# 数据血缘
注意:使用该功能前请先部署 Neo4j4.4.42(介质中不提供,请自行下载),并在 dws_server/config/application-dws.properties 修改配置开启配置。如果 dws.lineage.enable=false,则“数据血缘”相关功能入口将隐藏。
# 支持查看和管理数据血缘相关功能,配置为false则相关菜单和功能将禁用
dws.lineage.enable=true
# 当前服务器是否处理血缘任务,部署多台服务器时,配置一台启用即可
dws.lineage.analyser-enable=true
# 参考[应用中心-> 应用管理 -> DWS -> OAuth2认证设置],需要先启动AFC,获取此secret,如果刷新了secret,请更新此值
dws.lineage.secret=b7a75f72567048a78a89c54b23f5240c
# 每次获取分析任务的数量
dws.lineage.task.fetch-size=8
# 可以通过调整此值来控制等待队列的大小,用来提前装载分析任务
dws.lineage.task.waiting-queue-size=4
# 获取分析任务间隔时间,单位毫秒
dws.lineage.task.fetch-interval=1000
# 每次处理分析任务的数量(线程数量)
dws.lineage.task.analyser-size=4
# 缓存任务的分析结果数量,合理控制避免内存溢出,如果flush数据较慢,会暂停消费新的分析任务
dws.lineage.task.result-cache-size=20
# 周期性的flush缓存数据到图库中,单位毫秒
dws.lineage.task.result-flush-interval=10000
# apoc的写入批大小,同时也是全量分析时节点、边的缓存队列大小的配置值 ${result-flush-batch-size} * 1.5
dws.lineage.task.result-flush-batch-size=1000
spring.neo4j.uri=bolt://127.0.0.1:7687
spring.neo4j.authentication.username=neo4j
spring.neo4j.authentication.password=primeton
logging.level.org.springframework.data.neo4j=INFO
在IDE中进行数据开发时,提交版本后自动进行血缘分析并图形化展示数据血缘图,可以查看整个ETL流程的数据走向包括:数据源、表、字段血缘关系。
支持数据血缘的模型有:数据同步、数据加工、通用模板、作业流、SQL程序(包括:子查询语句、INNER JOIN语句、LEFT JOIN语句、RIGHT JOIN语句、UNION语句)。
提示:鼠标点选表后会,会自动计算并在有血统、影响的表展示 <、<<、>、>> 按钮。
该模块涉及的功能如下:
# 数据同步
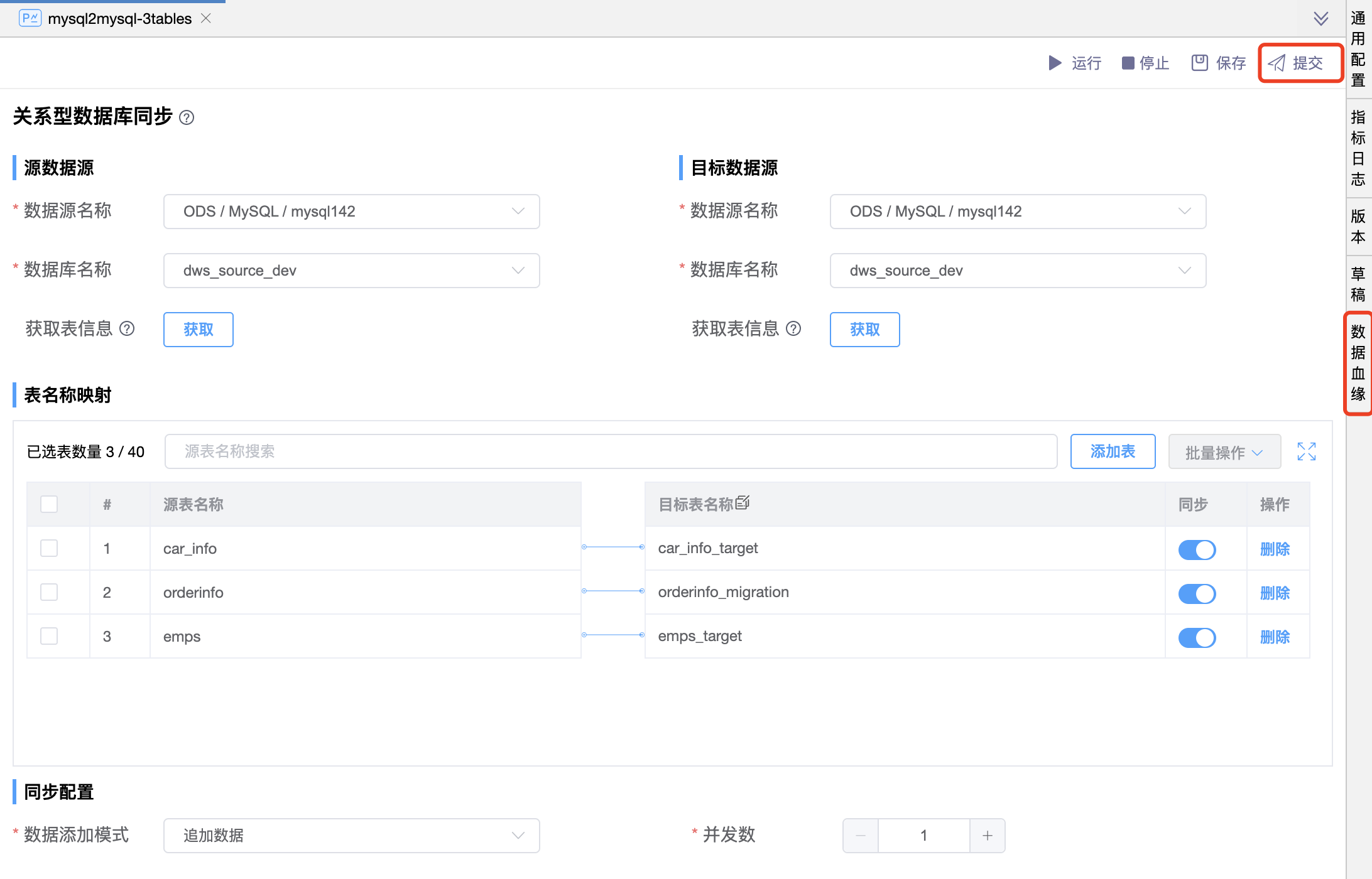
例如,完成如下数据同步作业的开发。点击【提交】按钮,并提示“提交成功”后,再点击【数据血缘】页签即可展示该作业的数据血缘图。
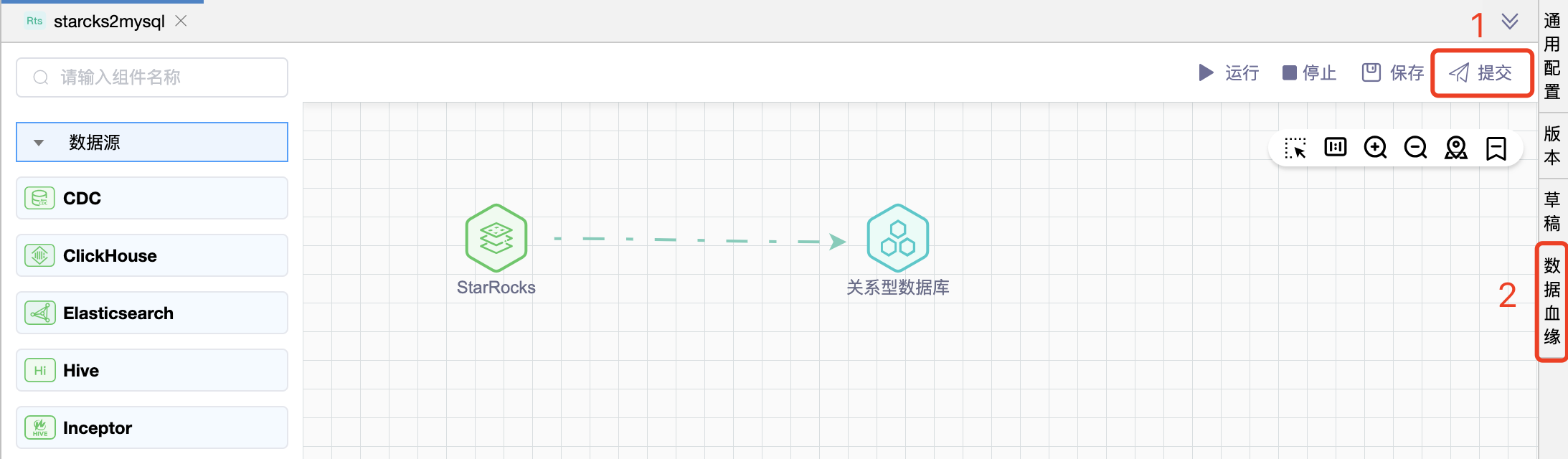
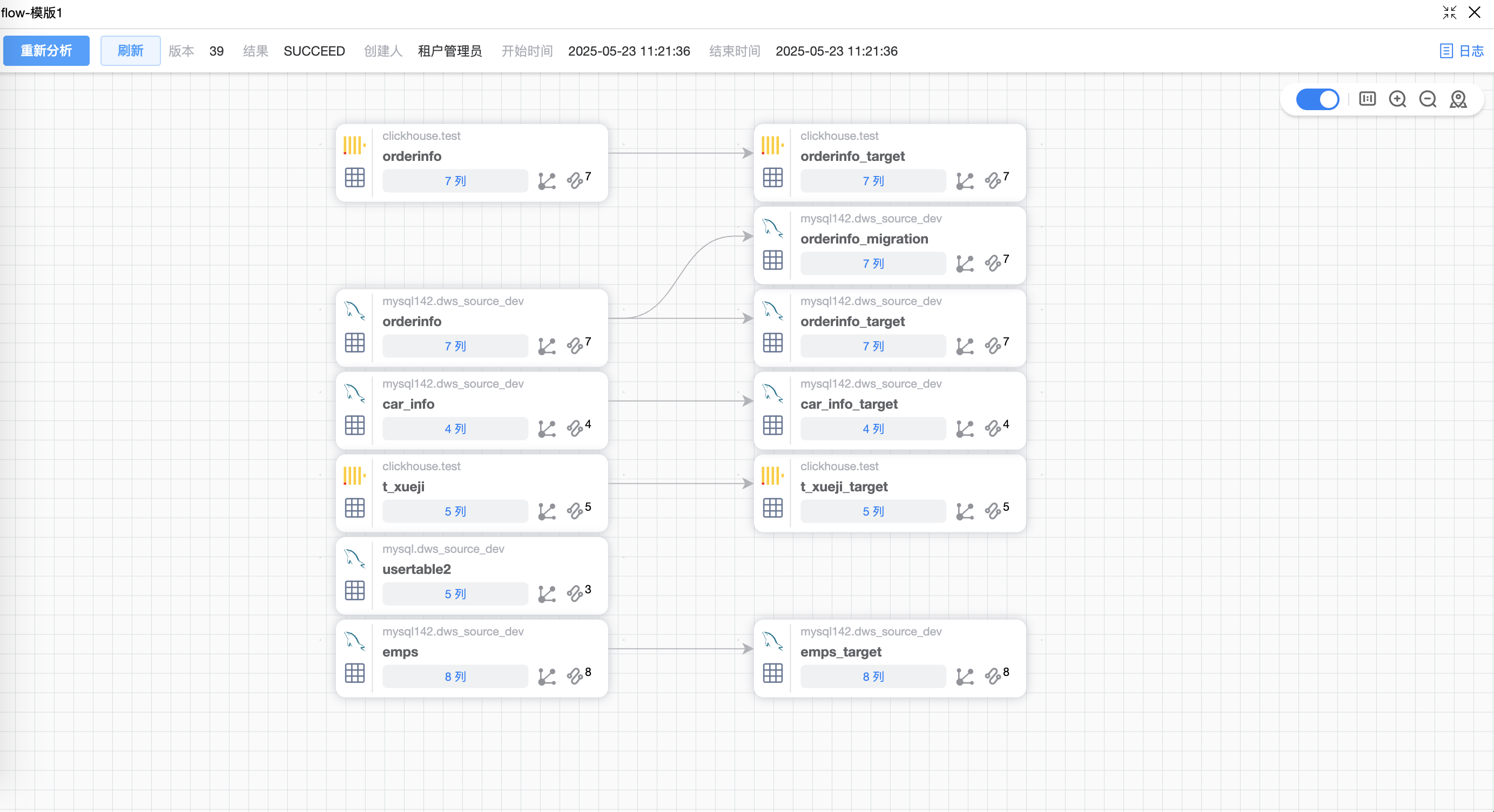
默认仅展示该作业的表血缘图,鼠标点选表后,可以根据表上的按钮查看血统(箭头 < 或者 <<)、影响(箭头 > 或者 >>)。
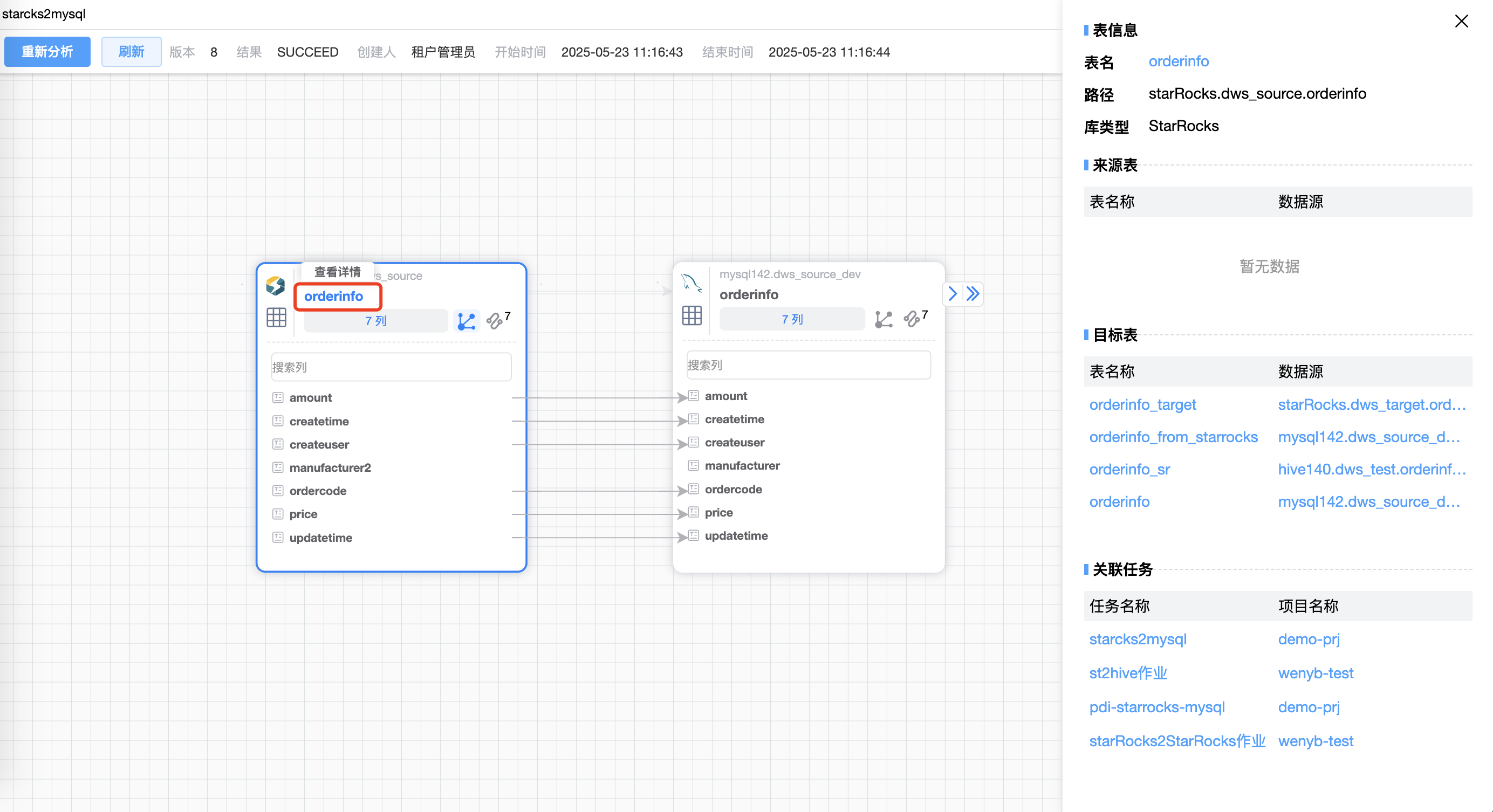
# 节点信息
点击图上红框的“数据源”区域,右侧会显示该节点的相关信息,包括:表信息、直接上游、直接下游、关联任务。
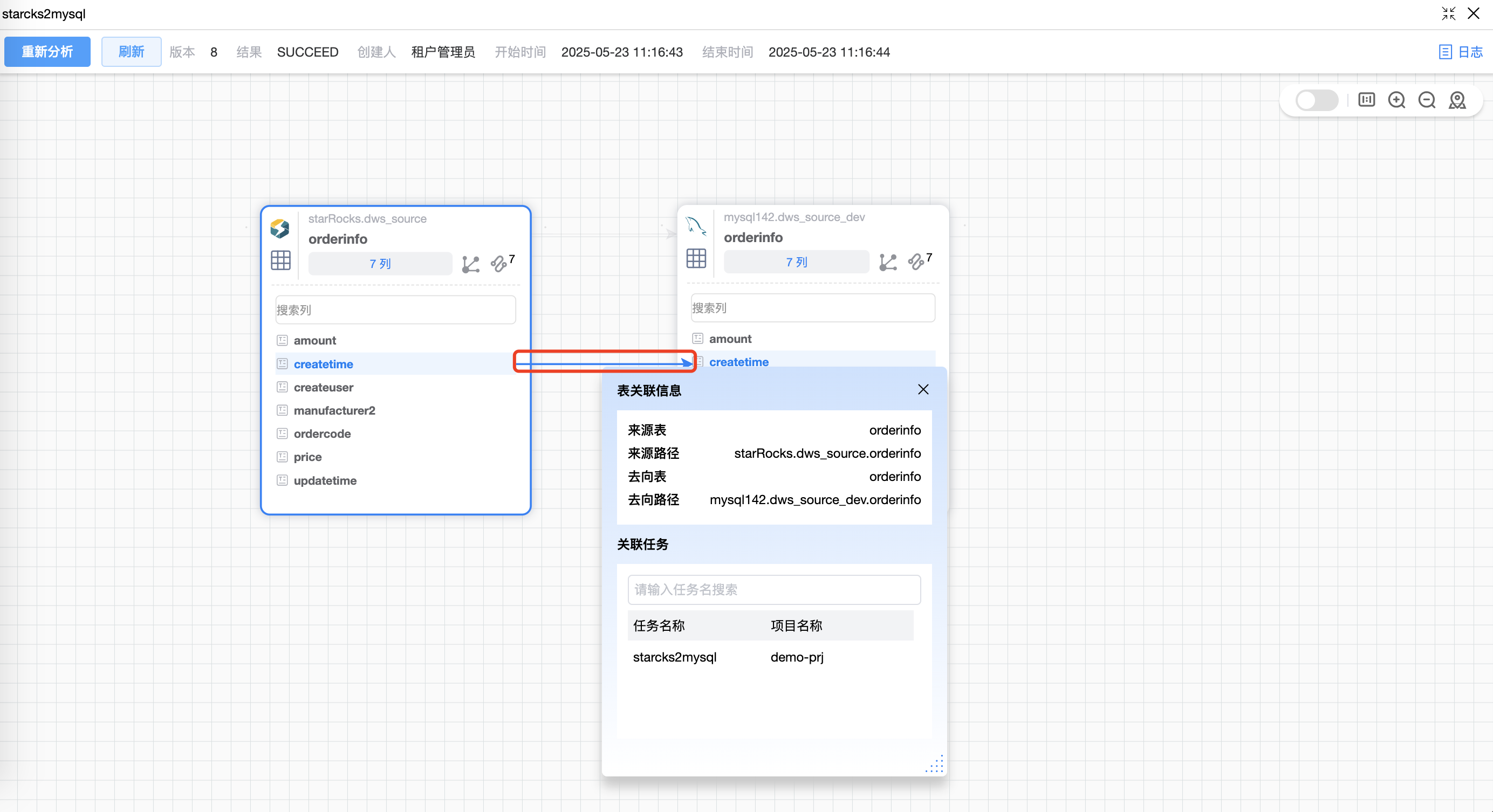
# 连线操作
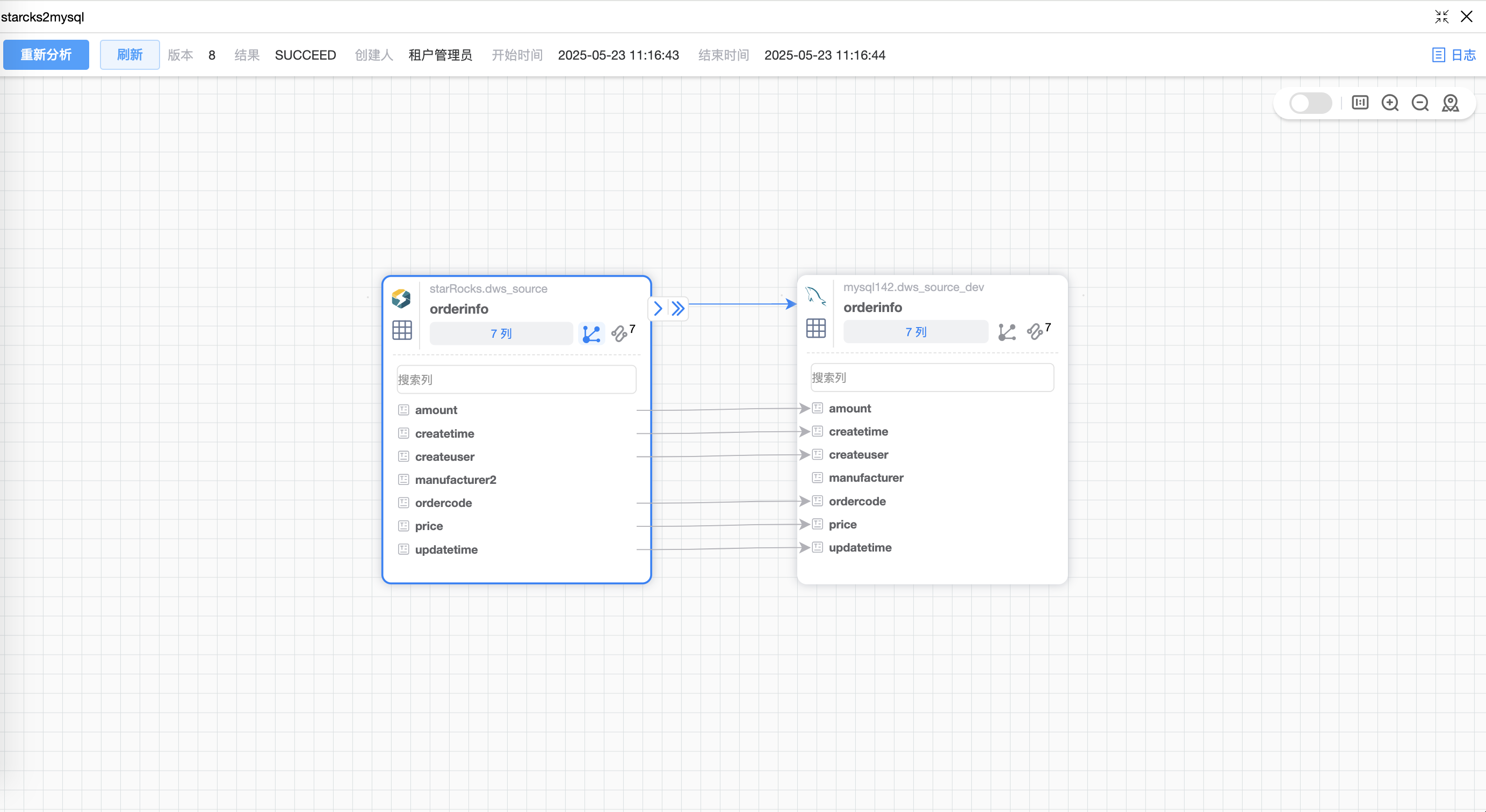
点击某个字段时,有映射关系的源表、目标表字段会着色,点击连线后的弹框显示表与表之间的数据往来,包括:来源表、来源路径、去向表、去向路径、关联作业。
点击“关联作业”可以跳转到与该表关联的其他相关作业。当关联作业较多时,可以输入关键字进行搜索、过滤。
| 操作及图形示意 | 说明 |
|---|---|
| 提交 | 作业开发完成并运行测试正常后,点击该按钮完成版本的提交,同时后台程序会自动进行血缘分析并记录血缘关系数据。 |
| 数据血缘 | 点击该按钮可以切换将界面切换至可视化数据血缘图。 |
| < | 展示当前表的直接血统表。 |
| << | 展示当前表的全部血统表。 |
| > | 展示当前表直接会影响的表。 |
| >> | 展示当前表会影响的全部表。 |
| + | 放大数据血缘图。 |
| - | 缩小数据血缘图。 |
| 1:1 | 复位数据血缘图的大小,恢复 1:1 的比例。 |
| 列分页开启/关闭 | 表中的字段分页展示或者全部展示。默认是分页展示。 |
| 展示列级血缘 | 显示表中的字段且源表与目标表的字段建立映射连线。 |
| 仅展示有血缘的列 | 当表中只有个别字段有血缘关系,则过滤(不展示)无血缘关系的字段,仅展示有血缘关系的字段。右上角数字表示有血缘关系的列个数。 |
| 查看详情 | 显示该表的详细信息,如:来源表、来源路径、去向表、去向路径、关联作业。 |
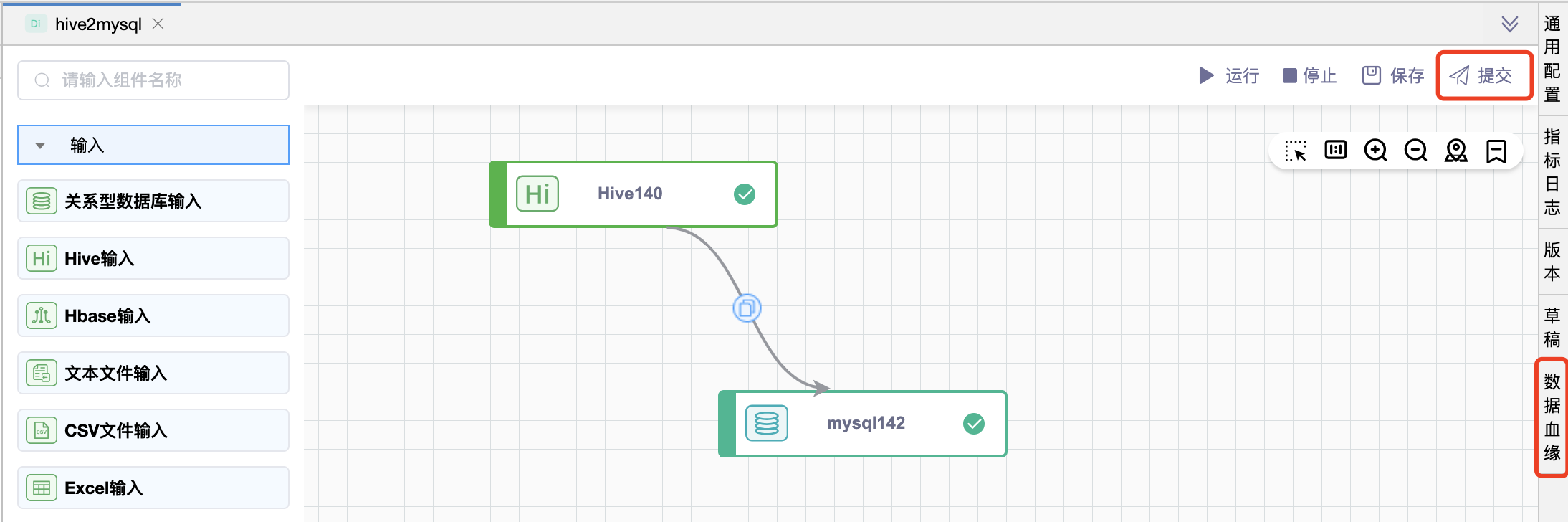
# 数据加工
例如,完成如下数据加工作业的开发。点击【提交】按钮,并提示“提交成功”后,再点击【数据血缘】页签即可展示该作业的数据血缘图。
默认仅展示该作业的表血缘图,鼠标点选表后,可以根据表上的按钮查看血统(箭头 < 或者 <<)。
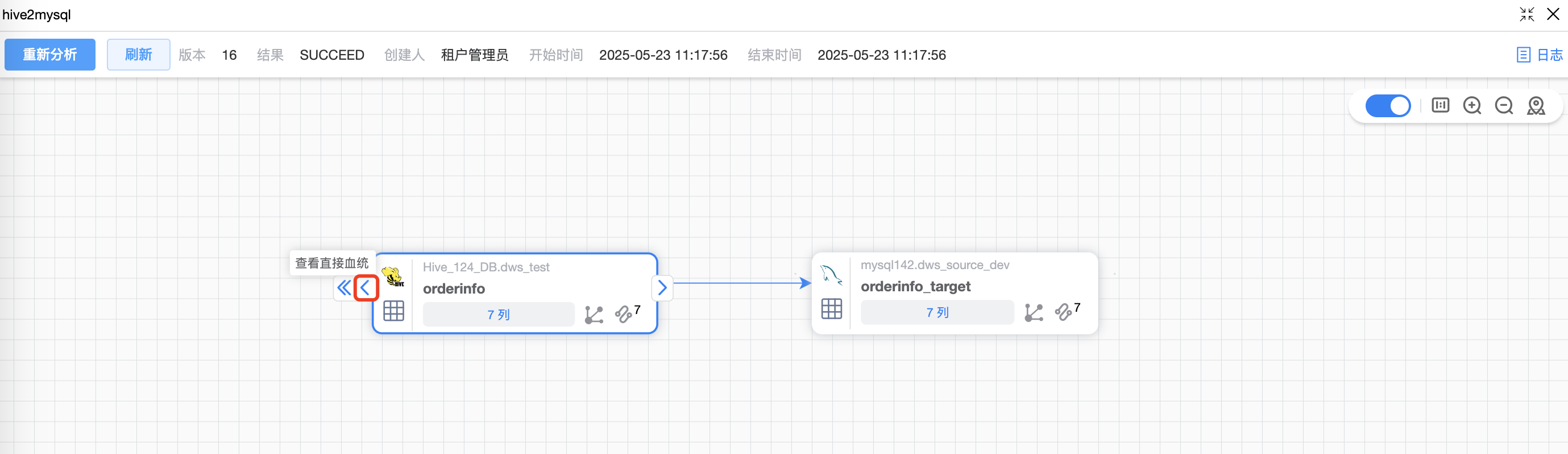
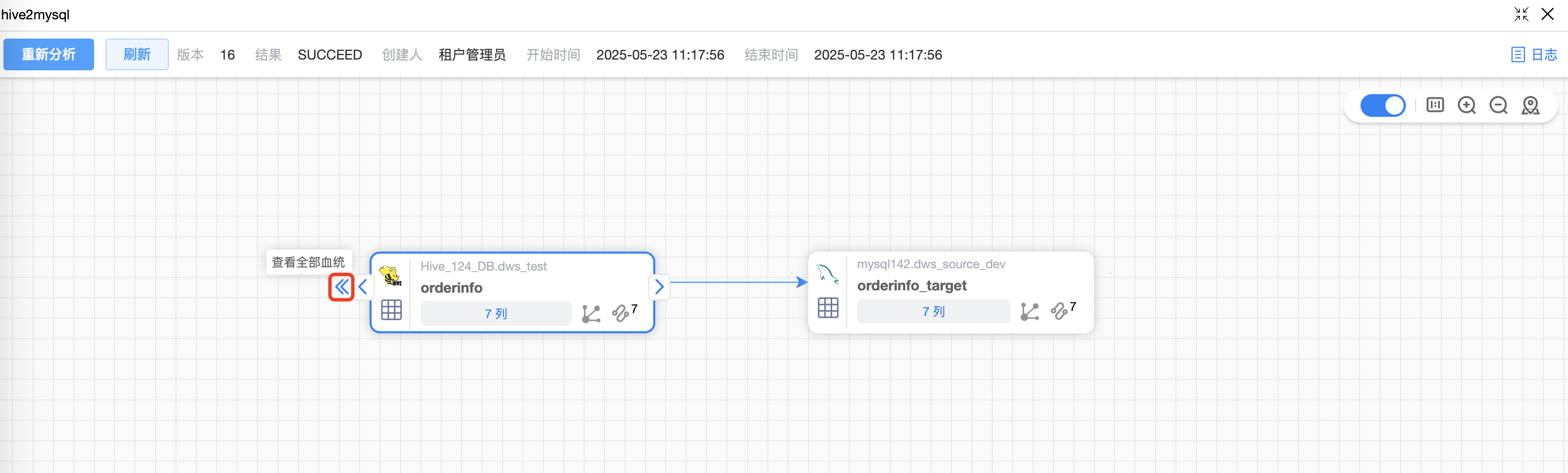
默认仅展示该作业的表血缘图,鼠标点选表后,可以根据表上的按钮查看血统影响(箭头 > 或者 >>)。
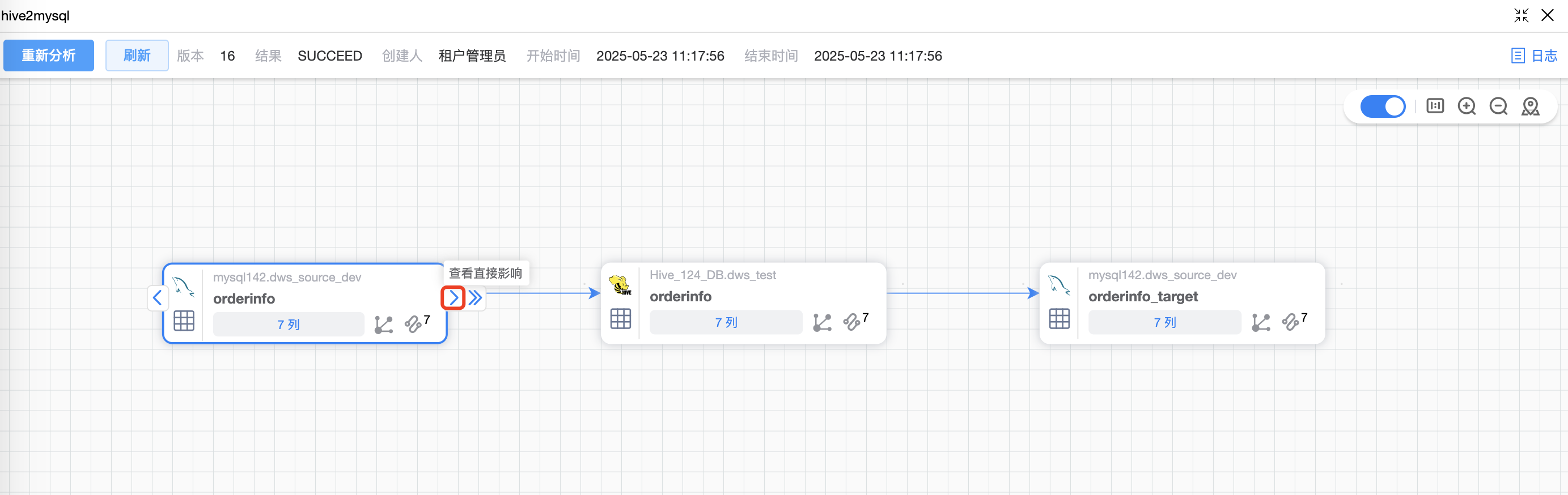
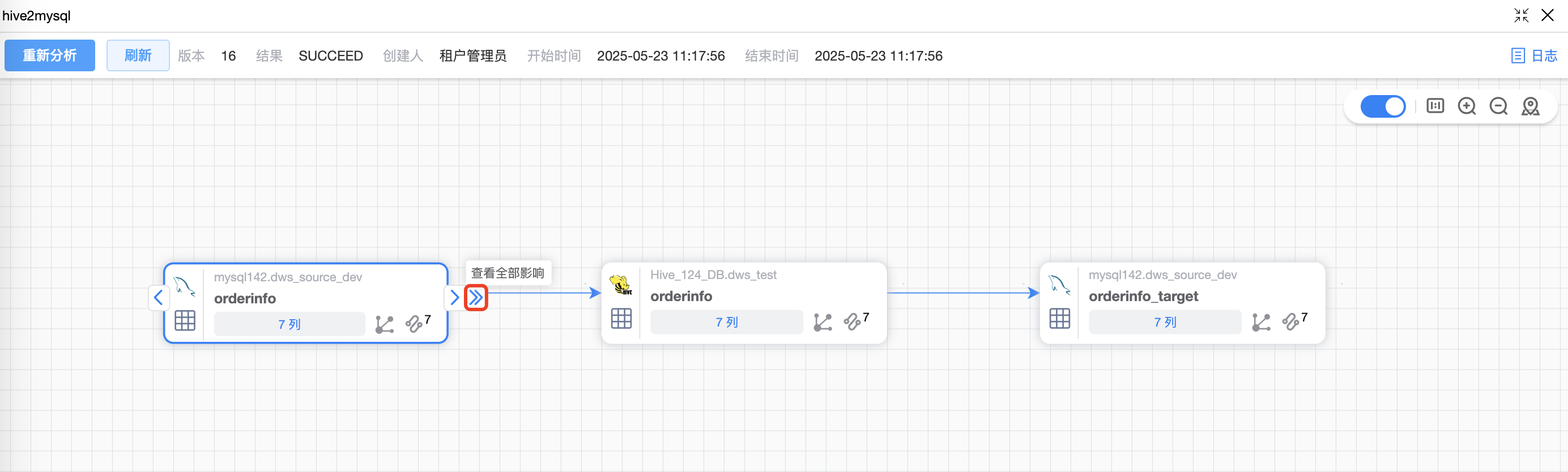
# 通用模板
例如,完成如下通用模板作业的开发。点击【提交】按钮,并提示“提交成功”后,再点击【数据血缘】页签即可展示该作业的数据血缘图。
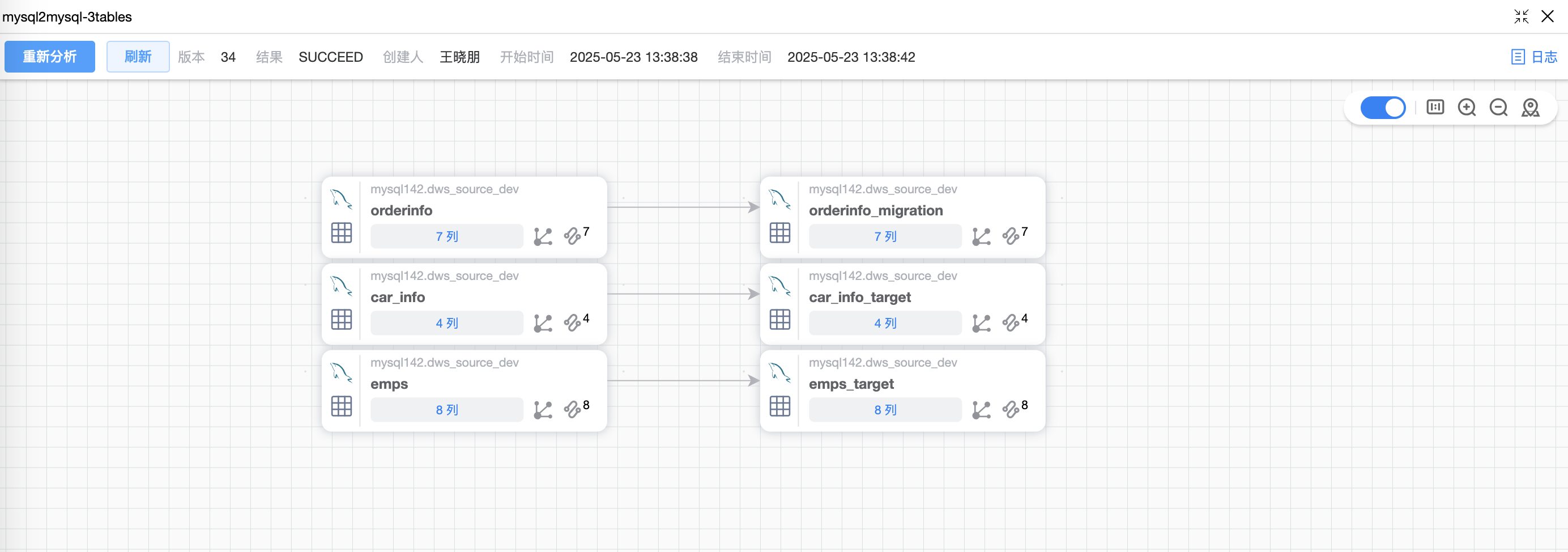
# SQL 程序
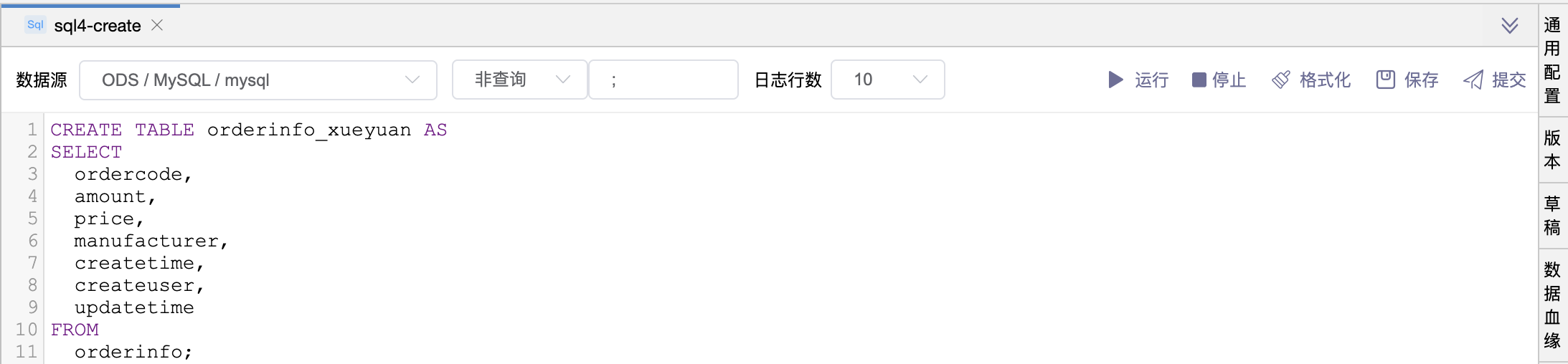
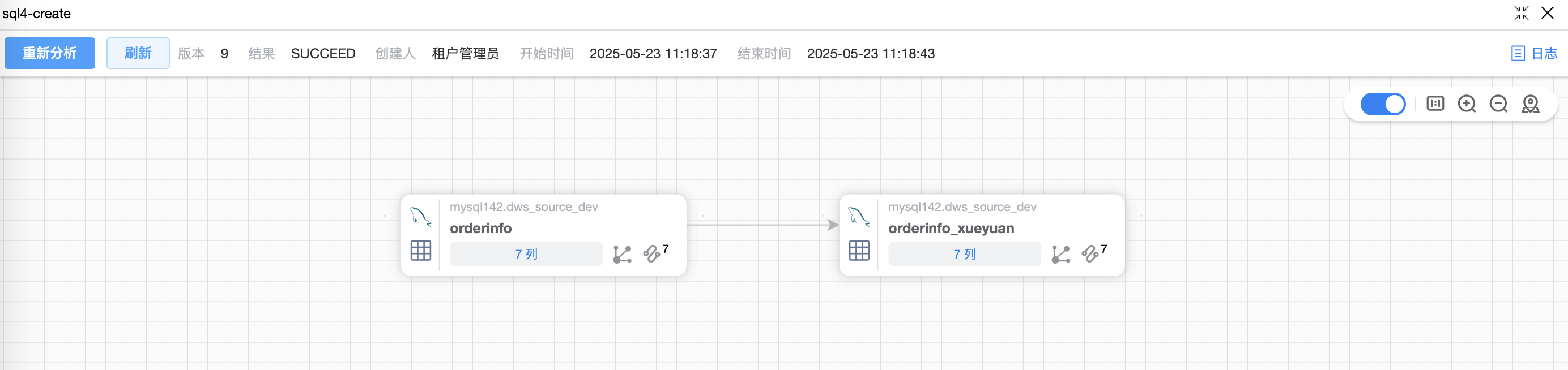
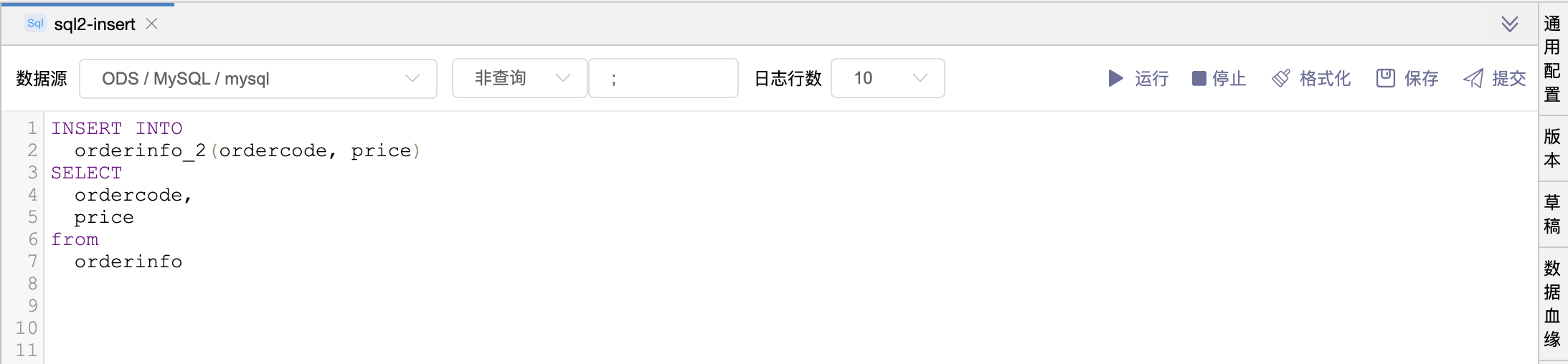
SQL 程序的数据血缘只支持:CREATE语句、INSERT语句、INNER JOIN语句、LEFT JOIN语句、RIGHT JOIN语句、UNION语句。
# 场景1:CREATE 语句
# 场景2:INSERT 语句
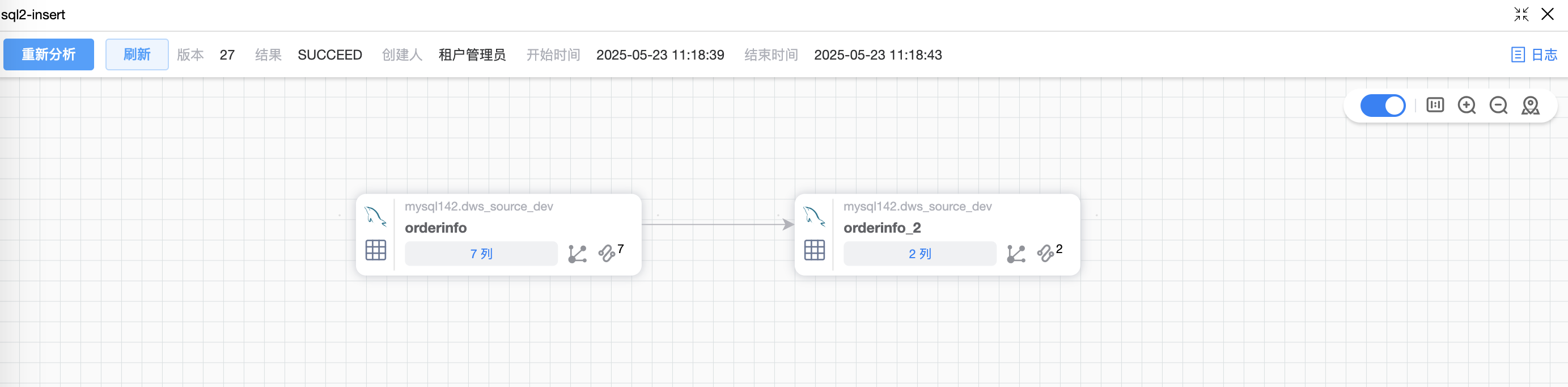
# 场景3:INNER JOIN 语句
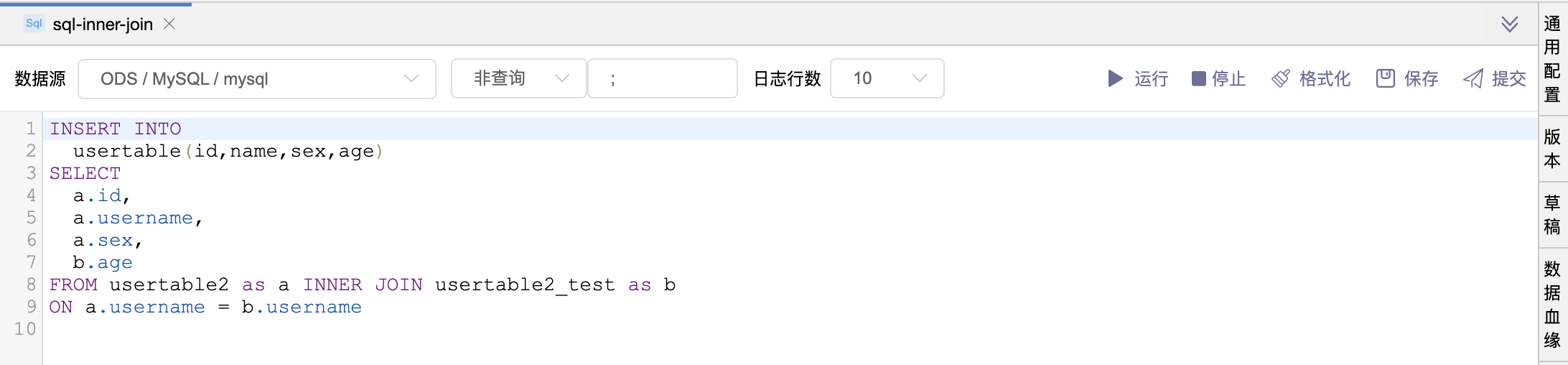
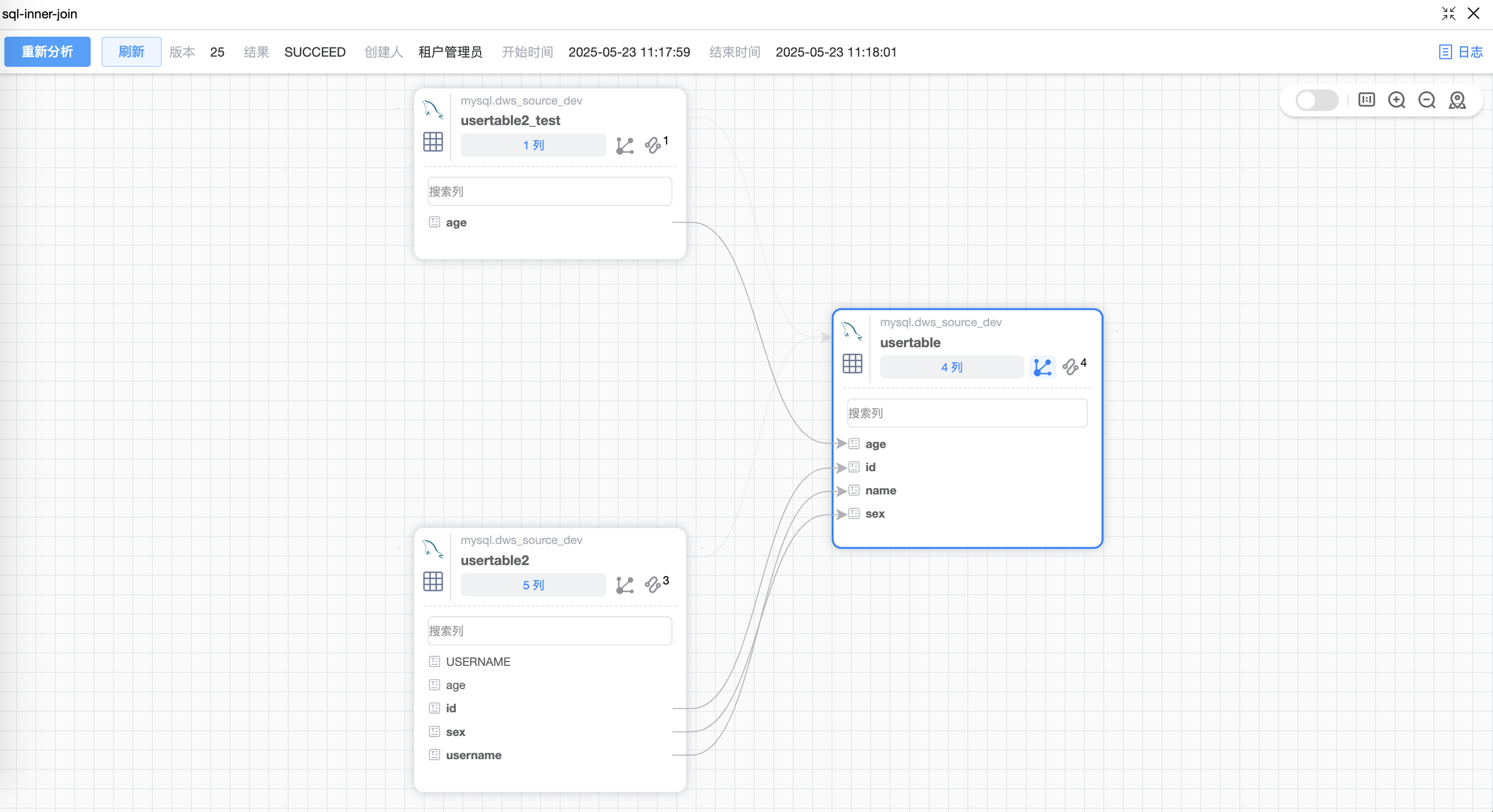
# 场景4:LEFT JOIN 语句
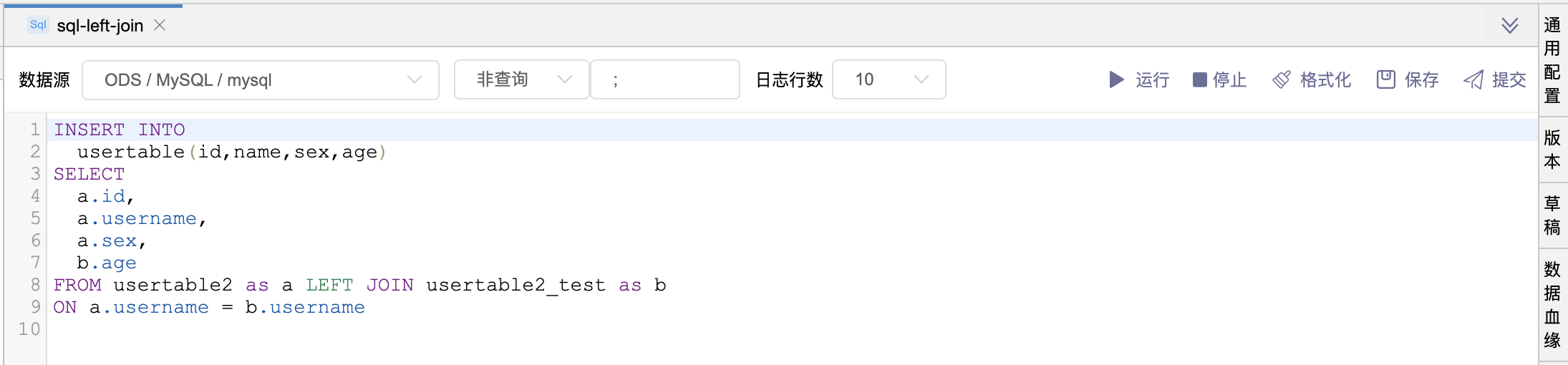
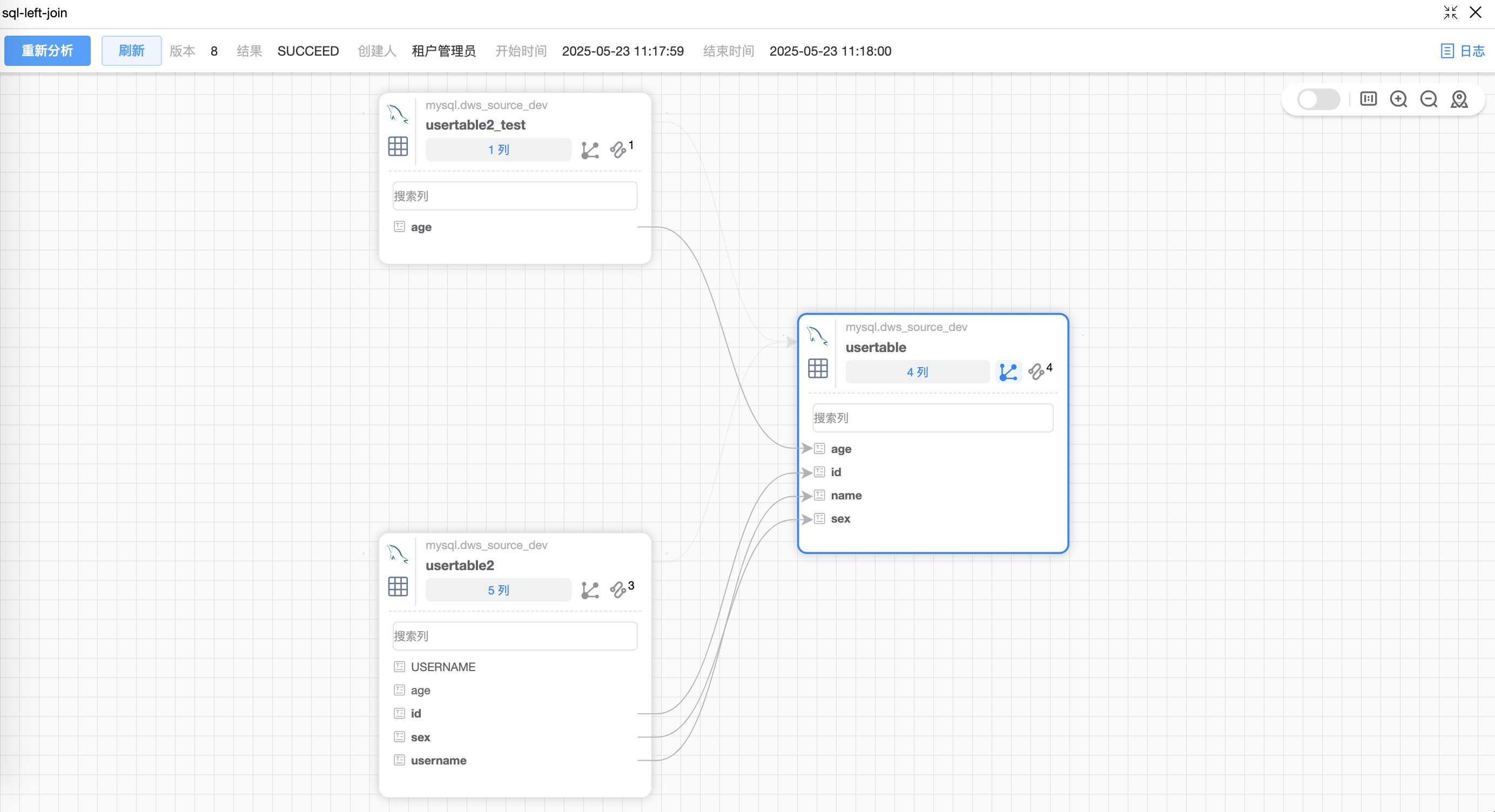
# 场景5:RIGHT JOIN 语句
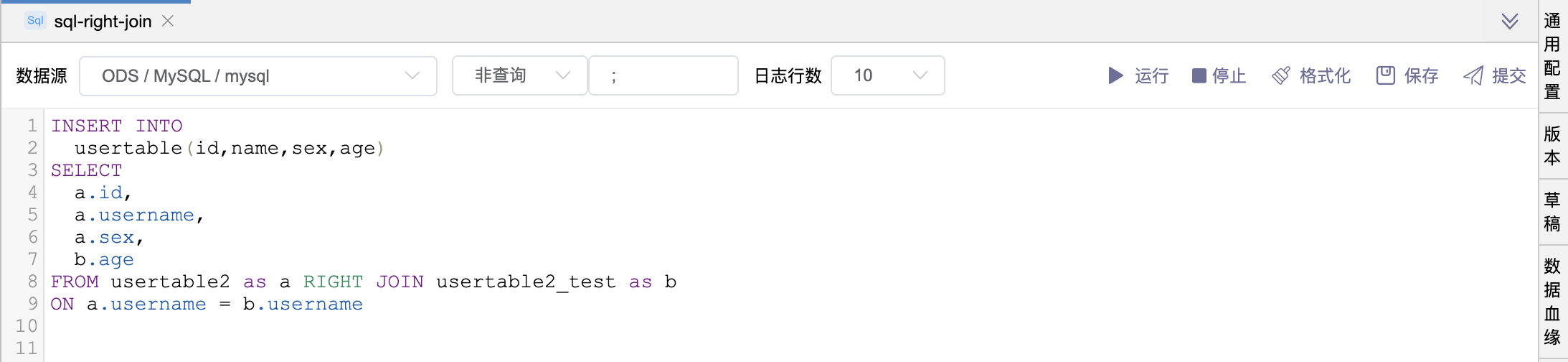
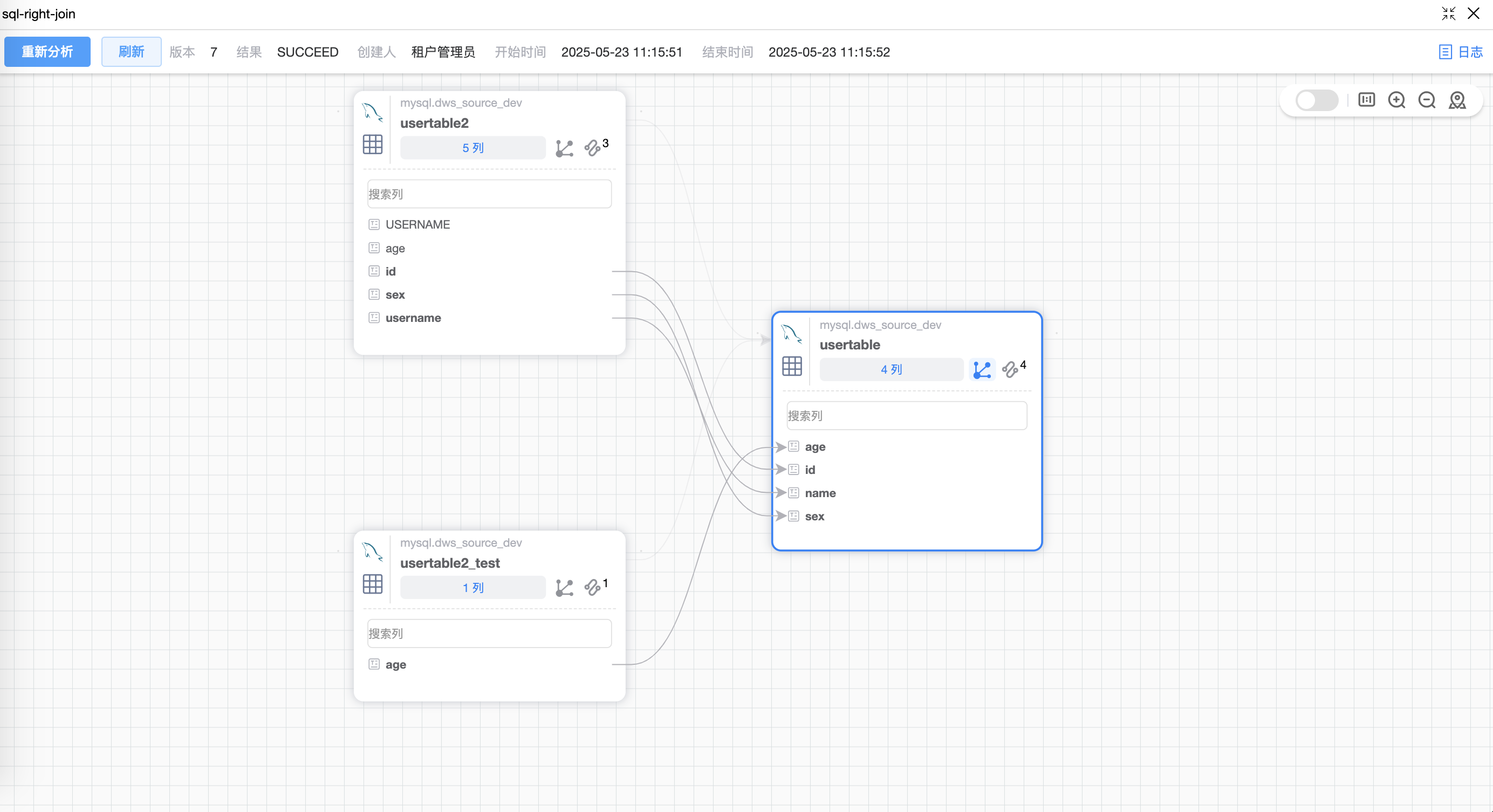
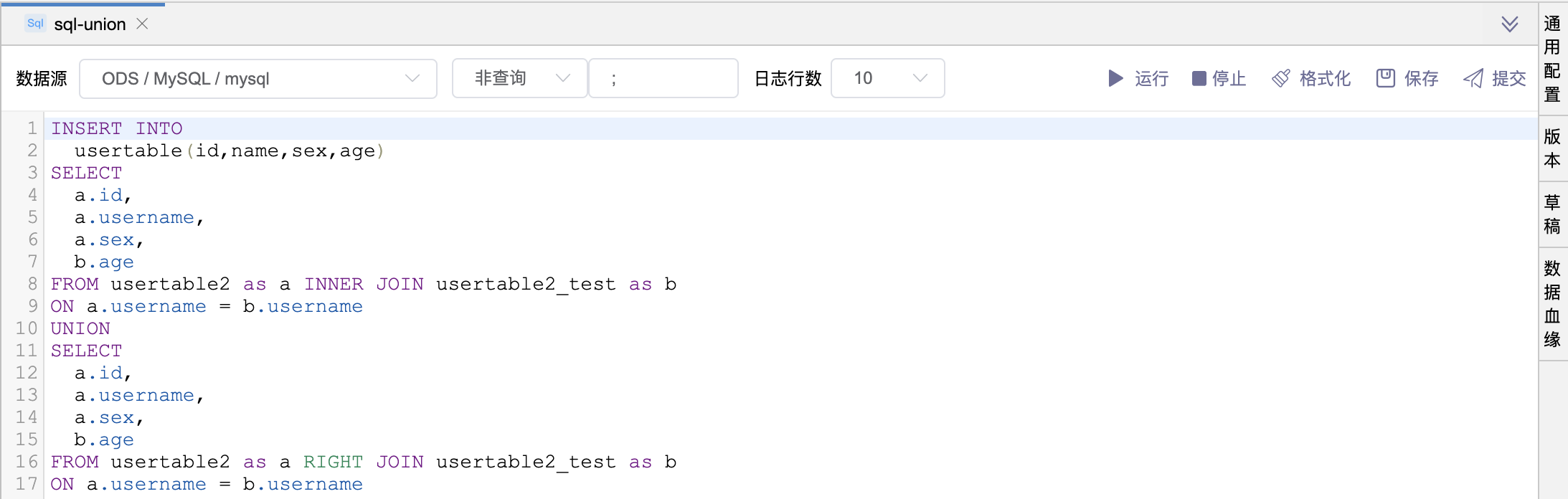
# 场景6:UNION 语句
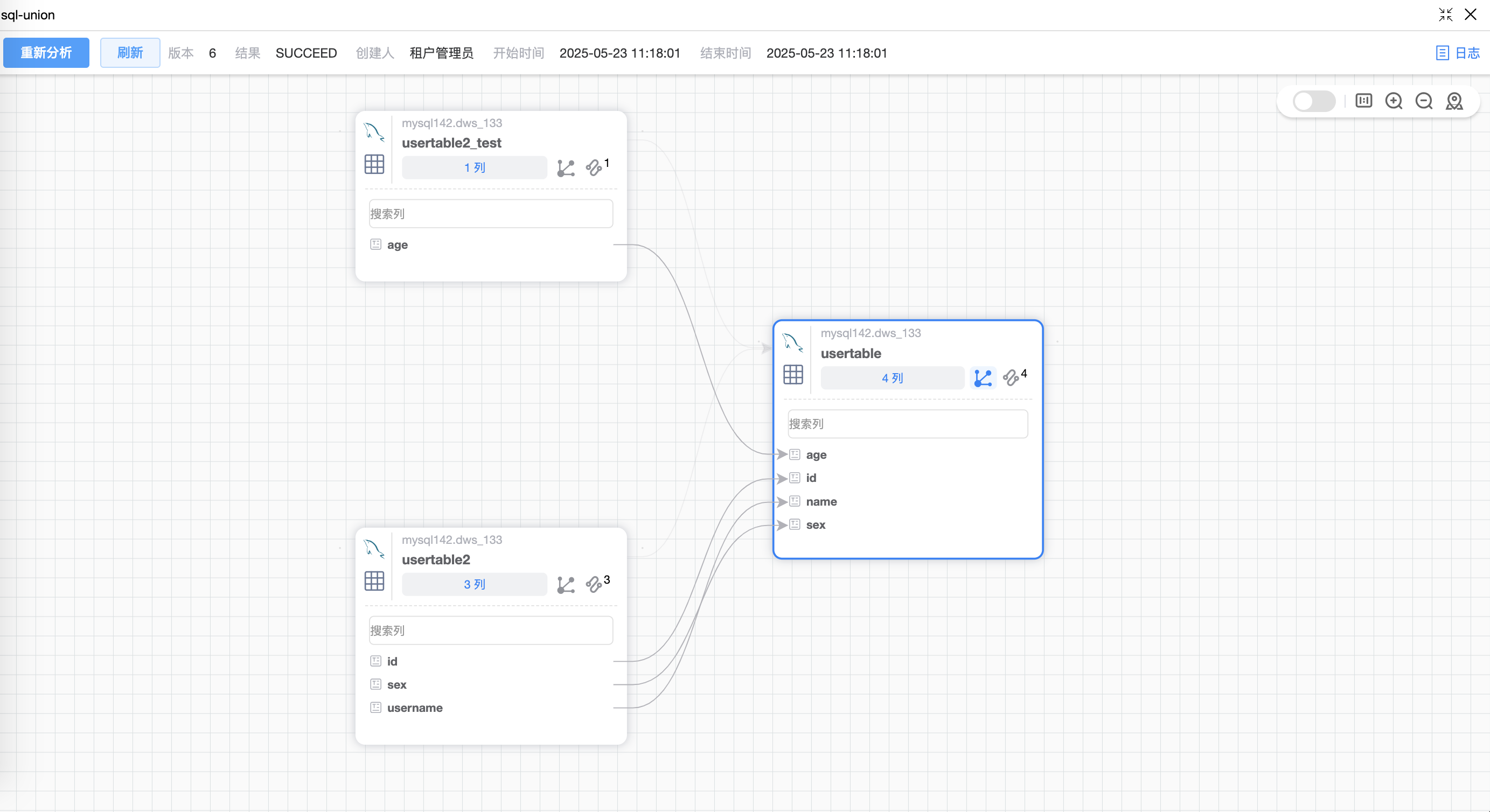
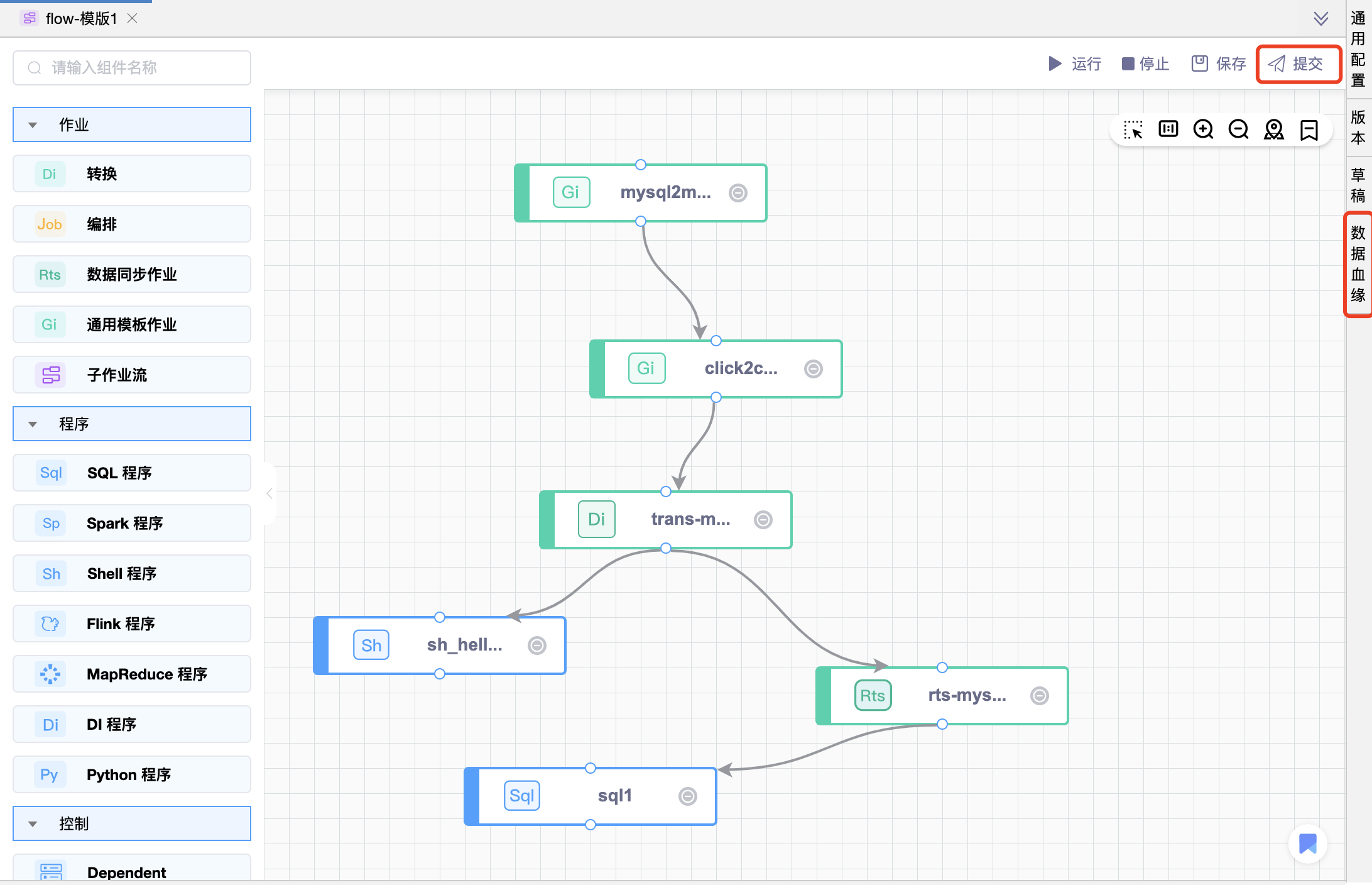
# 作业流
例如,完成如下作业流的开发。点击【提交】按钮,并提示“提交成功”后,再点击【数据血缘】页签即可展示该作业的数据血缘图。