
# Flink程序示例
本示例主要介绍开发Flink 程序的需求场景。
主要步骤如下:
# 环境准备
下载flink介质并部署在dolphinscheduler的worker节点所在服务器上。
tar -zxvf flink-1.15.4-bin-scala_2.12.tgz -C /home/将flink目录添加到dolphin的环境信息中。
Flink程序是在dolphinscheduler中运行,故需要配置FLINK_HOME环境变量。
vim bin/env/dolphinscheduler_env.sh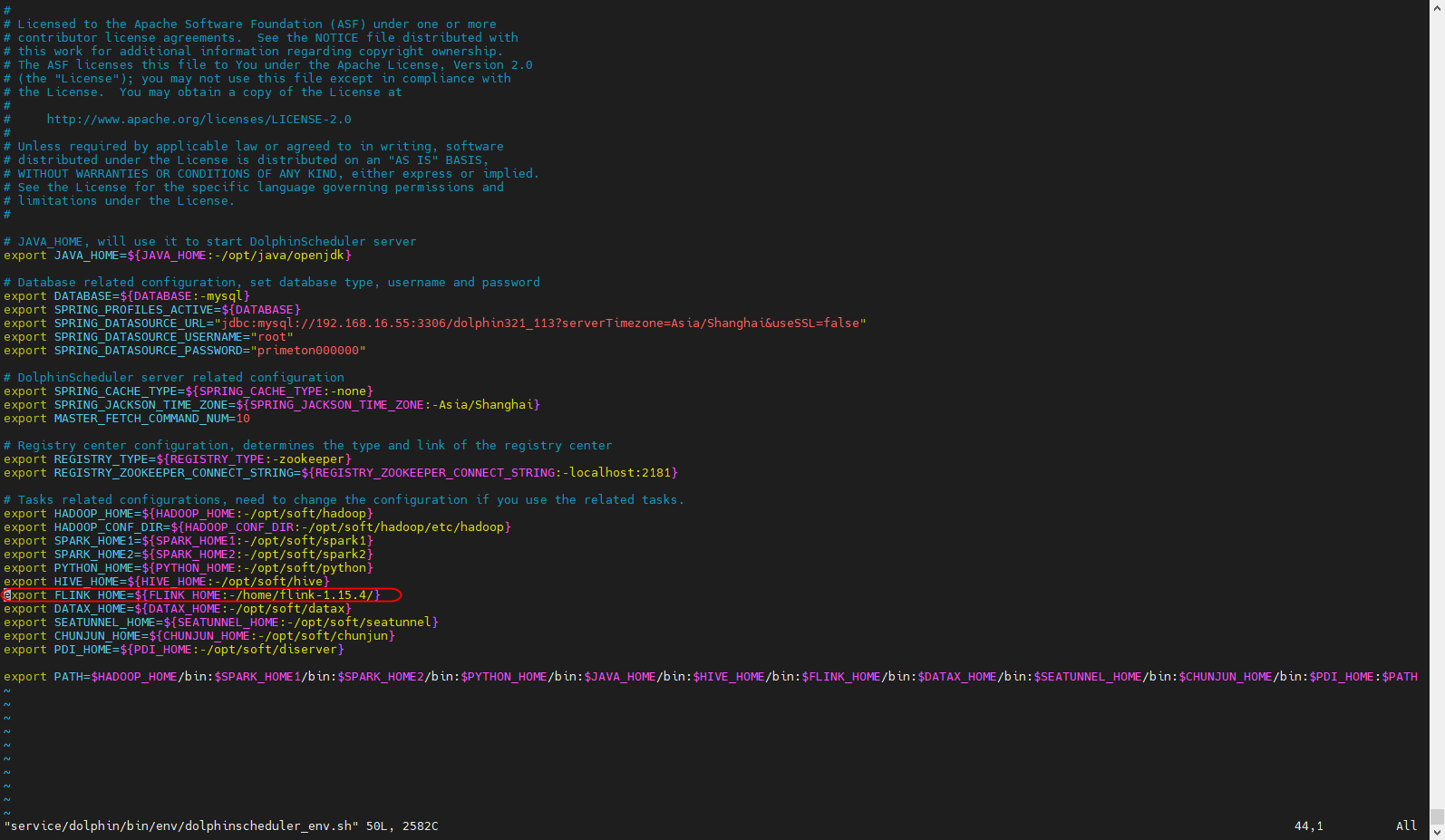
配置大数据环境
flink程序需要上传jar到hdfs,故需要配置大数据环境。可参考dolphinscheduler对接远端对象存储
- 将对应大数据环境的配置文件core-site.xml和hdfs-site.xml分别拷贝至worker-server/conf/和 api-server/conf/目录下。
dolphinshceduler standalone版将对应大数据环境的配置文件core-site.xml和hdfs-site.xml拷贝至standalone-server/conf目录下
在api-server/conf、worker-server/conf的配置文件common.properties中设置远端对象存储环境。
dolphinshceduler standalone版修改standalone-server/conf/common.properties文件
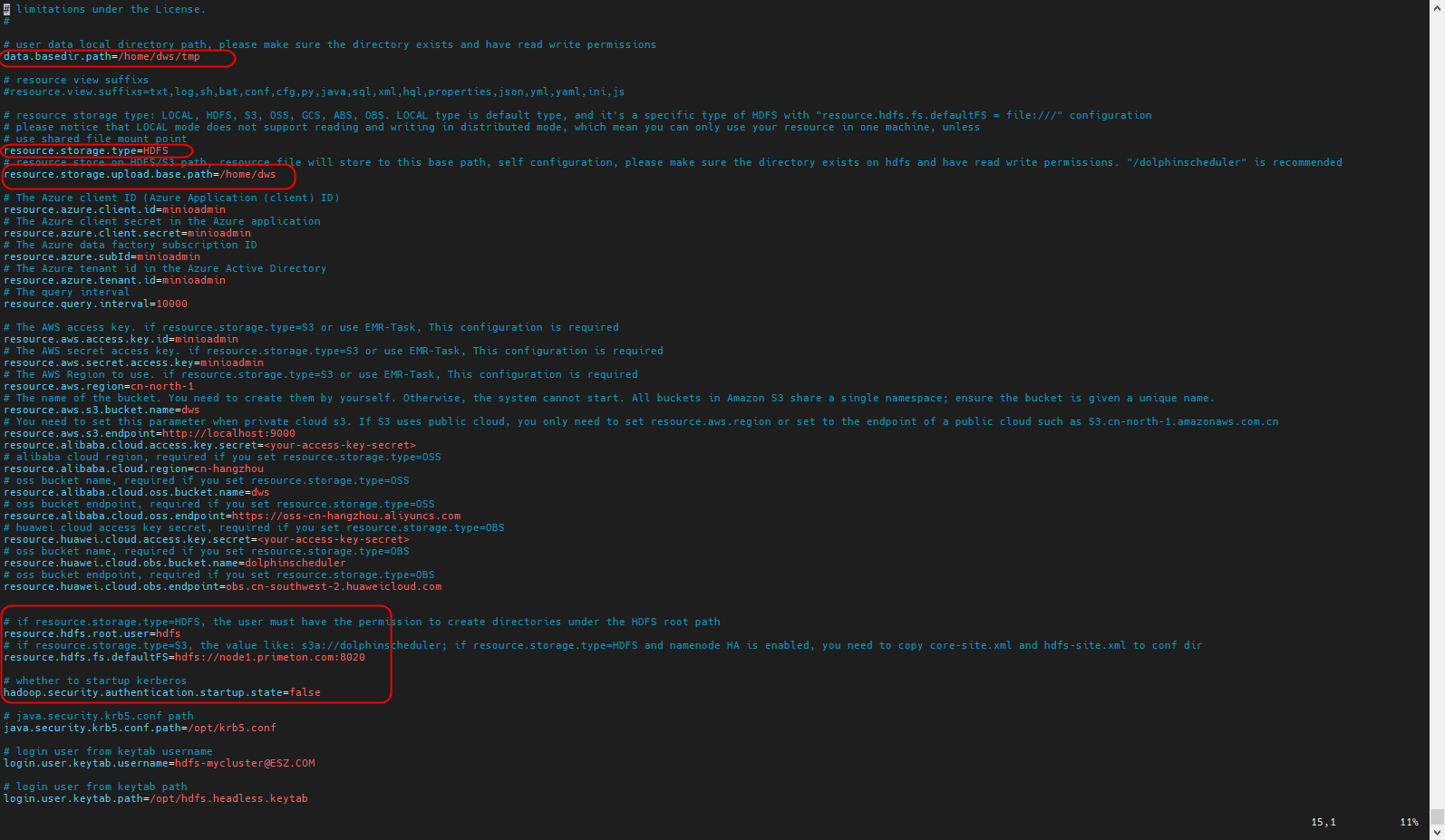
重启dolphinscheduler服务。
# 前置准备
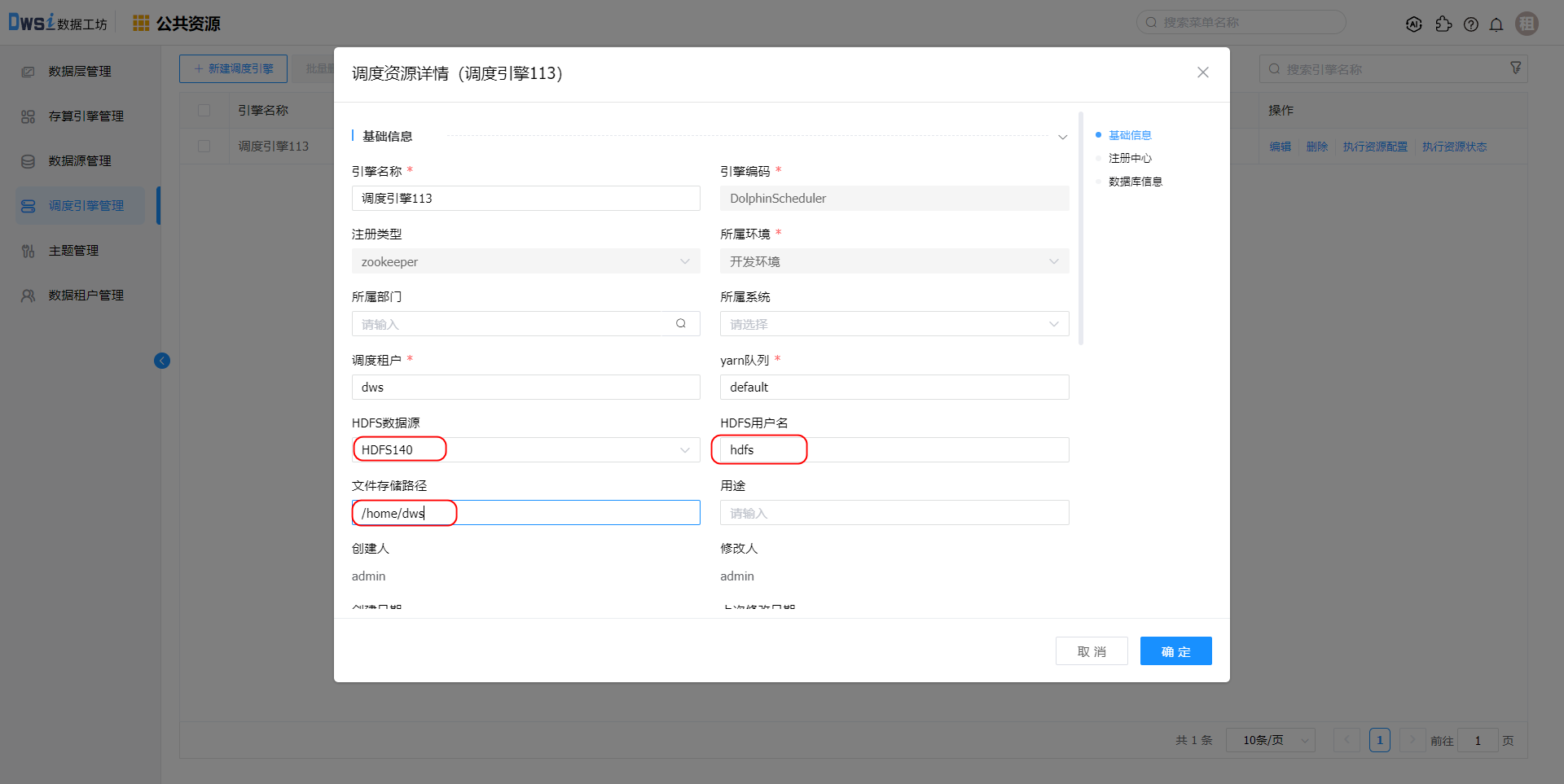
创建HDFS存算引擎及数据源

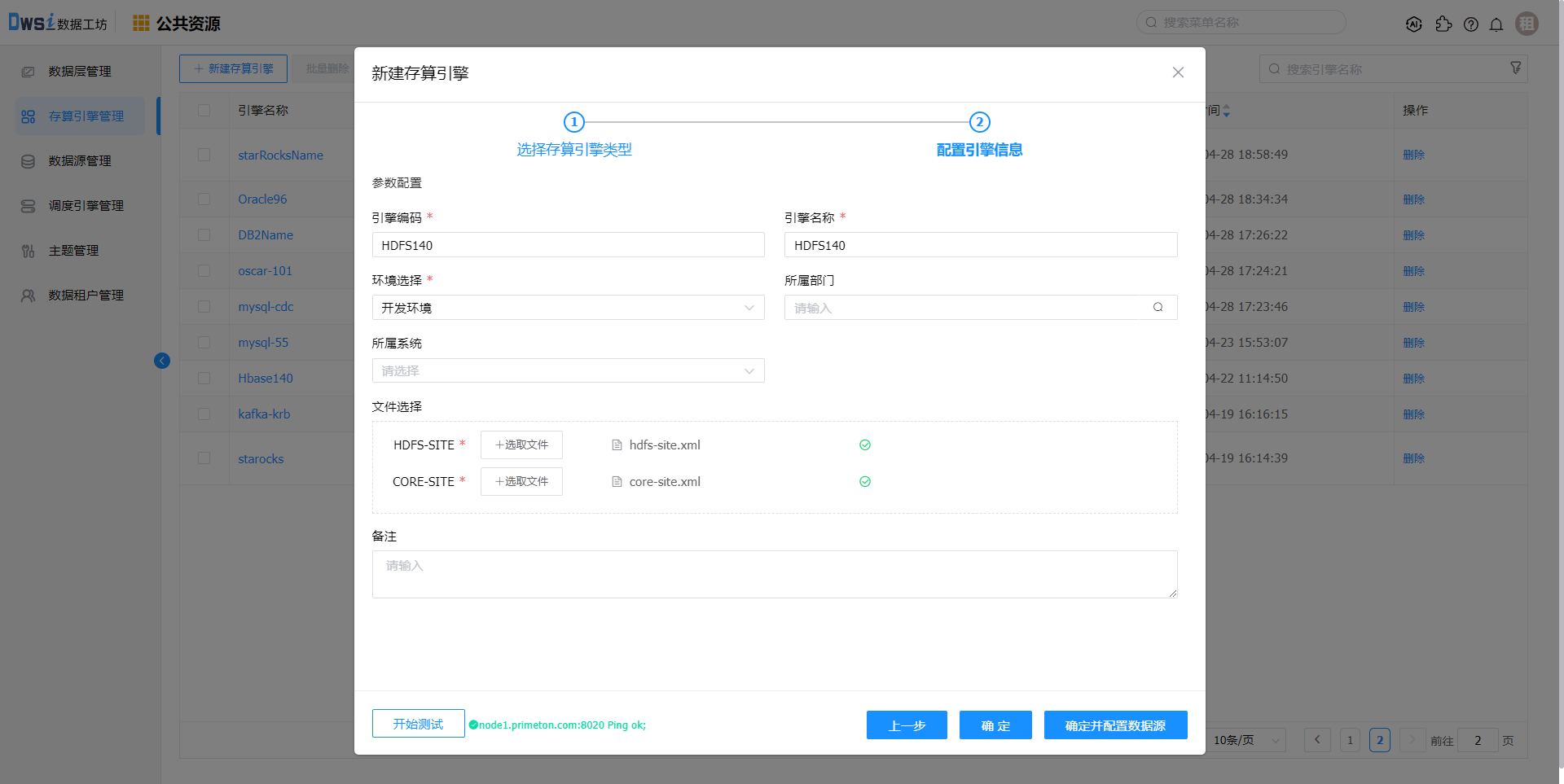
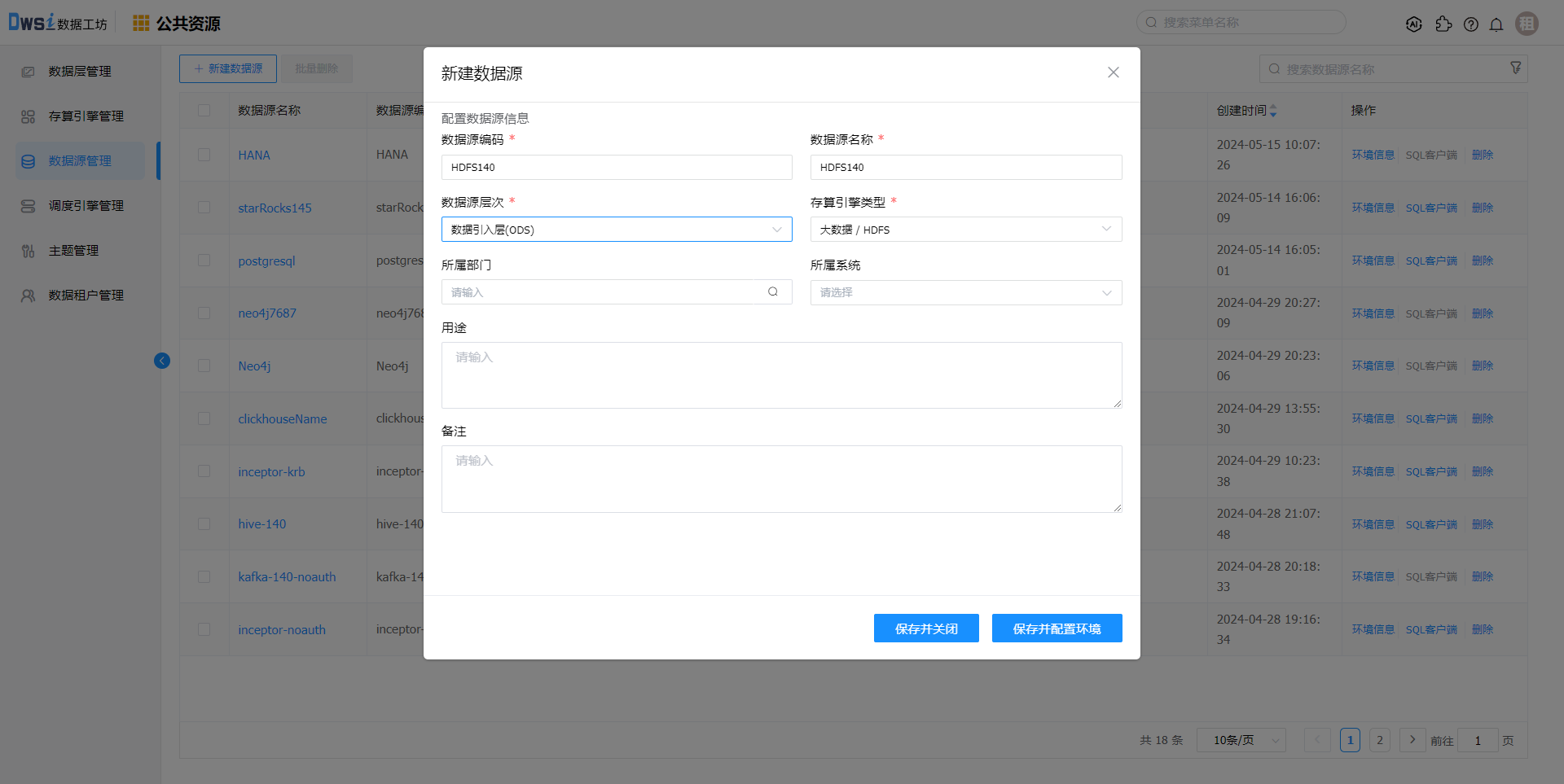
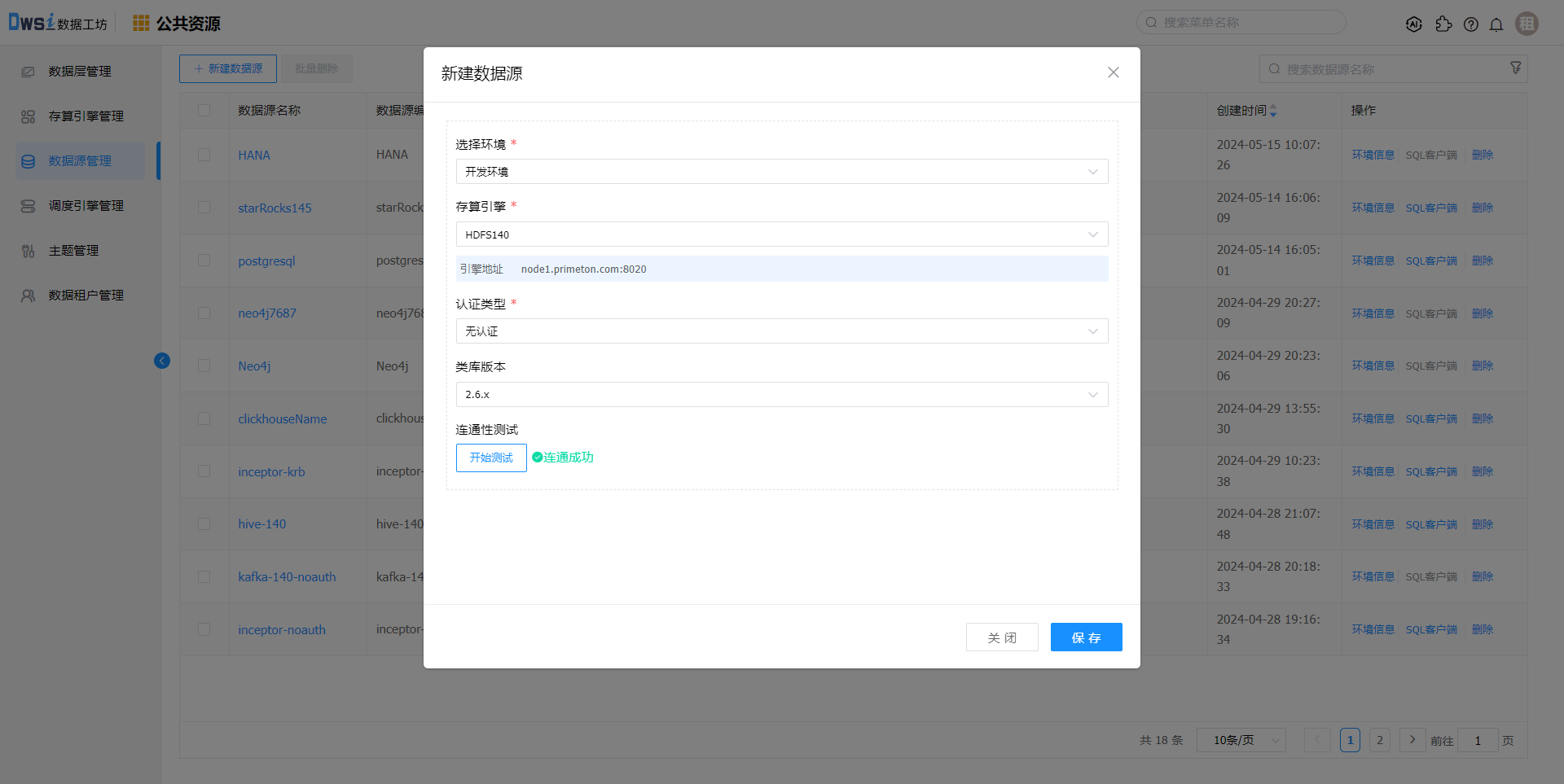
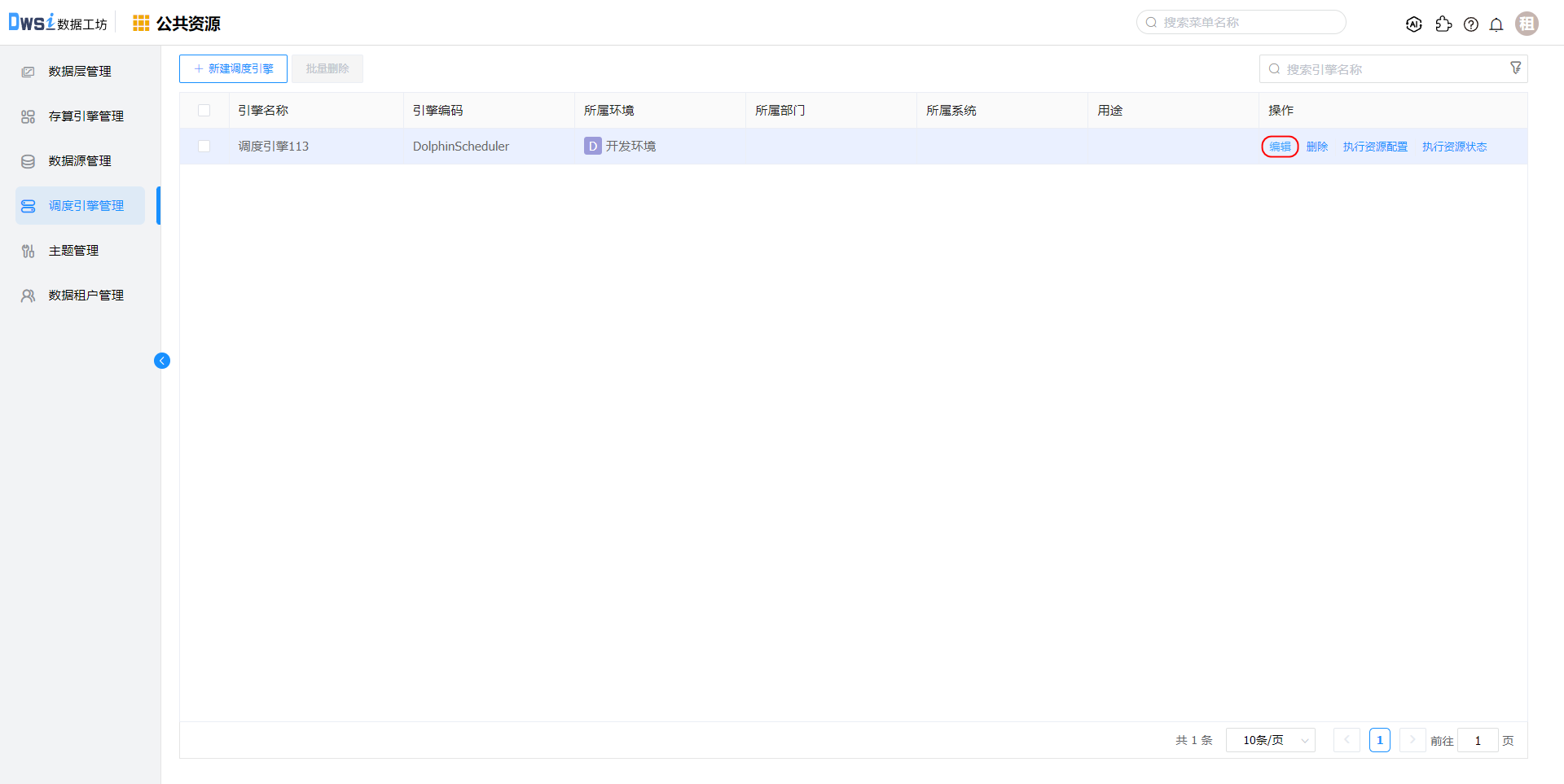
调度引擎关联HDFS数据源
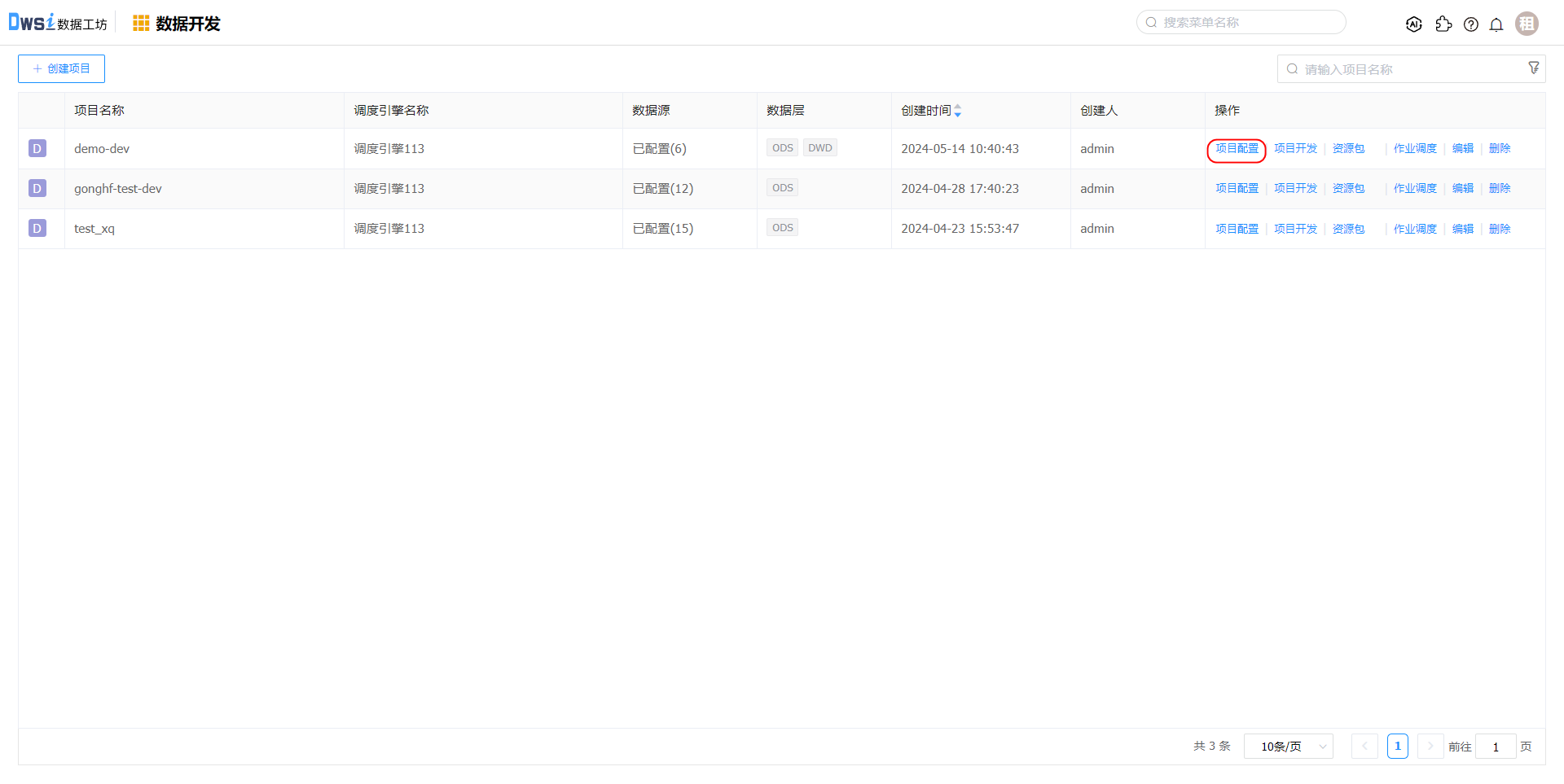
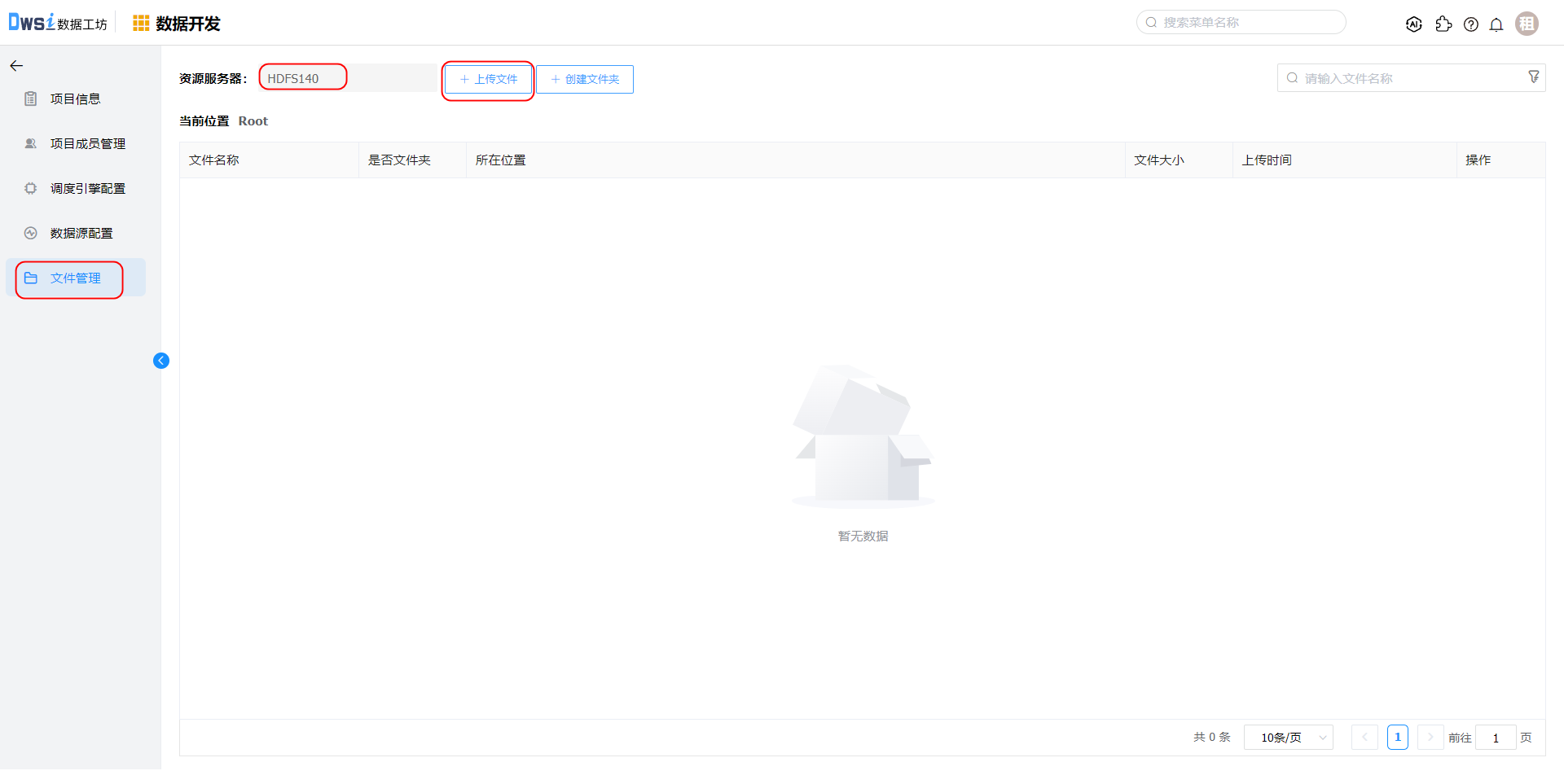
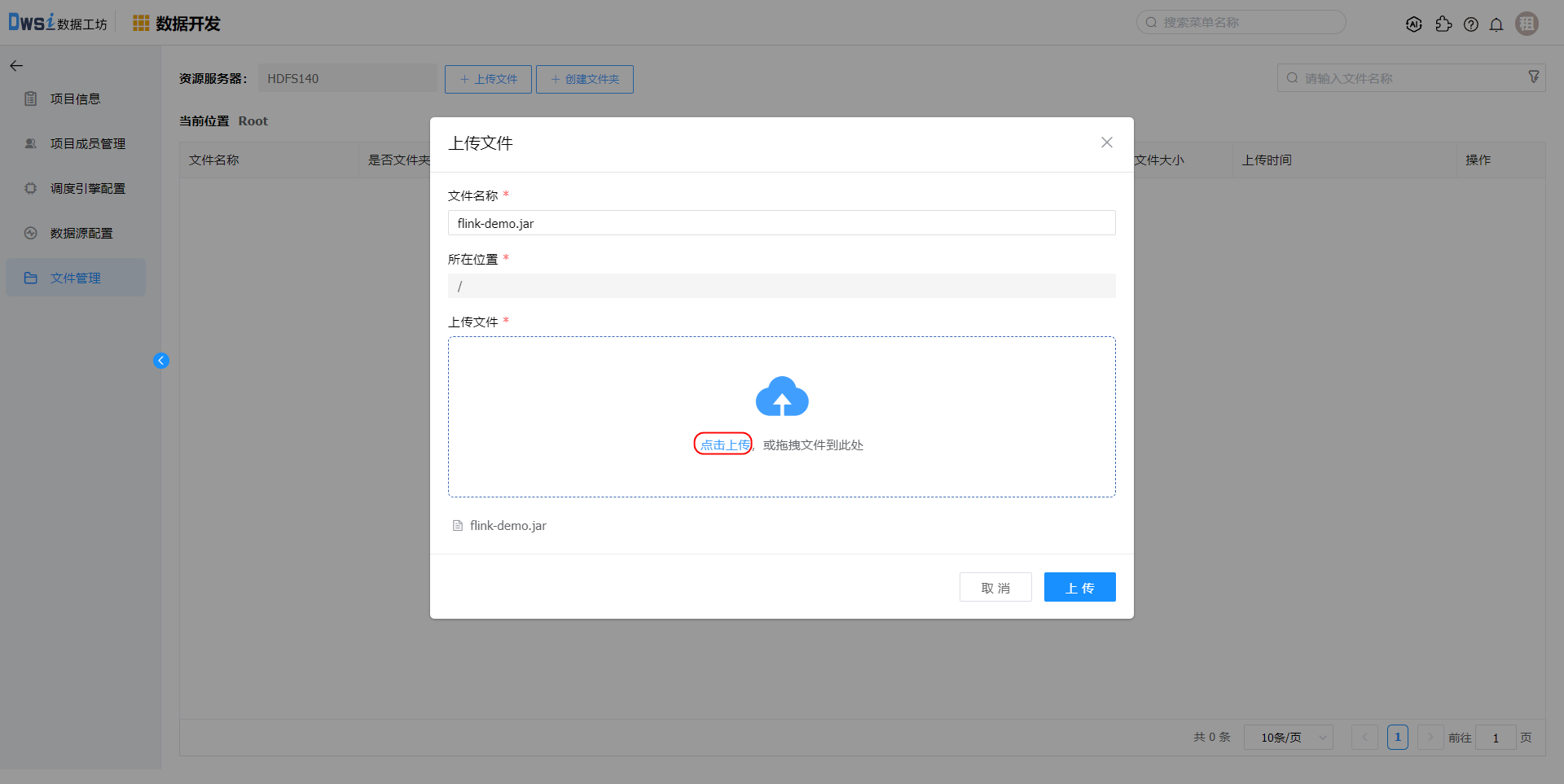
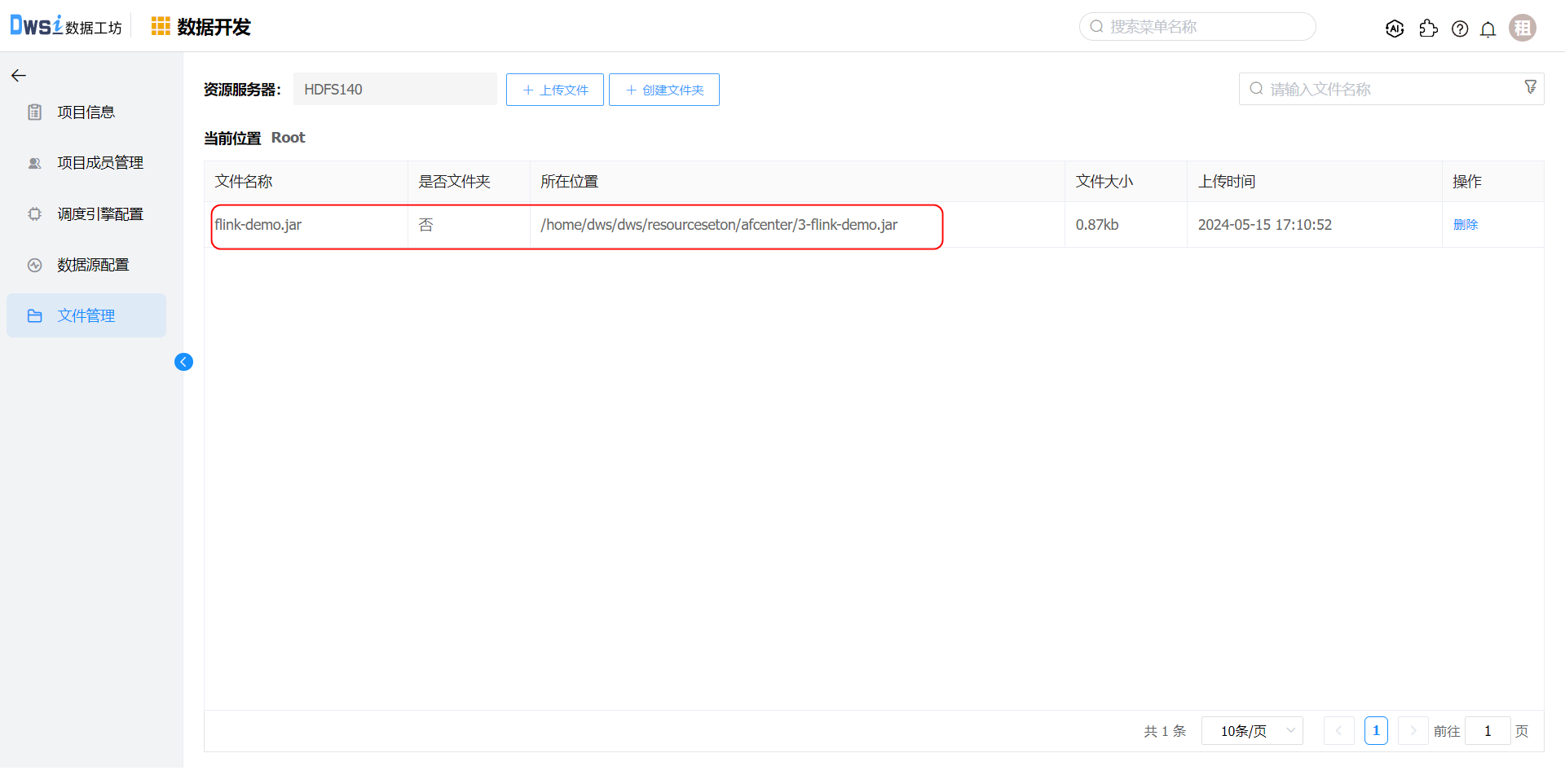
在项目开发菜单,点击项目的【项目配置】操作,在文件管理中上传待运行的jar文件。flink-demo.jar
# 新建Flink程序
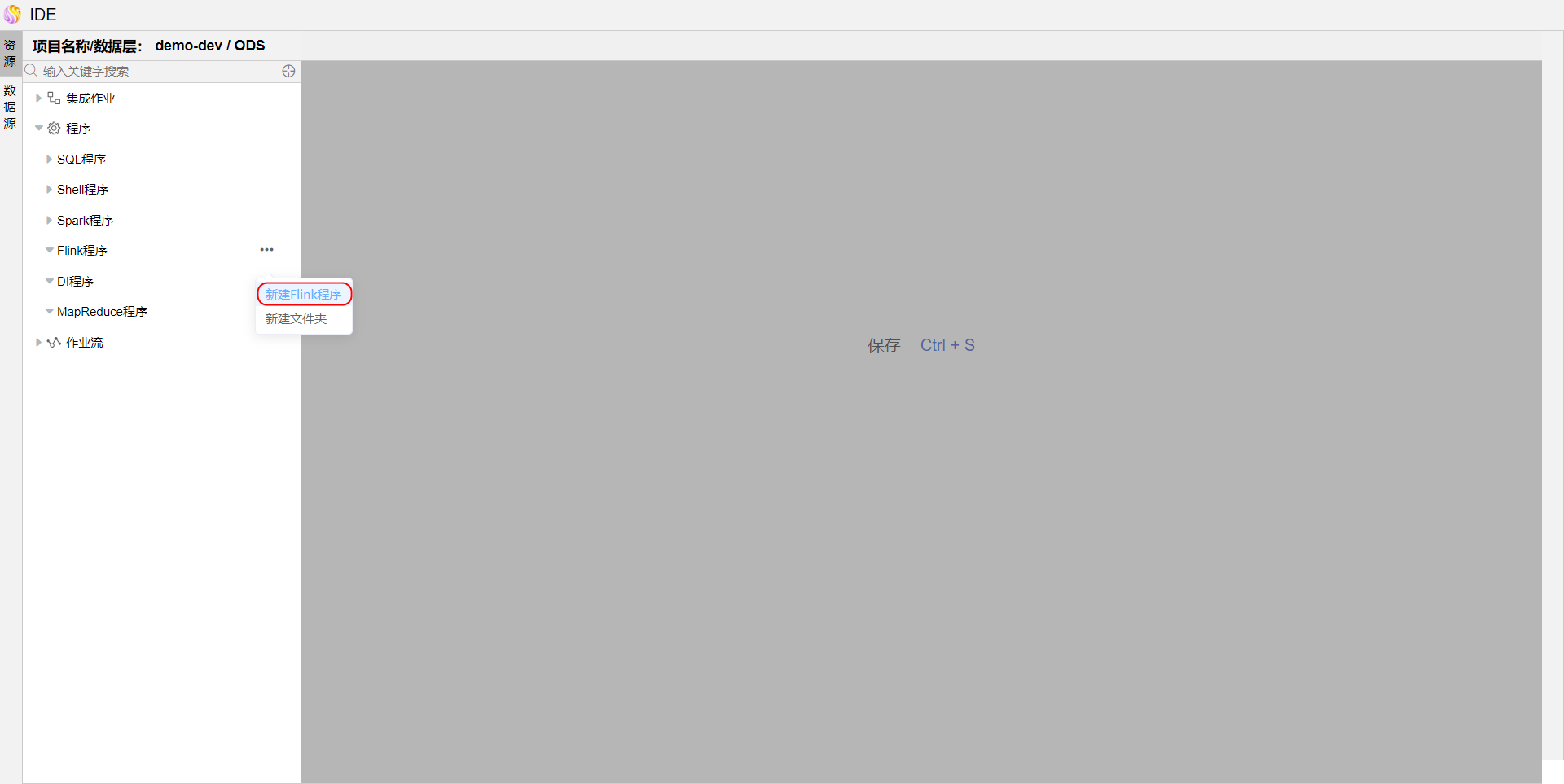
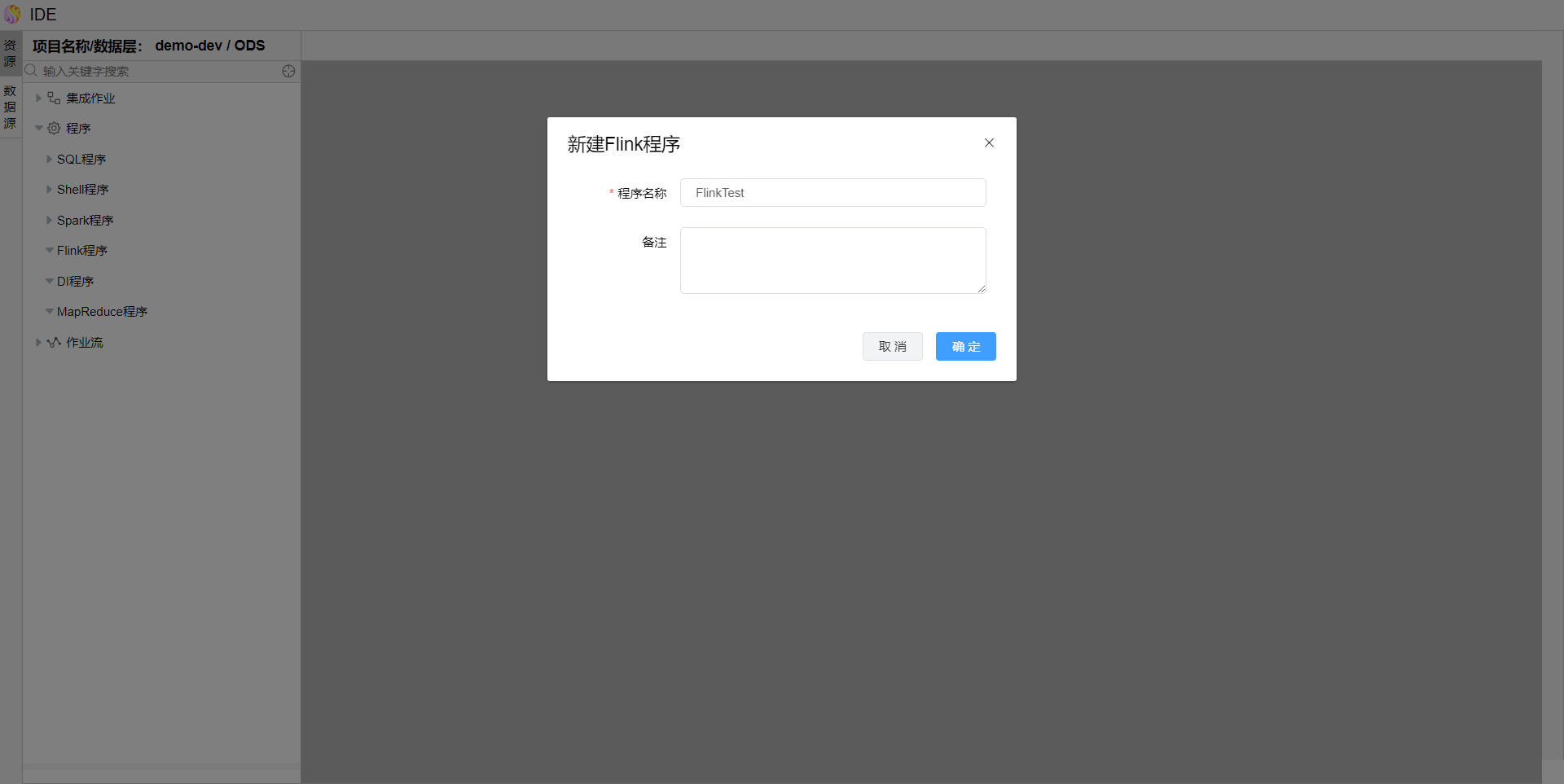
点击资源树"Flink程序"节点上的【...】,选择弹出菜单【新建Flink程序】,填写"程序名称",点击【确定】按钮。
# 配置Flink程序
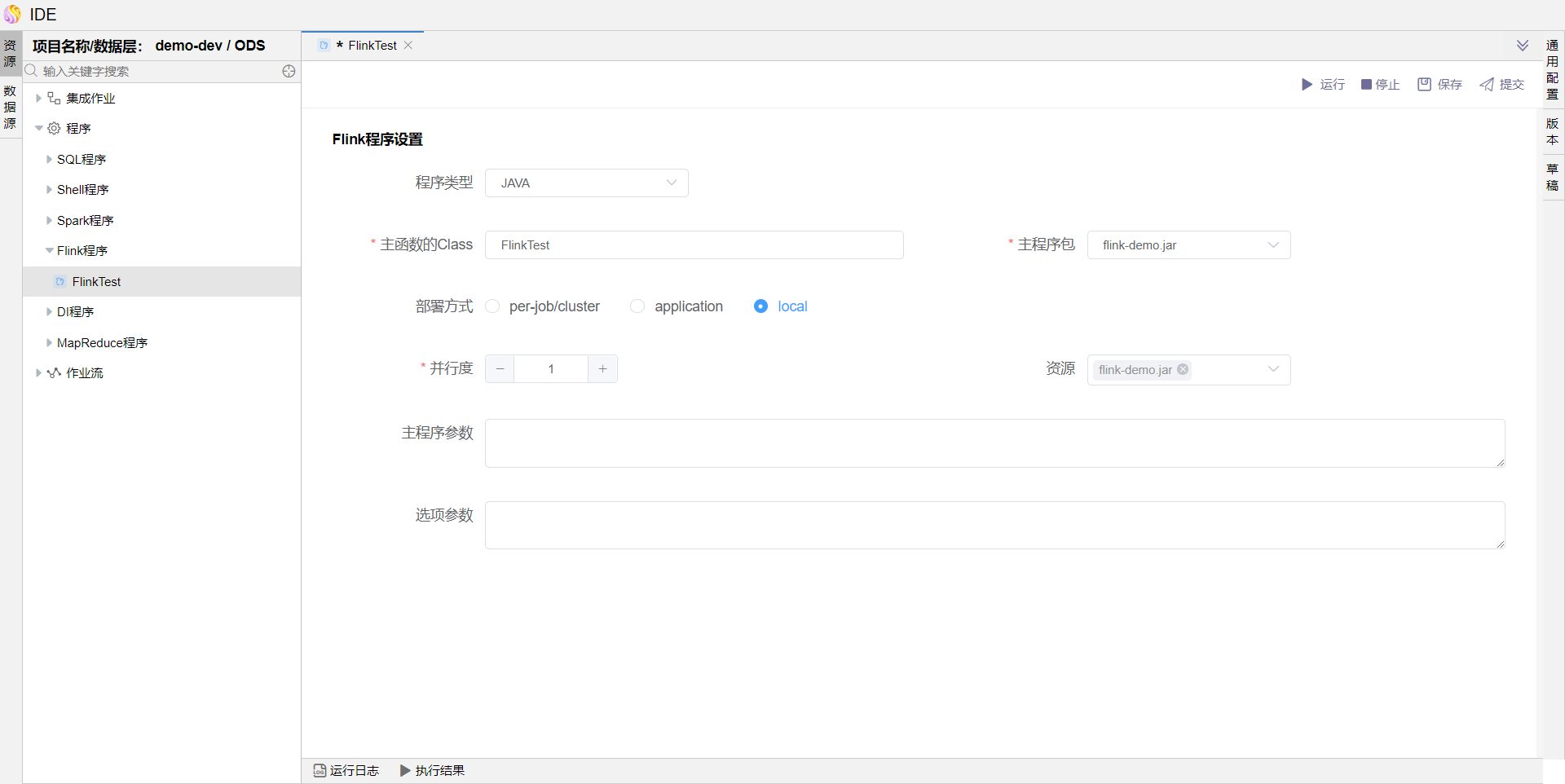
输入主函数的Class(本示例使用的jar中主函数为FlinkTest)、选择主程序包
# 通用配置
在通用配置中可以配置任务优先级、Worker 分组、本地参数、超时告警。 修改属性后请务必点击【确定】按钮。
# 保存草稿
如果所有组件属性都已设置完毕,点击【保存】按钮,可以看到保存过的历史草稿,并可以随意切换草稿。(草稿只保存最近 10 个)
可以参考示例关系型表数据同步示例 中的"保存草稿"说明。
# 运行
点击【运行】按钮,可以运行已经开发完毕的场景,在日志栏可以看运行日志及运行结果。
# 提交版本
当草稿运行正常后,点击【提交】按钮可以将该版本提交到作业调度,每次修改提交都会生成新的版本,可以看到提交的历史版本,并可以随意切换版本。
提交后的版本,可以在作业调度中进行"定时"调度配置。
可以参考示例关系型表数据同步示例 中的"提交版本"说明。