
# 输出组件
本章节详细说明输出组件的功能及属性,具体如下:
- 关系型数据库输出
- Hive输出
- Hbase输出
- 文本文件输出
- Excel输出
- XML输出
- JSON输出
- Kafka输出
- StarRocks输出
- ORC输出
- PARQUET输出
- 删除
- 选择/增删改
- 插入/更新
- 更新
# 关系型数据库输出
功能介绍:关系型数据库输出用于将数据写入关系型数据库表
使用场景:该组件相当于Sql insert,只用于向数据库表中插入数据
图标:

组件界面:

参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 选择输出数据源 |
| Schema | 下拉列表值为数据库schema值,当schema值为空时,下拉值为当前建立连接所用数据库名 |
| 目标表 | 指定结果输出表名称 |
| 提交记录数量 | 指定提交批处理的大小, 大小是在向数据库发送COMMIT命令之前要执行的INSERT语句的数量 |
| truncate表 | 每次操作前,先把目标表清空 |
| 指定数据库字段 | 指定需要插入字段,否则结果中全部字段都将进行插入操作 |
| 数据库字段 | 表字段: 最终输出的目标表中的列名 |
| 流字段: 数据源中的列名 |
# Hive输出
功能介绍:Hive输出用于将数据写入Hive表
使用场景:该组件相当于Sql insert,只用于向hive表中插入数据
图标:

组件界面:

参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 选择hive数据源 |
| Schema | 数据库名 |
| 目标表 | 指定结果输出表名称 |
| 提交记录数量 | 指定提交批处理的大小, 大小是在向数据库发送COMMIT命令之前要执行的INSERT语句的数量 |
| truncate表 | 每次操作前,先把目标表清空 |
| 指定数据库字段 | 指定需要插入字段,否则结果中全部字段都将进行插入操作 |
| 数据库字段 | 表字段: 最终输出的目标表中的列名 |
| 流字段: 数据源中的列名 |
# Hbase输出
功能介绍:Hbase输出用于将用户定义的列元数据写入HBase表
使用场景:该组件用于获取Hbase字段与输出流中字段映射,并结果写入Hbase表
图标:

组件界面:

参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 选择HBase数据源 |
| 表名 | HBase表名 |
| 映射名称 | 存储HBase表中需要映射的列信息的映射名称 |
| 保存映射 | 保存当前HBase表配置的列映射信息 |
| 删除映射 | 从映射表中删除当前HBase表所指定的映射 |
| 创建/编辑映射选项 | 别名:HBase表列别名,对于表键列是必需的,但对于非键列是可选的 |
| 键:指定该字段是否是表的键 | |
| 列名:HBase表列名 | |
| 列族: 字段在HBase表中所属的列族。非键列必须指定列族和列名 | |
|
类型:
列为键时,类型:String/Integer/UnsignedInteger/Long/UnsignedLong/Date/UnsignedDate/Binary
列非键时,类型:String/Integer/Long/Float/Double/Boolean/Date/BigNumber/Serializable/Binary
|
# 文本文件输出
功能介绍:文本文件输出用于将数据导出到文本文件。此步骤通常用于生成可由电子表格应用程序读取的逗号分隔值 (CSV) 文件,也可用于生成特定长度的文件
使用场景:该组件用于将结果输出到文本文件中
图标:

组件界面:



参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 文件名称 | 输出文件文件名 |
| 文件设置 | 创建父目录:勾选后将根据“文件名称”中的路径自动创建父目录 |
| 从字段中获取文件名:从前置步骤结果中获取字段作为文件名,下方将能够选择包含文件名字段 | |
| 扩展名:指定输出文件名的扩展名 | |
| 文件名设置 | 文件名包含日期:勾选此项,生成文件名会包含年、月、日 |
| 文件名包含时间:勾选此项,生成文件名会包含时、分、秒 | |
| 预览文件名:获取将输出文件名格式 | |
| 是否添加文件名到结果 | 勾选此项,可把转换的结果文件名存进流中,使其可以在后续步骤中被获取 |
| 分隔符 | 指定在文本中分隔字段的字符,例如;或者制表符 |
| 编码方式 | 指定文件使用的编码 |
| 格式 | DOS或者UNIX。UNIX 文件行分隔符是换行符。DOS 文件可以是换行符或者回车符 |
| 压缩格式 | 指定压缩的类型 |
| 行分割数据 | 根据指定行数对结果数据进行行分割输出 |
| 追加方式 | 是否在指定的文件最后追加行 |
| 添加头部行 | 勾选后选用第一行数据作为头部,例如:CSV |
| 内容字段 | 名称:设置要在输出流中显示的字段名称 |
| 内容:字段类型 | |
| 格式:控制输入数据的格式 | |
| 长度:
对于Number:有效数的数量
对于String:字符的长度
对于Date:打印输出字符的长度(例如4 代表返回年份)
| |
| 精度:只对number有效,为浮点数保留位置 |
# Excel输出
功能介绍:Excel输出用于将来自 PDI 的传入行写入 Excel 文件,并支持.xls和.xlsx文件格式。.xls文件使用更适合简单内容的二进制格式,而. xlsx文件使用 Open XML 格式。
使用场景:该组件用于将结果输出到excel中
图标:

组件界面:



参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 文件名称 | 输出文件文件名 |
| 扩展名 | 指定输出excle文件扩展名 |
| 文件名设置 | 文件名包含日期:勾选此项,生成文件名会包含年、月、日 |
| 文件名包含时间:勾选此项,生成文件名会包含时、分、秒 | |
| 预览文件名:获取将输出文件名格式 | |
| 文件已存在 | 对指定文件名进行覆盖或者追加 |
| 在接收数据前不创建文件 | 勾选此项,完成此步骤后,再创建输出文件。当数据流中没有行时,这可以避免创建空文件 |
| 结果中添加文件名 | 勾选此项,可把转换的结果文件名存进流中,使其可以在后续步骤中被获取 |
| 行分割数据 | 根据指定行数对结果数据进行行分割输出 |
| 工作表名 | Excel中的Sheet名称 |
| 设为活动表 | 将当前工作表名对应工作表设为活动表 |
| 保护设置 | 勾选此项,使用密码保护工作表,必须在“保护密码”字段中指定密码 |
| 保护人:工作表账号 | |
| 保护密码:工作表密码 | |
| 内容配置 | 开始输出单元格:指定开始写入的单元格 |
| 输出表头:勾选此项,使用输出结果第一行作为表头 | |
| 自动调整列大小:勾选此项,根据内容自适应列宽 | |
| 内容字段 | 名称:输出字段名称 |
| 类型:输出数据类型 | |
| 格式:根据指定格式化类型对结果进行格式化 |
# XML输出
功能介绍:XML输出用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。
Xml是标准通用标记语言(SGML)的子集,非常适合Web传输。XML提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。
使用场景:该组件用于将结果输出到xml文件中
图标:

组件界面:


参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 文件名称 | 输出文件文件名 |
| 启动时不创建文件 | 勾选此项,当没有行被处理时,使能够避免空文件 |
| 扩展名 | 指定输出文件扩展名 |
| 文件名设置 | 文件名包含日期:勾选此项,生成文件名会包含年、月、日 |
| 文件名包含时间:勾选此项,生成文件名会包含时、分、秒 | |
| 预览文件名:获取将输出文件名格式 | |
| 结果中添加文件名:勾选此项,可把转换的结果文件名存进流中,使其可以在后续步骤中被获取 | |
| 编码方式 | 指定要使用的编码 |
| 命名空间 | 指定xml命名空间 |
| 根元素名称 | XML文档中根元素的名称 |
| 子元素名称 | 要在XML文档中使用的行元素的名称 |
| 行分割数据 | 根据指定行数对结果数据进行行分割输出 |
| 是否压缩为zip | 勾选此项,将xml压缩为zip文件 |
| 忽略输入到XML文件的null值 | 勾选此项,将忽略输出到xml的数据中的null值 |
| 字段 | 名称:输出字段名称 |
| 元素名称:XML文件中要使用的元素的名称 | |
| Content type:指定字段是元素节点还是属性节点 | |
| 类型:指定字段的类型 | |
| 格式:选择格式 | |
| 长度:指定字段的长度 | |
| 精度:为数字类型字段指定浮点数保留位数 |
# JSON输出
功能介绍:JSON输出允许基于输入步骤值生成Json块。根据步骤设置,输出json将作为java脚本数组或java脚本对象可用
使用场景:该组件用于将结果输出到JSON中
图标:

组件界面:


参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 输出方式 |
写入文件:结果只写入json文件
输出值:结果只输出到流里
输出值并写入文件:是即输出到js文件又输出到值里
|
| Json条目名称 | 最终保存json数据的名称 |
| 分割数据行数 | 根据指定行数对结果数据进行行分割输出 |
| 输出值 | 输出到流里的字段名称 |
| 兼容模式 | kettle版本的兼容 |
| 文件名称 | 输出文件文件名 |
| 追加方式 | 勾选此项,以追加方式输出到文件 |
| 创建父文件夹 | 勾选此项,根据文件路径创建不存在的上级文件夹 |
| 启动时不创建文件夹 | 勾选此项,转换启动时不创建文件,输出结果为空时不创建文件,避免创建空文件 |
| 扩展名 | 输出文件扩展名 |
| 文件名设置 | 文件名包含日期:勾选此项,生成文件名会包含年、月、日 |
| 文件名包含时间:勾选此项,生成文件名会包含时、分、秒 | |
| 预览文件名:获取将输出文件名格式 | |
| 结果中添加文件名:勾选此项,可把转换的结果文件名存进流中,使其可以在后续步骤中被获取 | |
| 字段 | 名称:输出结果流中字段名称 |
| 元素名称:结果流中字段输出到json文件中对应字段名称 |
# Kafka 输出
功能介绍:Kafka 输出组件用于将数据写入 Kafka 主题。
使用场景: 将数据写入 Kafka 主题。
图元:
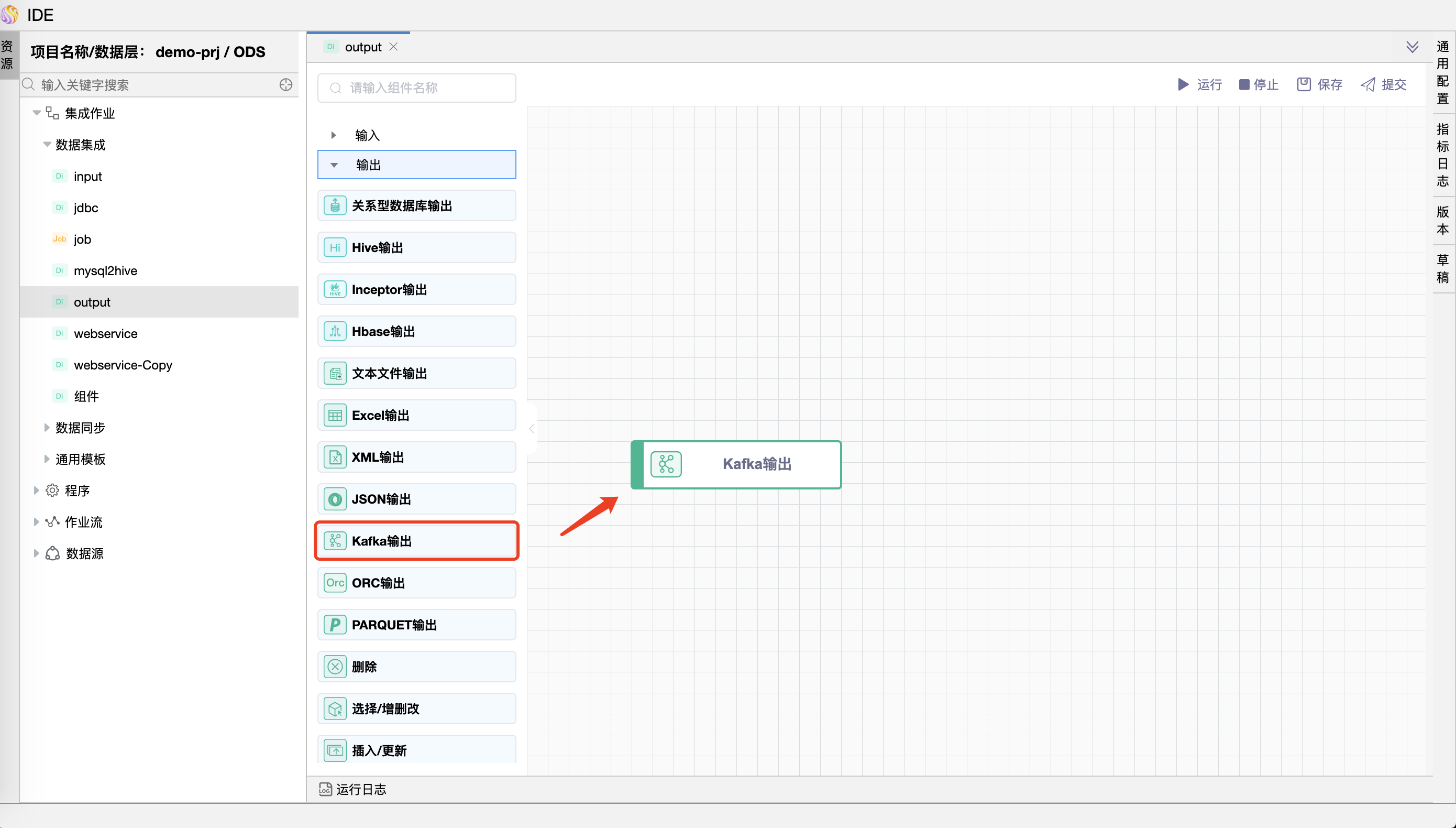
组件界面:
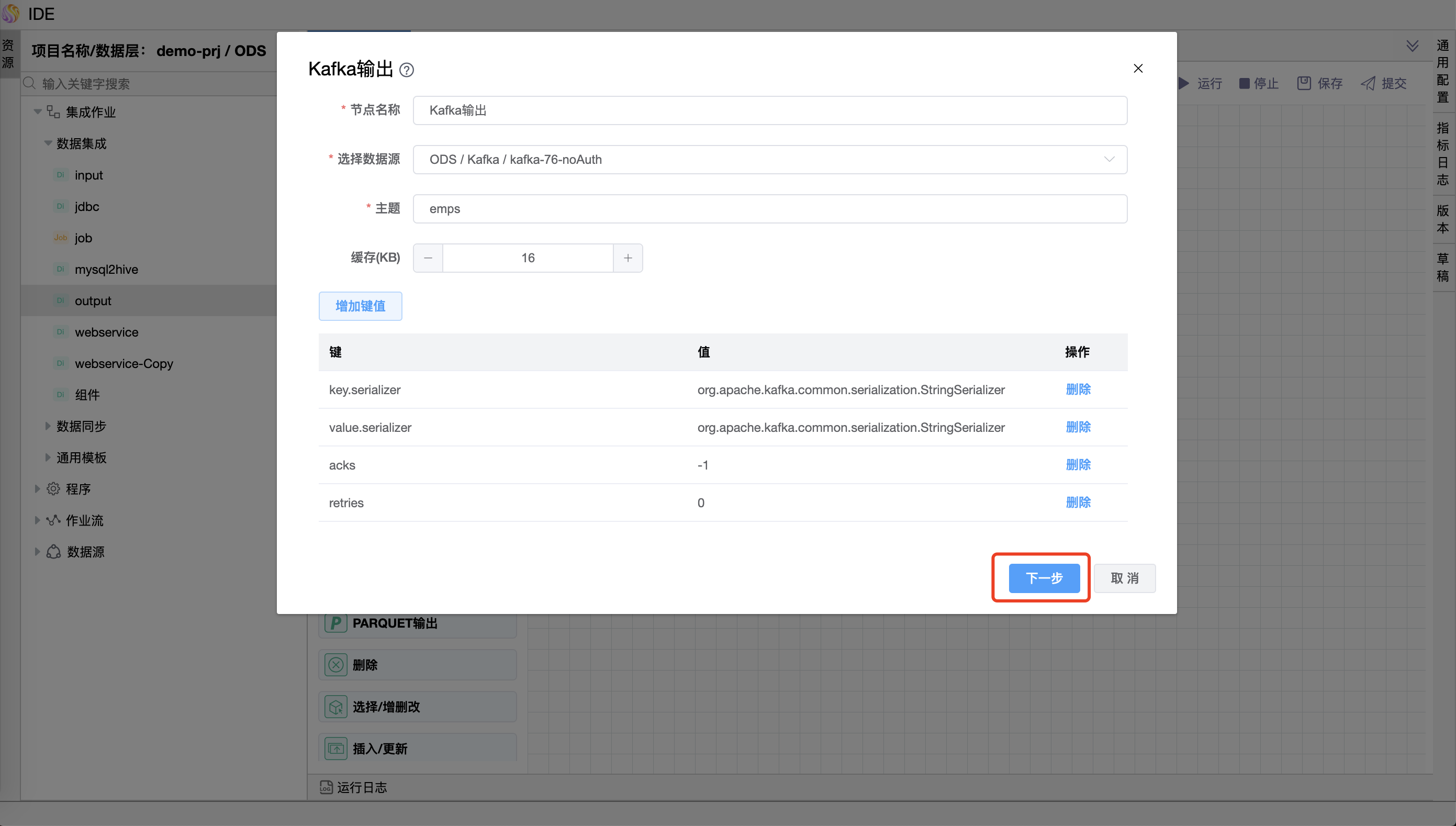
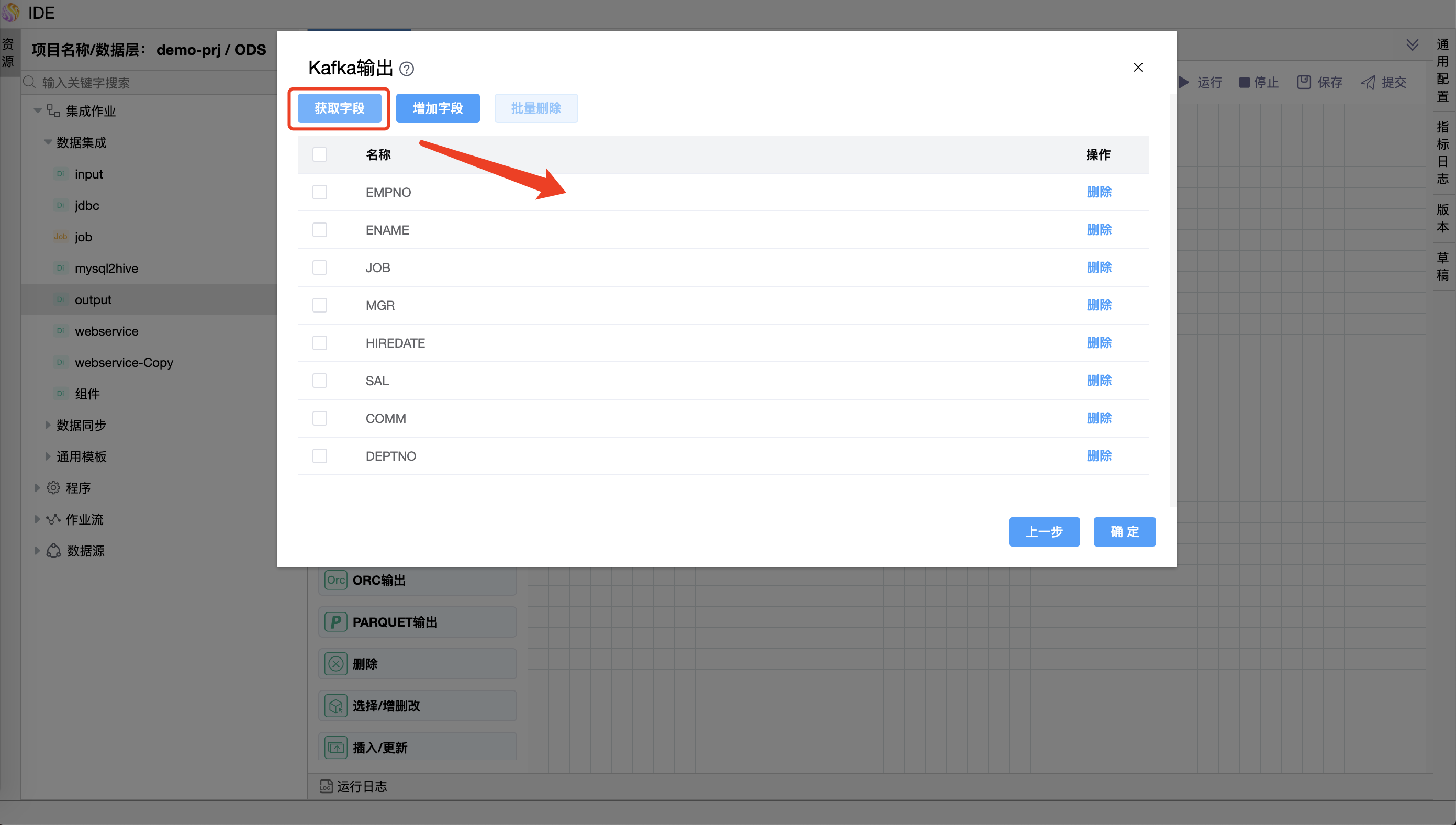
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(Kafka)的数据源进行选择。 |
| topic | Kafka 主题名称。 |
| 缓存(KB) | 一次性读取消息的缓存大小。 |
| 键 | 更多属性的名称。 |
| 值 | 对应键的值。 |
# StarRocks 输出
功能介绍:StarRocks 输出组件用于向StarRocks数据源写入数据。
图标:

组件界面:
【基础信息配置】

【内容规则配置】

 *注意:“是否支持部分导入”选择“是”时,以下“字段设置”中才允许“删除”操作,反之不允许。
*注意:“是否支持部分导入”选择“是”时,以下“字段设置”中才允许“删除”操作,反之不允许。
【字段设置】
- 获取字段

- 字段映射(通过在来自数据源目标表与来自上级节点的字段集中选择字段,来手动配置字段映射)



参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(StarRocks)的数据源进行选择。 |
| 库名称 | 选定的来源库。 |
| 表名称 | 选定的来源表。 |
| 格式 | 使用什么格式导入数据,可选“CSV”或“JSON” 。 |
| 列分隔符 | CSV导入列分隔符。(格式为“CSV”时需配置) 使用StreamLoad CSV导入,此处可配置CSV导入列分隔符,默认\t,如使用默认值请不要在此显式指定。如果您的数据中本身包含\t,则需自定义使用其他字符作为分隔符。 |
| 单次最大导入 | 对于批处理写入,当缓冲区达到最大导入数时,数据将被刷新到 StarRocks 中。 |
| 刷新频率 | 刷新失败的重试次数。 |
| StarRocks 连接超时时间 | 在尝试重试StarRocks请求之前等待的时间。 |
| Stream Load | 流加载模式的参数。StarRocks sink连接器的内部实现是通过流加载批量缓存和导入的。 |
| 仅支持主键表更新 | 选择“是”时,“字段设置”中才允许“删除”操作,反之不允许。 |
| 是否支持更新和删除 | 是否启用upsert/delete,只支持PrimaryKey模式。 |
| 字段设置 | 表字段:根据选择的数据源及目标表,展示输出数据。 流字段: 根据上游的输入组件的输出字段,展示输入字段。 |
# ORC输出
功能介绍: ORC输出步骤将PDI数据流中的数据串行化为ORC文件格式,然后将其写入文件。ORC是一种用于快速列式存储的数据格式。此步骤创建一个文件,该文件包含ORC格式的输出数据。写入ORC输出文件的字段由输入字段定义。未写入输出文件的字段将被删除,或使用备用字段名或默认值写入输出文件。
使用场景: 该组件用于将数据输出成Orc格式,常用于输出到Hive Orc格式表。
图标:

组件界面:

参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线 |
| 选择类型 | 可选择“HDFS”类型或“LOCAL”类型。 |
| 文件目录 | 读取数据的文件/目录来源。 |
| 文件名称 | ORC文件要输出的路径及ORC文件名 |
| ORC字段名 | 显示在ORC数据文件中的字段名称 |
| 字段名称 | 指定PDI字段的名称 |
| ORC类型 | 数据类型 |
# PARQUET输出
功能介绍: PARQUET输出步骤将PDI字段映射到数据文件中的字段,并选择要处理这些文件的位置,例如在 HDFS 上。
使用场景: 该组件用于将数据输出成Parquet格式。此步骤创建一个文件,该文件包含Parquet格式的输出数据。写入Parquet输出文件的字段由输入字段定义。未写入输出文件的字段将被删除,或使用备用字段名或默认值写入输出文件。
图标:

组件界面:


先指定字段来源(支持Hive、Inceptor数据源类型),在字段列表中,可为要导出的字段定义属性。
可以手动添加字段,也可以“获取字段”来填充字段。当检索字段时,PDI类型将转换为适当的Parquet类型。
配置项:
 在“配置项”选项卡中,您可以为文件输出定义属性。
在“配置项”选项卡中,您可以为文件输出定义属性。
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线 |
| 选择类型 | 可选择“HDFS”类型、“LOCAL”或“DATASOURCE”类型。 |
| 文件目录 | 读取数据的文件/目录来源。 |
| 文件名称 | Parquet文件要输出的路径及Parquet文件名 |
| 字段列表 | Parquet字段名:显示在Parquet数据文件中的字段名称。 字段名称:指定PDI字段的名称。 Parquet类型:指定用于在Parquet文件中存储数据的数据类型。 精度:指定数字中有效数字的总数(仅适用于Decimal Parquet类型)。缺省值为20。 范围:指定小数点后的位数(仅适用于decimal Parquet类型)。缺省值为10。 默认值:如果字段为空或空,请指定该字段的默认值。 是否可以为null:指定字段是否可以包含空值。 【注意】为了避免转换失败,请确保默认值字段包含在“是否可以为 null”设置为No条件下的所有字段的值。 |
| 配置项 | 压缩算法:指定用于压缩Parquet输出文件的编解码器。 版本:指定要使用的Parquet版本。 文件扩展名:选择输出文件的扩展名。缺省值为parquet。 行组大小:指定行的组大小。缺省值为 0。 页大小:指定数据的页面大小。 启用字典编码:指定字典编码,它构建列中遇到的值的字典。列的数据页之前,首先写入字典页。请注意,如果字典的大小大于Page大小(无论是大小还是不同值的数量),则编码方法将恢复为普通编码类型。 字段页大小:使用字典编码时指定页面大小。默认值为 1024。 文件名是否包含日期:在文件名中添加系统日期。 文件名包含时间:将系统时间添加到文件名中。 指定日期掩码:指定日期和时间格式。 |
# 删除
功能介绍:删除用于从数据库中永久删除一行,以便您可以清除数据。选择一个字段与另一个步骤中传入字段的值进行比较。当满足比较要求时,将删除数据库行。如果有多行匹配,那么所有具有该值的行都将从数据库中删除
使用场景:该组件用于根据指定条件删除数据库表中数据
图标:

组件界面:

参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 指定数据源 |
| Schema | 下拉列表值为数据库schema值,当schema值为空时,下拉值为当前建立连接所用数据库名 |
| 目标表 | 指定转换操作表名称 |
| 提交记录数量 | 提交之前要改变的行数 |
| 查询值关键字段 | 表字段:表中字段 |
| 比较符:表中字段数据与流中数据比较条件 | |
| 流字段1:当比较符不为IS NULL/IS NOT NULL时,此值不能为空,该字段值为前置步骤输出流中值 | |
| 流字段2:当比较符为BETWEEN时,此值不能为空,该字段值为前置步骤输出流中值 |
# 选择/增删改
功能介绍:选择/增删改用于对数据库中表的数据进行插入、删除、更新操作
使用场景:该组件用于根据指定条件对数据库表进行插入、更新、删除
图标:

组件界面:


参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| Switch字段名 | 勾选是时,switch字段值对case值使用equals进行比较 勾选否时,switch字段值对case值使用contains进行比较 |
| Case值数据类型 | case值类型 |
| Case值 | 新增:勾选此项,并填写响应的case值,switch值与case值比较为true时,进行新增操作 |
| 修改:勾选此项,并填写响应的case值,switch值与case值比较为true时,进行新增修改 | |
| 删除:勾选此项,并填写响应的case值,switch值与case值比较为true时,进行新增删除 | |
| 选择数据源 | 指定数据源 |
| Schema | 下拉列表值为数据库schema值,当schema值为空时,下拉值为当前建立连接所用数据库名 |
| 目标表 | 指定转换操作表名称 |
| 提交记录数量 | 批量提交行数 |
| 使用批量插入 | 使用批量提交,一次提交量根据提交记录数量确定 |
| 跳过查找 | 跳过查找,直接更新所选字段 |
| 忽略查询失败 | 勾选此选项,忽略更新错误 并添加标志字段,该指定的标志字段,将会添加在每行输出结果的末尾,值为boolen,用于表示该条更新是否成功 |
| 查询值关键字段 | 表字段:表中字段 |
| 比较符:表中字段数据与流中数据比较条件 | |
| 流字段1:当比较符不为IS NULL/IS NOT NULL时,此值不能为空,该字段值为前置步骤输出流中值 | |
| 流字段2:当比较符为BETWEEN时,此值不能为空,该字段值为前置步骤输出流中值 | |
| 更新字段 | 表字段:表中字段 |
| 流字段1:前置组件结果流中对应字段 |
# 插入/更新
功能介绍:插入/更新用于数据库表的插入、更新操作。首先使用一个或多个查找键查找表中的一行。如果找不到该行,则插入该行。如果可以找到它,并且要更新的字段相同,则什么也不做。如果它们不完全相同,则更新表中的行。
使用场景:该组件用于根据指定条件对数据库表进行插入、更新
图标:

组件界面:

参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 指定数据源 |
| Schema | 下拉列表值为数据库schema值,当schema值为空时,下拉值为当前建立连接所用数据库名 |
| 目标表 | 指定转换操作表名称 |
| 提交记录数量 | 批量提交行数 |
| 仅执行插入数据 | 勾选此项,对所有结果流中数据只进行插入操作 |
| 查询值关键字段 | 表字段:表中字段 |
| 比较符:表中字段数据与流中数据比较条件 | |
| 流字段1:当比较符不为IS NULL/IS NOT NULL时,此值不能为空,该字段值为前置步骤输出流中值 | |
| 流字段2:当比较符为BETWEEN时,此值不能为空,该字段值为前置步骤输出流中值 | |
| 更新字段 | 表字段:表中字段 |
| 流字段1:前置组件结果流中对应字段 | |
| 更新:是否进行更新操作 |
# 更新
功能介绍:更新类似于插入-更新组件,不同之处在于只执行更新,不执行任何插入。
使用场景:该组件用于根据指定条件对数据库表进行更新
图标:

组件界面:

参数说明:
| 参数 | 说明 |
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 指定数据源 |
| Schema | 下拉列表值为数据库schema值,当schema值为空时,下拉值为当前建立连接所用数据库名 |
| 目标表 | 指定转换操作表名称 |
| 提交记录数量 | 批量提交行数 |
| 使用批量更新 | 使用批量提交,一次提交量根据提交记录数量确定 |
| 跳过查询 | 跳过查找,直接更新所选字段 |
| 忽略查询失败 | 勾选此选项,忽略更新错误 并添加标志字段,该指定的标志字段,将会添加在每行输出结果的末尾,值为boolen,用于表示该条更新是否成功 |
| 查询值关键字段 | 表字段:表中字段 |
| 比较符:表中字段数据与流中数据比较条件 | |
| 流字段1:当比较符不为IS NULL/IS NOT NULL时,此值不能为空,该字段值为前置步骤输出流中值 | |
| 流字段2:当比较符为BETWEEN时,此值不能为空,该字段值为前置步骤输出流中值 | |
| 更新字段 | 表字段:表中字段 |
| 流字段1:前置组件结果流中对应字段 |