
# 流查询示例
本示例主要介绍 流查询 的使用方法。
该场景Mysql中存入订单数据,文件中存入订单快递数据,先读取Mysql数据和文件,通过流查询组件将对应的快递数据添加到Mysql的数据后面,最后输出到文本文件中。主要步骤如下:
- 准备数据
- 新建批量作业
- 画布中拖入关系型数据库输入图元、文本文件输入图元、流查询图元、文本文件输出图元
- 配置"关系型数据库输入"组件属性
- 配置"文本文件输入"组件属性
- 配置"流查询"组件属性
- 配置"文本文件输出"组件属性
- 通用配置
- 保存草稿
- 运行
- 提交版本
# 准备数据
在Mysql上执行创建订单主表orders_info并插入数据:
-- 订单主表
CREATE TABLE `orders_info` (
`order_id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '订单ID',
`order_no` VARCHAR(32) NOT NULL COMMENT '订单编号',
`user_id` BIGINT(20) NOT NULL COMMENT '用户ID',
`user_name` VARCHAR(50) NOT NULL COMMENT '用户名',
`total_amount` DECIMAL(10,2) NOT NULL COMMENT '订单总金额',
`order_status` TINYINT(4) NOT NULL DEFAULT 0 COMMENT '订单状态:0-待付款 1-已付款 2-已发货 3-已完成 4-已取消',
`pay_type` TINYINT(4) DEFAULT NULL COMMENT '支付方式:1-微信 2-支付宝 3-银行卡',
`pay_time` DATETIME DEFAULT NULL COMMENT '支付时间'
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单主表';
-- 插入订单主数据
INSERT INTO `orders_info` (`order_no`, `user_id`, `user_name`, `total_amount`, `order_status`, `pay_type`, `pay_time`) VALUES
('ORD202401010001', 1001, '张三', 299.00, 3, 1, '2024-01-01 10:30:00'),
('ORD202401010002', 1002, '李四', 1599.50, 2, 2, '2024-01-01 14:20:00'),
('ORD202401020001', 1003, '王五', 89.90, 1, 3, '2024-01-01 02:20:00'),
('ORD202401020002', 1001, '张三', 459.00, 3, 1, '2024-01-02 11:45:00'),
('ORD202401030001', 1004, '赵六', 2399.00, 0, 3, '2024-01-02 10:15:00');
在本地创建/home/DI/files/order_extend.csv并插入数据:
order_no,receiver_address,receiver_name,receiver_phone,remark,client_source,user_grade,company,delivery_man,tracking_no,invoice_title,invoice_type
ORD202401010001,北京市朝阳区XX街道XX号,张三,13800138001,请尽快发货,急用,APP,VIP,顺丰速运,王师傅,SF1234567890,张三个人,1
ORD202401010002,上海市浦东新区XX路XX号,李四,13800138002,,PC,NORMAL,中通快递,,ZTO9876543210,上海科技有限公司,2
ORD202401020001,广州市天河区XX路XX号,王五,13800138003,放在快递柜,小程序,,,,,,
ORD202401020002,北京市朝阳区XX街道XX号,张三,13800138001,,APP,VIP,京东快递,,JD5555555555,,1
ORD202401030001,深圳市南山区XX科技园XX栋,赵六,13800138004,企业采购,需要合同,PC,ENTERPRISE,,,,深圳科技有限公司,2
文件内容如下:

Mysql表orders_info中的order_no字段(订单编号)和order_extend.csv中的order_no进行关联。
# 新建批量作业
点击资源树节点上的【...】,选择弹出菜单【新建批量作业】。作业名称为:"StreamingLookup",选择作业类型:"转换"。
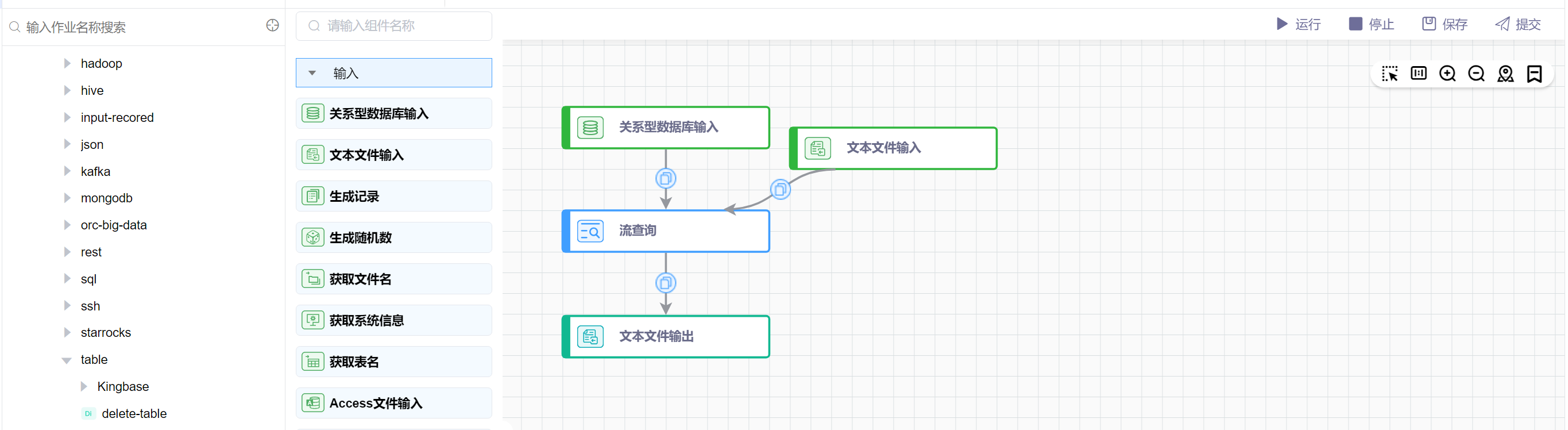
# 画布中拖入关系型数据库输入图元、文本文件输入图元、流查询图元、文本文件输出图元
依次拖拽输入中的关系型数据库输入组件和文本文件输入组件、查询中的流查询组件、输出中的文本文件输出组件,依次连线。如下图所示:
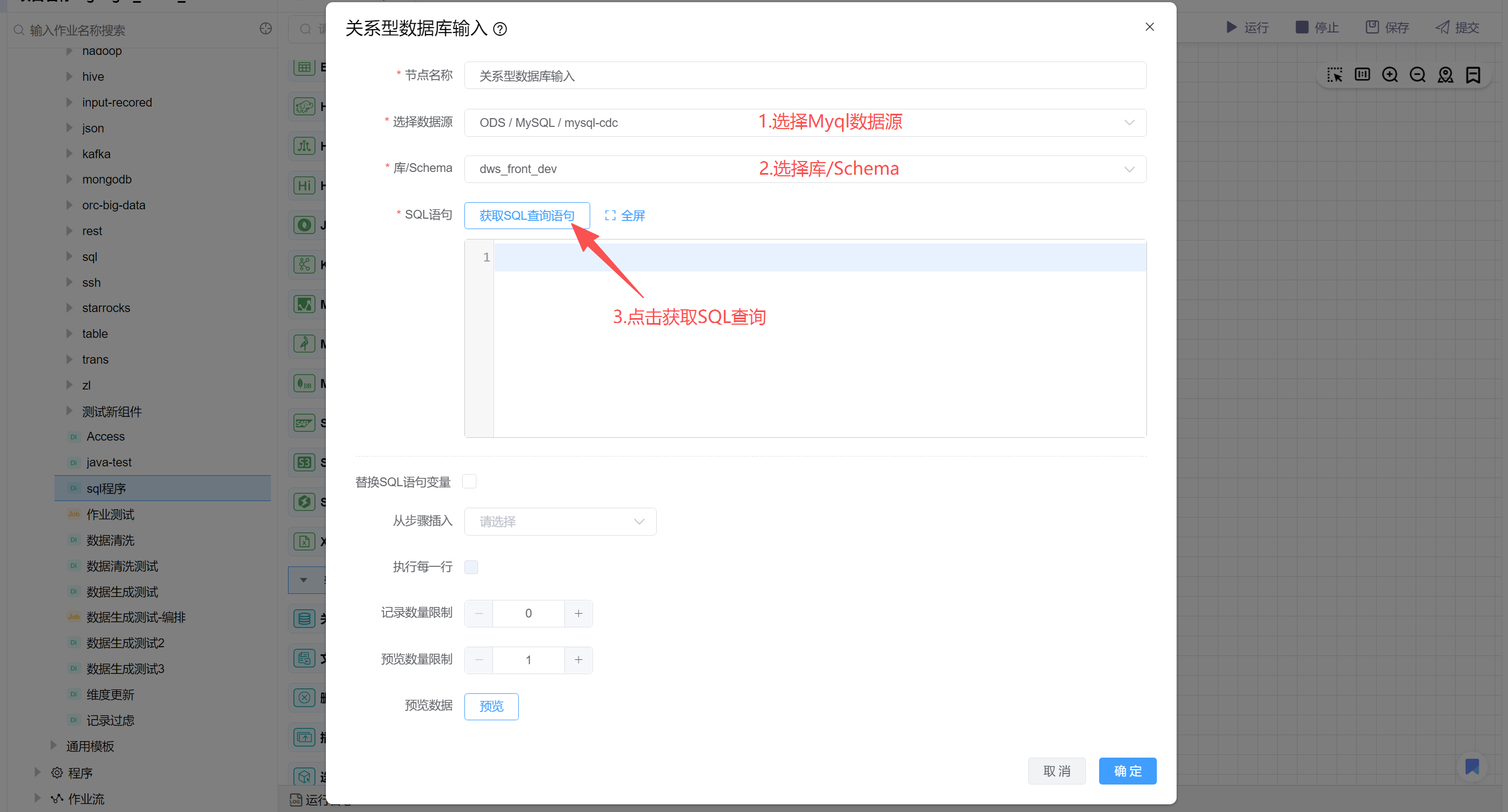
# 配置"关系型数据库输入"组件属性
选择Mysql数据源,然后选择刚才执行“订单主表”sql语句的数据库,最后点击获取SQL查询。
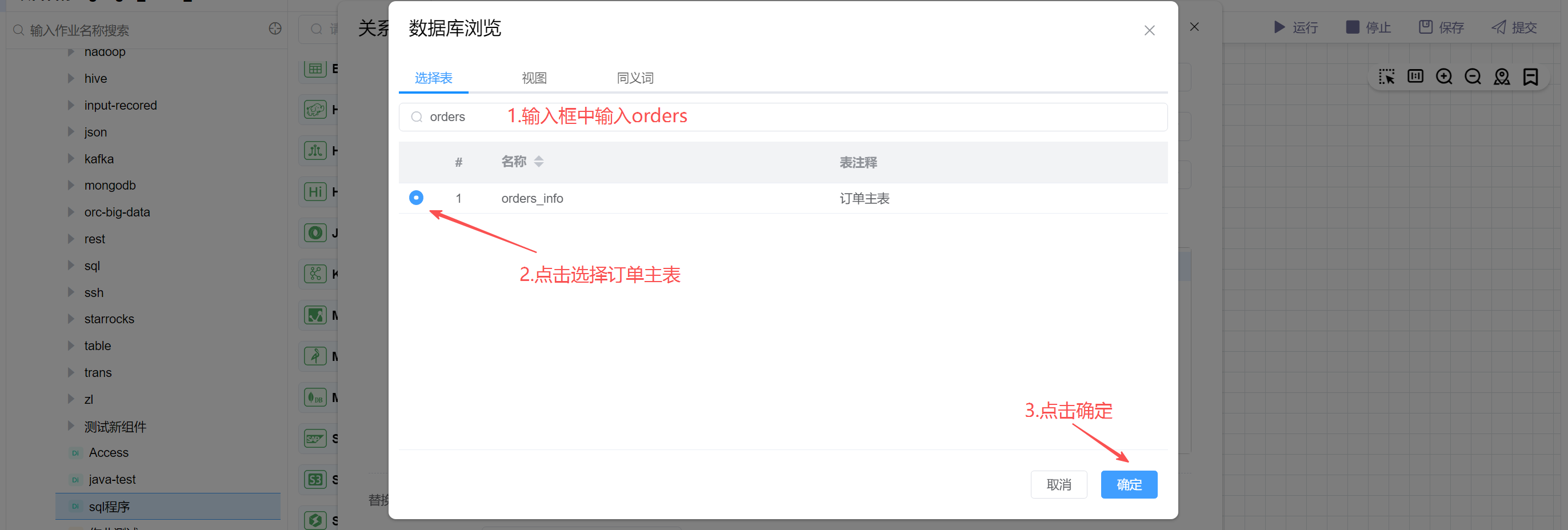
在数据库浏览中输入“orders”进行筛选,并选择订单主表,最后点击确定。
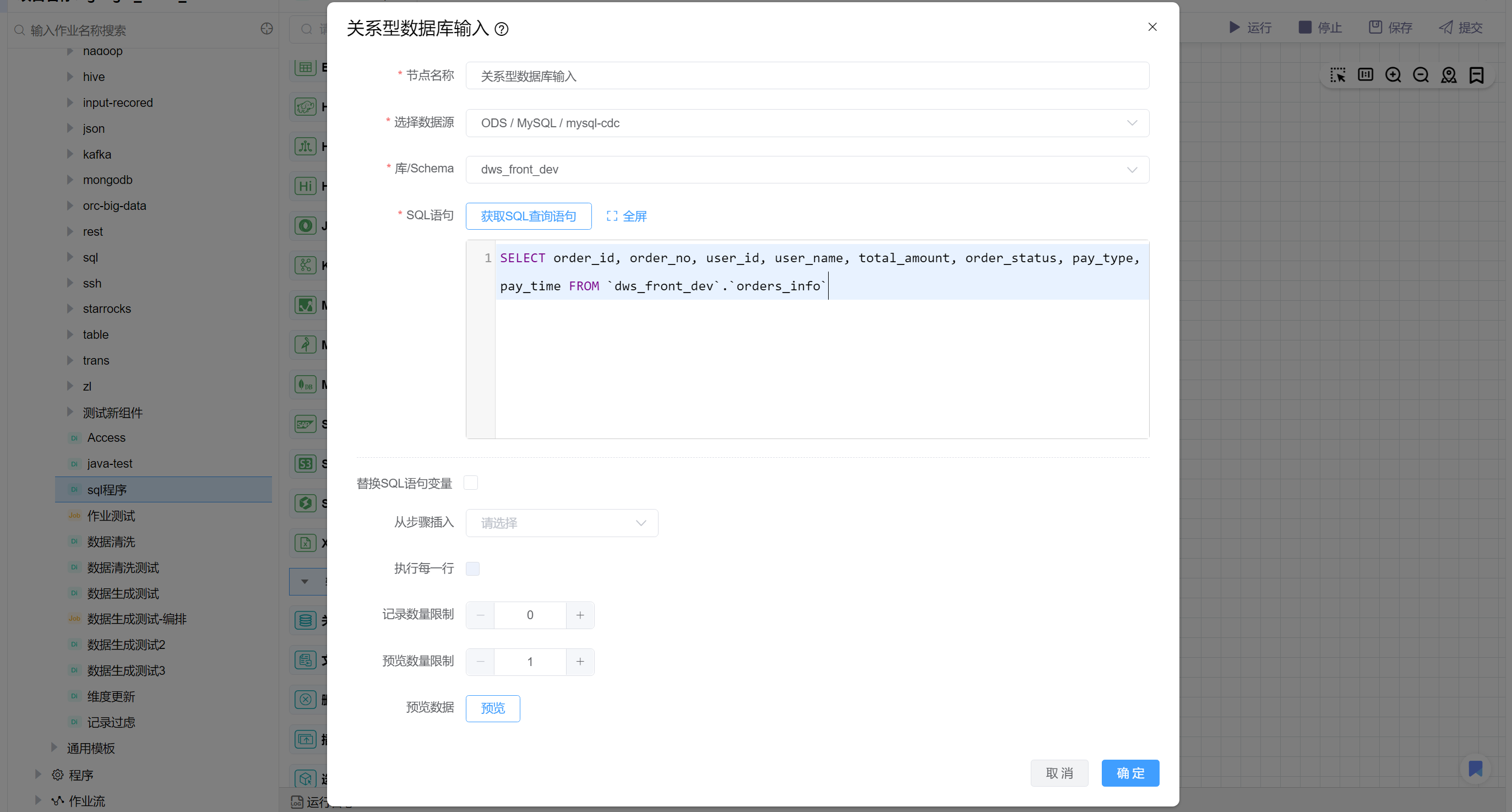
关系型数据库输入最终配置如下:
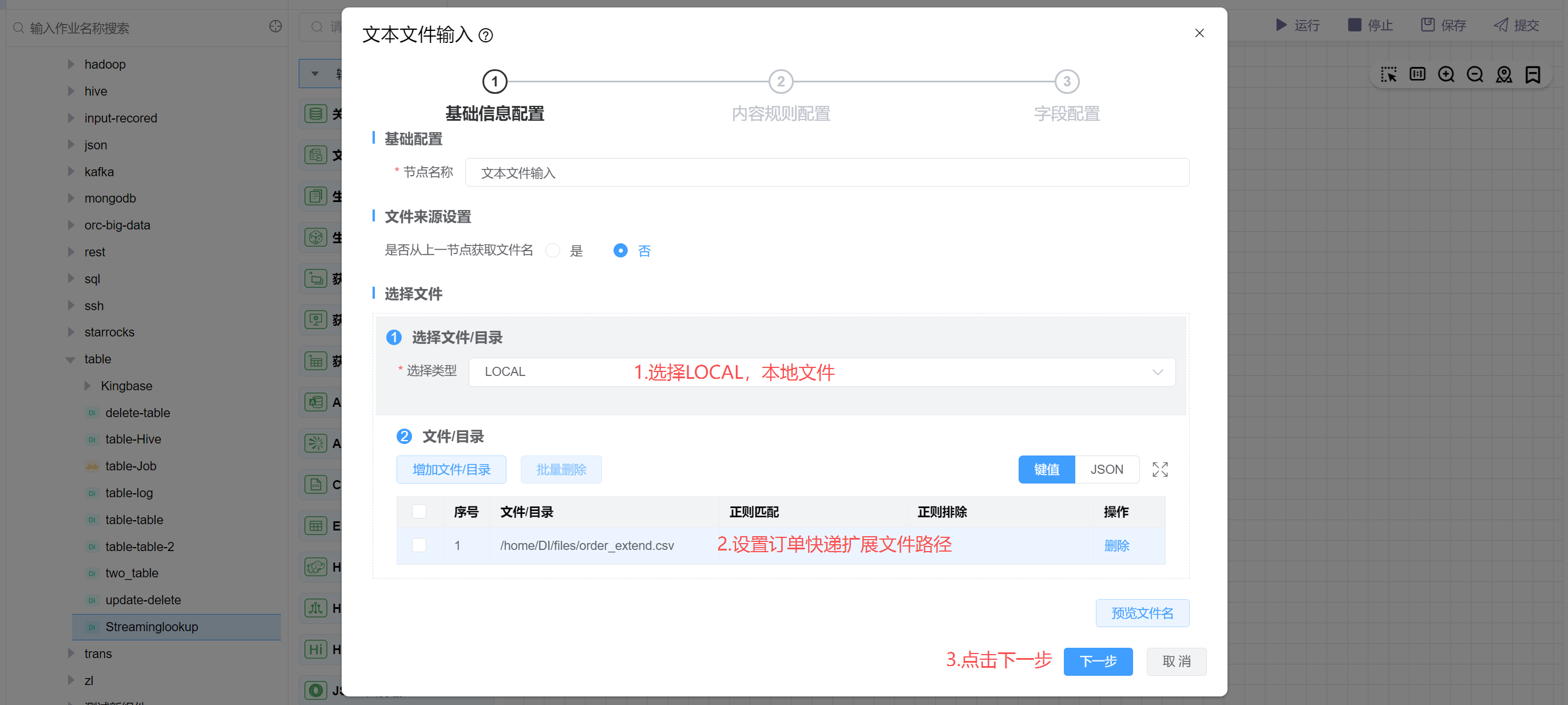
# 配置"文本文件输入"组件属性
选择文本文件数据源,并填写文件路径为:/home/DI/files/order_extend.csv。
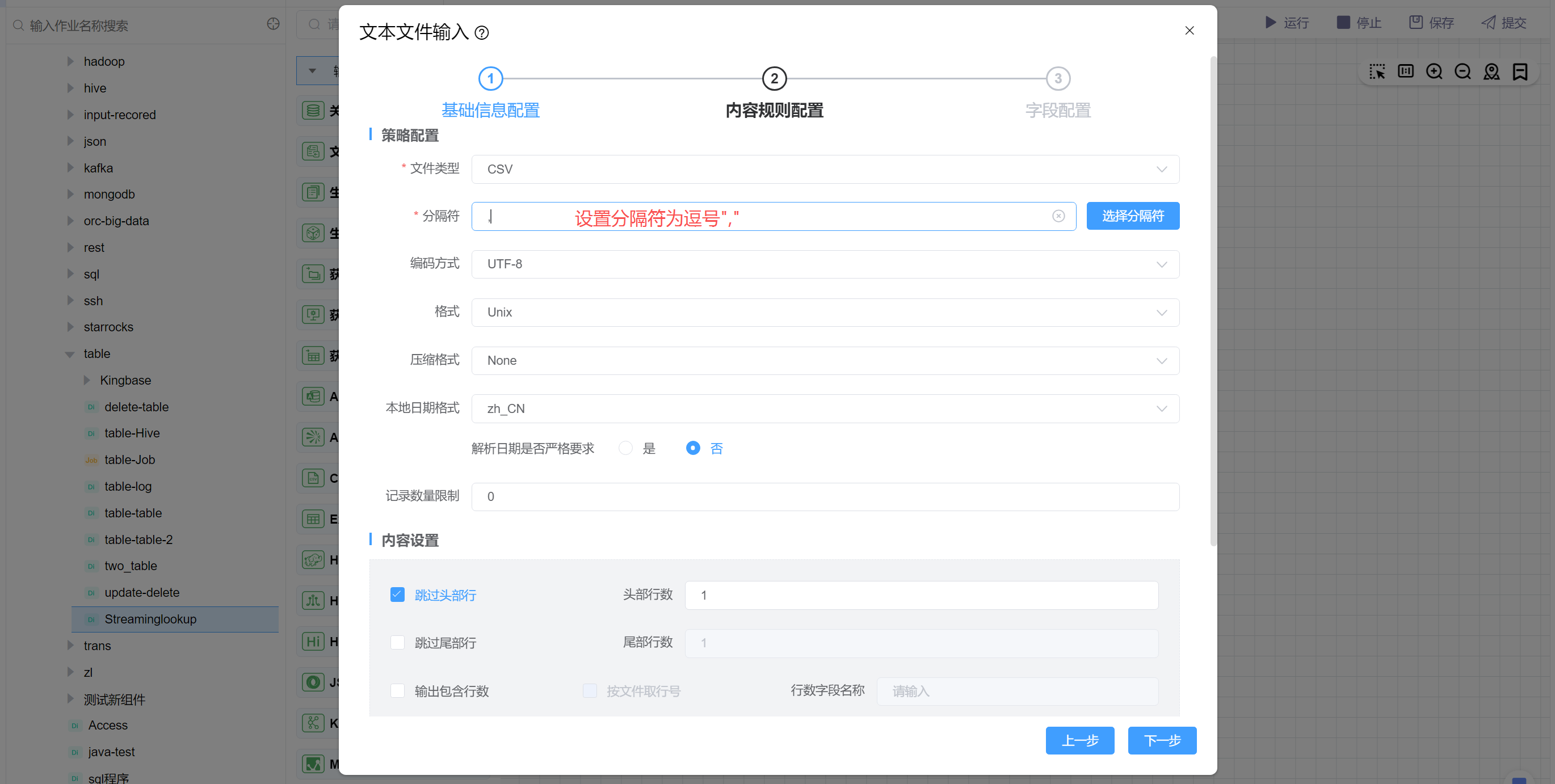
设置文件格式为CSV,分隔符为","。
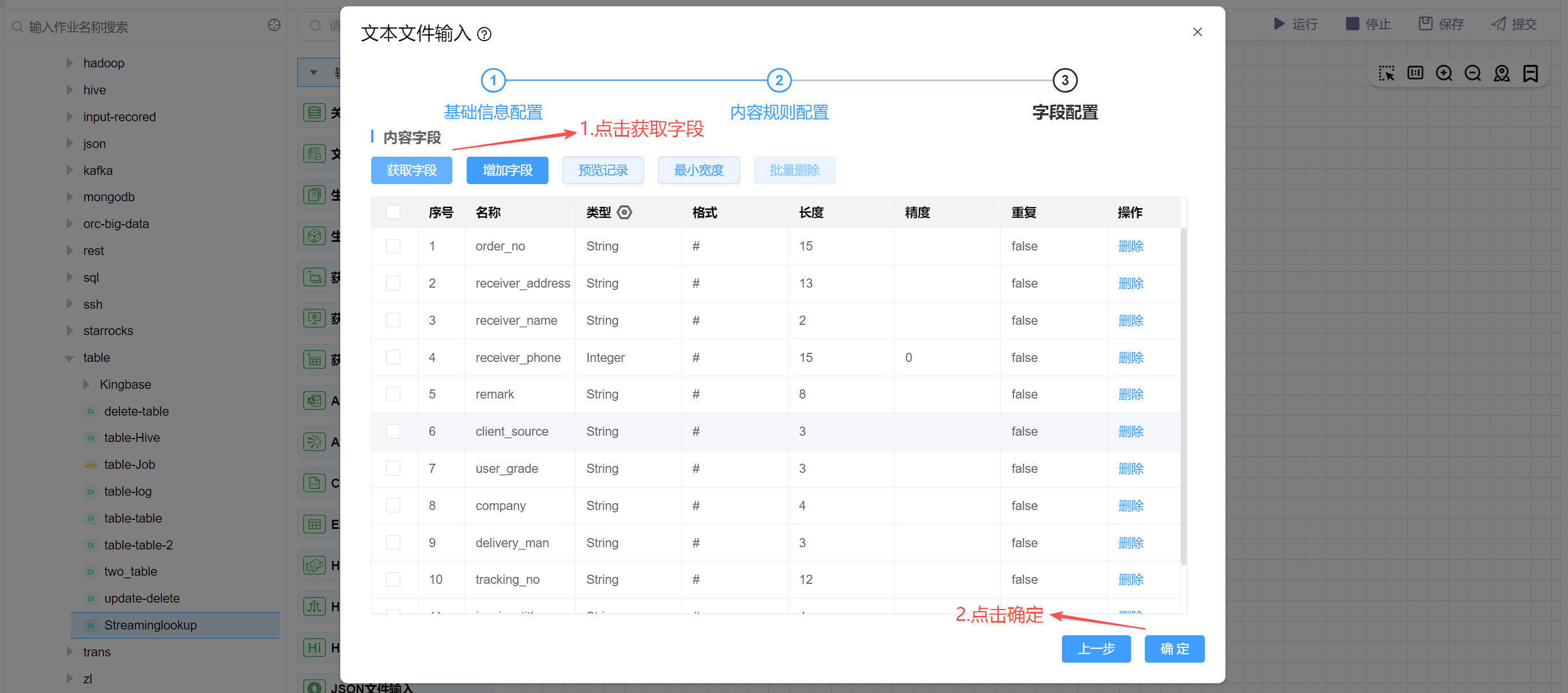
点击获取字段,并点击确定。
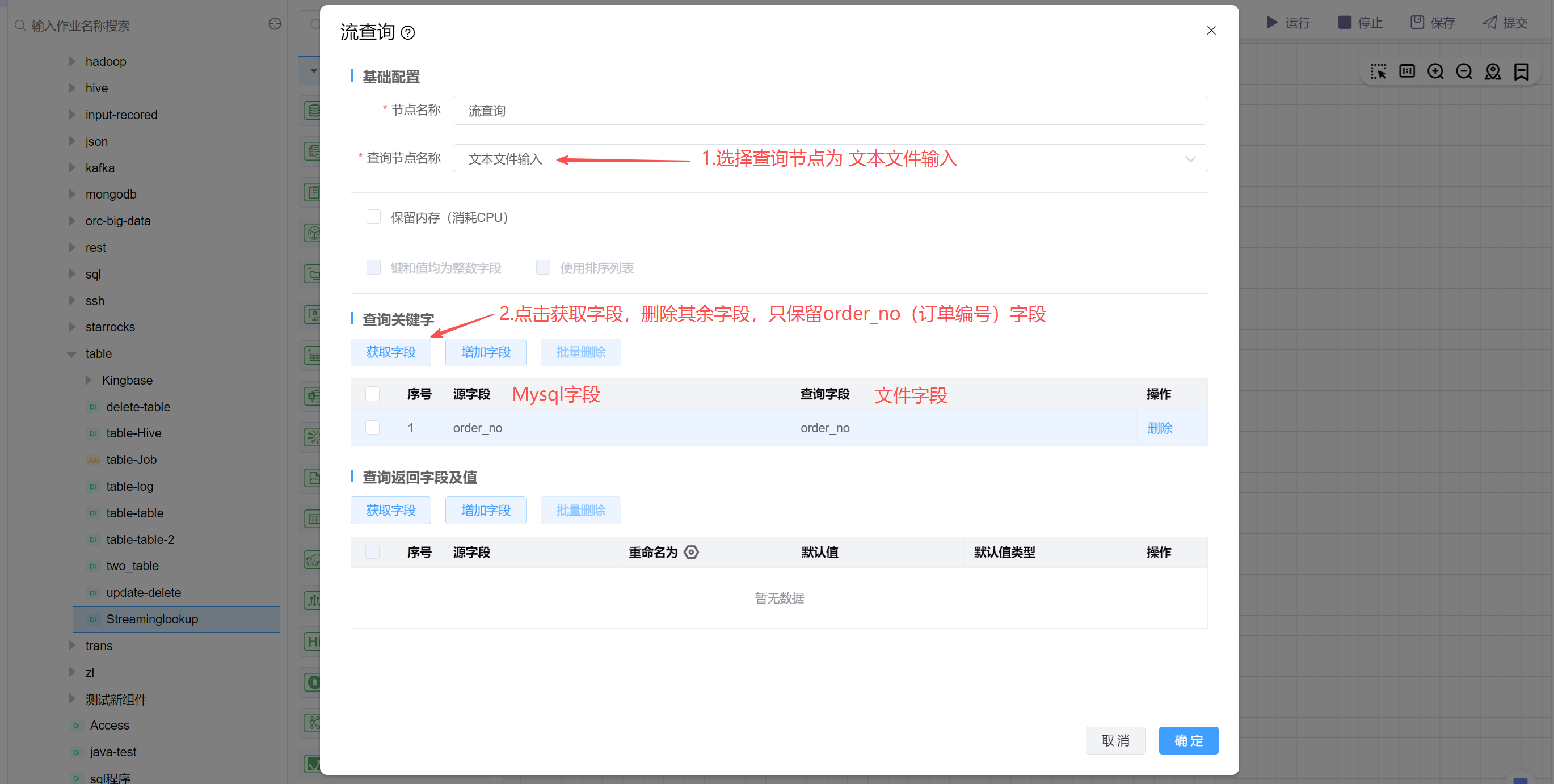
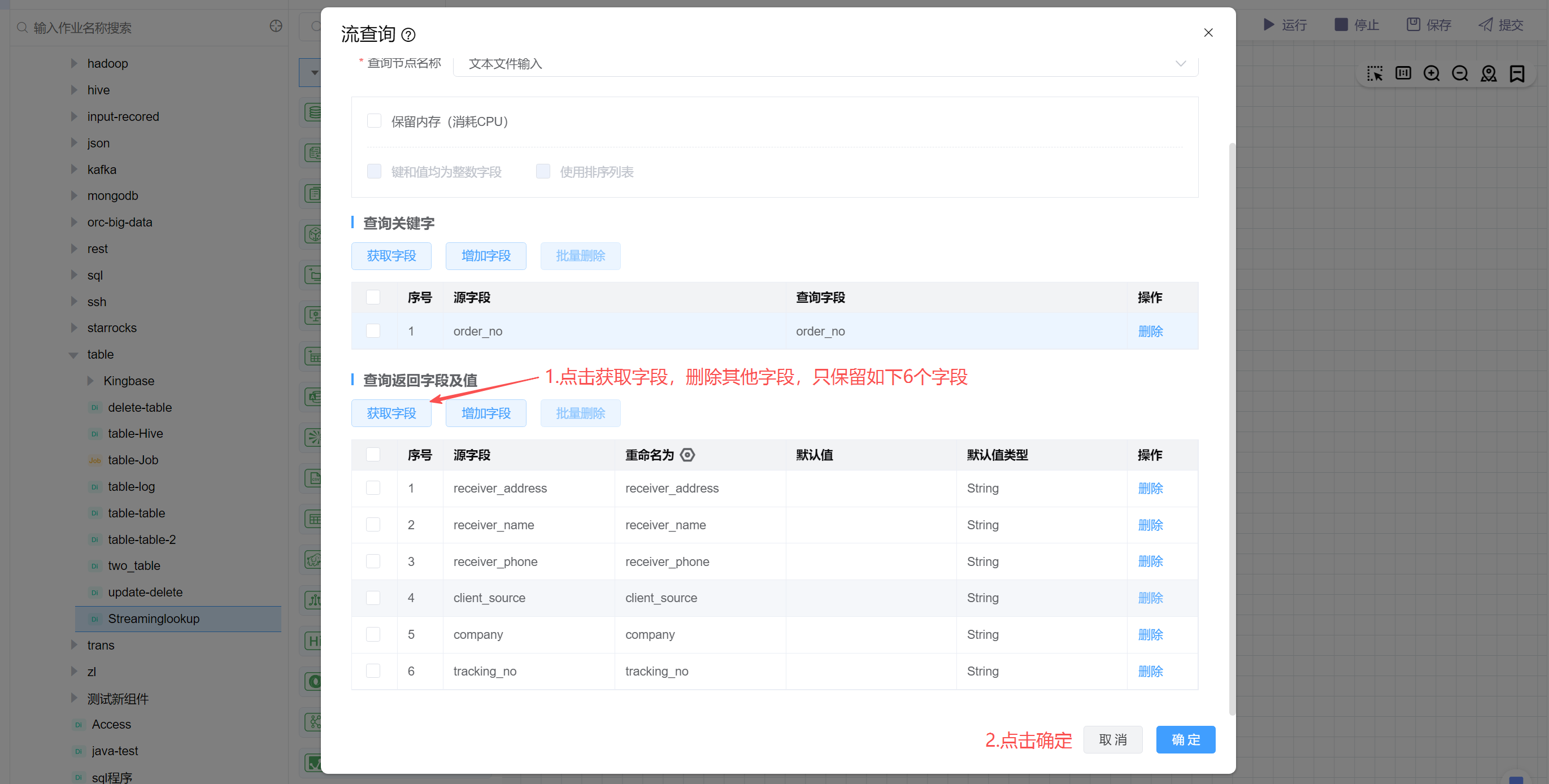
# 配置"流查询"组件属性
- 选择查询节点名称:该组件会将查询节点组件的数据缓存到内存中,当过来数据时去内存中查找数据,所以该节点选择“文本文件输入”。
- 查询关键字:点击获取字段,原字段是Mysql表中的字段,查询字段为文件中的字段,所以只保留 order_no订单编号字段进行关联即可。
- 查询返回字段及值:点击获取字段,获取通过查询需要返回的字段(文件中的字段),可以根据需要进行设置,本示例返回了6个字段。
设置查询关键字:
设置查询返回字段及值:
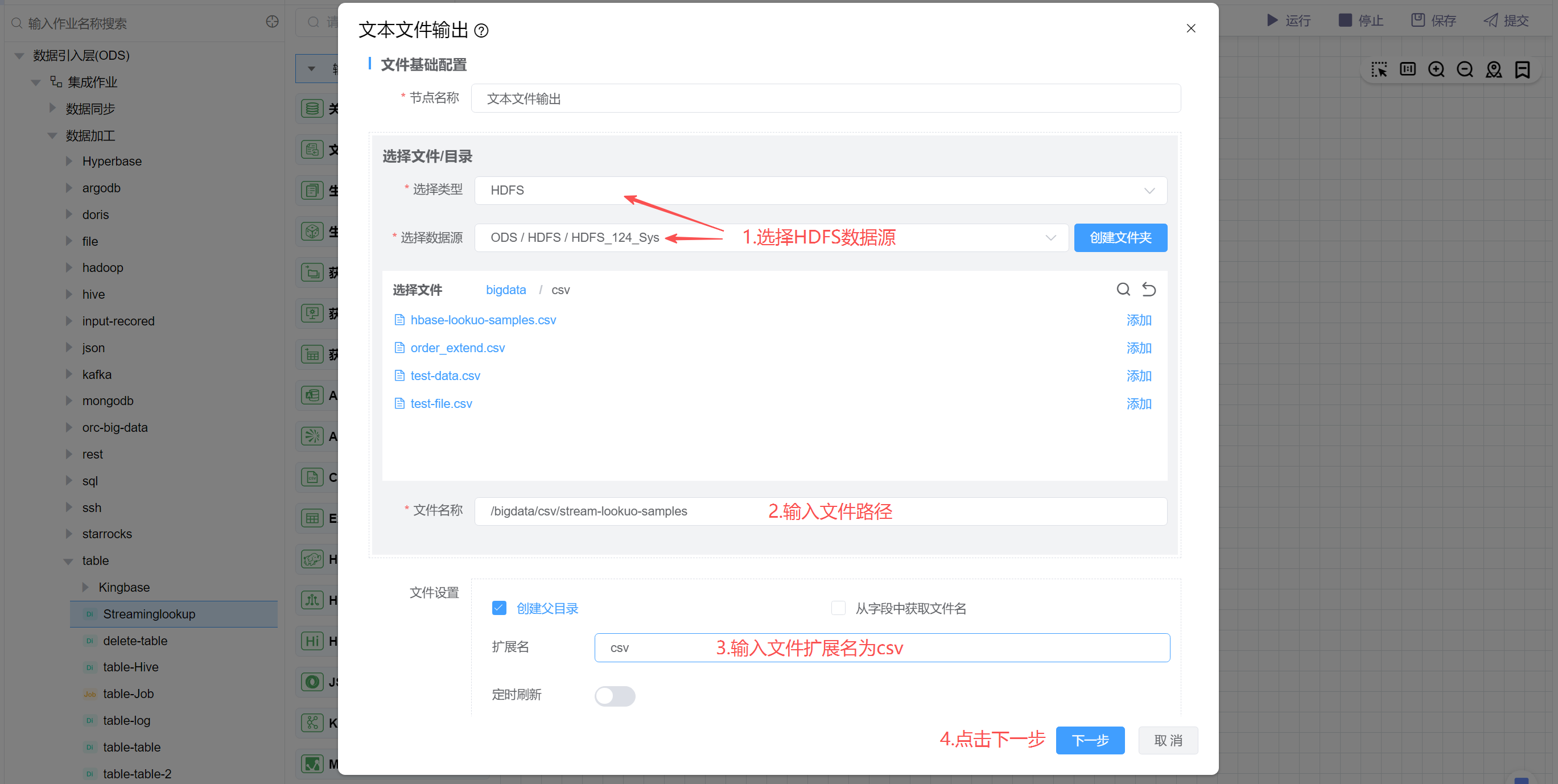
# 配置"文本文件输出"组件属性
选择HDFS数据源,输入文件路径为/bigdata/csv/stream-lookuo-samples,并设置扩展名为csv,最后点击下一步。
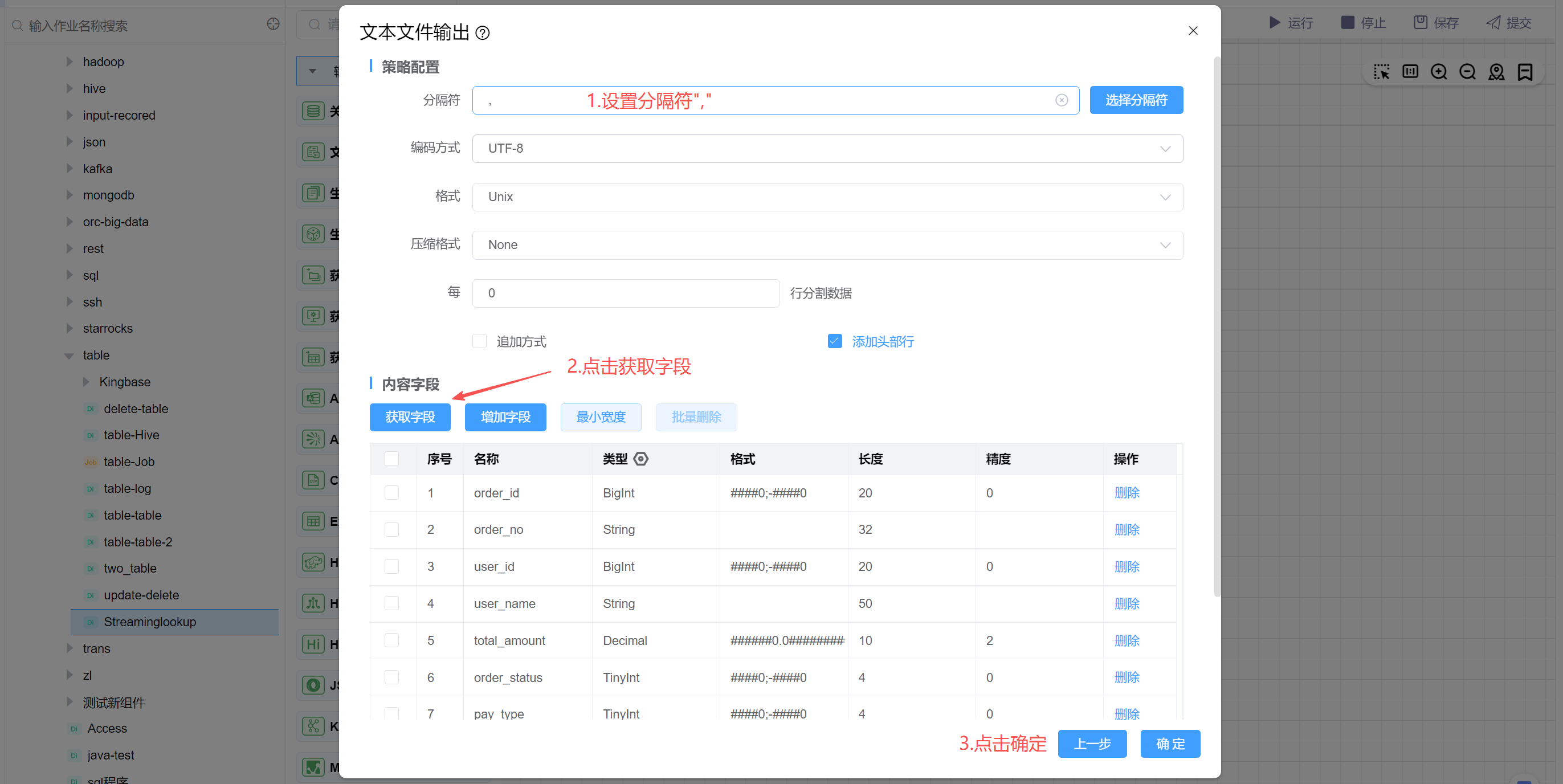
设置分隔符为逗号",",点击获取字段,字段中包含Mysql表字段和流查询返回字段。最后点击确定。
# 通用配置
在通用配置中可以配置任务优先级、Worker 分组、命名参数、本地参数、超时告警。
可以参考示例关系型表数据同步示例 中的"通用配置"说明。
# 保存草稿
如果所有组件属性都已设置完毕,点击【保存】按钮,可以看到保存过的历史草稿,并可以随意切换草稿。(草稿只保存最近 10 个)
可以参考示例关系型表数据同步示例 中的"保存草稿"说明。
# 运行
点击【运行】按钮,可以运行已经开发完毕的场景,在日志栏可以看运行日志及运行结果。
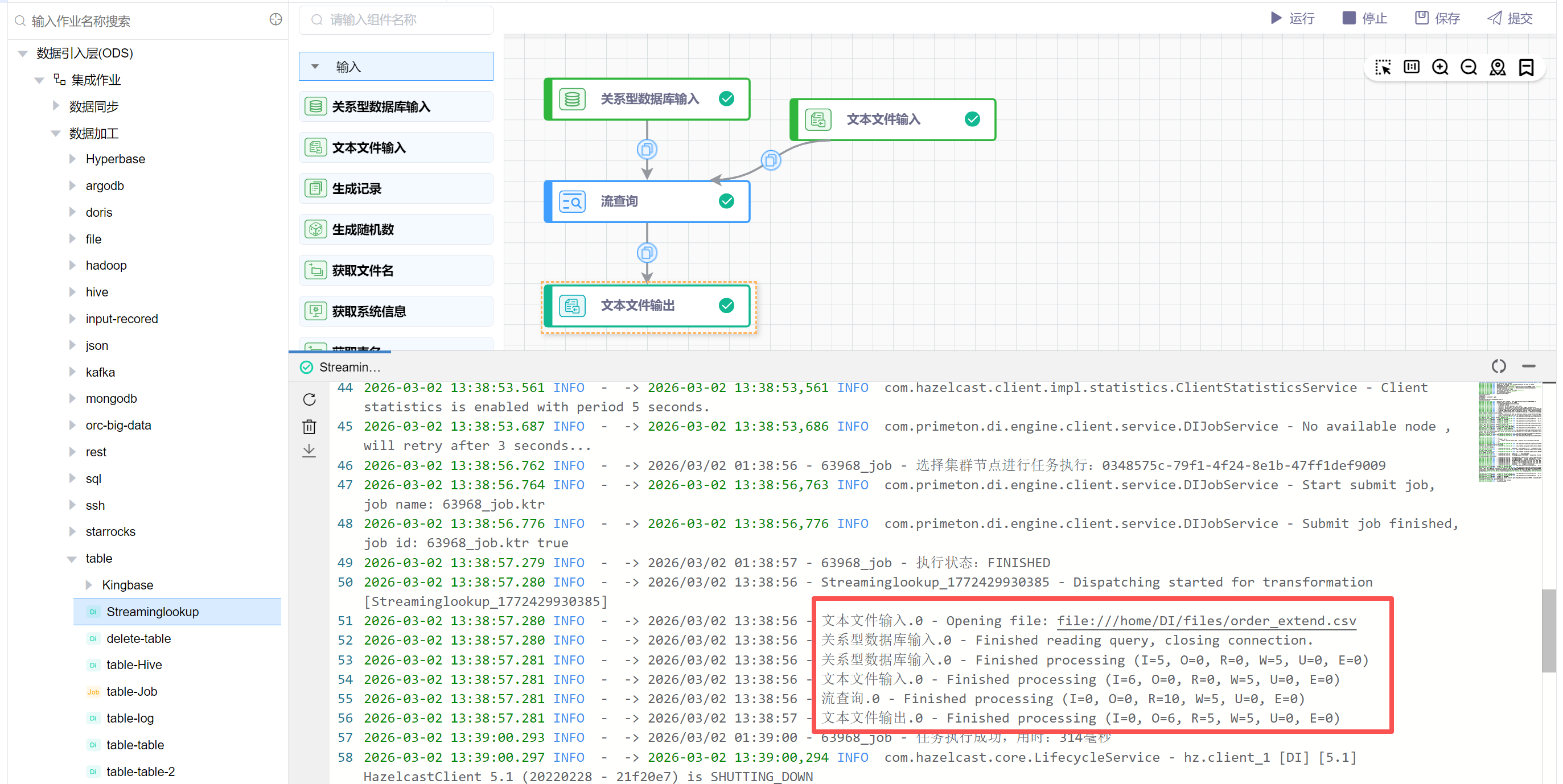
查看HDFS系统的/bigdata/csv/stream-lookuo-samples.csv文件,包含Mysql字段和流查询返回的字段。

# 提交版本
当草稿运行正常后,点击【提交】按钮可以将该版本提交到作业调度,每次修改提交都会生成新的版本,可以看到提交的历史版本,并可以随意切换版本。
提交后的版本,可以在作业调度中进行"定时"调度配置。
可以参考示例关系型表数据同步示例 中的"提交版本"说明。