# Kafka Source组件使用说明
# 组件说明
Kafka Source 连接器支持从 Kafka 单主题或多主题中高效消费数据,提供丰富的配置选项以满足不同场景需求。
# 配置项说明
| 配置名称 | 数据类型 | 是否必须 | 默认值 | 描述 |
|---|---|---|---|---|
| 节点名称 | String | 是 | Kafka | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。确保唯一性。 |
| 节点编码 | String | 是 | 自动生成 | 当前创建的节点编码,以此标识此组件,由用户自定义且不可为空。命名可包含字母、数字、下划线。确保唯一性。 |
| 选择数据源 | String | 是 | - | 从下拉选项中选择列出的当前项目已经关联的数据源。 |
| 主题名称 | String | 是 | - | Kafka Topic 名称。如果有多个topics,使用英文符号"," 进行拆分,例如:"tpc1,tpc2" 。 |
| 主题名称正则匹配 | Boolean | 是 | 否 | 如果设置为是,主题名称填写正则表达式。 |
| 行异常处理方式 | String | 否 | - | 有两种方式:阻塞抛出异常、跳过当前行。 |
| 数据格式 | String | 是 | json | 数据格式支持: - json:JSON数据 - text:普通文本 - canal_json/debezium_json/maxwell_json/ogg_json:CDC变更数据捕获 - avro:Avro序列化 - protobuf:Protobuf序列化(需指定protobuf_message_name和protobuf_schema) - native:保留Kafka元数据(分区、偏移量、时间戳等) 默认格式为 json。默认的字段分隔符是","。如果自定义分隔符,请添加“字段分隔符”选项。 如果使用 canal 格式,请参考 canal-json (opens new window) 了解详细信息。如果使用 debezium 格式,请参考 debezium-json (opens new window)。一些Format的详细信息请参考 formats (opens new window) |
| 数据结构 | String | 否 | - | 字段的数据结构(包括字段名称和字段类型)。 详见FAQ-Q1 |
| 消费组ID | String | 是 | - | Kafka 消费者的 group id,用来区分不同的消费群体。 |
| 偏移量是否定期提交 | Boolean | 否 | 否 | boolean 类型,如果为 true,消费者的偏移量将在后台定期提交。 |
| 消费模式 | String | 否 | group_offsets | 消费者的初始消费模式,有 5 种: - earliest:从最早偏移量开始; - group_offsets:从 Consumer Group 已提交偏移量恢复; - latest:从最新偏移量开始; - specific_offsets:指定分区具体偏移量(需配合start_mode.offsets); - timestamp:从指定时间戳开始(需配合start_mode.timestamp)。 |
| 动态发现主题和分区时间间隔 | Int | 否 | -1 | 动态发现主题和分区的时间间隔。 |
| 轮询时间间隔 | Int | 否 | 10000 | 轮询消息的间隔时间,单位为:毫秒。 |
| 可选参数 | - | 是 | - | 其他参数,用户可以根据需求进行配置。 |
# 错误处理与性能调优
格式错误处理:format_error_handle_way = "skip"跳过坏消息,默认fail抛出异常
字段分隔符:field_delimiter,Text格式时自定义分隔符(默认逗号)
poll超时:poll.timeout = 10000(毫秒),控制拉取间隔
Checkpoint提交:commit_on_checkpoint = true,在Checkpoint时提交偏移量(推荐)
Reader缓存:reader_cache_queue_size,控制Shard缓存大小,默认1024
# FAQ
- 包括字段名称和字段类型:
- 字段类型:
- string
- boolean
- tinyint
- smallint
- int
- bigint
- float
- double
- decimal
- bytes
- date
- timestamp
- map (map<string, int>,map<string, string>,map<string, boolean>,map<string, tinyint>,map<string, smallint>,map<string, bigint>,map<string, float>,map<string, double>,map<string, decimal>,map<string, date>,map<string, time>,map<string, timestamp>,map<string, null>,map<string, array>,map<string, map>
)
- array
- string
Q2: Kafka中有一个Json数据,在数据结构中怎么配置呢?
Kafka json数据:{"id": "1001", "name": "zhangsan"}
数据结构配置:
| 字段名 | 字段类型 |
|---|---|
| id | string |
| name | string |
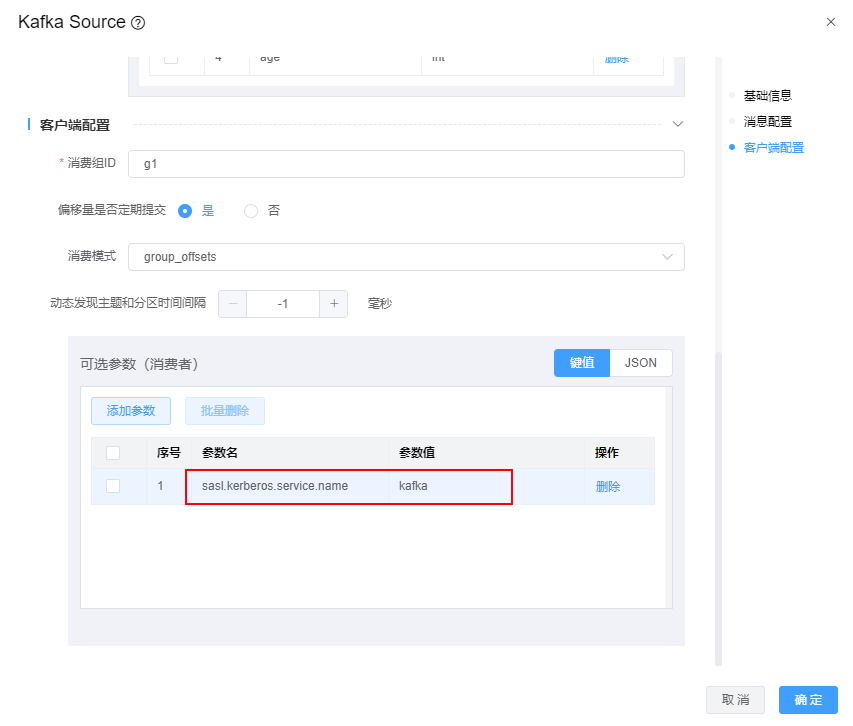
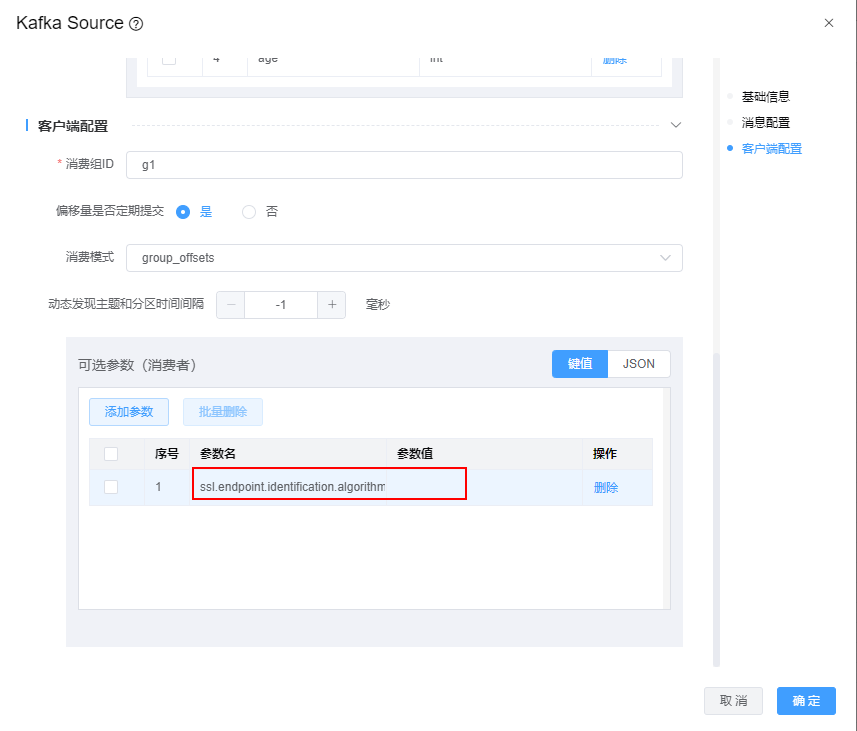
Q3: kafka使用SSL认证或者kerberos认证时,模型应该怎么配置?
A3: 当kafka使用认证后,还需要在可选参数中做如下配置
kafka使用SSL认证,增加参数 ssl.endpoint.identification.algorithm =
kafka使用kerberos认证,增加参数 sasl.kerberos.service.name= kafka