
# HDFS文件输入-输入示例
本示例主要介绍 HDFS文件输入 和 HDFS文件输出的使用方法。
该场景读取HDFS某个目录下的文件,并写入到HDFS的其他目录中。在实际使用中'HDFS文件输出'可以根据需求换成'S3文件输出'、'Minio文件输出'等。 主要步骤如下:
# 准备文件
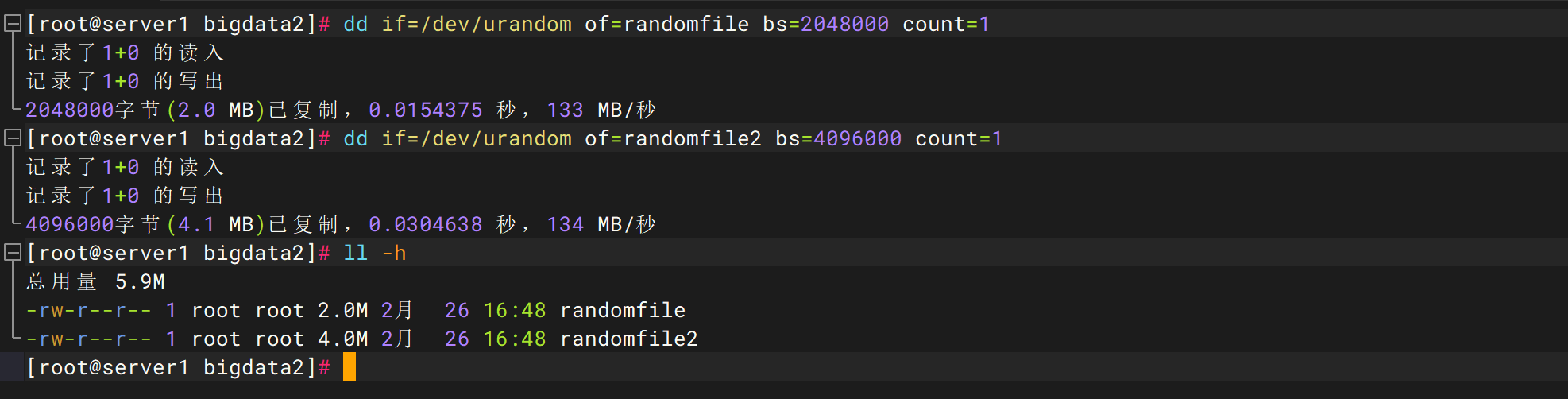
在linux环境上执行生成随机文件命令:
dd if=/dev/urandom of=randomfile bs=2048000 count=1
dd if=/dev/urandom of=randomfile2 bs=4096000 count=1
将randomfile、randomfile2文件上传到hdfs://cdh01:8020/bigdata/randomfile/下:
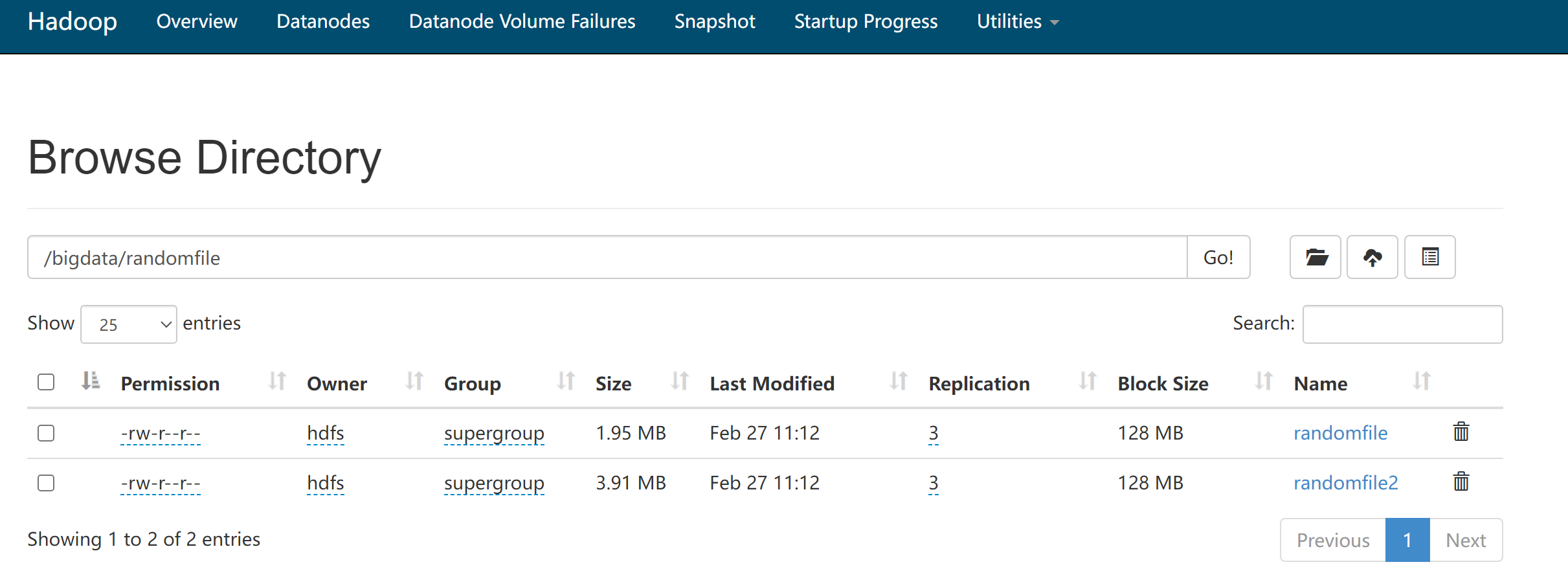
本案例通过linux命令生成随机文件,并上传到HDFS。也可以将已有文件上传到HDFS后进行后续操作。
# 新建批量作业
点击资源树节点上的【...】,选择弹出菜单【新建批量作业】。作业名称为:"HdfsFileTrans",选择作业类型:"转换"。
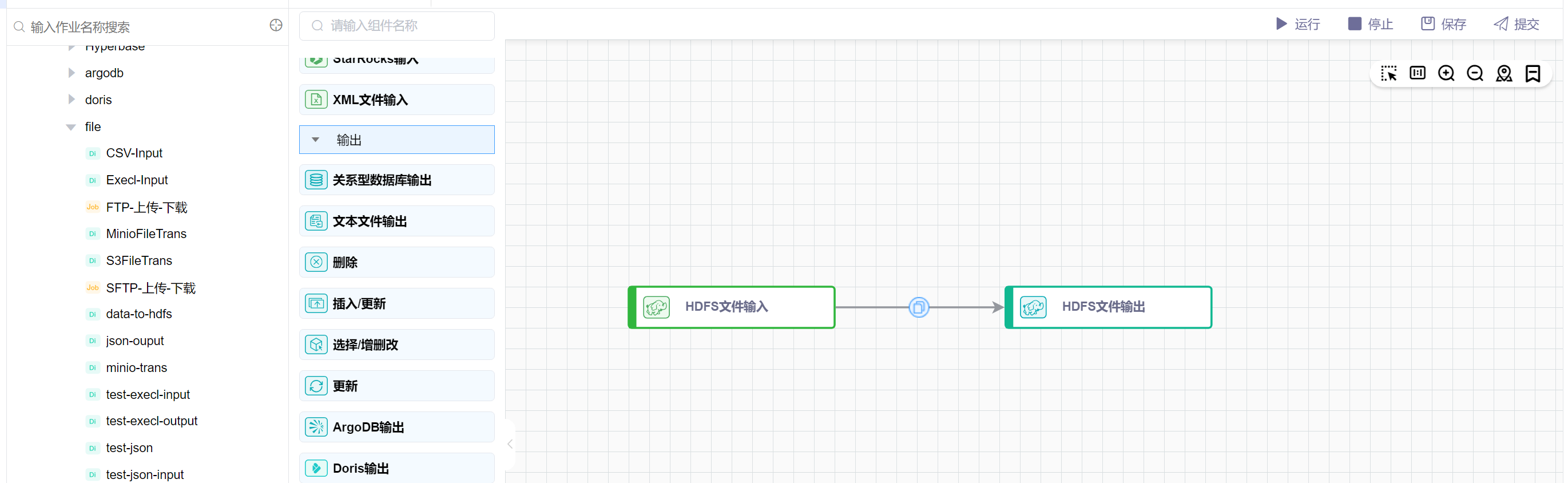
# 画布中拖入HDFS文件输入图元、HDFS文件输出图元
依次拖拽输入中的HDFS文件输入组件、输出中的HDFS文件输出组件,依次连线。如下图所示:
# 配置"HDFS文件输入"组件属性
点击“选择数据源”,选择HDFS数据源:
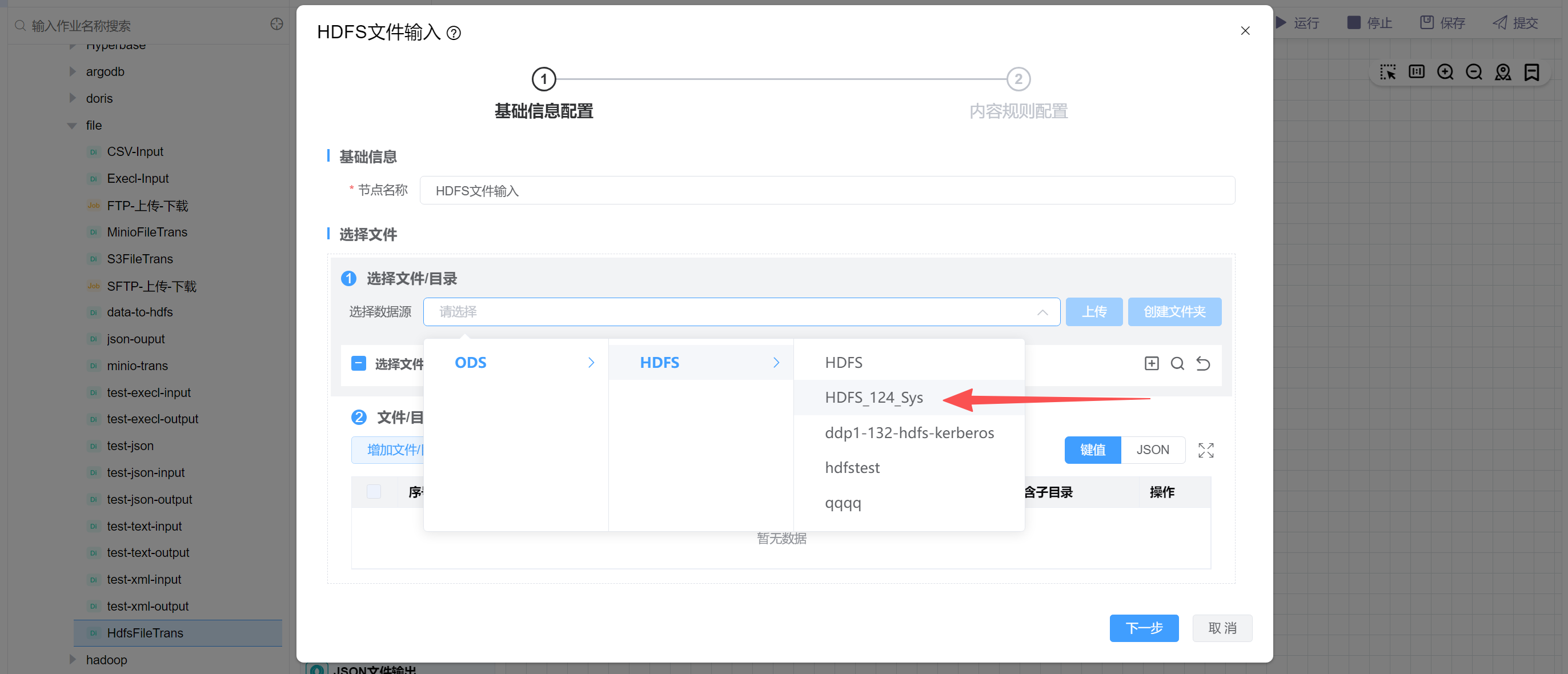
选择需要传输的文件,以randomfile、randomfile2为例:
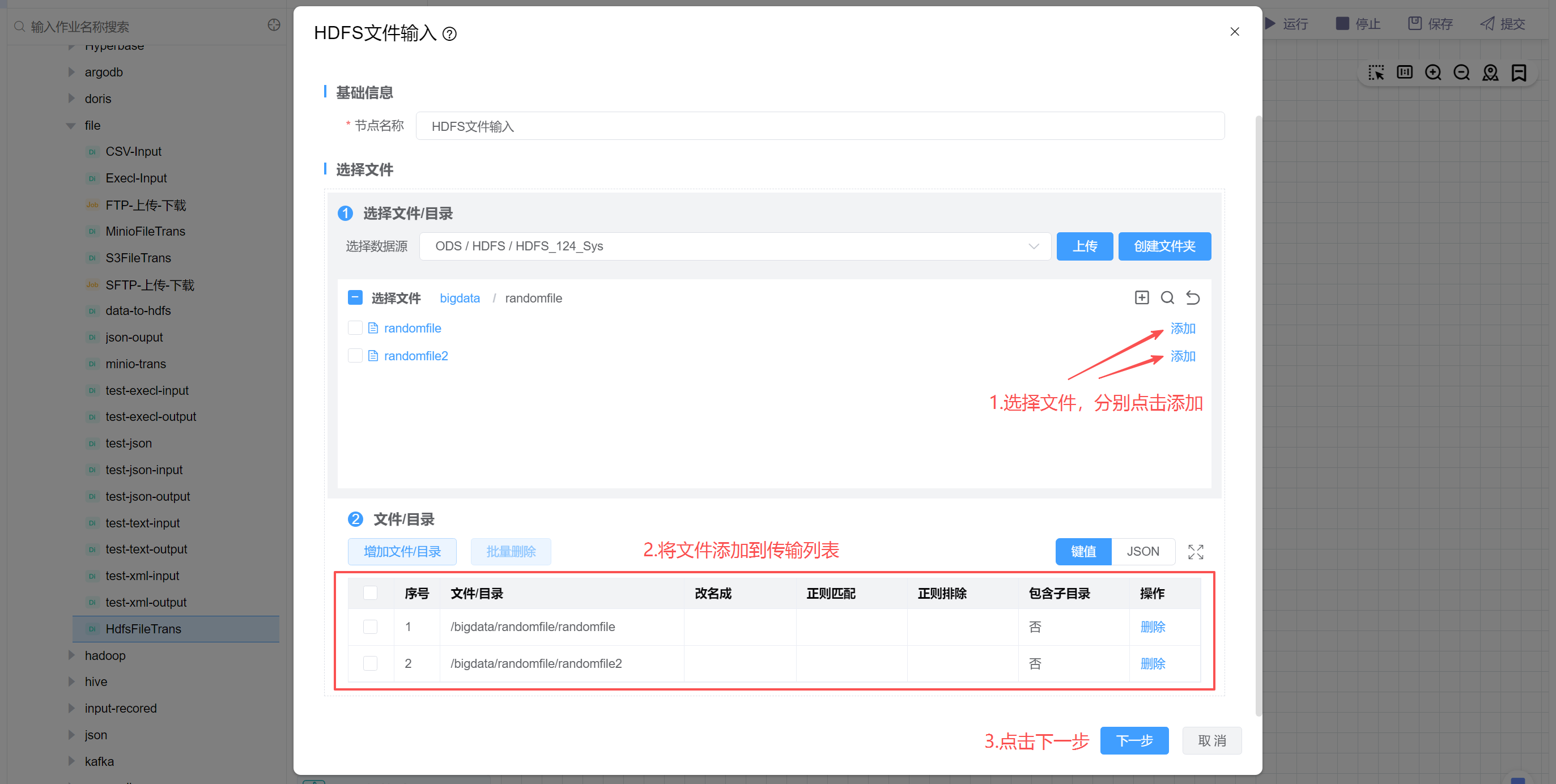
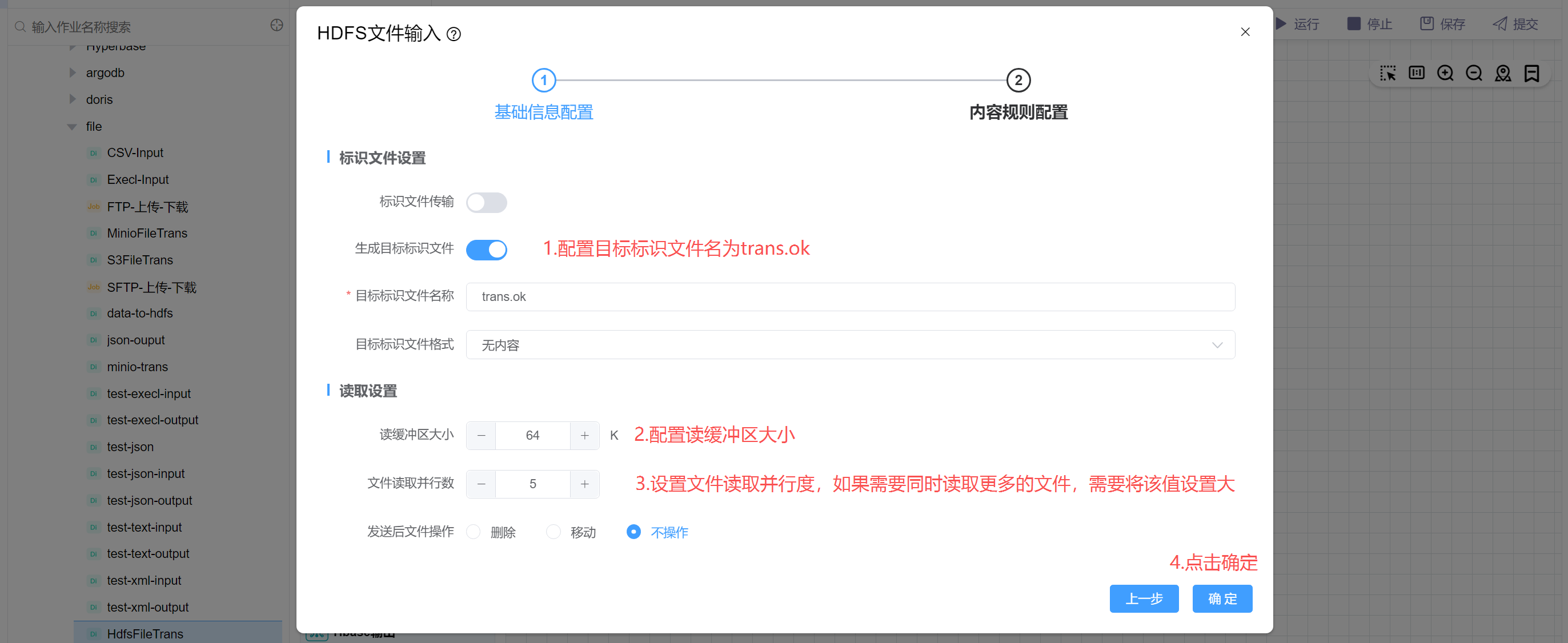
配置目标标识文件为trans.ok(传输完成后会在目录目录下生成一个trans.ok文件),配置读取缓冲区大小和读取并行度。然后点击确定。
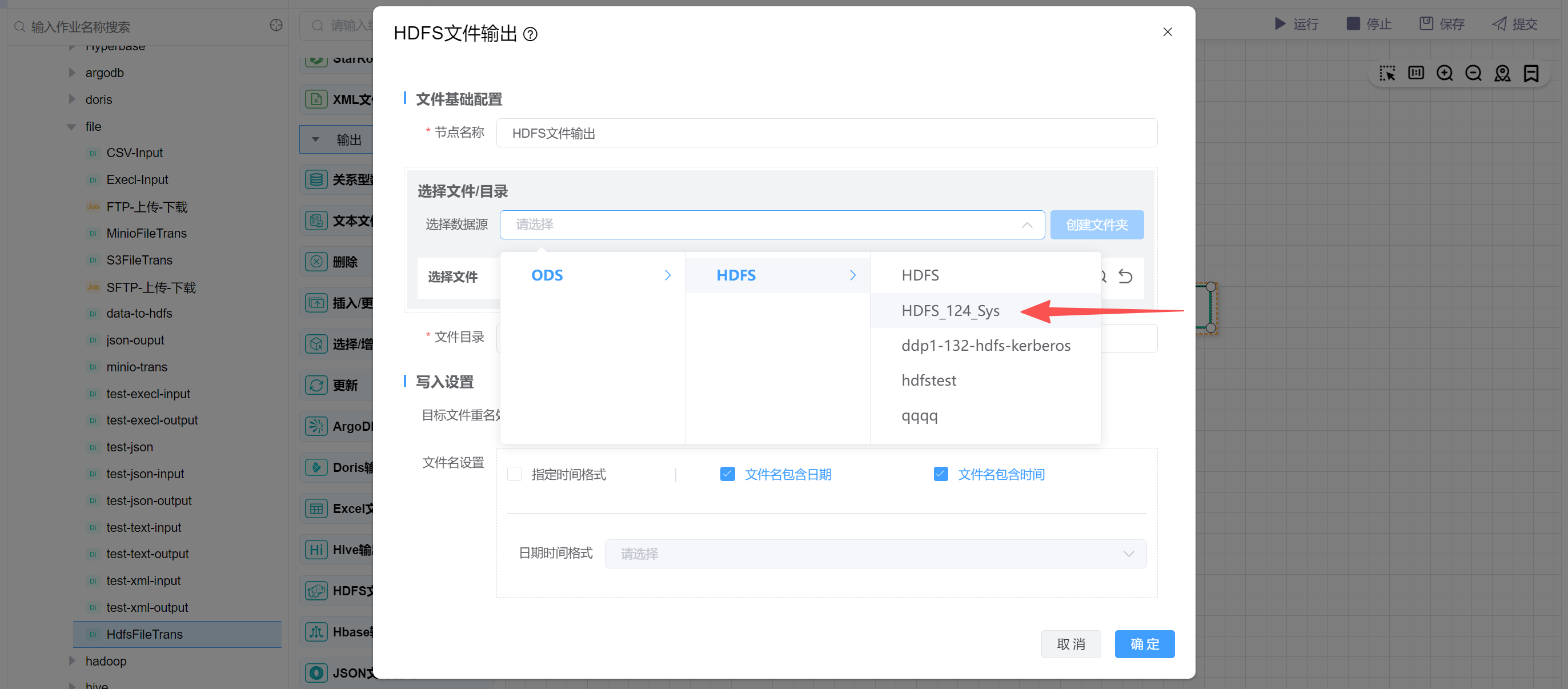
# 配置"HDFS文件输出"组件属性
点击“选择数据源”,选择HDFS数据源:
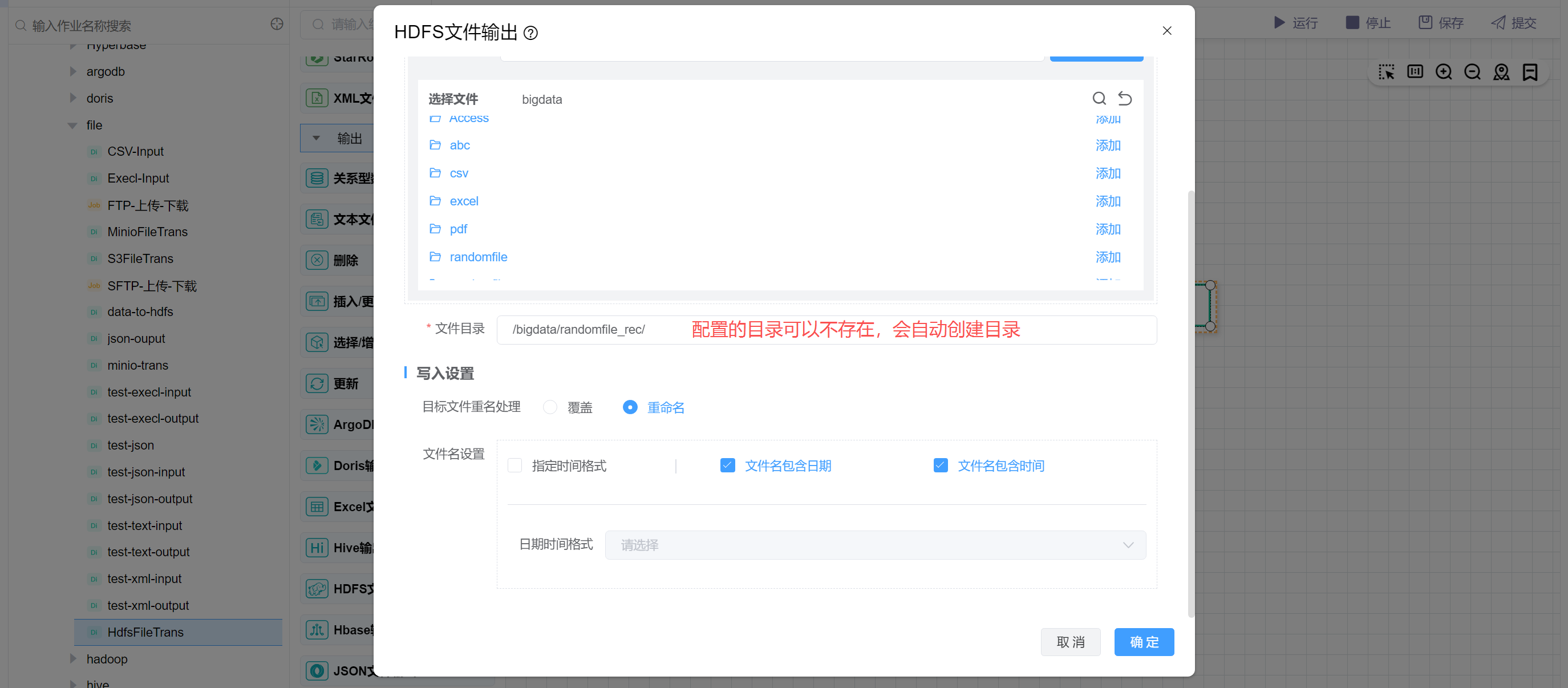
配置文件目录为/bigdata/randomfile_rec,设置文件重名处理为重命名,重命名后的文件包含日期和时间。然后点击确定。
# 通用配置
在通用配置中可以配置任务优先级、Worker 分组、命名参数、本地参数、超时告警。
可以参考示例关系型表数据同步示例 中的"通用配置"说明。
# 保存草稿
如果所有组件属性都已设置完毕,点击【保存】按钮,可以看到保存过的历史草稿,并可以随意切换草稿。(草稿只保存最近 10 个)
可以参考示例关系型表数据同步示例 中的"保存草稿"说明。
# 运行
点击【运行】按钮,可以运行已经开发完毕的场景,在日志栏可以看运行日志及运行结果。
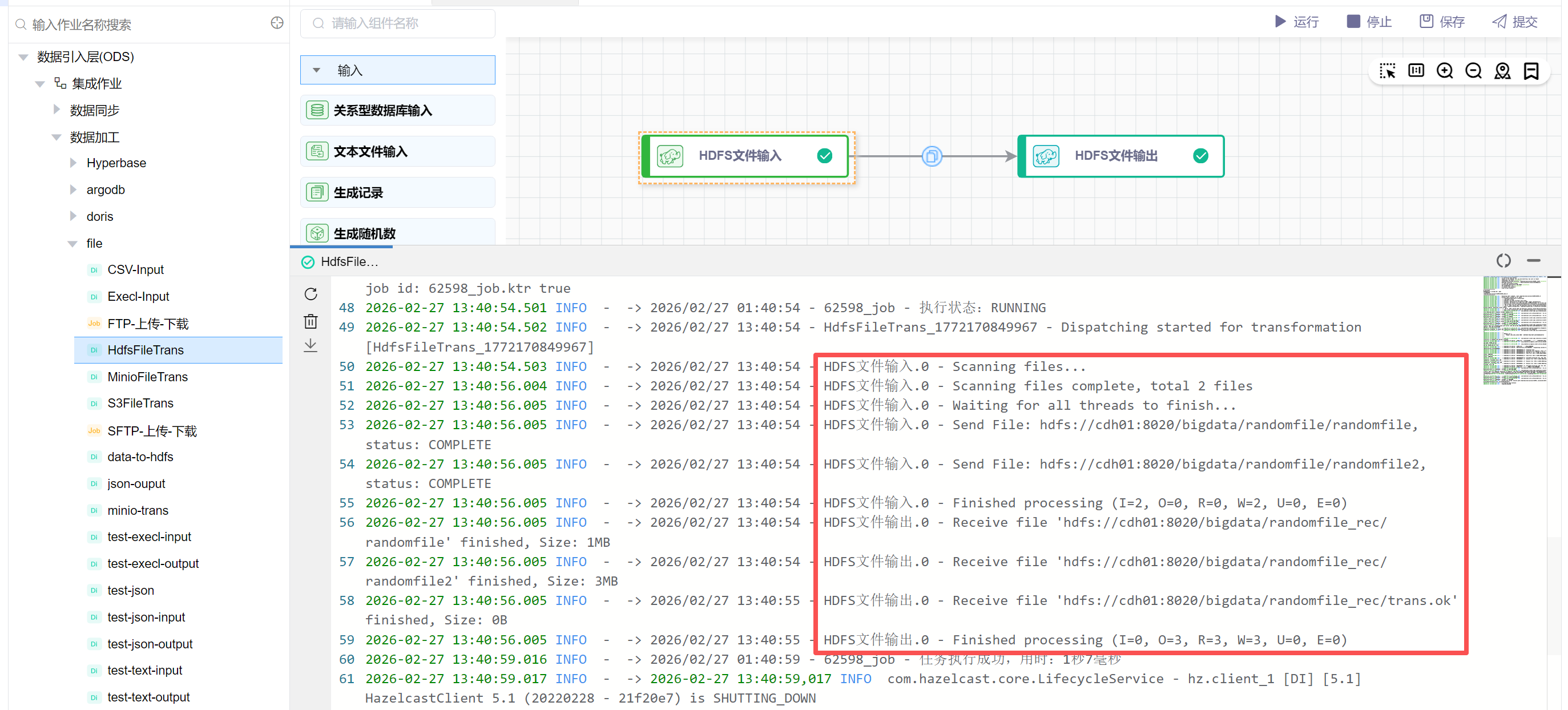
在HDFS中查看/bigdata/randomfile_rec目录,完成传输并生成了trans.ok目标标识文件。

# 提交版本
当草稿运行正常后,点击【提交】按钮可以将该版本提交到作业调度,每次修改提交都会生成新的版本,可以看到提交的历史版本,并可以随意切换版本。
提交后的版本,可以在作业调度中进行"定时"调度配置。
可以参考示例关系型表数据同步示例 中的"提交版本"说明。