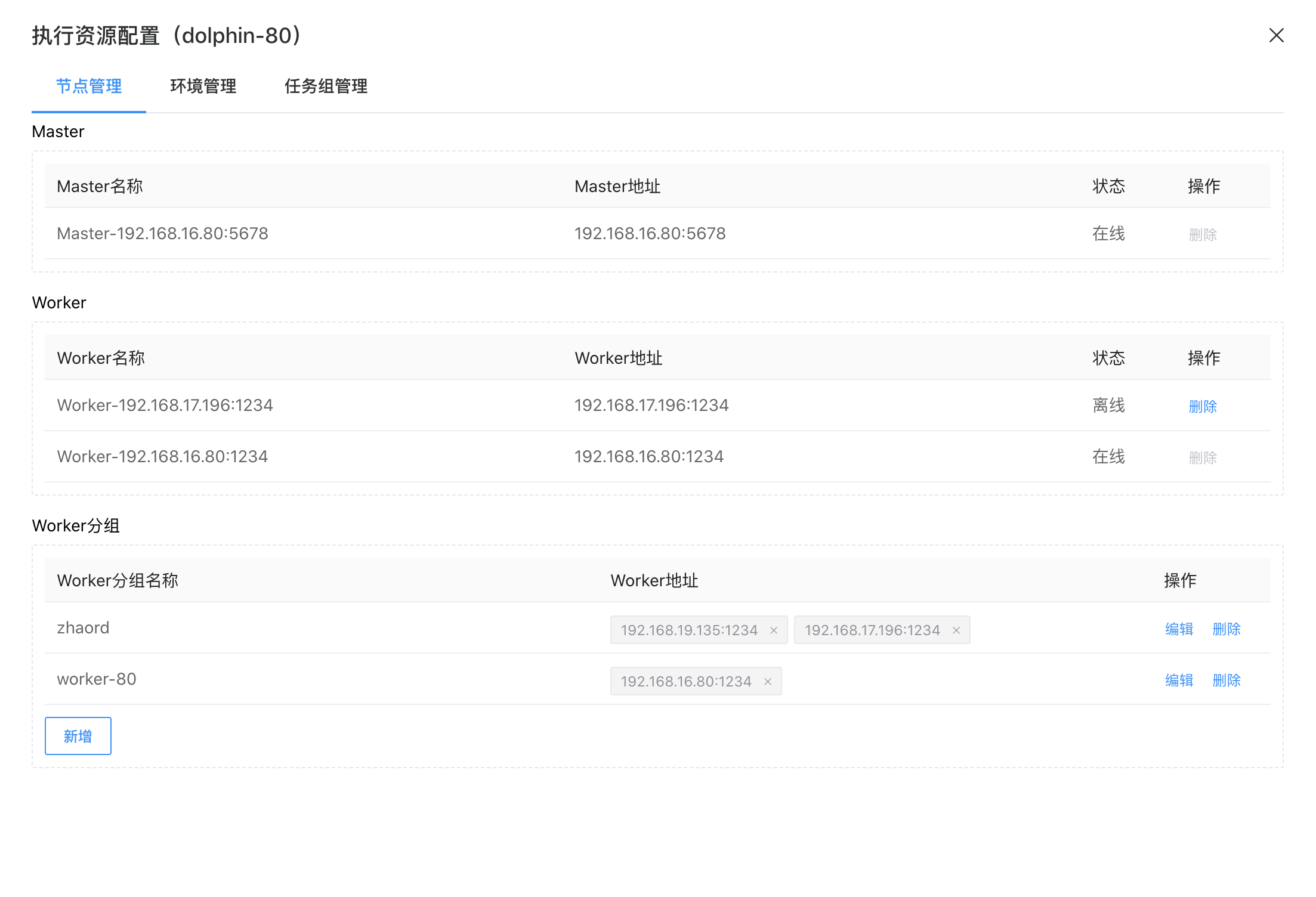
点击底部的【新增】按钮,可以添加执行资源的 Worker 分组。用户可以将选择不同 Worker 节点放在同一个分组中。
1、Master、Worker 下列表显示的节点会自动发现并显示,不允许删除。
2、Worker分组名称具有唯一性,不允许重名。
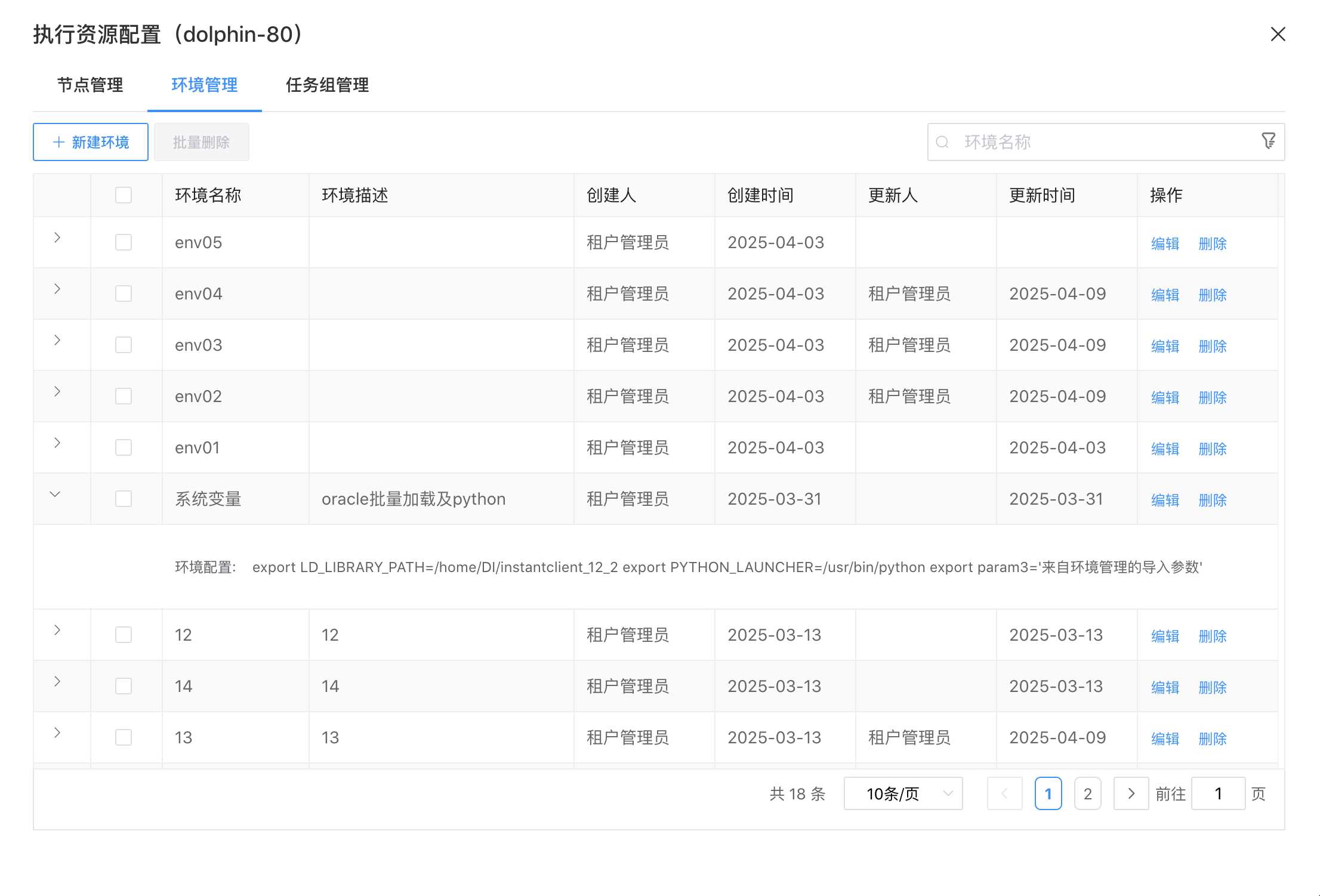
# 环境管理
为指定的 Worker 组预先定义一套任务执行时需要的环境变量(如JAVA_HOME、HIVE_HOME、SPARK_HOME等)。
解决不同任务对运行环境依赖不同的问题。你不需要登录服务器修改.bashrc,直接在页面上为不同任务类型(Hive、Spark、Shell)创建独立的环境,并在工作流运行时动态选择。
在任务执行时,将任务分配给指定 Worker 分组,根据 Worker 分组选择对应的环境,最终由该组中的 Worker 节点执行环境来执行任务。
比如:Worker1 配置了两个 DI 环境 DI1、DI2,在 IDE 的通用配置中,作业1选择环境“DI1”,作业2选择环境“DI2”,则在具体执行时作业1、作业2分别在环境 DI1、DI2 执行。
选择“环境管理”,进入环境管理界面。
点击【新建环境】按钮,填入环境名称、环境配置、环境描述,即可新建 Worker 环境。
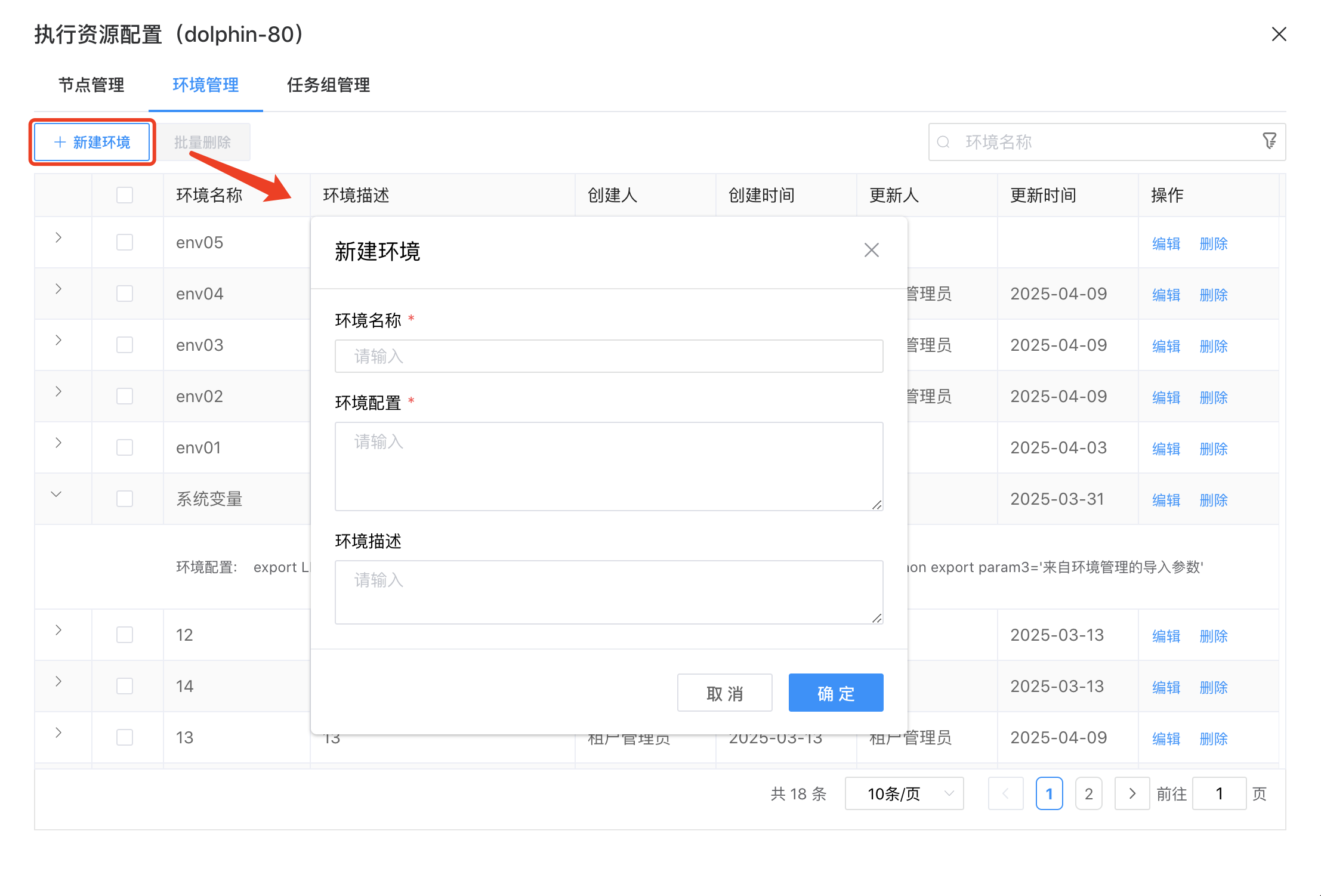
点击【编辑】,可以修改环境信息。
点击【删除】,可以删除已经配置好的环境。
| 配置项名称 | 说明 |
|---|---|
| 环境名称 | 自定义名称,如 hive_env、spark_313_env。 |
| 环境配置 | 核心内容。以export KEY=VALUE 格式写入。 示例:export JAVA_HOME=/usr/lib/jvm/java-8-openjdk export HIVE_HOME=/opt/soft/hive export PATH=$HIVE_HOME/bin:$PATH |
| 环境描述 | 文字说明该环境的用途。 |
# 环境典型应用场景
场景1:同一套集群同时跑Hive和Spark任务
- 创建环境 hive_env → 绑定Worker组 default → 配置HIVE_HOME和HADOOP_HOME。
- 创建环境 spark_env → 绑定Worker组 default → 配置SPARK_HOME和HADOOP_CONF_DIR。
- 结果:Hive任务选hive_env,Spark任务选spark_env,互不干扰,无需重启服务。
场景2:多版本引擎共存(如Hive 1.x和Hive 3.x)
- 为不同版本的Hive安装路径分别创建环境,分配给不同的Worker节点组(或相同组)。
- 任务根据依赖的Hive版本选择对应的环境。
# 任务组管理
任务组用于控制任务实例并发数的轻量级流量管控工具。
它不同于Worker分组(负载均衡),也不同于Yarn队列(计算资源管控),其核心价值是防止瞬时并发任务压垮下游系统(数据库、Hadoop等)。
针对不同项目,可以配置对应的任务组,并配置任务在任务组内运行的优先级。
# 任务组的定义与定位
核心作用:限制同一时刻属于该组的任务实例数量,保护下游系统不被突增流量打崩。
适用范围:仅对Worker执行的任务生效(Shell、SQL、Python、Flink、Spark等)。Master执行的逻辑节点(Switch、Condition、SubProcess等)不受任务组控制。
隔离级别:项目级隔离。任务组可绑定指定项目,也可全局可见;与租户无关。
# 操作入口
选择“任务组管理”,进入任务组管理界面。
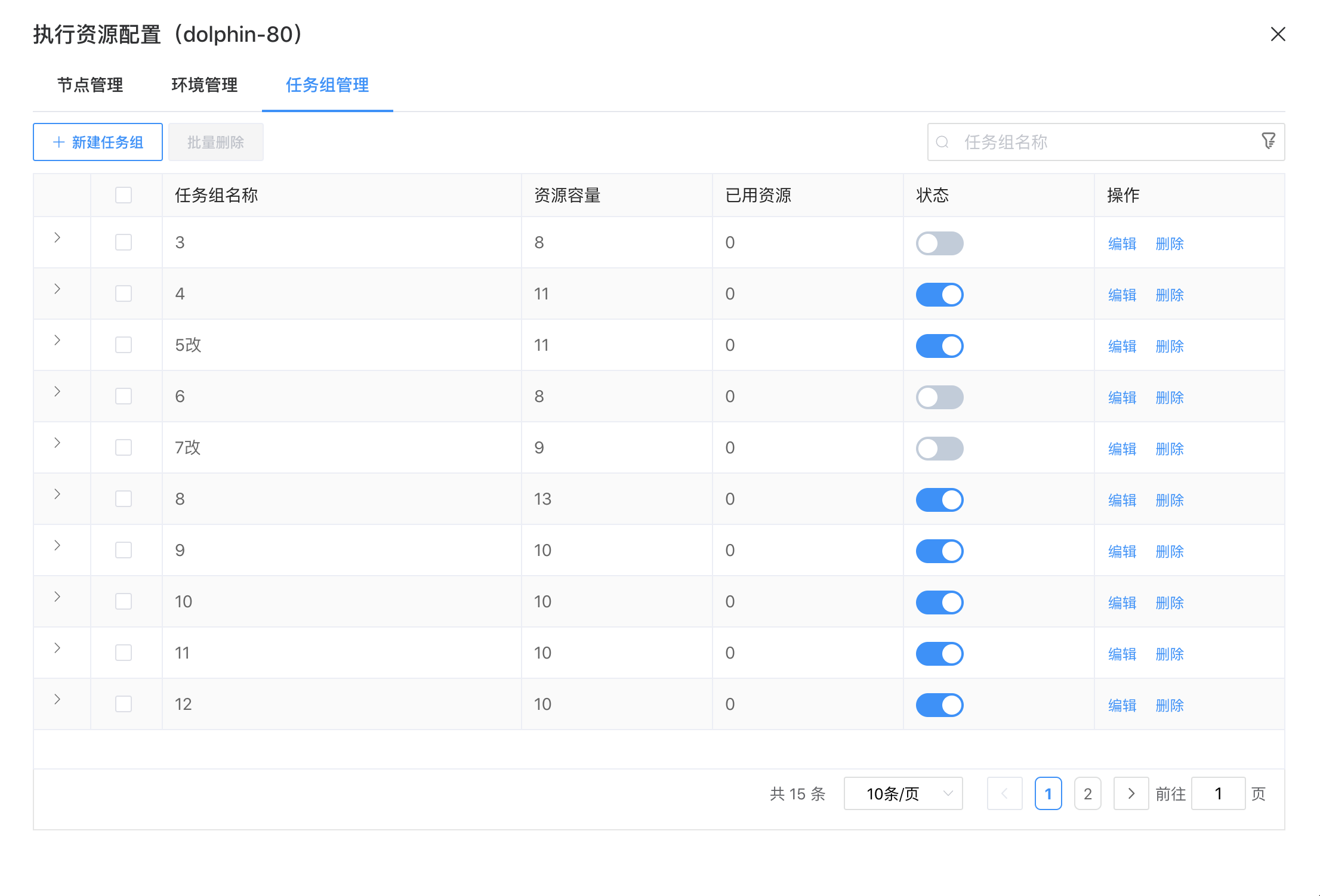
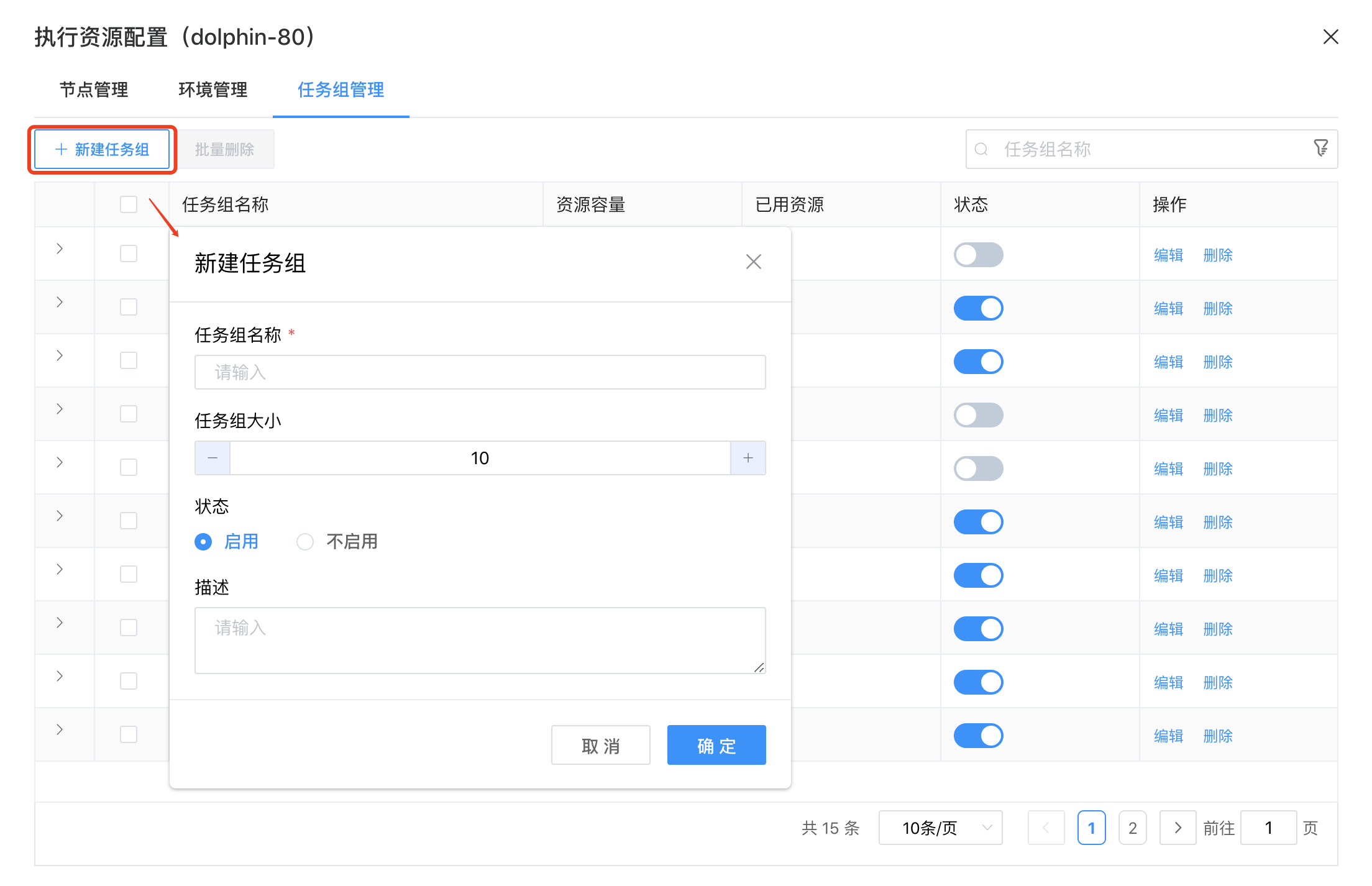
点击【新建任务组】按钮,填入任务组名称、任务组大小()、启用/不启用、描述,即可新建任务组。
点击【编辑】,可以修改任务组。
点击【删除】,可以删除已经创建的任务组。
| 配置项名称 | 说明 | 建议 |
|---|---|---|
| 任务组名称 | 显示名称,任务定义时选择 | 语义化命名,如 limit_hadoop_10 |
| 任务组大小 | 最大并发数 | 根据下游系统吞吐量设定。默认10,生产环境需评估。 |
| 状态 | 是否启用任务组 | |
| 描述 | 文字说明该任务组的用途。 |
# 任务组最佳实践建议
多拆分,少复用
不要把几百个任务放到同一个任务组。一旦阻塞,运维界面无法批量操作,恢复成本极高。推荐按业务线、数据源、重要程度拆分多个组。
容量设定原则
初始值建议设为下游系统(如Hadoop队列、数据库连接池)阈值的70% ,留缓冲。后期通过监控任务组等待时长动态调整。
监控与告警
任务组队列长度持续>0 → 触发告警。这是下游系统“即将过载”的早期信号。
不受控节点提醒
再次强调:Switch、Condition、SubProcess等逻辑节点不受任务组限制。若工作流中有大量这类节点,任务组对总体并发控制效果有限。
# 执行资源状态
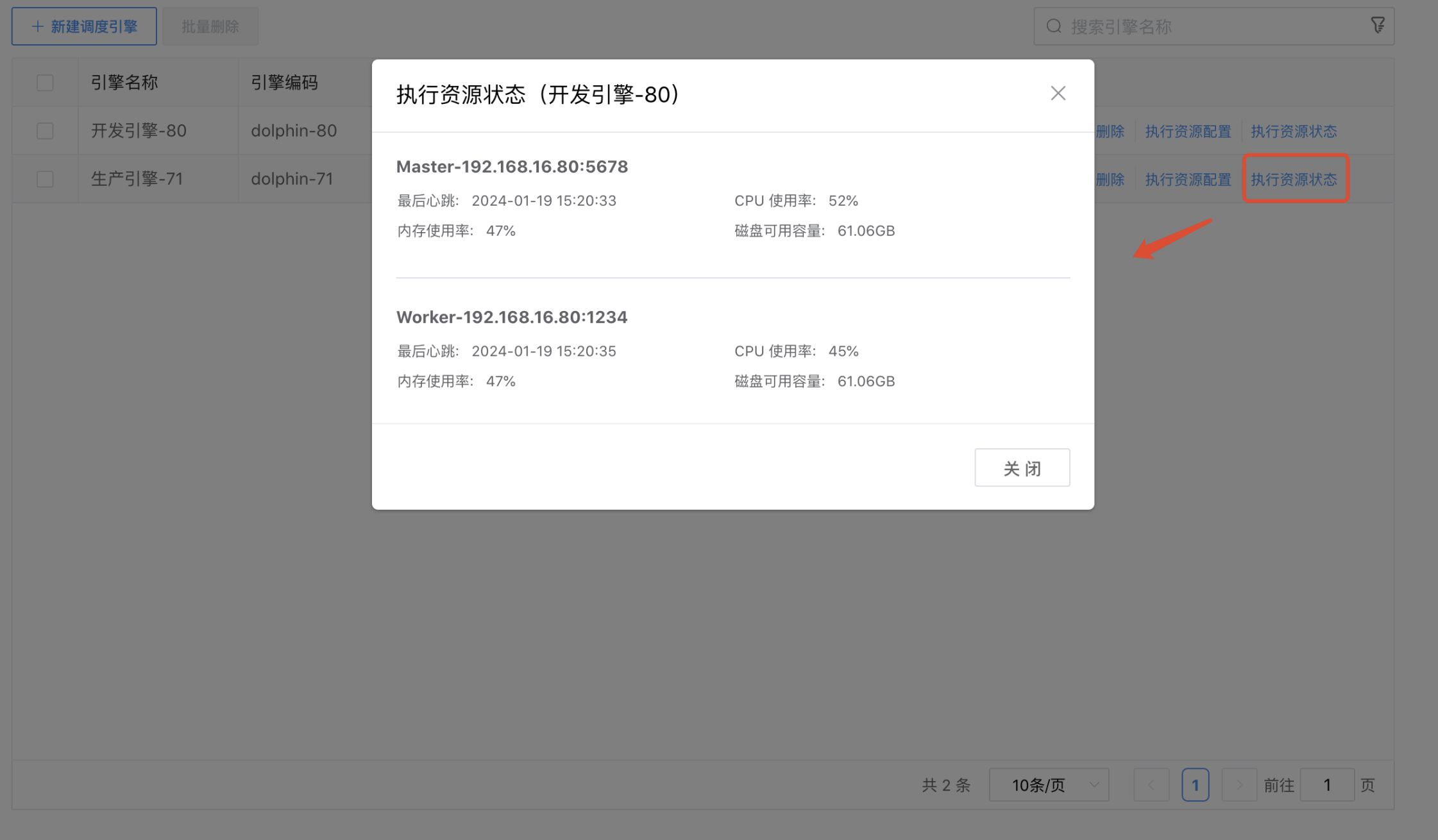
点击调度引擎列表后边的【执行资源状态】按钮,弹出"执行资源状态"弹窗。可以查看对应调度引擎的 Master 和 Worker 的资源状态,包括:Master 和 Worker 的节点地址、心跳、CPU 使用率、内存使用率、磁盘可用容量。
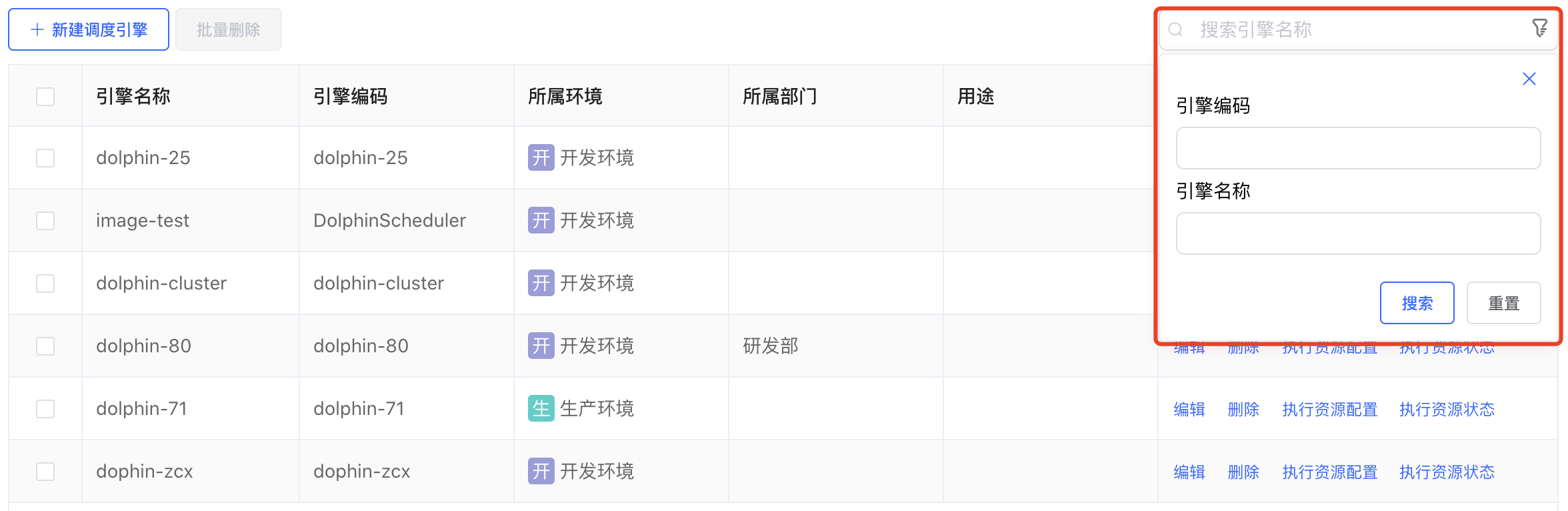
# 搜索
点击调度引擎列表右上方的【高级搜索】按钮,输入搜索条件"引擎编码"或者"引擎名称",点击【搜索】按钮,可以按照条件完成模糊查询,点击【重置】按钮,可以清空搜索条件。