
# 输入组件
本章节详细说明输入组件的功能及属性,具体如下:
- 关系型数据库输入
- Hive 输入
- HBase 输入
- 文本文件输入
- CSV 文件输入
- Excel 输入
- XML 输入
- JSON 输入
- Kafka 输入
- 生成记录
- 生成随机数
- 获取系统信息
- 获取表名
- 获取文件名
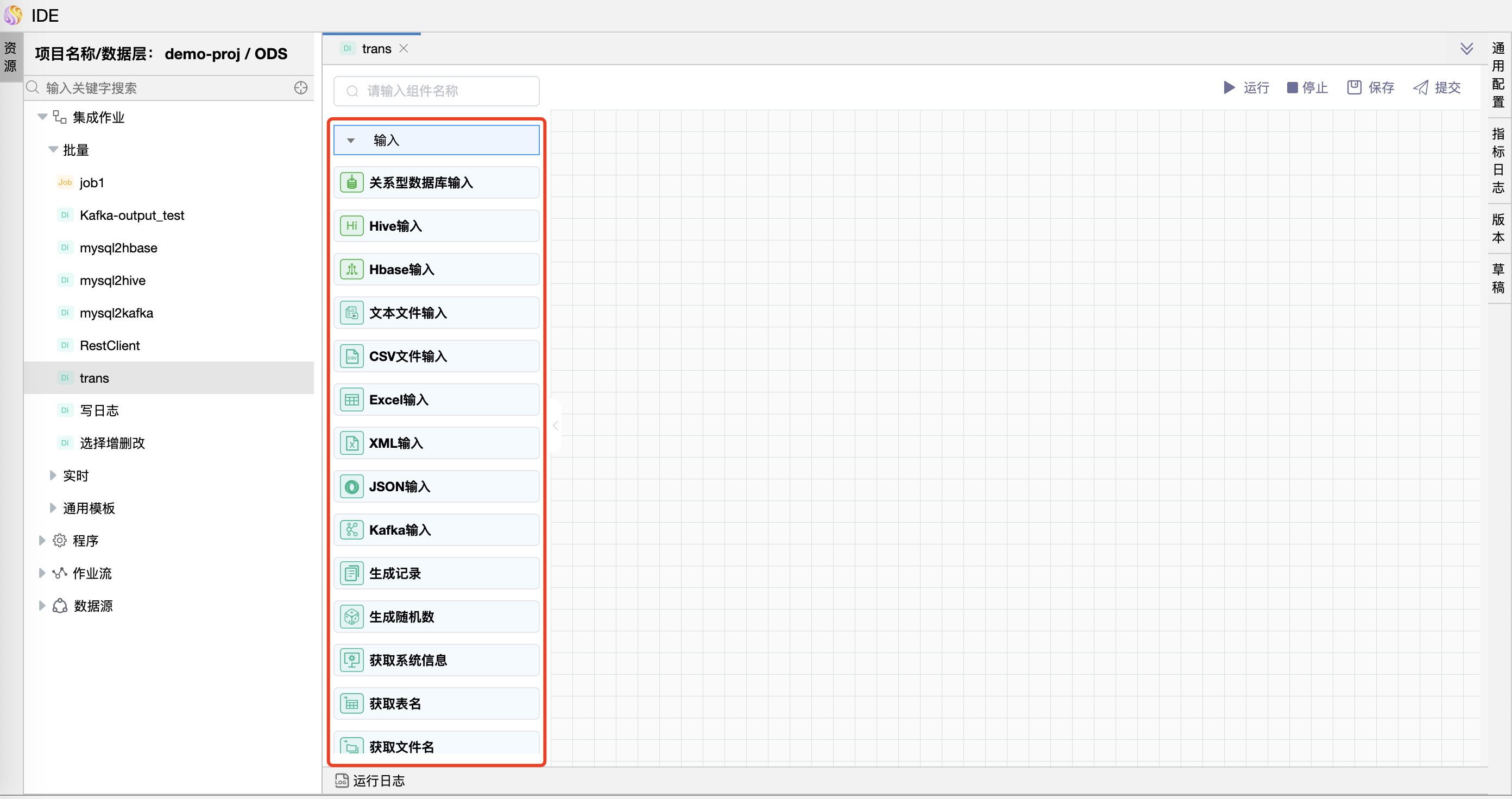
# 关系型数据库输入
功能介绍:关系型数据库输入组件用于利用 SQL 查询关系型数据库表,从关系型数据库中读取表数据。
图元:
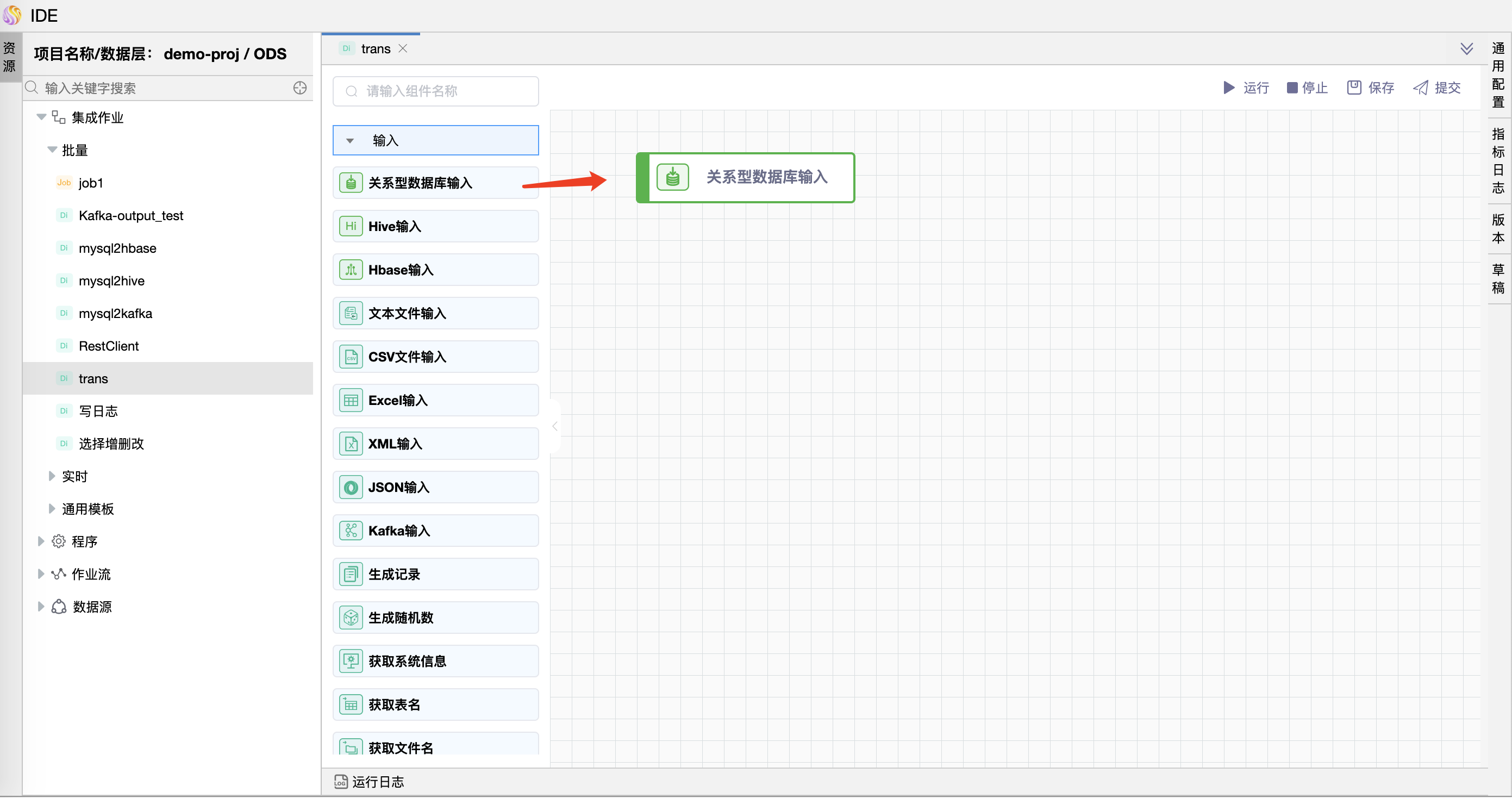
组件界面:
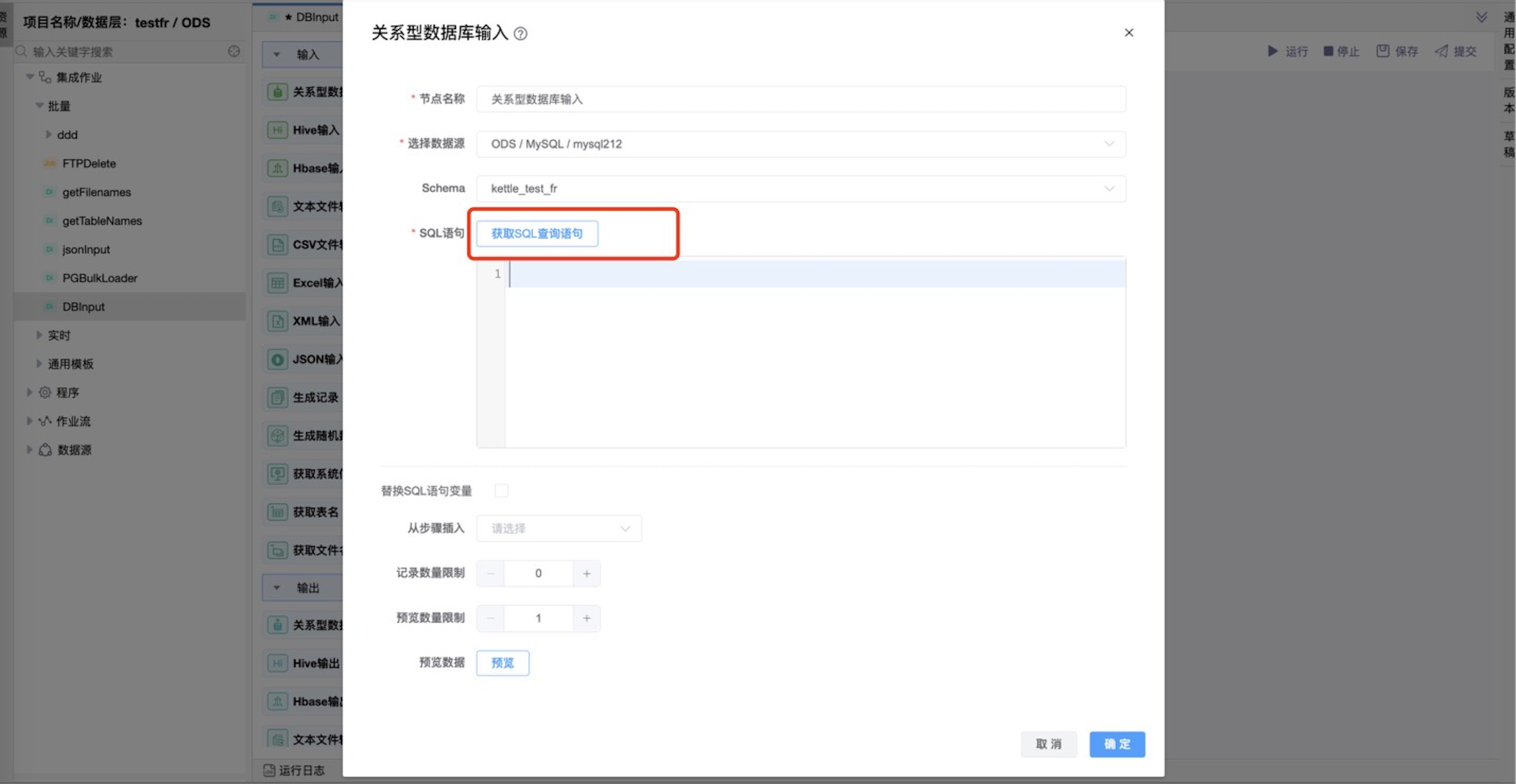
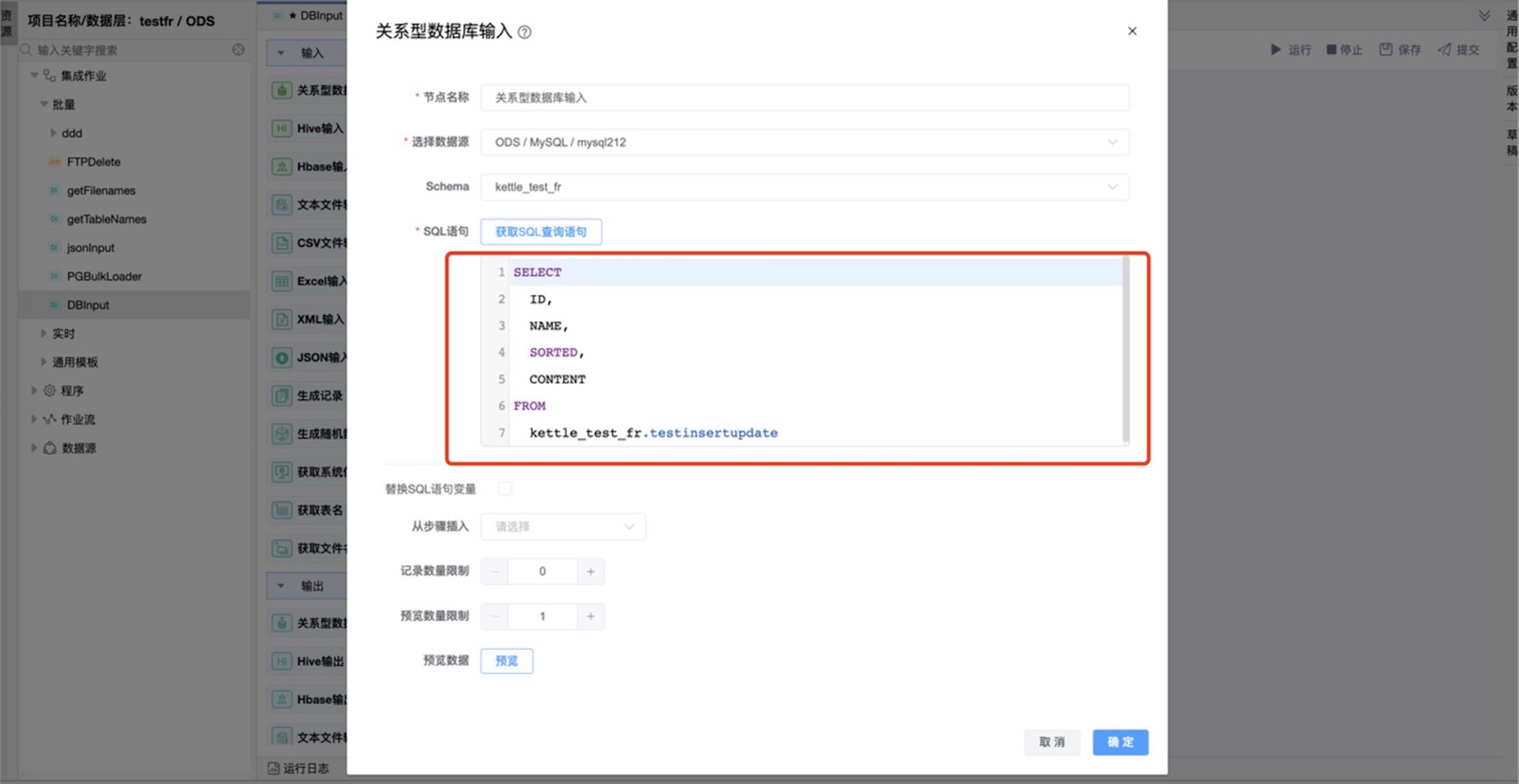
通过选择数据库中的数据表生成默认的SQL语句。
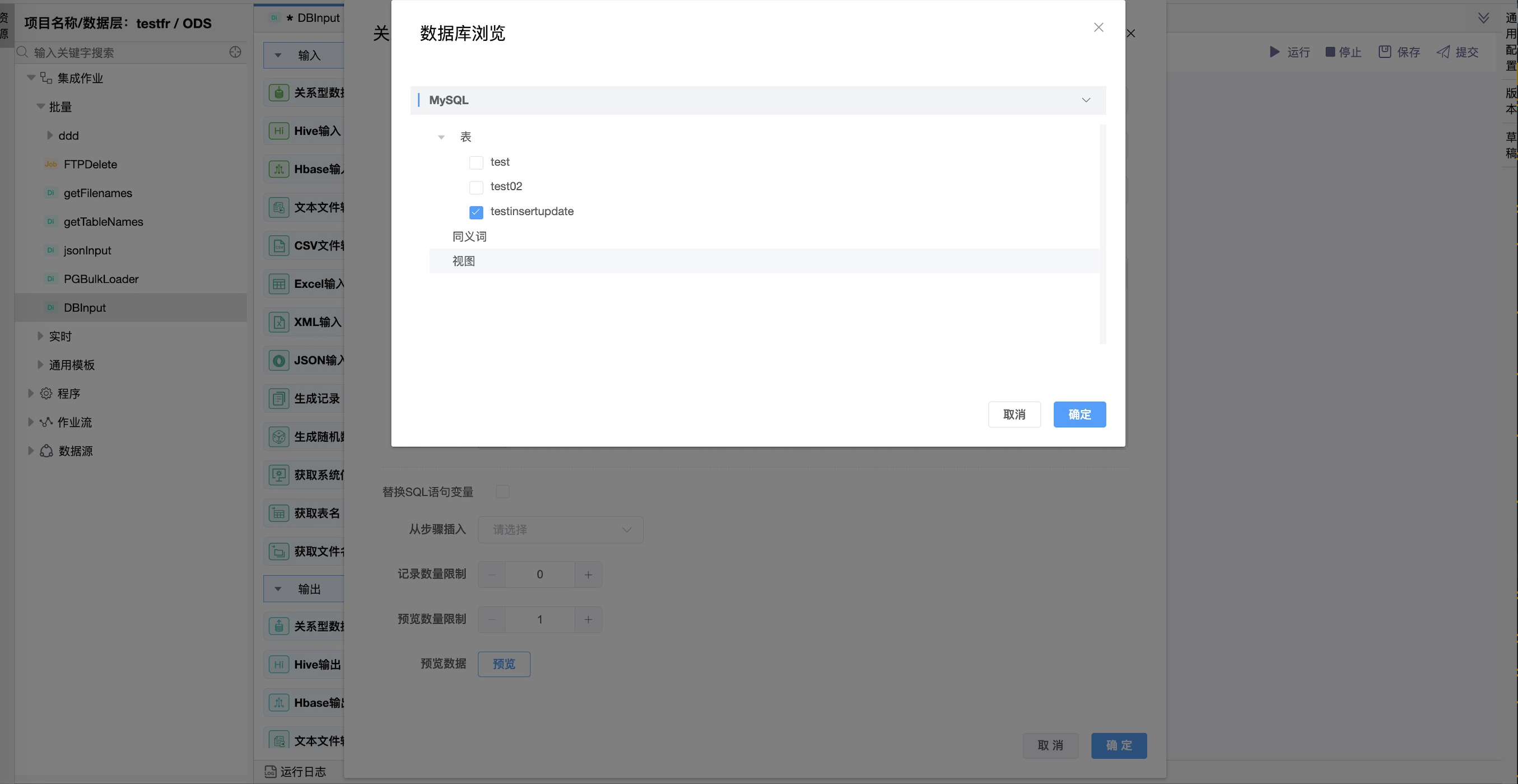
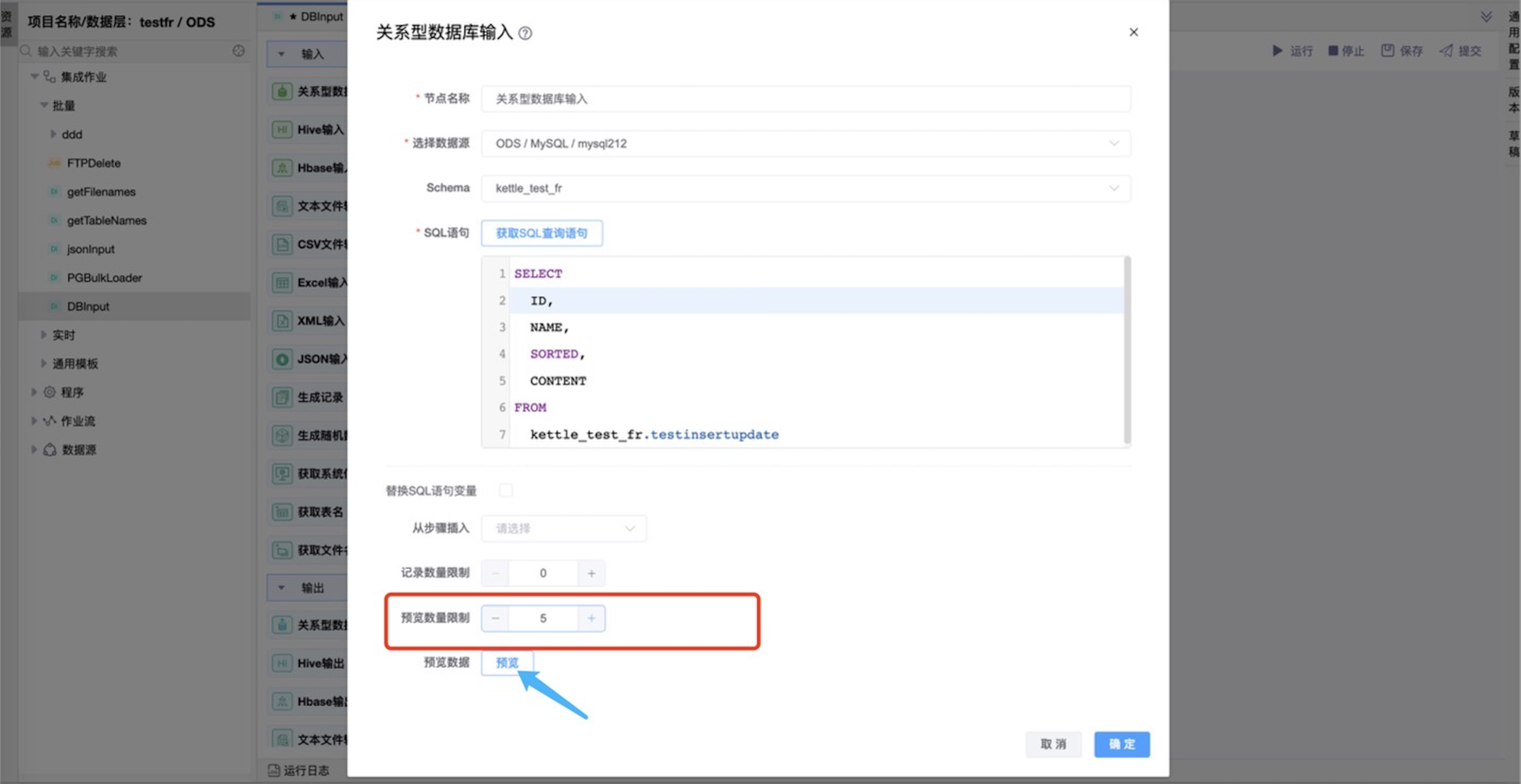
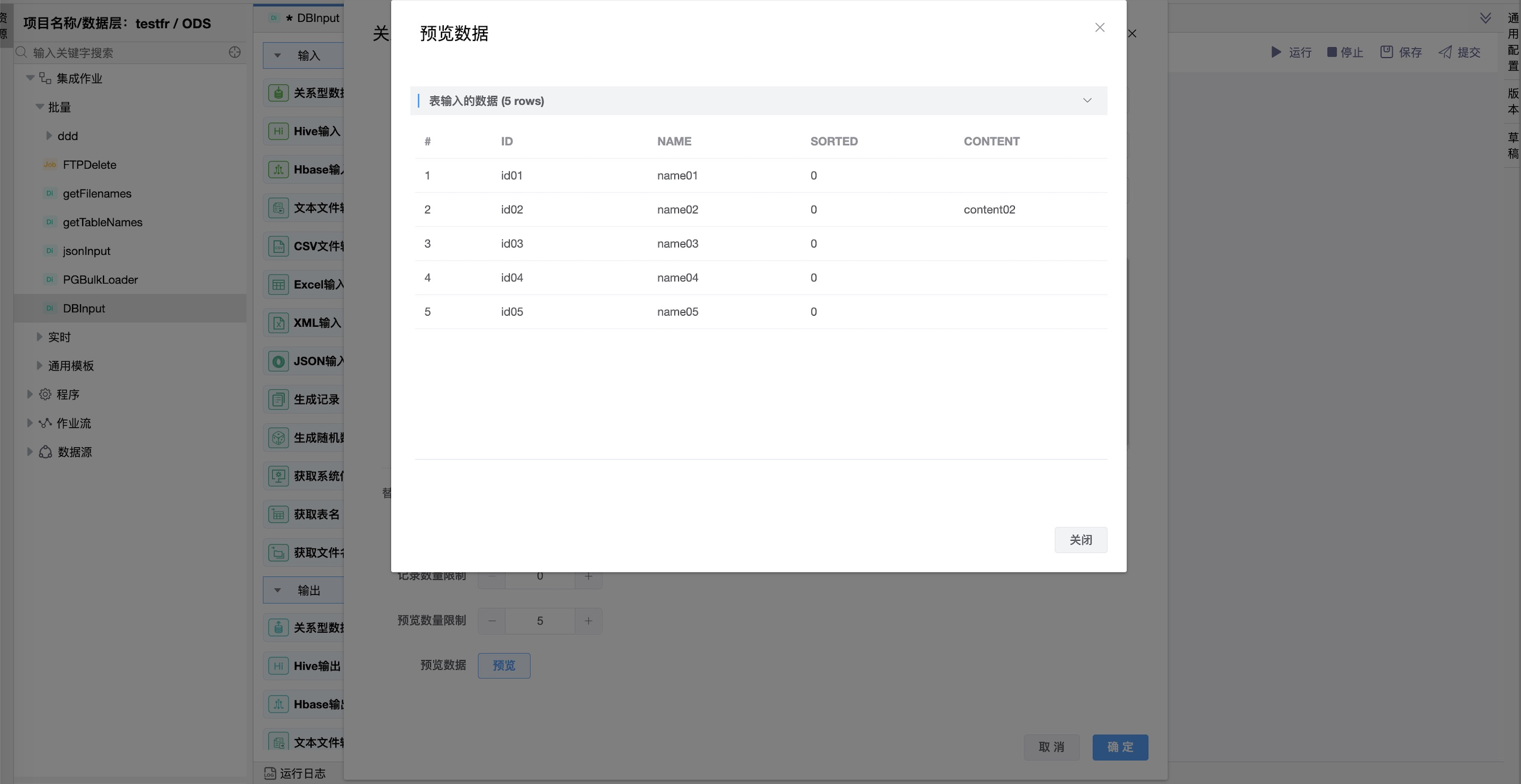
可通过编辑“预览数量限制”,点击“预览”按钮,查询预览当前表输入的数据。
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
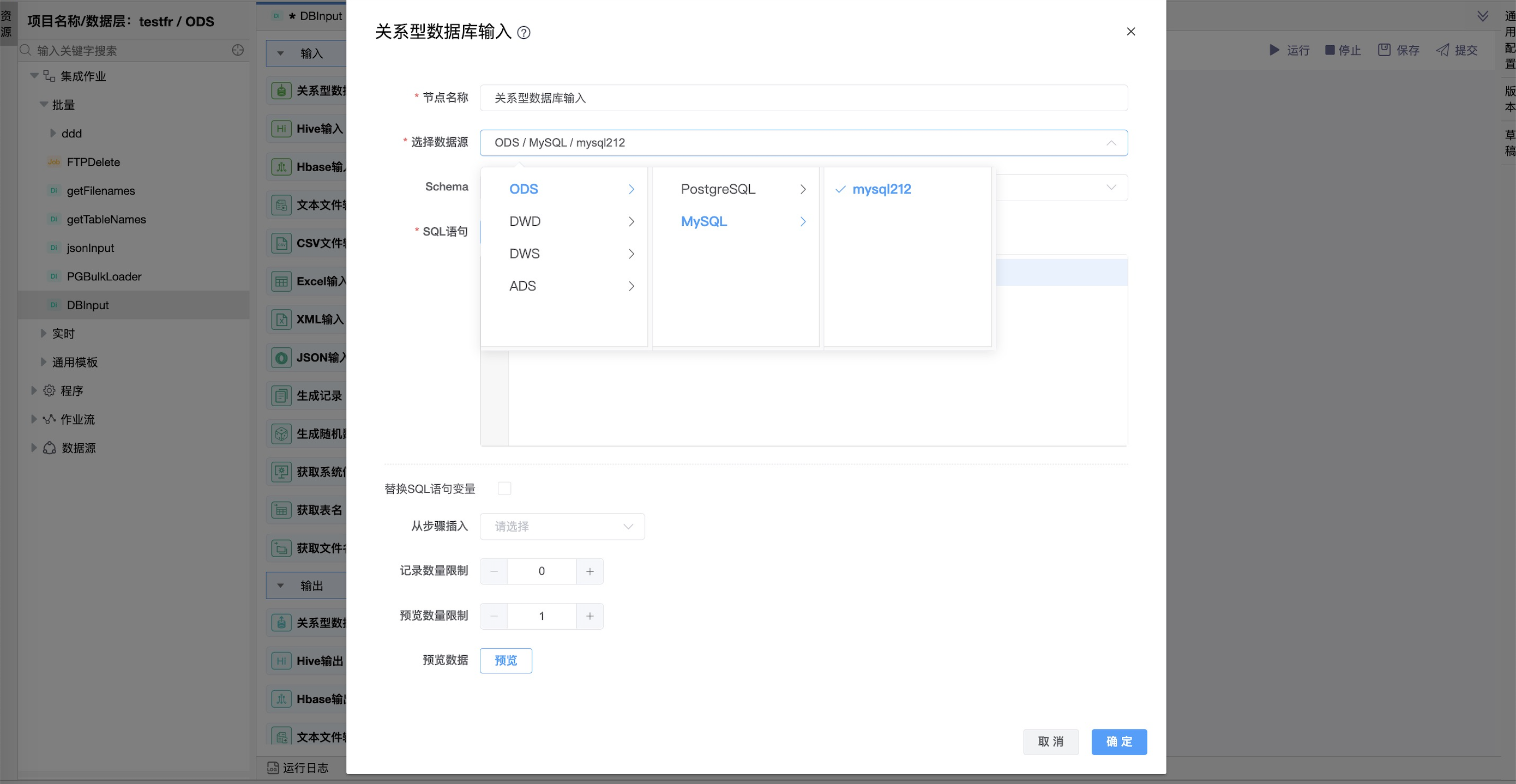
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(MySQL,SQLServer,Oracle,DB2,PostgreSQL,GBase,DM,ClickHouse,Kingbase)的数据源进行选择。 |
| 库/Schema | 选定的目标库或模式。 |
| SQL 语句 | SQL 语句用来从数据库连接中读取数据。可以通过选择数据库中的数据表生成默认的SQL语句,也可以自己编写SQL语句。 |
| 替换 SQL 语句变量 | 如果需要传入参数变量则勾选此选项。详见示例: MySQL表数据同步示例(替换SQL语句变量) |
| 从步骤插入 | 如果该组件有上一步骤,且需要从该步骤中获取变量作为参数则选中上一步骤。详见示例: MySQL表数据同步示例(从步骤中插入变量) |
| 记录数量限制 | 限制要查询的数据记录数,0表示没有限制。 |
| 预览数量限制 | 筛选要查询预览的数量。 |
# Hive 输入
功能介绍:Hive输入组件用于利用 SQL 查询 Hive 数据库表。
使用场景: 从 Hive 数据库中读取表信息,自动生成基本的 SQL 语句。
图标:

组件界面:
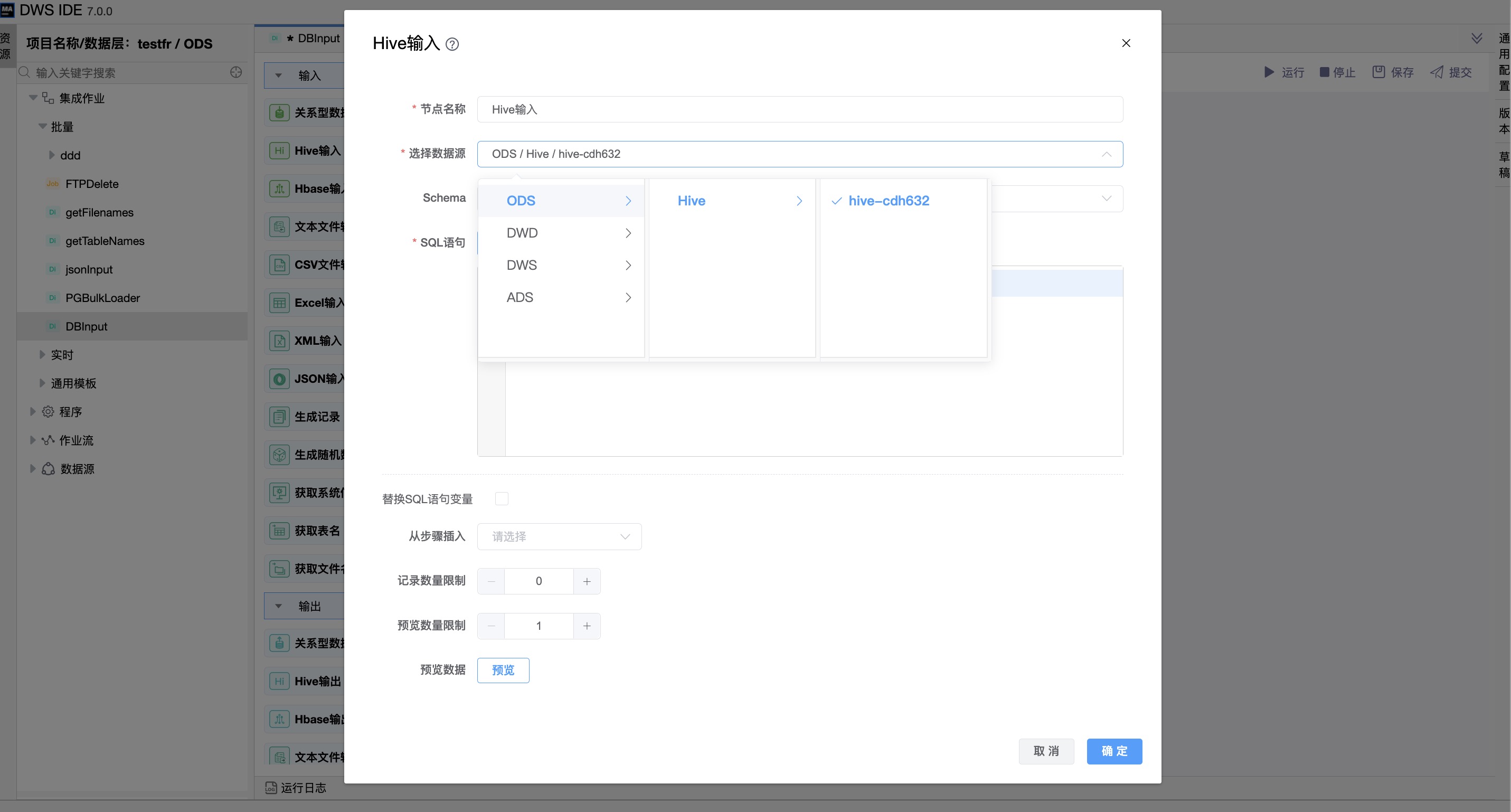
通过选择数据库中的数据表生成默认的SQL语句。
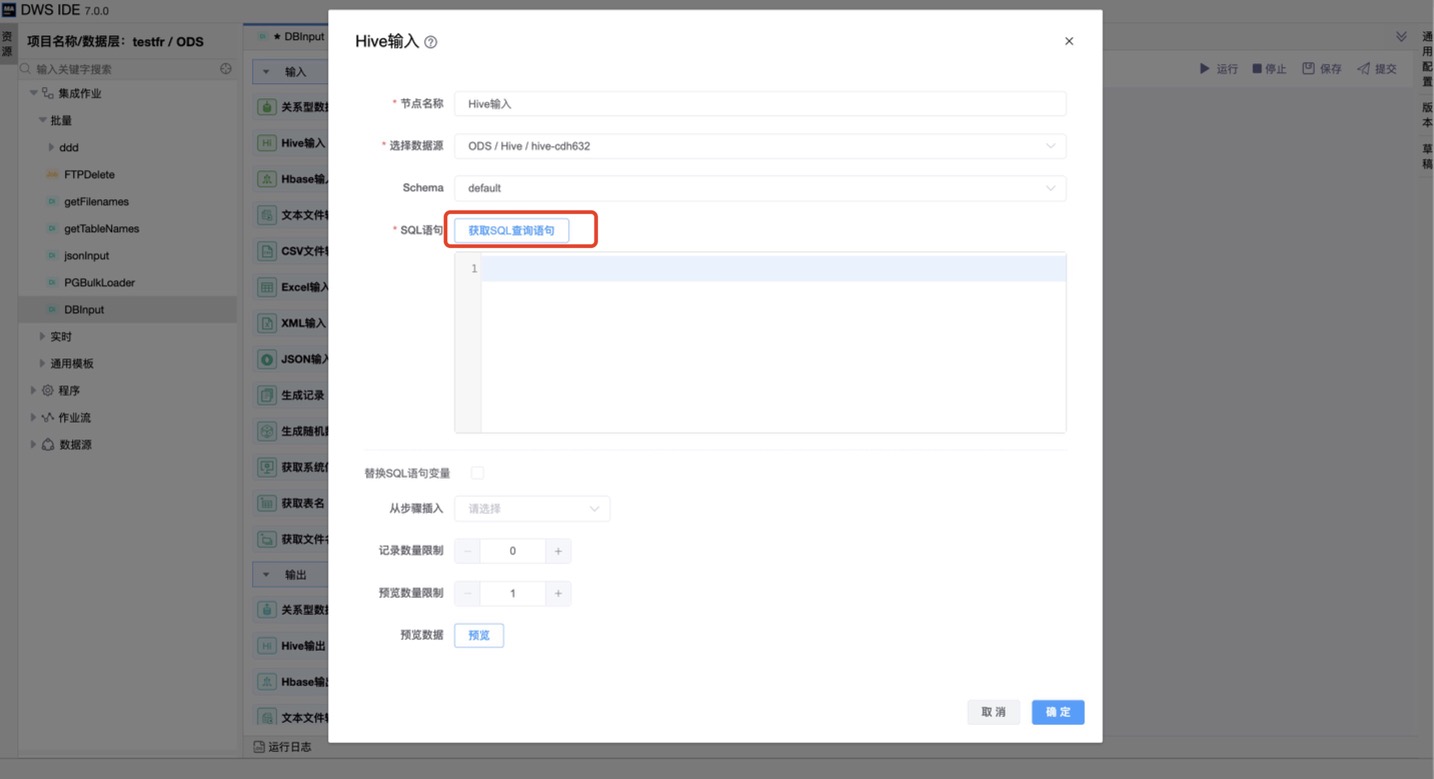
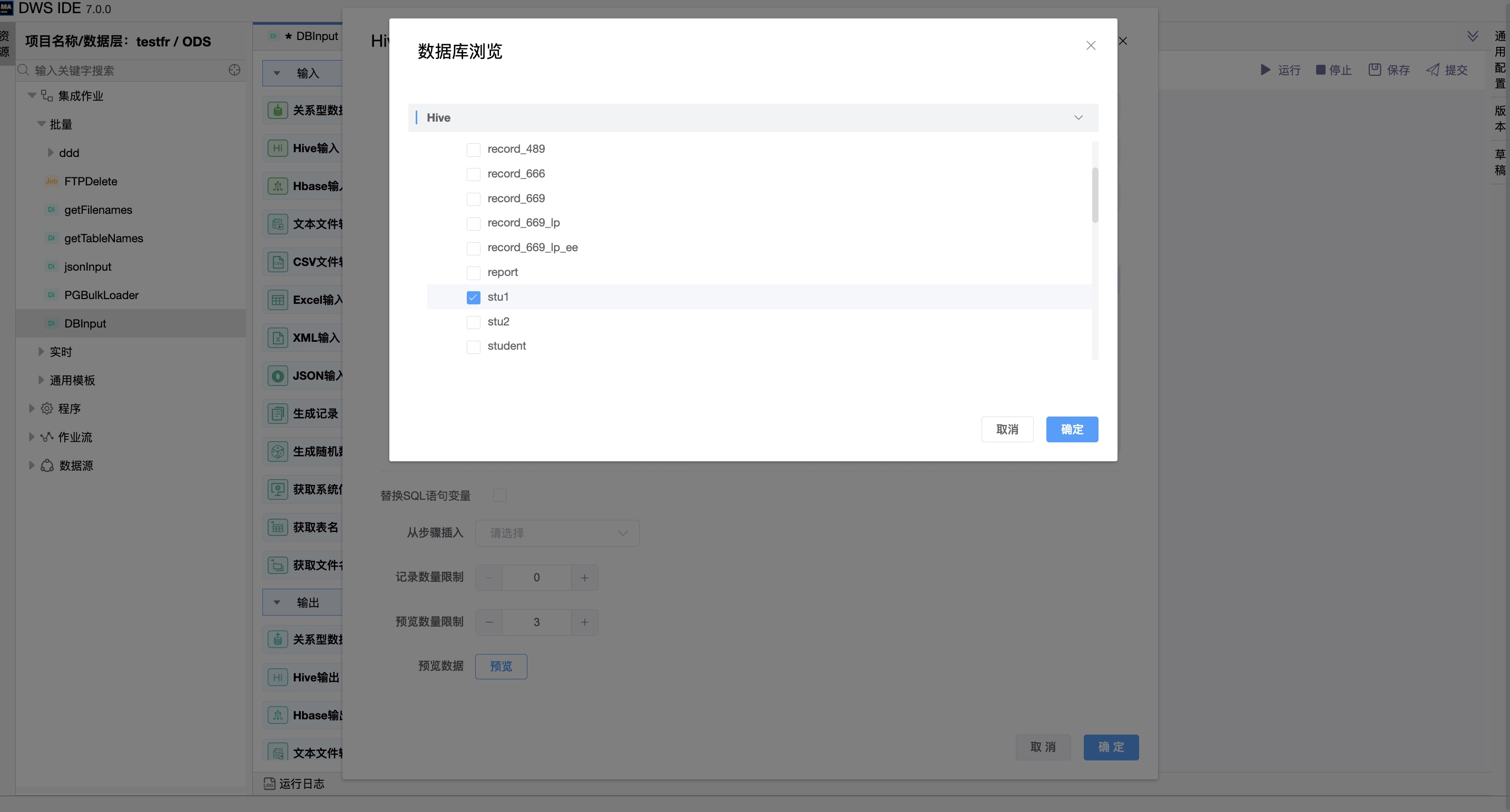
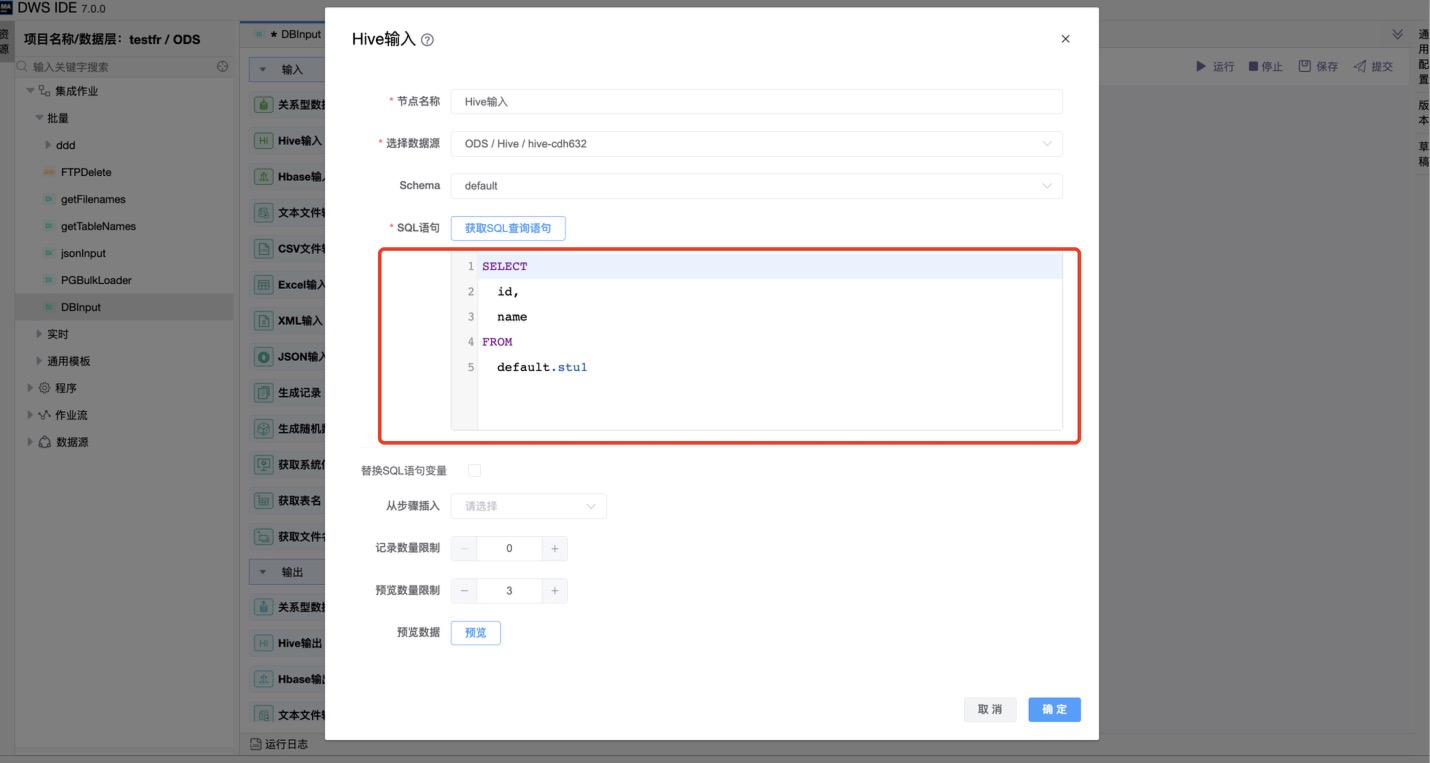
可通过编辑“预览数量限制”,点击“预览”按钮,查询预览当前表输入的数据。
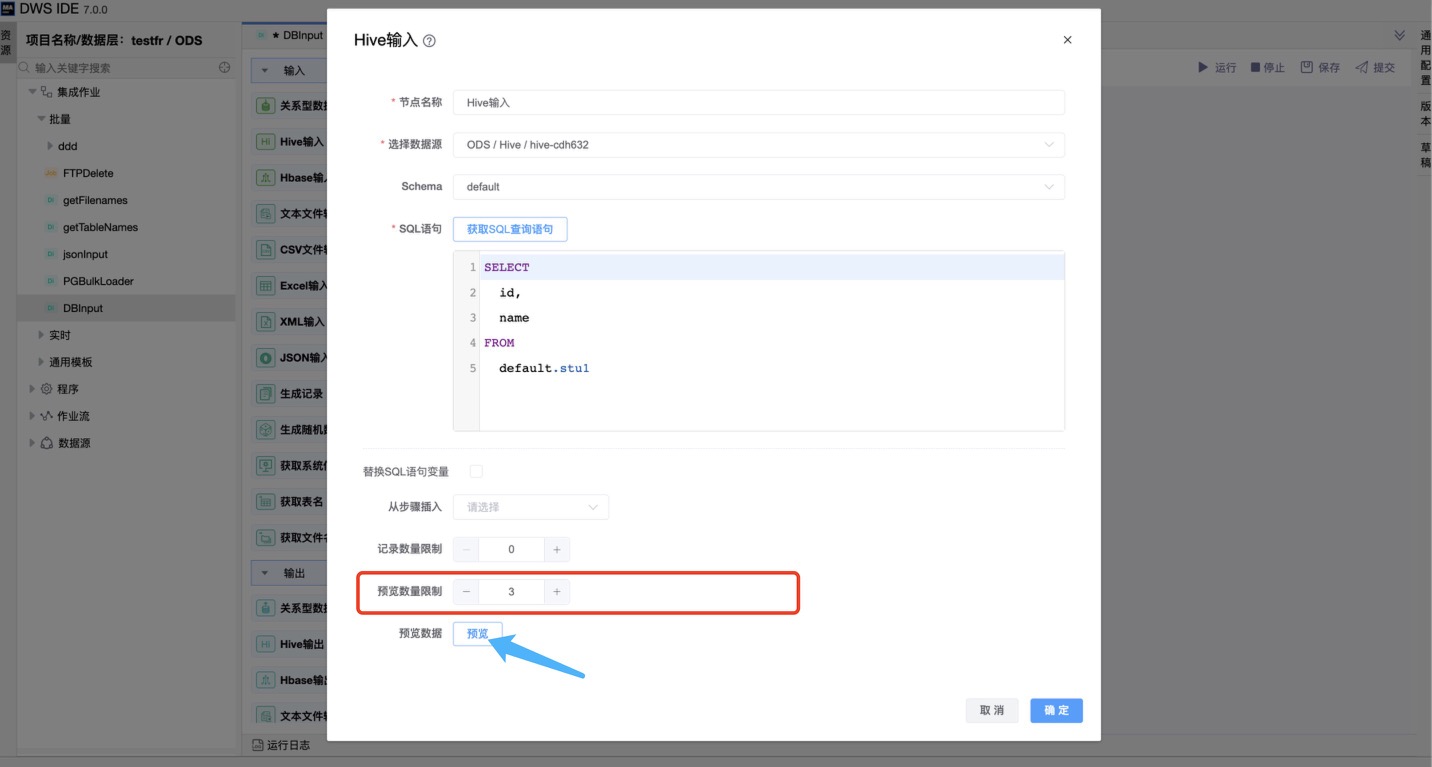
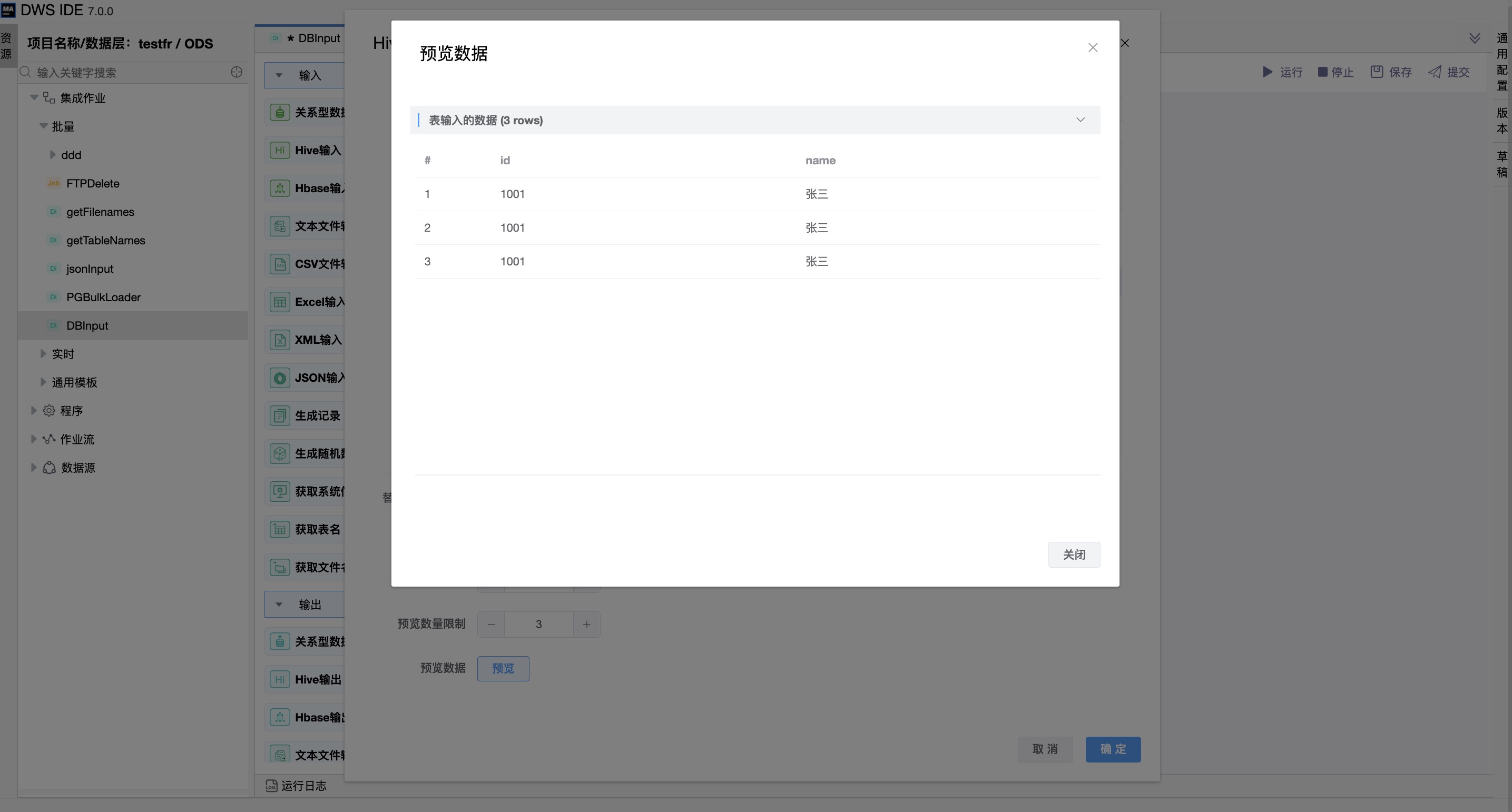
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(Hive)的数据源进行选择。 |
| Schema | 当前输入选定的目标模式。 |
| SQL 语句 | SQL 语句用来从数据库连接中读取数据。可以通过选择数据库中的数据表生成默认的SQL语句。 |
| 替换 SQL 语句变量 | 如果需要传入参数变量则勾选上。 |
| 从步骤插入 | 如果该组件有上一步骤,且需要从该步骤中获取变量作为参数则选中上一步骤。 |
| 记录数量限制 | 限制要查询的数据记录数,0表示没有限制。 |
| 预览数量限制 | 筛选要查询预览的数量。 |
# HBase 输入
功能介绍:HBase输入组件用于根据用户定义的列元数据从HBase表中读取数据。HBase是一个分布式的、面向列的数据库,提供对Hadoop文件系统的随机读写访问。
使用场景: 根据用户定义的列元数据从HBase表中读取数据。
图标:

组件界面:
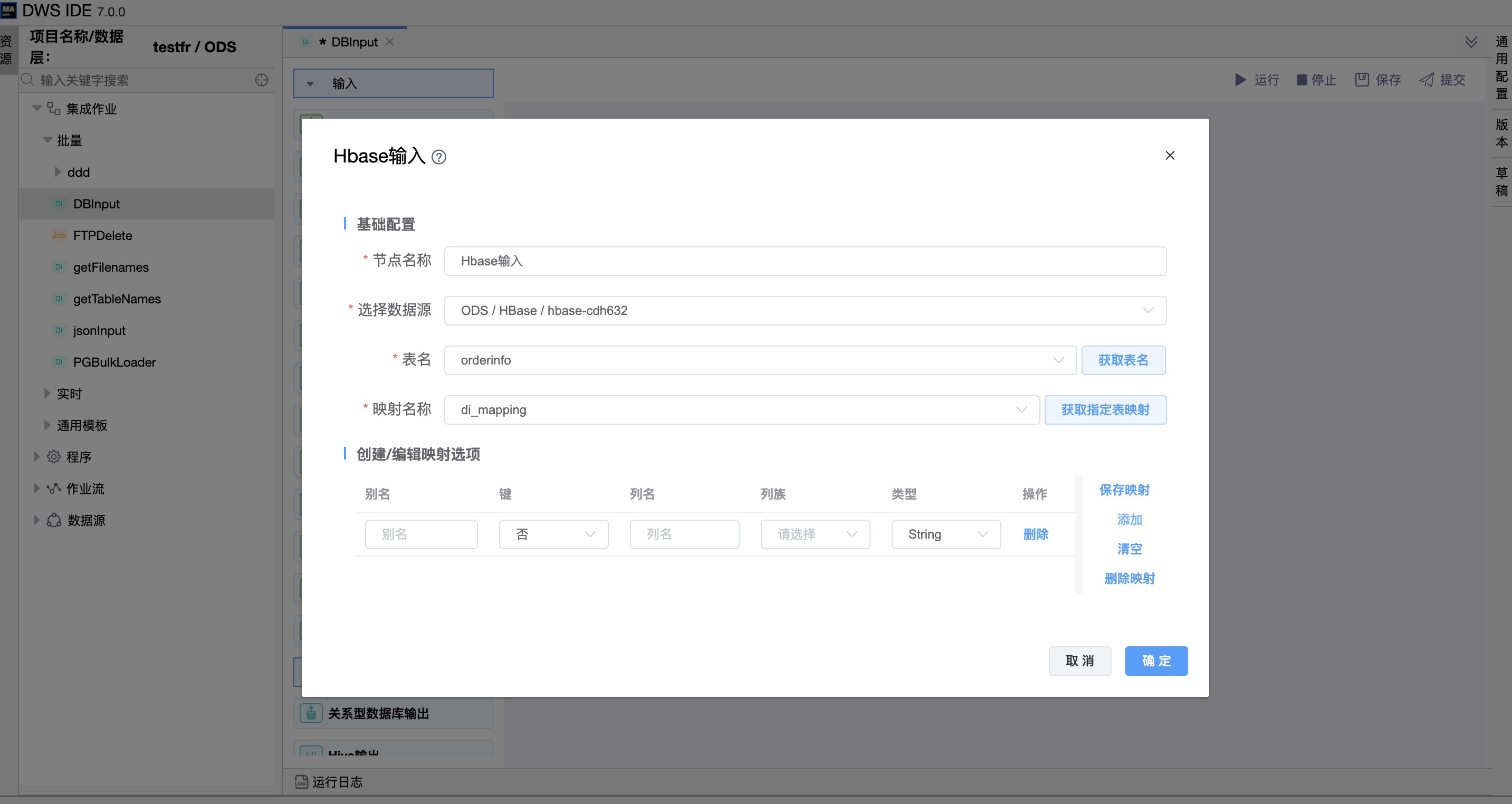
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(HBase)的数据源进行选择。 |
| 表名 | 要读数据的表名。 |
| 映射名称 | 指定表映射。 |
| 映射选项 | 别名:HBase表列别名,对于表键列是必需的,但对于非键列是可选的。 键:指定该字段事都是表的键。 列名:HBase表列名。 列族:字段在HBase表中所属的列族。非键列必须制定列族和列名。 类型: 列为键时,类型:String/Integer/UnsignedInteger/Long/UnsignedLong/Date/UnsignedDate/Binary 列非键时,类型:String/Integer/Long/Float/Double/Boolean/Date/BigNumber/Serializable/Binary |
# 文本文件输入
功能介绍:用于从各种文本文件类型中读取数据。
使用场景:从各种文本文件类型读取数据,包括由电子表格和固定宽度平面文件生成的格式。该组件的特性允许您从文件或目录列表中读取,以正则表达式的形式使用通配符,并接受前面步骤中一般化的文件名。
图标:
组件界面:
《基础信息配置》
文件目录可指定数据源文件,可选择txt、csv等文件,也可选择目录,而后用指定正则表达式通配符的形式来搜索文件。
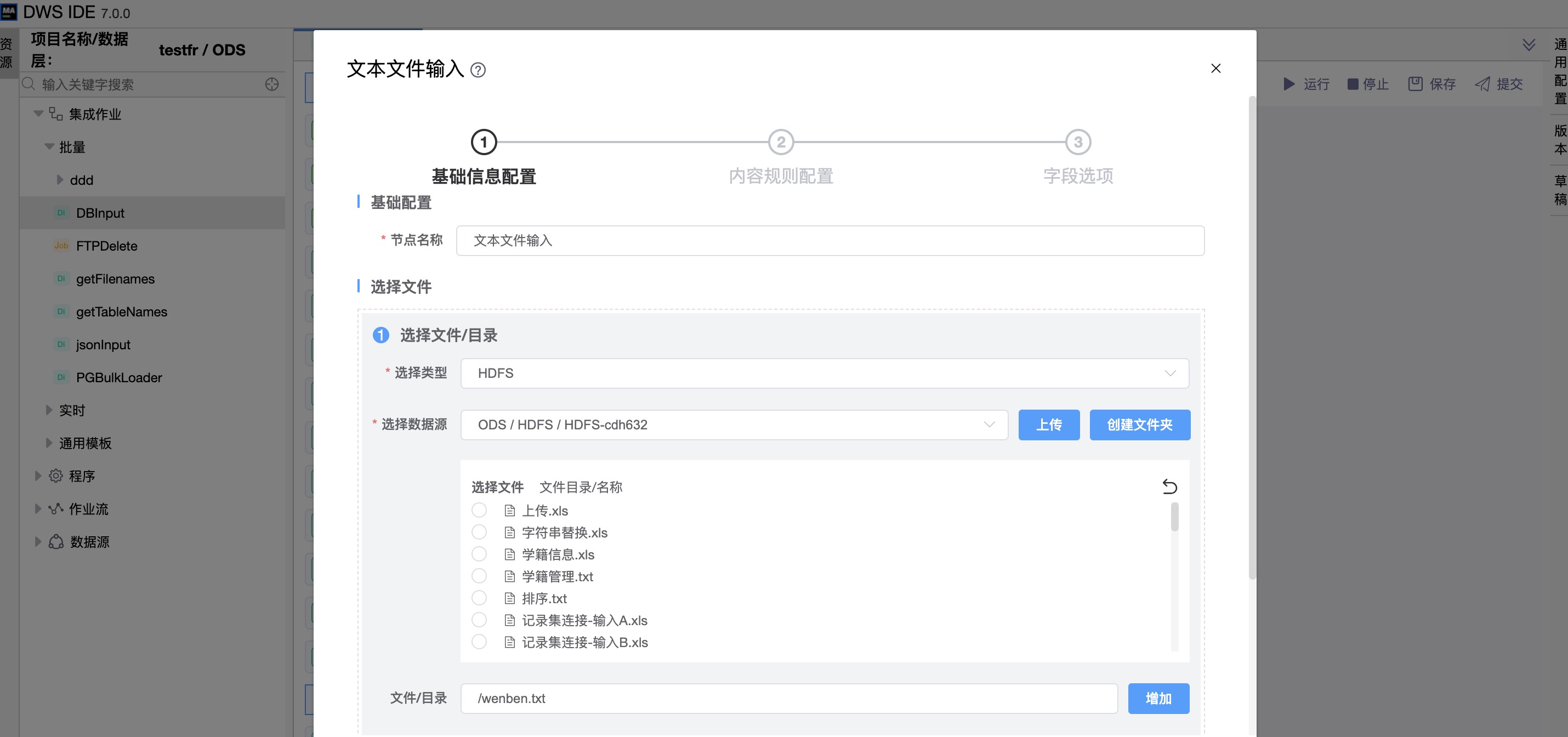

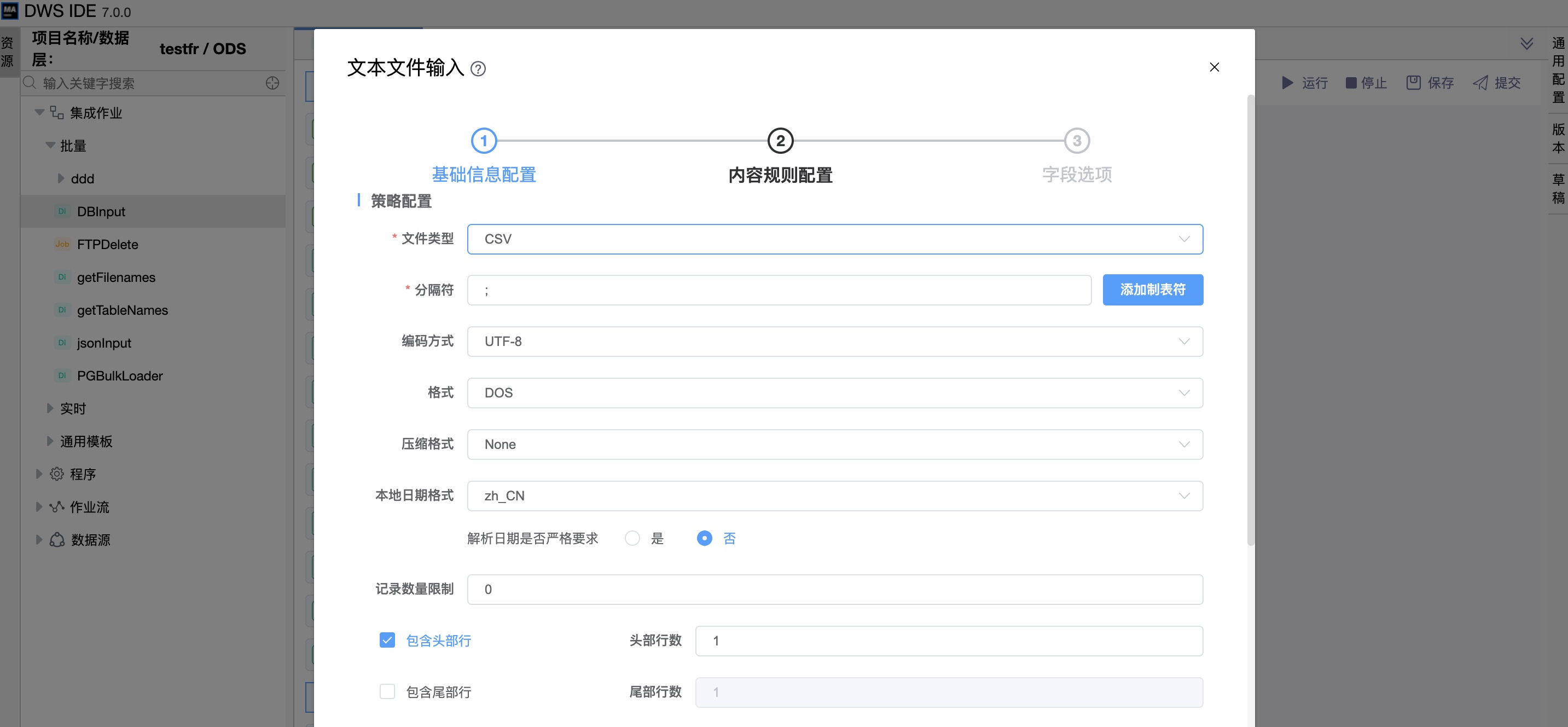
《内容规则配置》
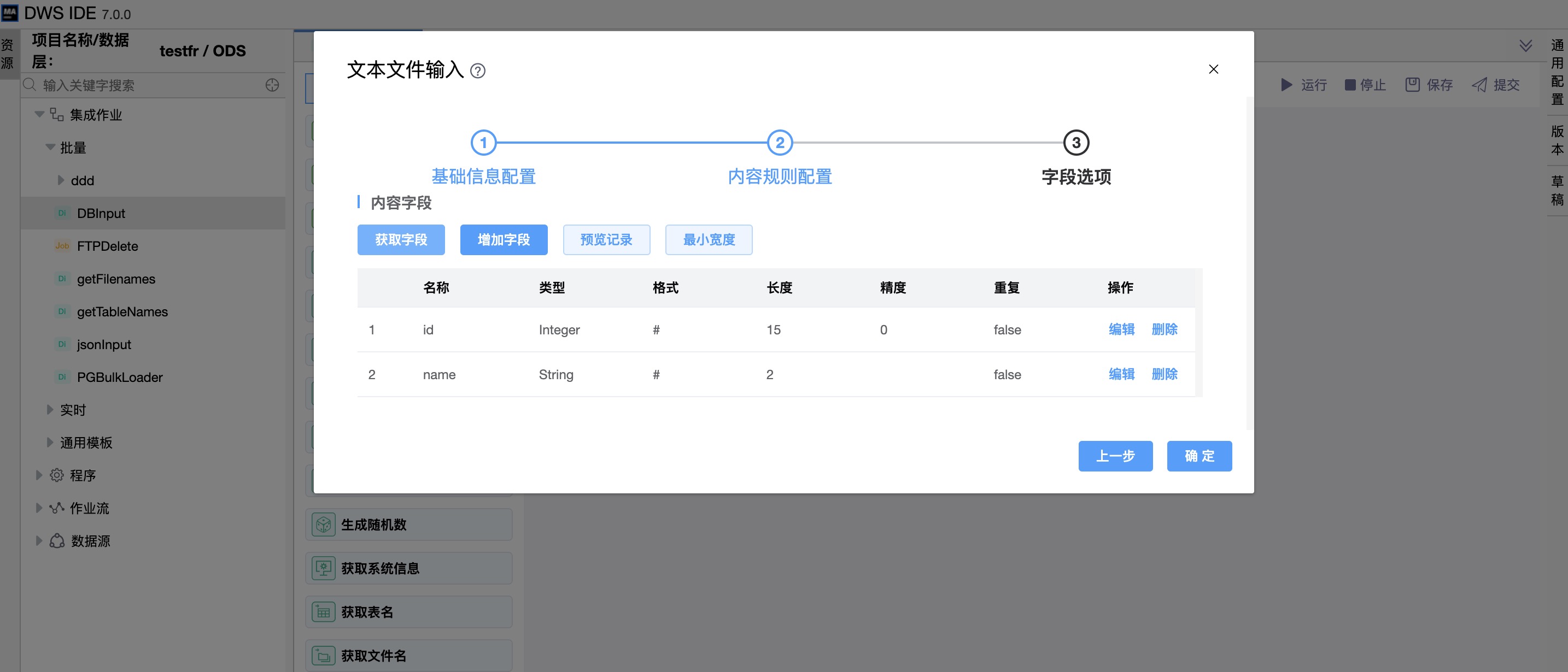
字段选项
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择类型 | 可选择“HDFS”类型或“LOCAL”类型。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(HDFS)的数据源进行选择。 |
| 文件目录 | 读取数据的文件/目录来源。 |
| 文件类型 | CSV |
| 分隔符 | 在文本的单行中,一个或多个字符将被用来分隔字段,比较有代表性的是';',或者一个tab 制表符。 |
| 编码方式 | 指定文本文件编码方式。如果不设置就使用系统默认的编码方式。如果想用Unicode,可以指定UTF-8 或者UTF-16。 |
| 格式 | 可以是DOS、UNIX 或者混合模式。UNIX 行终止可以是回车,DOS 中可以是回车或者换行。如果你选择混合模式,将不会验证。 |
| 本地日期格式 | zh_CN |
| 解析日期时是否严格要求 | 如果你想严格的解析数据字段,可以禁用这个选项。如果启用的时候,Jan 32nd 将变成Feb 1st。 |
| 记录数量限制 | 设置读取记录的行数。0 代表读取所有的。 |
| 头部行数 | 如果你的文本文件有头部行就使用这个。你可以指定头部行出现的行数。 |
| 尾部行数 | 如果你的文本文件有尾部行就使用这个。你可以指定尾部行出现的行数。 |
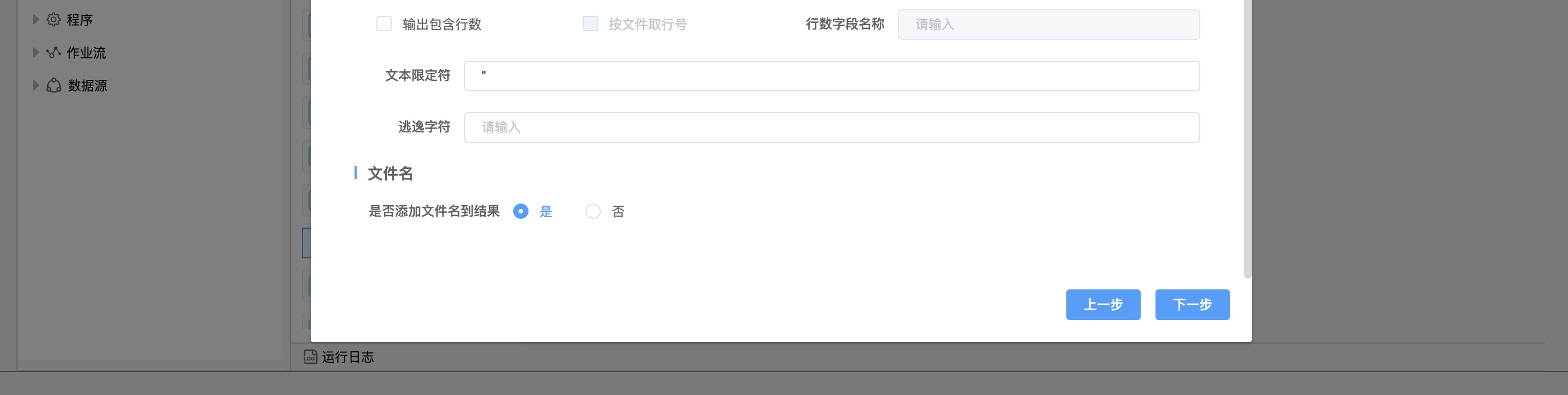
| 输出包含行数 | 如果你想行数作为输出的一部分,可以启用这个。 |
| 行数字段名称 | 包含行数的字段名称。 |
| 逃逸字符 | 如果你的数据中有逃逸字符,就指定逃逸字符(或者逃逸字符串)。如果\作为逃逸字符,文本’Not the nine o\’clock news.’(’作为封闭字符),将被解析成Not the nine o’clock news. |
| 添加文件名到结果 | 如果你想文件名作为输出的一部分,可以启用这个。 |
| 内容字段 | 名称: 设置要在输出流中显示的字段名称。 类型:字段类型(String、Date、Number 等)。 格式:控制输入数据的格式(整数、有小数位、日期格式等)。 长度: 对于Number:有效数的数量。 对于String:字符的长度。 对于Date:打印输出字符的长度(例如4 代表返回年份)。 精度: 对于Number:浮点数的数量。 对于String,Date,Boolean:未使用。 重复:Y/N:如果在当前行中对应的值为空,则重复最后一次不为空的值。 |
# CSV 文件输入
功能介绍:该组件用于将数据从带分隔符的文本文件读取到PDI转换中。虽然此步骤称为CSV文件输入,但您也可以将CSV文件输入与许多其他分隔符类型一起使用,例如管道、制表符和分号。
使用场景:从指定的CSV文件输入/读取数据。
图标:
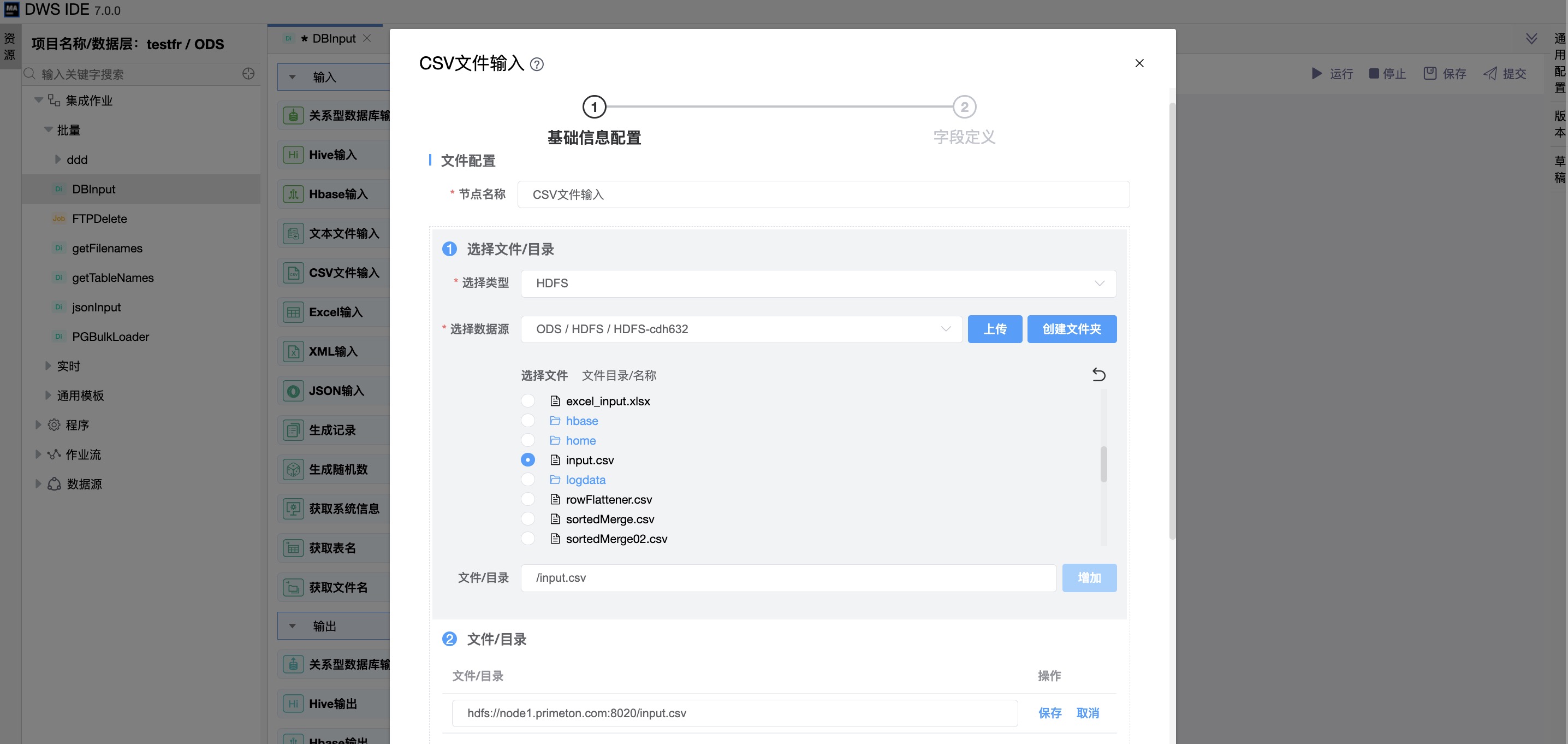
组件界面:
《基础信息配置》
文件目录可指定数据源文件,可选择csv文件,也可选择目录,而后用指定正则表达式通配符的形式来搜索文件。

《字段定义》
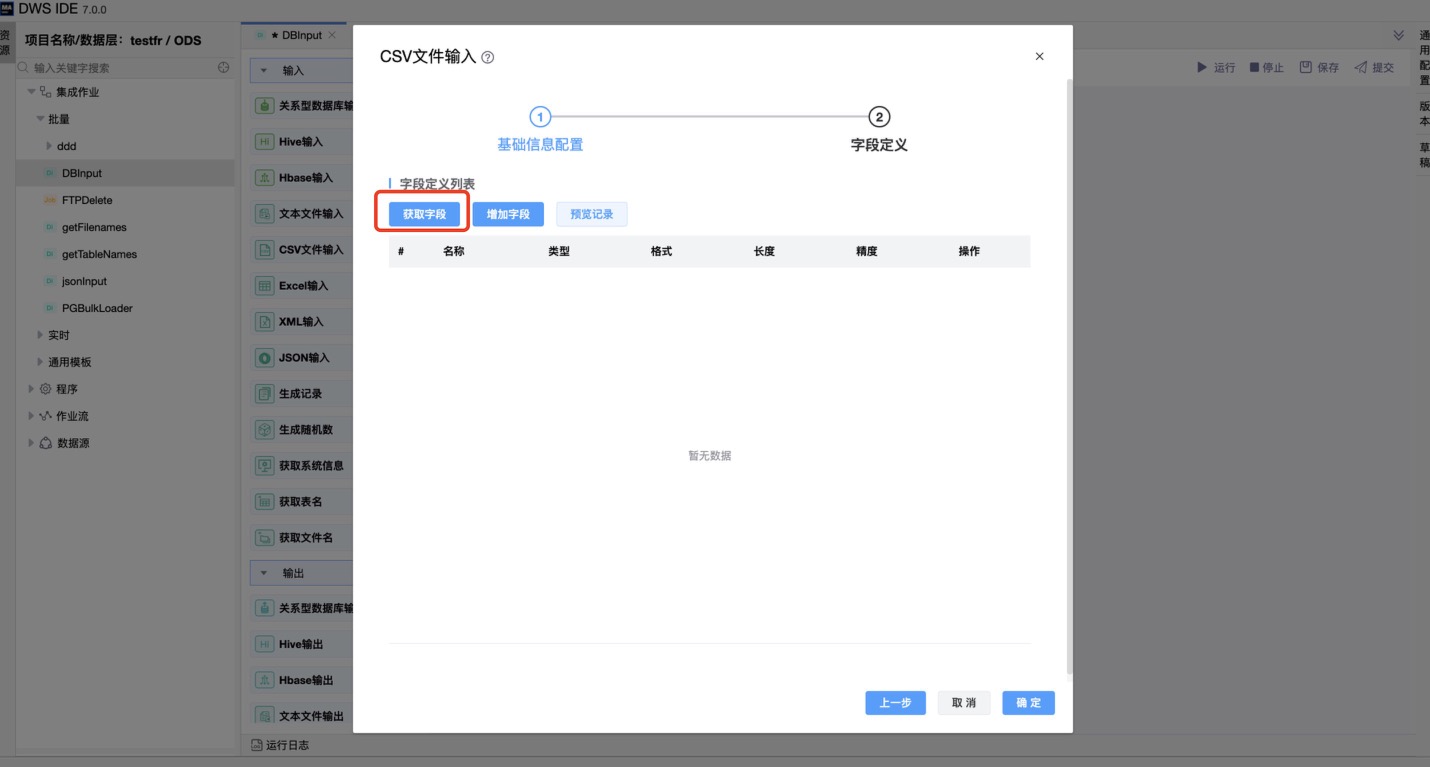

参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择类型 | 可选择“HDFS”类型或“LOCAL”类型。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(HDFS)的数据源进行选择。 |
| 文件目录 | 读取数据的文件/目录来源。 |
| 文件类型 | CSV文件类型。 |
| 源文件包含列名标题行 | 指示源文件是否包含列名的一个标题行。 |
| 字段中有回车换行 | 设置数据字段是否可能包含换行字符。 |
| 添加文件名到结果 | 将CSV源文件名添加到此转换的结果中。 |
| 文件编码 | 指定源文件的编码,防止读取的数据乱码。 |
| 列分隔符 | 文件中每一列数据之间,使用的分割符。 |
| 封闭符 | 指定源文件中使用的结束字符。 |
| NIO缓存 | 指定读取缓冲区的大小,指一次从源文件读取的字节数。 |
| 字段定义列表 | 名称:字段的名称。 类型:字段的类型(String,Date或Number等)。 格式:用于转换原始字段格式的可选格式掩码。 长度:字段的长度取决于以下字段类型: Number:一个数字中有效数字的总数; String:字符串的总长度; Date:字符串打印输出的长度。 精度: 用于数字类型字段的浮点数。 |
# Excel 输入
功能介绍:该组件用于从 Microsoft Excel 读取数据。默认类型设置为 Excel 97-2003 XLS。以下部分描述了用于配置此步骤的每个可用功能:
- 当您在读取其他文件类型(Excel 2007)并使用受保护工作表等特殊功能时,您需要相应地更改文件选项卡中的电子表格类型(引擎)。
- 如果您使用受密码保护的工作表,则必须将电子表格类型(引擎)设置为 Excel 2007 XLSX (Apache POI)。
使用场景:从指定的EXCEL文件输入/读取数据。
图标:

组件界面:
《文件设置》
文件目录可指定数据源文件,选择excel文件,也可选择目录,而后用指定正则表达式通配符的形式来搜索文件。


《读取工作表》
Exel中默认可有多个sheet页,指定你要读取的数据在哪个sheet页(可选择多个)。
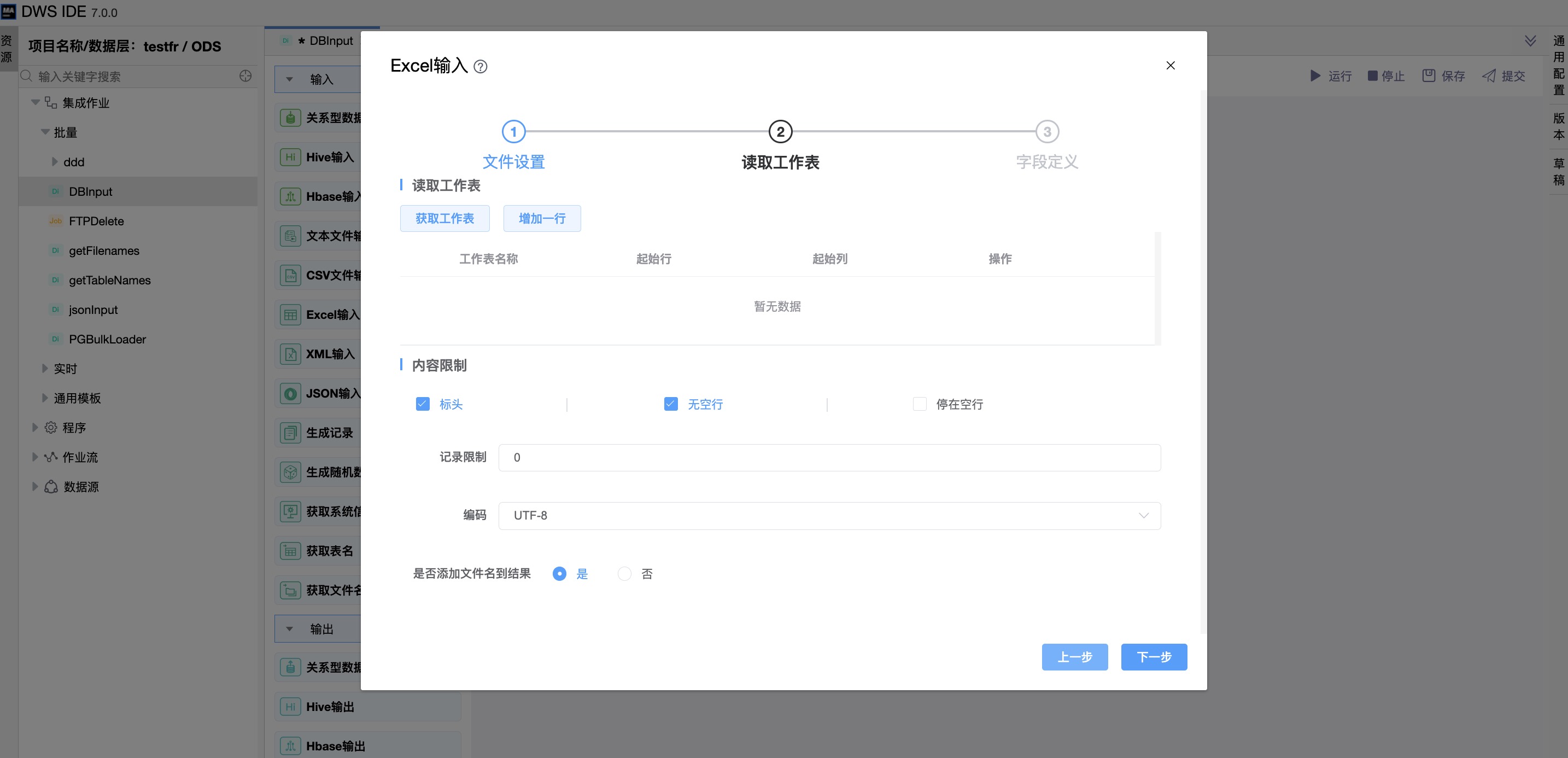 《字段定义》
《字段定义》
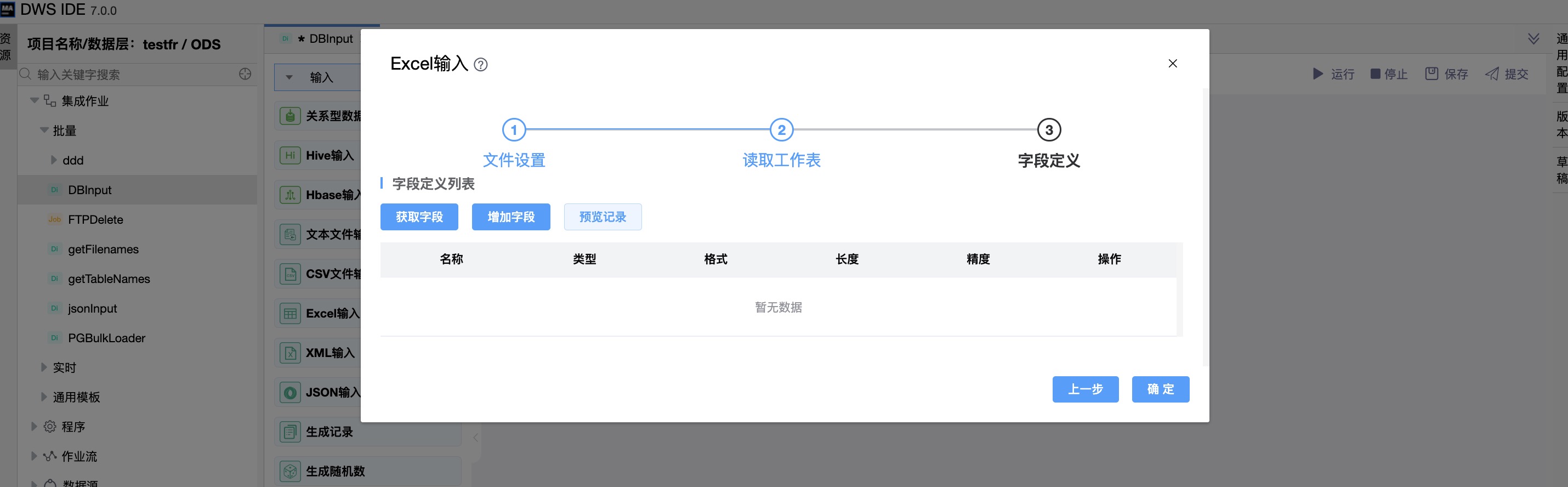
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 表格类型 | (1)、Excel 97-2003 xls(JXL): 这个引擎只支持xls结尾的excel; (2)、Excel 2007 XLSX(Apache POI):一般我们选择这个即可,支持xls和xlsx的小文件; (3)、Excel 2007 XLSX(Apache POI Streaming):如果读取的文件比较大,建议使用这个,否则本机内存很快就吃光了。 |
| 是否从上一节点获取文件名 | 如果该组件有上一节点,且需要从该节点中获取变量的值,作为文件名,则选中此选项。 |
| 选择类型 | 可选择“HDFS”类型或“LOCAL”类型。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(HDFS)的数据源进行选择。 |
| 文件目录 | 读取数据的文件/目录来源。 |
| 读取工作表 | 指定你要读取的数据在哪个sheet页(可选择多个)。 |
| 标头 | 检查是否工作表指定了一个头部行。 |
| 无空行 | 检查是否不需要空行输出。 |
| 停在空行 | 当步骤在读取工作表遇到一个空行的时候停止读取。 |
| 记录限制 | 限制输出的行数,0 代表输出所有行。 |
| 编码 | 防止中文乱码,指定和excel一样即可。 |
| 是否添加文件名到结果 | 此组件运行时,会把读取的文件名输出1列。 |
| 字段定义列表 | 名称:字段的名称。 类型:字段的类型(String,Date或Number等)。 格式:用于转换原始字段格式的可选格式掩码。 长度:字段的长度取决于以下字段类型: .Number:一个数字中有效数字的总数; .String:字符串的总长度; .Date:字符串打印输出的长度。 精度: 用于数字类型字段的浮点数。 |
# XML 输入
功能介绍:该组件提供了使用 XPath 规范从任何类型的 XML 文件中读取数据的能力。
使用场景:从指定的XML文件输入/读取数据。
图标:

组件界面:
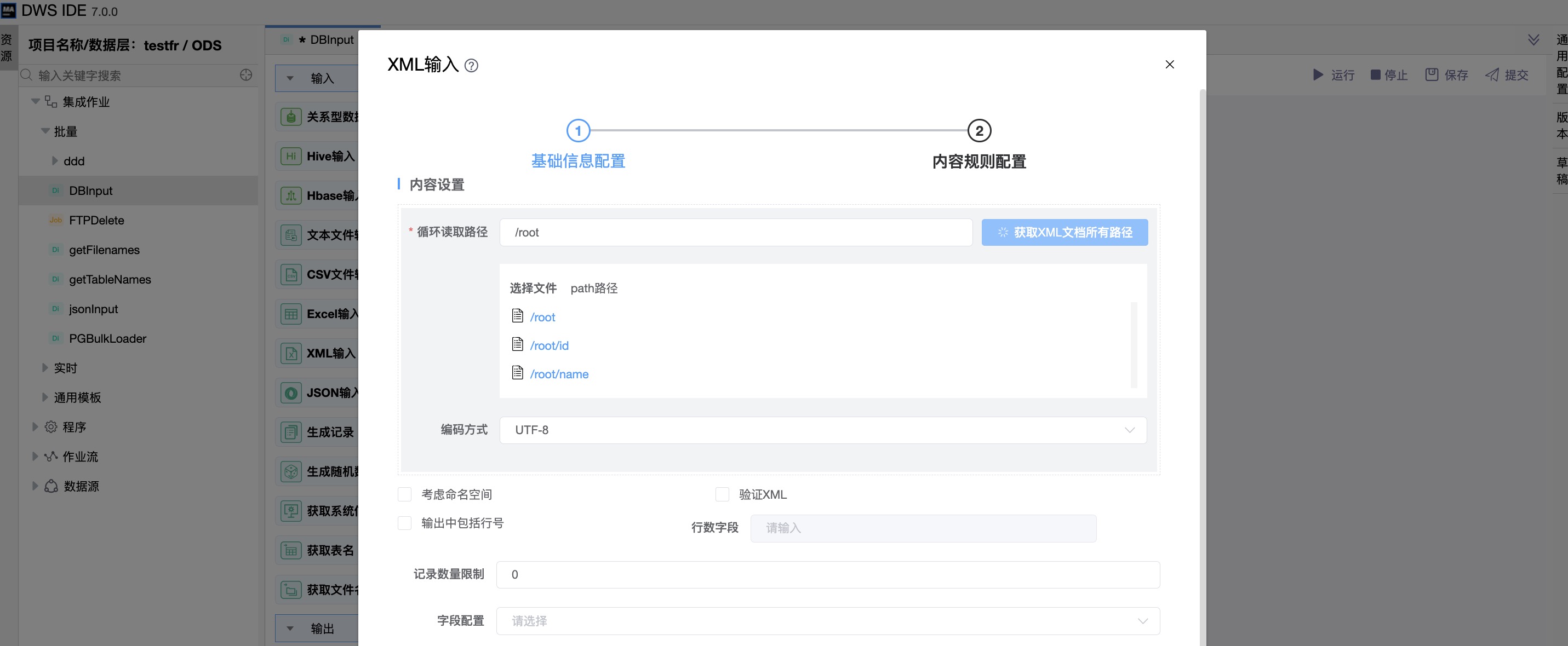
《基础信息配置》
“是否将XML源定义在一个字段中”:否
文件目录可指定数据源文件,可选择xml文件,也可选择目录,而后用指定正则表达式通配符的形式来搜索文件。
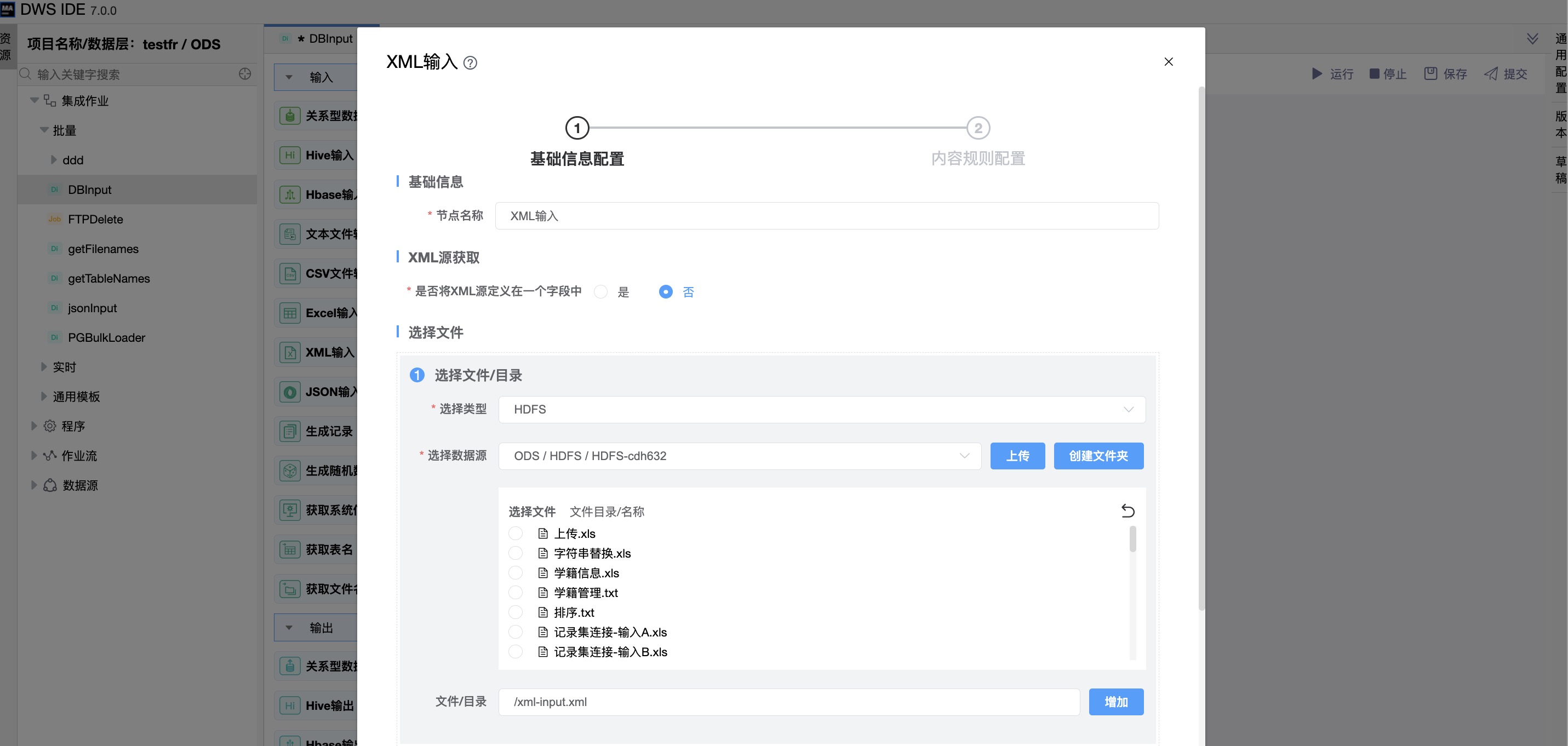
 “是否将XML源定义在一个字段中”:是
选择将XML源定义在一个字段中,此时该组件连接上一节点,源字段名的数据便是从上一节点获取的。
“是否将XML源定义在一个字段中”:是
选择将XML源定义在一个字段中,此时该组件连接上一节点,源字段名的数据便是从上一节点获取的。
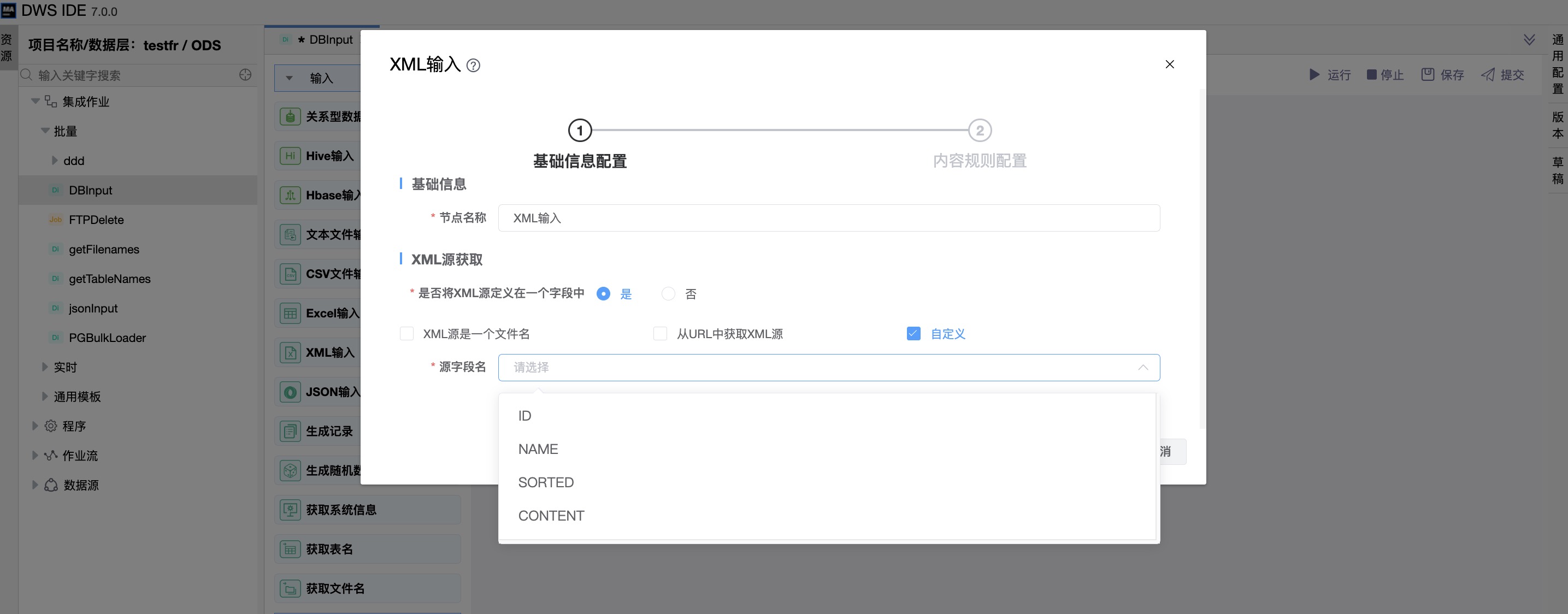 《内容规则配置 + 字段配置》
《内容规则配置 + 字段配置》

参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 是否将XML源定义在一个字段中 | 如果该组件有上一节点,且需要从该节点中获取变量的值,作为XML源的定义,则选中此选项。 |
| 源字段名 | XML源字段名选择。 |
| 选择类型 | 可选择“HDFS”类型或“LOCAL”类型。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(HDFS)的数据源进行选择。 |
| 循环读取路径 | xml文件中的层次结构。 |
| 编码方式 | xml文件的字符编码类型。 |
| 考虑命名空间 | 选中此项即可识别XML文档名称空间。 |
| 验证XML | 在解析之前验证XML。 |
| 输出中包括行号 | 显示行数,为递增列。 |
| 行数字段 | 行数字段。 |
| 记录数量限制 | 限制记录数量。 |
| 字段列表 | 名称:字段的名称。 XML路径:要读取的元素节点或属性的路径 节点:要读取的元素类型:节点或属性 类型:字段的类型(String,Date或Number等)。 格式:控制输入数据的格式(整数、有小数位、日期格式等)。 长度:字段的长度取决于以下字段类型: .Number:一个数字中有效数字的总数; .String:字符串的总长度; .Date:字符串打印输出的长度。 精度: .对于Number:浮点数的数量。 对于String,Date,Boolean:未使用。 |
# JSON 输入
功能介绍:该组件使用JSONPath表达式从JSON结构、文件或传入字段读取数据,以提取数据和输出行。JSONPath表达式可以使用点表示法或方括号表示法。
使用场景:从指定的JSON文件输入数据。
在转换名称字段中输入以下信息:
步骤名称:指定画布上JSON输入转换步骤的唯一名称。您可以自定义名称,也可以将其保留为默认值。
您可以使用预览行来显示此步骤生成的行。JSON输入步骤根据选项卡中提供的信息确定要输入哪些行。此预览功能可帮助您确定所提供的信息是否准确地模拟了您要检索的行。
图标:

组件界面:
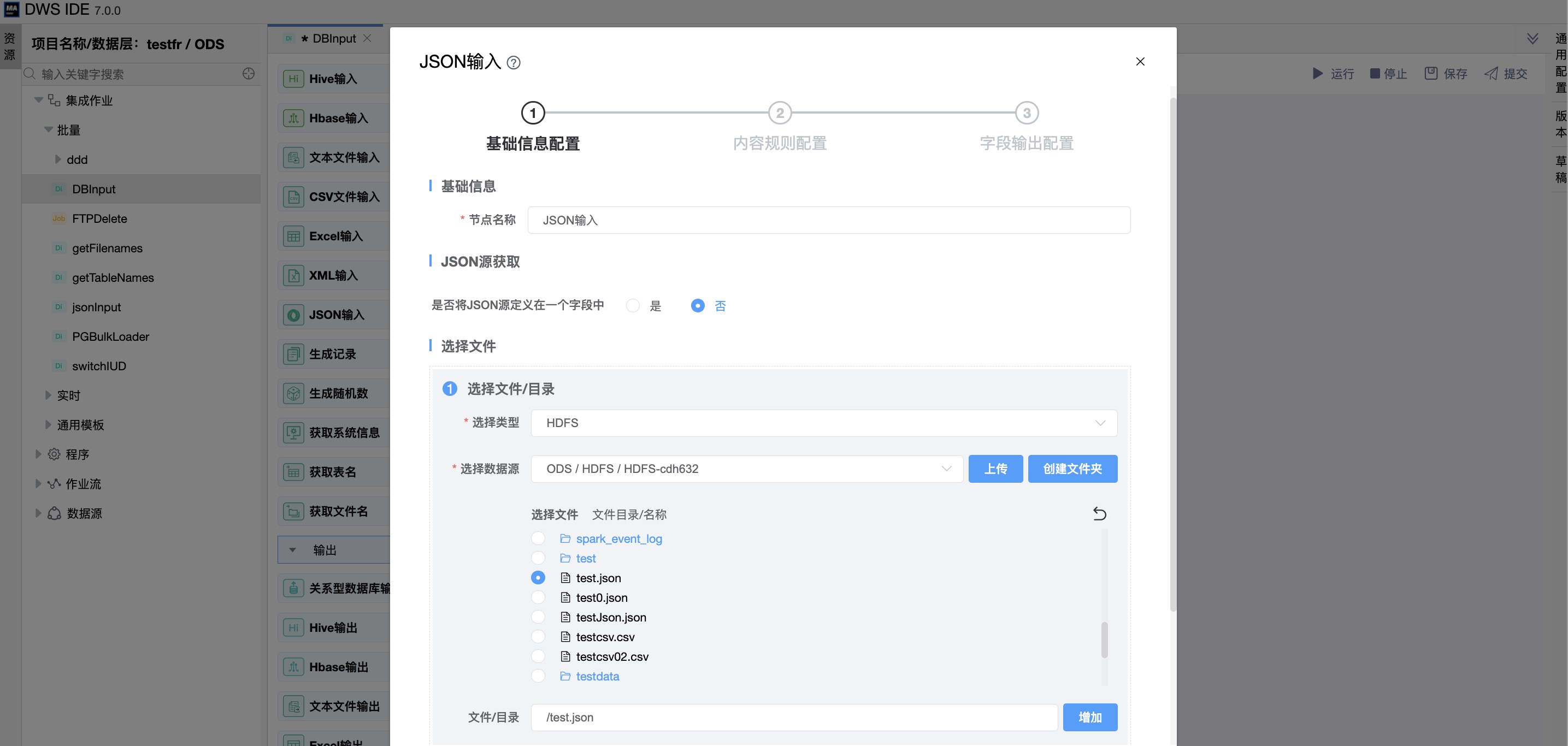
《基础信息配置》
“是否将JSON源定义在一个字段中”:否
文件目录可指定数据源文件,选择json文件,也可选择目录,而后用指定正则表达式通配符的形式来搜索文件。
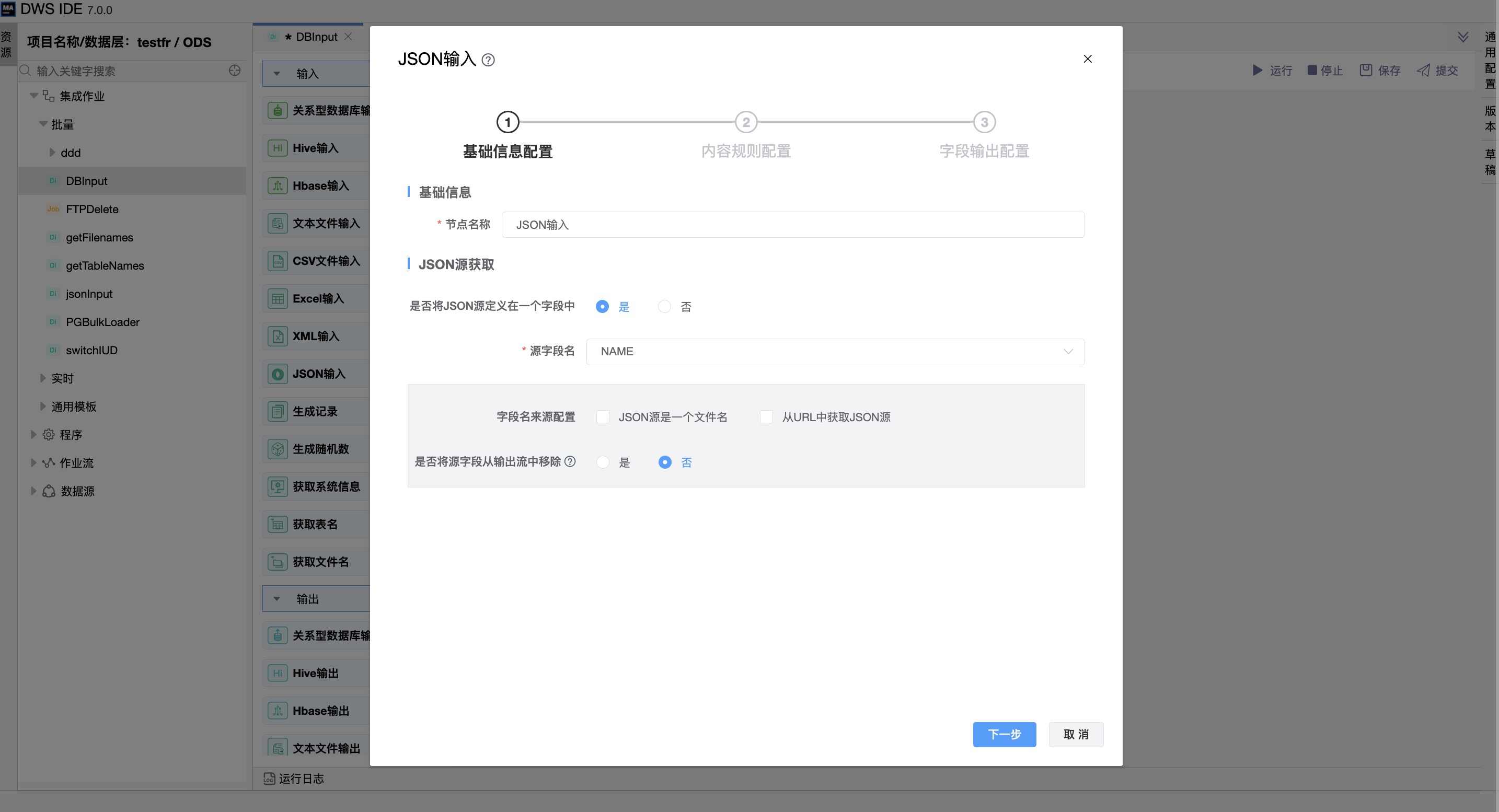
 “是否将JSON源定义在一个字段中”:是
“是否将JSON源定义在一个字段中”:是
选择将JSON源定义在一个字段中,此时该组件连接上一节点,源字段名的数据便是从上一节点获取的。
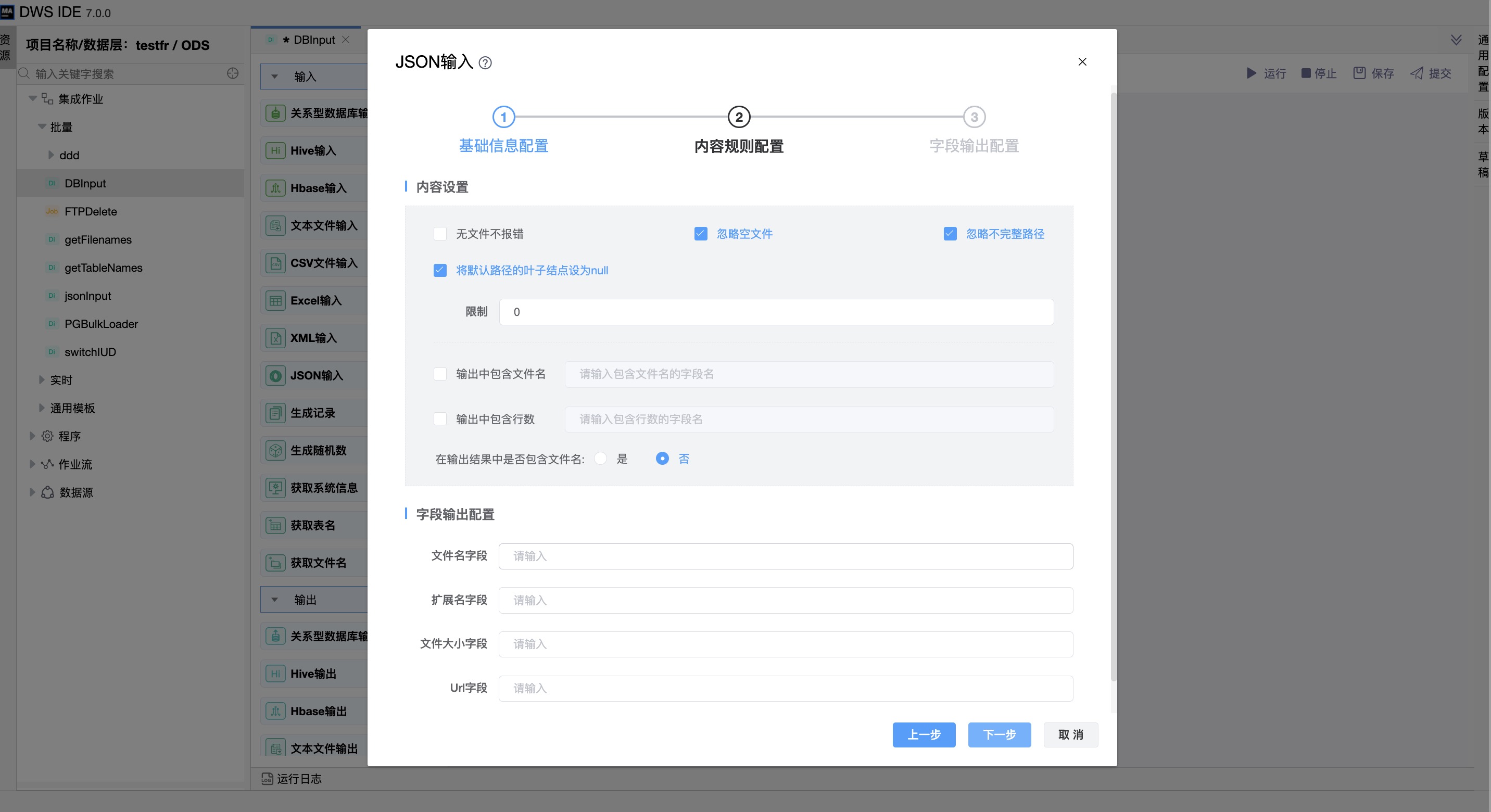
《内容规则配置》
《字段输出配置》
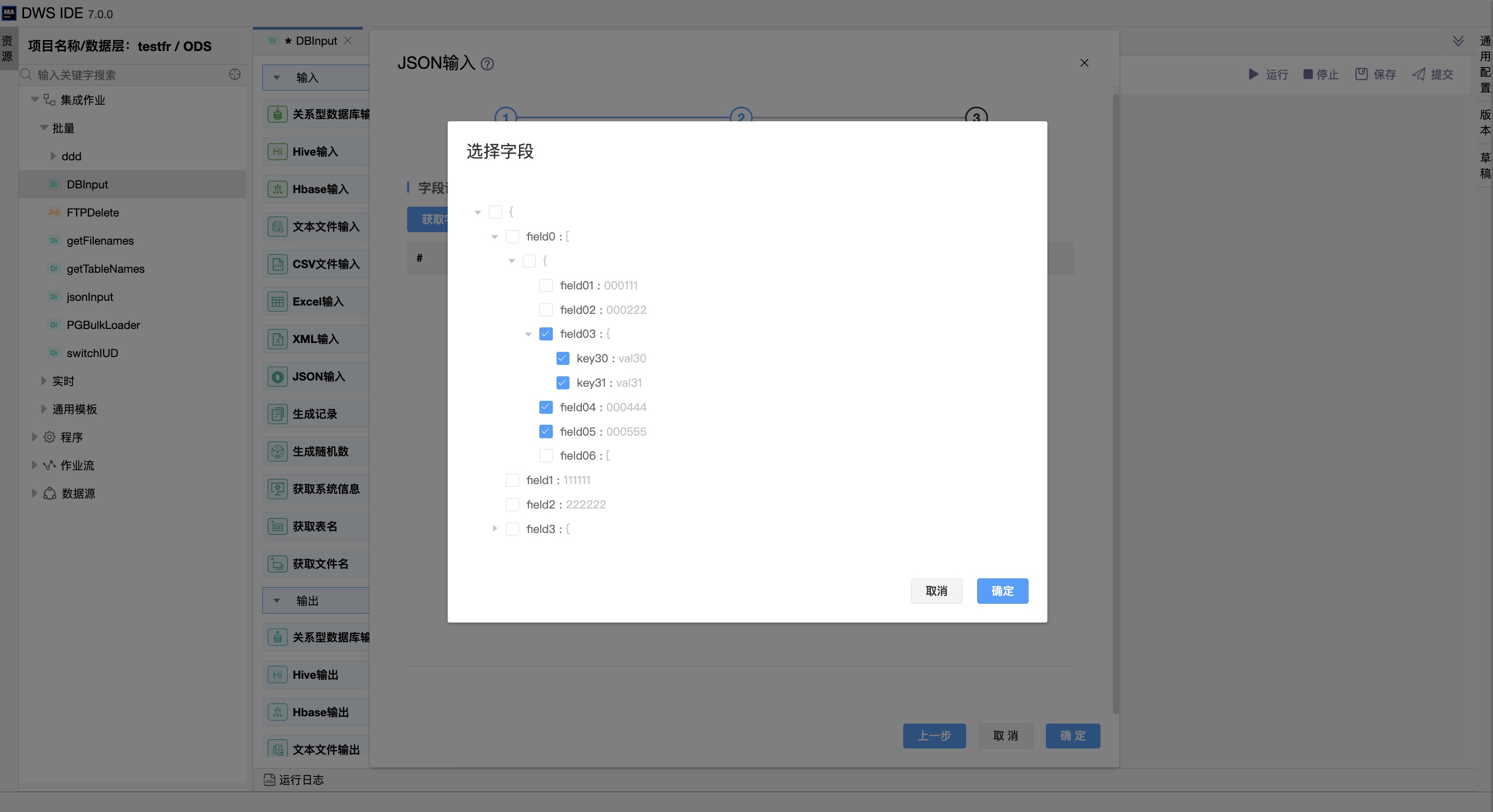
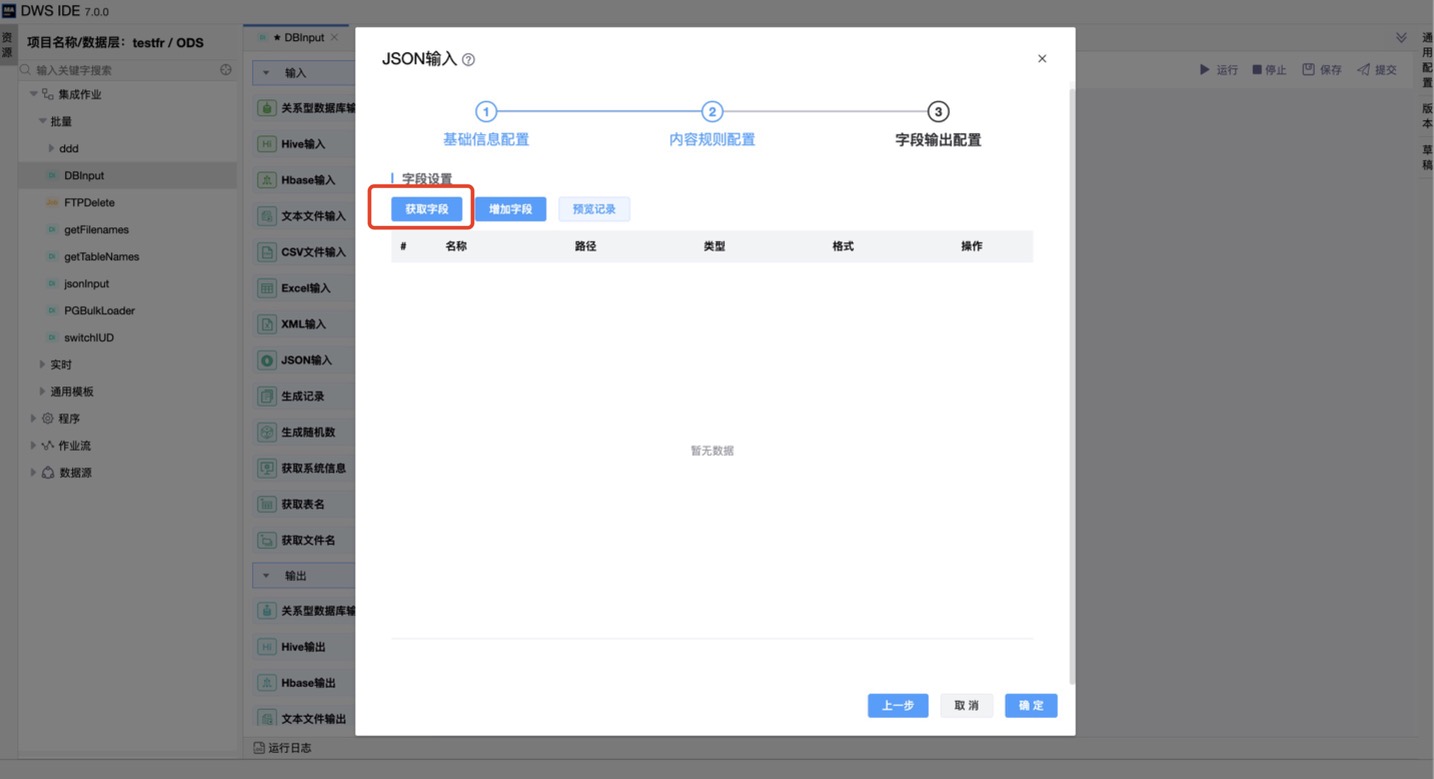 点击获取字段后,会弹出当前json文件读出的数据(树形展示的键值对),直观查看当前读取json的内容格式。
点击获取字段后,会弹出当前json文件读出的数据(树形展示的键值对),直观查看当前读取json的内容格式。
选择并确认后,会生成相应的JSONPath-路径,用于解析提取给定JSON文档的部分内容。

参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 是否将XML源定义在一个字段中 | 选择从前面定义的字段检索源。选择后,设置一下字段可用:Select field(从字段获取源字段名)、Use field as file names(JSON源是一个文件名)、Read source as URL(从URL获取JSON源) |
| 源字段名 | JSON源字段名选择。 |
| JSON源是一个文件名 | 选中表示源是文件名。 |
| 源字从URL获取JSON源段名 | 选中表示是否应该以URL的形式访问源。 |
| 选择类型 | 可选择“HDFS”类型或“LOCAL”类型。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(HDFS)的数据源进行选择。 |
| 文件或路径 | 如果源未在字段中定义,请指定源文件。 |
| 正则表达式 | 指定一个正则表达式来匹配指定目录中的文件名。 |
| 正则表达式(排除) | 指定一个正则表达式以排除指定目录中的文件名。 |
| 无文件不报错 | 当没有文件可供处理时,选择继续。 |
| 忽略空文件 | 选择跳过空文件。清除后,空文件将导致进程失败并停止。 |
| 忽略不完整路径 | 当出现错误(1)没有字段匹配JSON路径或(2)所有值都为null时,选择继续处理文件。清除后,发生错误时不再处理其他行。 |
| 将默认路径的叶子节点设为null | 如果选中,为缺少的路径返回一个null值。 |
| 限制 | 指定从该步骤生成的记录数量的限制。当设置为0时,结果不受限制。 |
| 输出中包含文件名 | 如果选中,则在结果中添加具有文件名的字符串字段。 |
| 输出中包含行数 | 选择此选项可在结果中添加带有行号的整数字段。 |
| 添加文件名到结果 | 选择将已处理文件添加到结果文件列表。 |
| 文件名字段 | 指定包含不带路径信息但带扩展名的文件名的字段。 |
| 扩展名字段 | 指定包含文件名扩展名的字段。 |
| 文件大小字段 | 指定包含数据大小的字段 |
| Uri字段 | 指定包含URI的字段。 |
| 字段设置 | 名称:映射到JSON输入流中相应字段的字段的名称。 路径:JSON输入流中字段名的完整路径。通过在路径中添加星号*,可以检索所有记录。 类型:输入字段的数据类型。 格式:用于转换原始字段格式的可选掩码。有关此步骤中可以使用的通用有效日期和数字格式的信息。 |
# 生成记录
功能介绍:该组件用于测试目的,生成固定数量的行。
使用场景:当我们想将一部分文本数据变成数据行,每个字段作为一个数据行的一个列,那么我们可以利用这个组件。
例如:
您希望在12个月内正好生成12行。有时,您可以使用“生成记录”来生成一行,该行是转换的起始点。
您可以生成一行,其中包含两个或三个字段值,您可以使用这些字段值参数化SQL,然后生成实际的行。
图标:

组件界面:
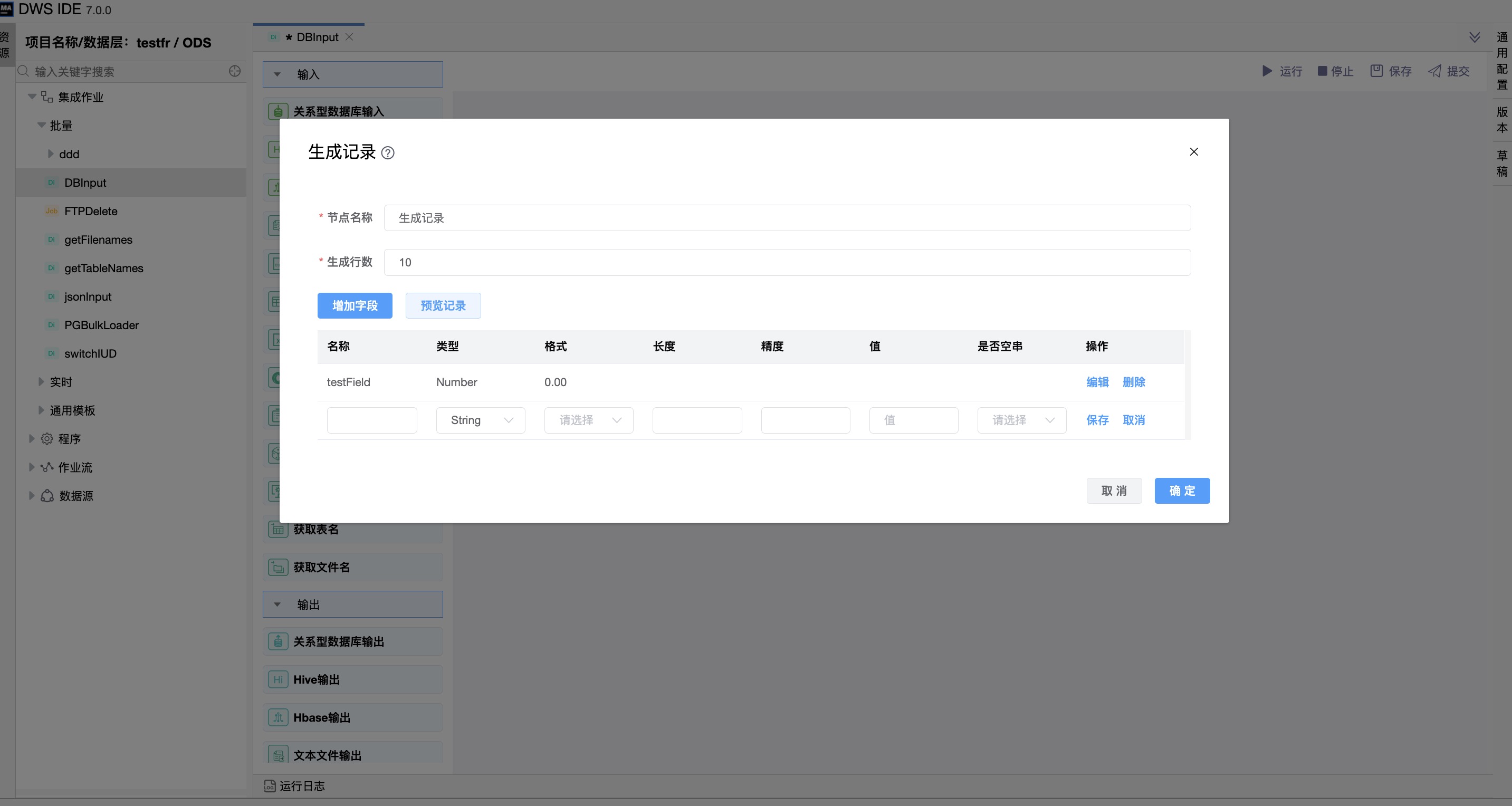
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 生成行数 | 设置要生成的最大行数。 |
| 字段 | 在这个表中,您可以配置生成的行(可选)的结构和值。 |
# 生成随机数
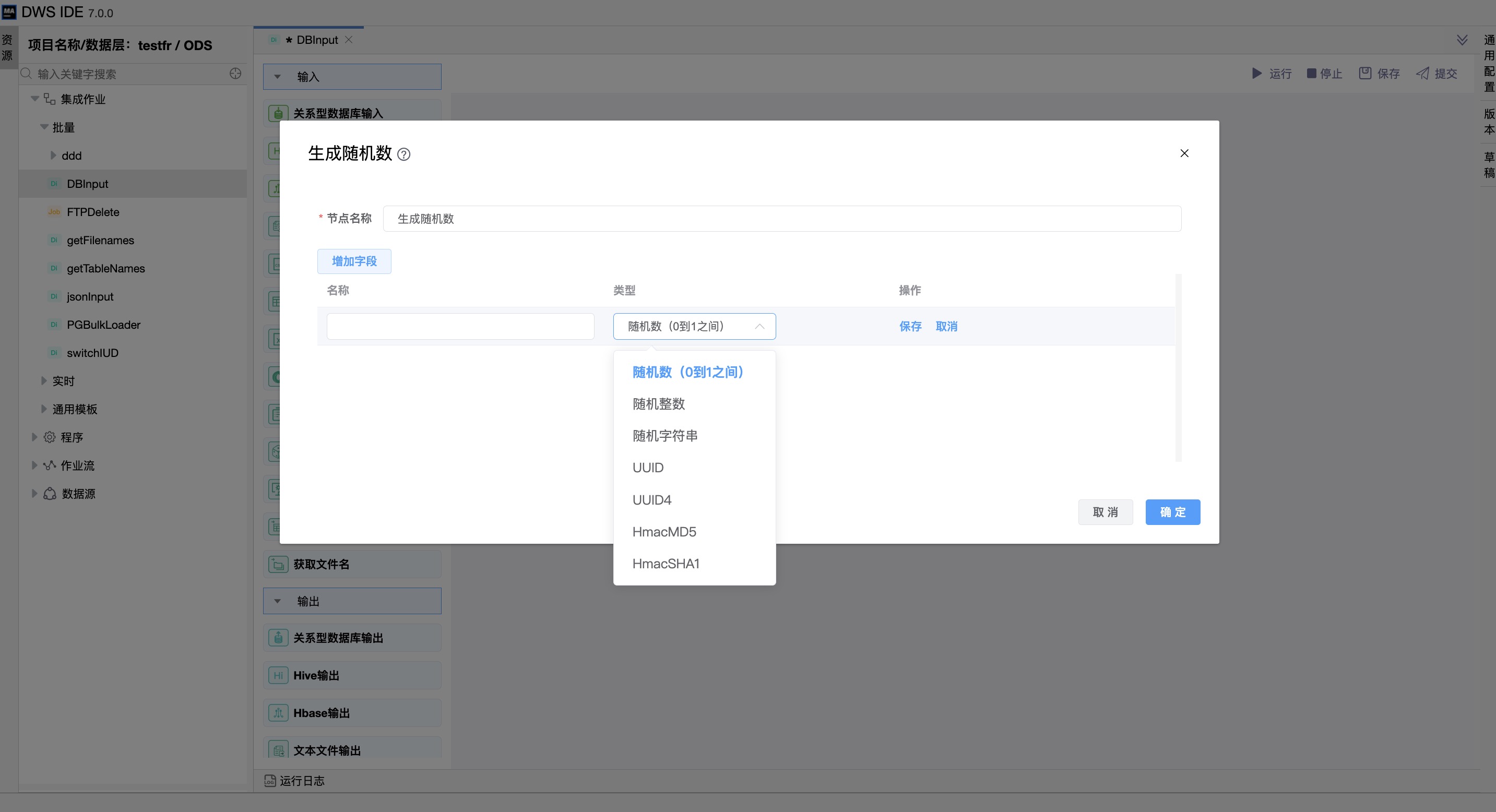
功能介绍:该该组件用于在转换模型中生成随机数。支持生成如下 7 种类型的随机数:
随机数(1到10之间):生成0到10之间的随机数。
随机整数:生成一个32位的随机整数。
随机字符串:基于64位长随机值生成随机字符串。
UUID:统一唯一标识符。
UUID4:统一唯一标识符类型4。
HmacMD5:HmacMD5随机消息认证码。
HmacSHA1:HmacSHA1随机消息认证码。
使用场景:在使用Kettle进行数据入库的时候,经常会涉及到为ID字段生成唯一标识,而UUID通常是我们生成唯一表示的选择,这个时候就需要使用到“生成随机数”功能组件,通过“生成随机数”可以生成UUID。
图标:

组件界面:
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 字段 | 在这个表中,您可以配置输入字段名和随机数类型。 |
# 获取系统信息
功能介绍:该组件用于从系统环境中检索系统信息。您可以在其中指定一个名称,并将其分配给要检索的任何可用系统信息类型。
使用场景:从Kettle环境中检索系统信息。
该组件包括一个表,您可以在其中指定一个名称,并将其分配给您想要检索的任何可用系统信息类型。此步骤生成单行,其中包含所请求信息的字段。
它还可以接受任意数量的输入流,聚合此步骤定义的任何字段,并将合并后的结果发送到输出流。
图标:

组件界面:
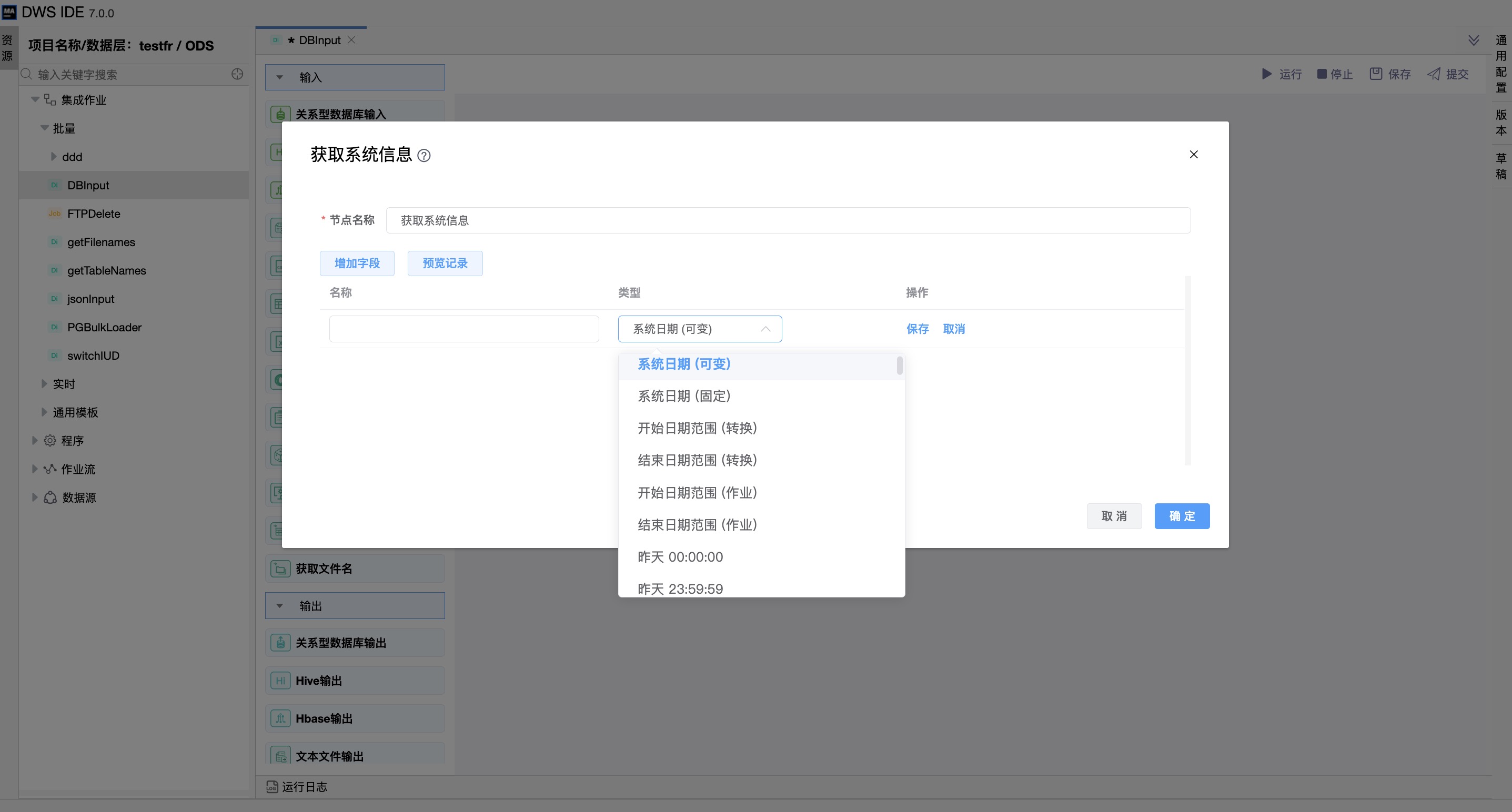
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 字段 | 可用系统数据类型的列表。 |
# 获取表名
功能介绍:获取指定数据库下所有的数据表名。
使用场景:获取指定数据库下所有的数据表名。
图标:
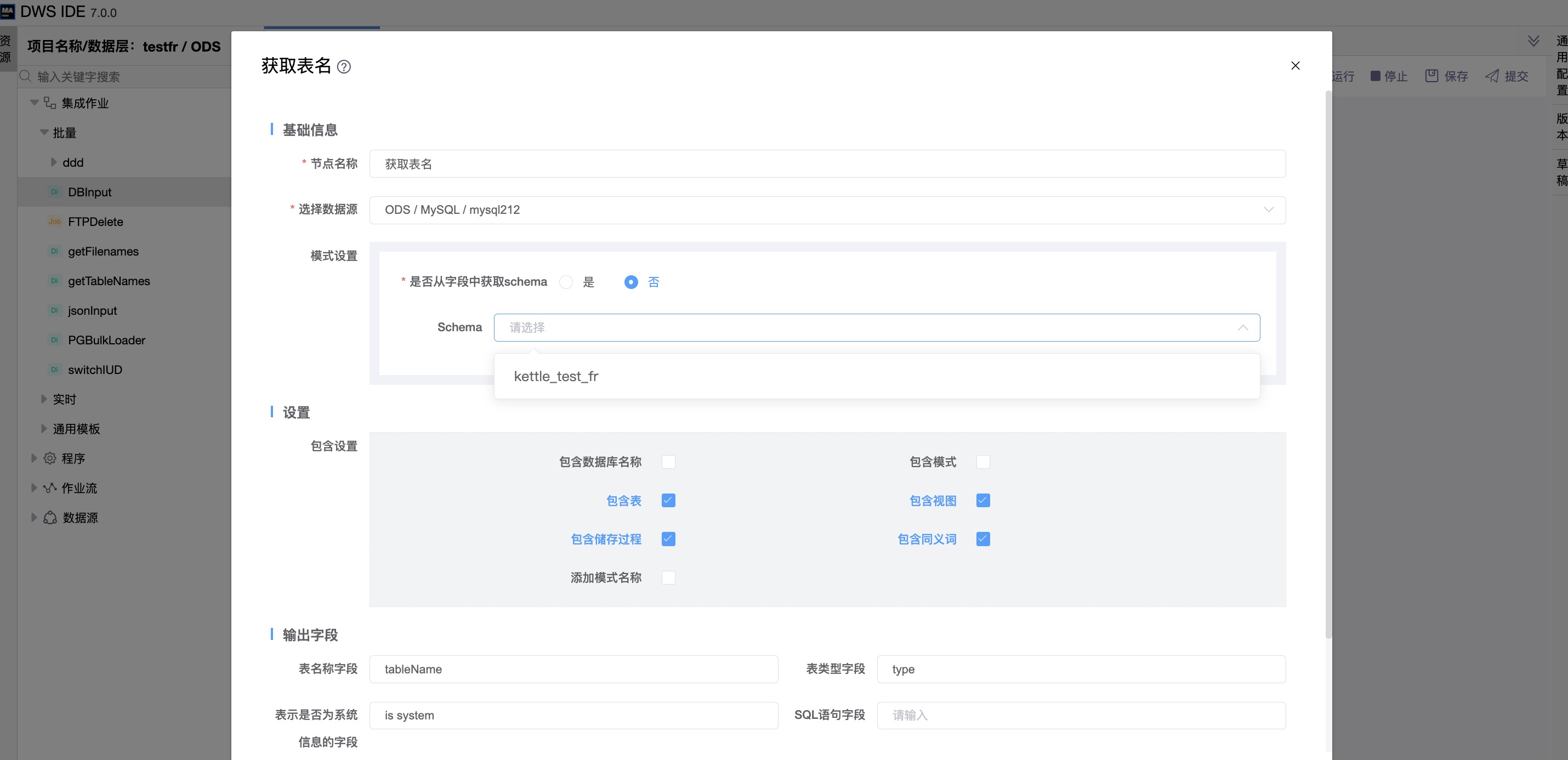
组件界面:
是否从字段中获取schema:否
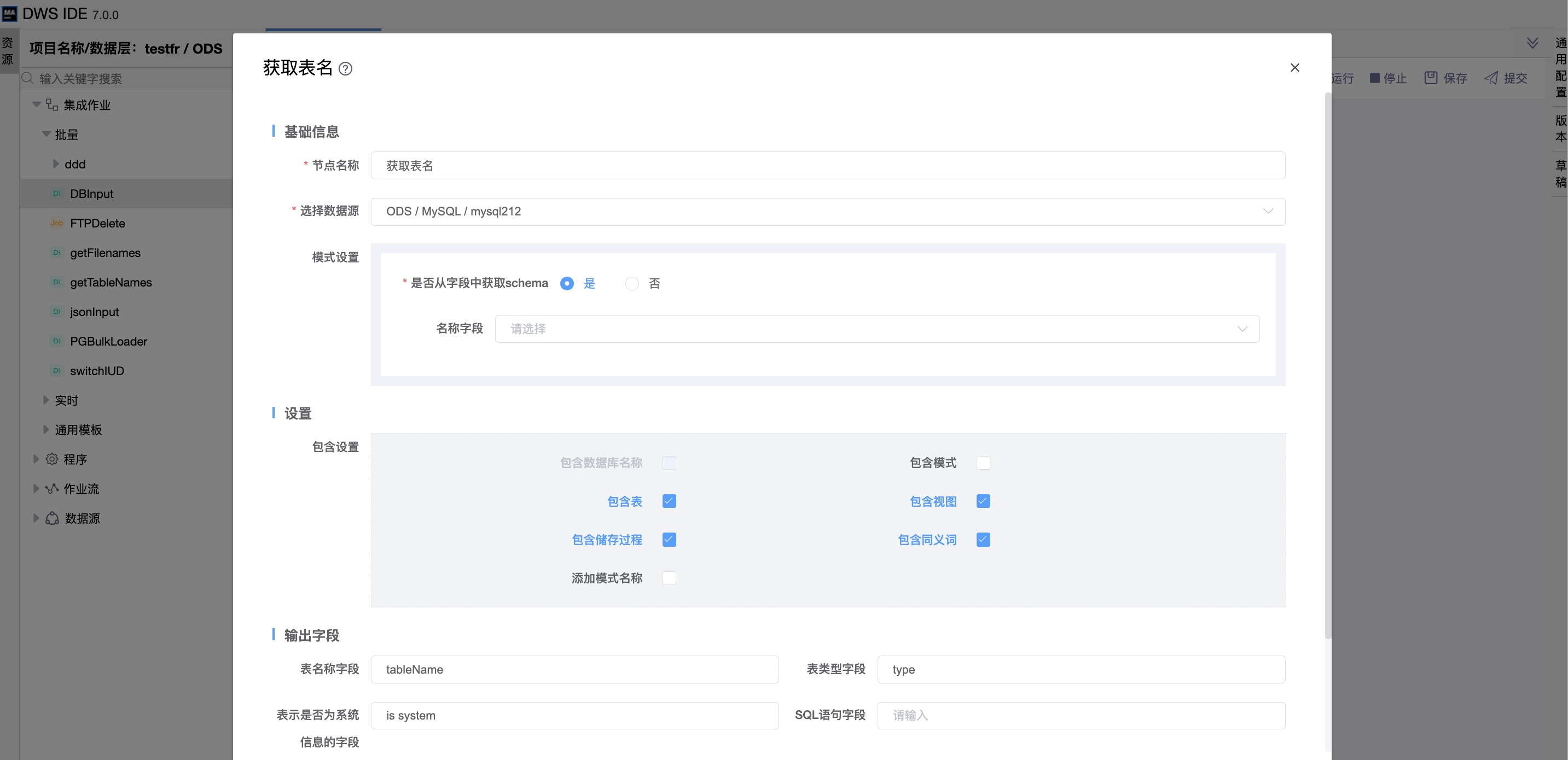
 是否从字段中获取schema:是
是否从字段中获取schema:是
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(MySQL,SQLServer,Oracle,DB2,PostgreSQL,GBase,DM,ClickHouse,Kingbase)的数据源进行选择。 |
| 是否从字段中获取schema | 选择是,则须从上一节点输出的字段中选择“名称字段”。 |
| 包含数据库名称 | 提取的表名信息是否包含数据库名称。 |
| 包含模式 | 提取的表名信息是否包含模式名称。 |
| 表名称字段 | 设置表名使用的变量。 |
| 表类型字段 | 设置表类型使用的变量 |
| 表示是否为系统信息的字段 | 设置判断“是否为系统信息”的变量。 |
| SQL语句字段 | 设置SQL语句使用的变量。 |
# 获取文件名
功能介绍:通过“获取文件名”组件,您可以获取与文件系统上的文件名相关的信息。检索到的文件名作为行添加到流中。
使用场景:获取指定文件夹下的文件名 ${Internal.Entry.Current.Directory}\输入\文件夹。
在这一步的输出字段是:
文件名-完整的文件名,包括路径(/tmp/kettle/somefile.txt)
Short_filename -只有文件名,没有路径(somefile.txt)
路径-只有路径(/tmp/kettle/)
类型
存在
ishidden
isreadable
iswriteable
lastmodifiedtime
大小
扩展
uri
rooturi
注意:如果您没有文件,那么步骤(和转换)不会中止。如果您想要中止转换,您可以使用带有一些逻辑的检测空流步骤(参见附带的示例GetFileNamesAbortExample.ktr)。还可以通过“检查是否存在文件”作业条目来检查作业中是否没有文件和Abort。
图标:
组件界面:
《基础配置》
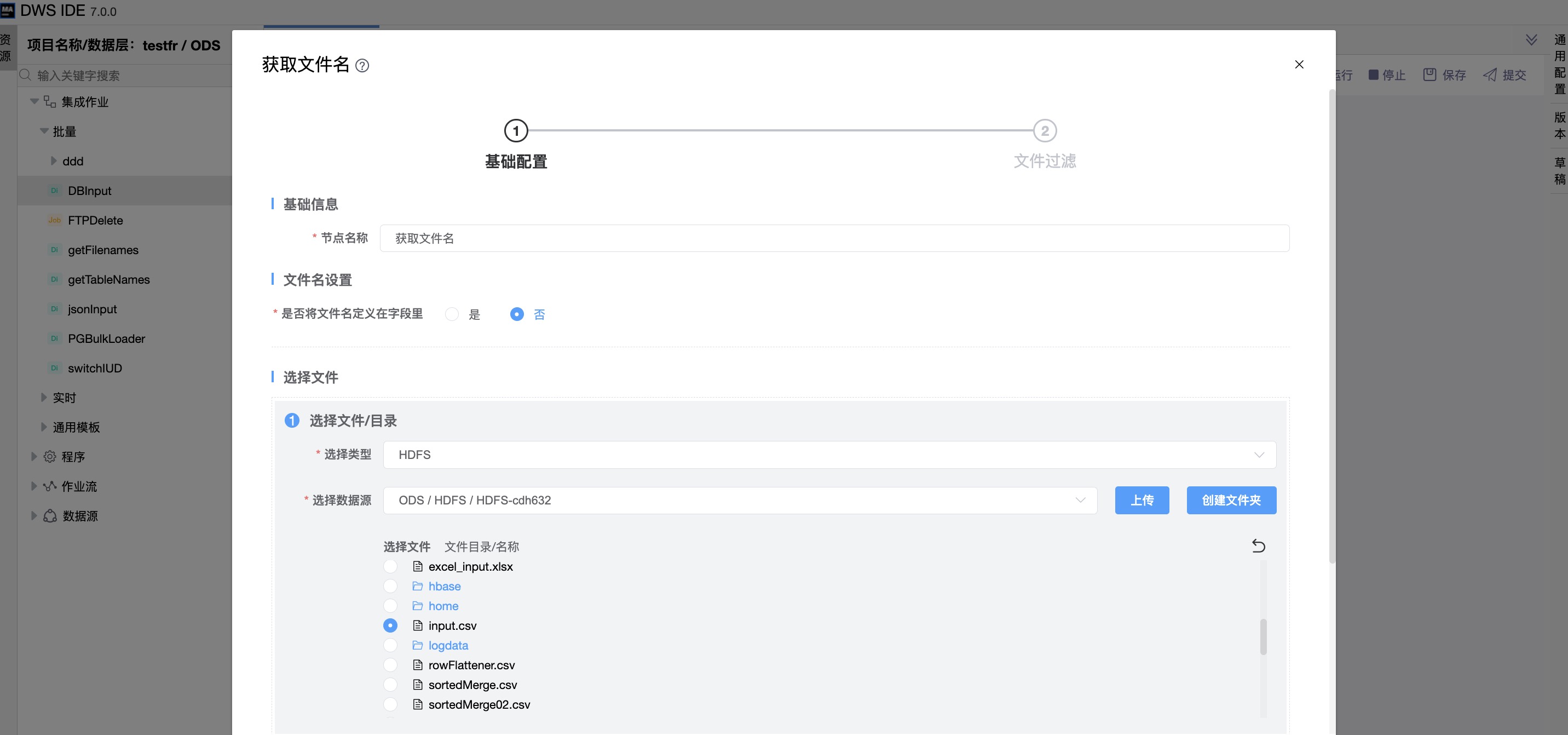
是否将文件名定义在字段里:否
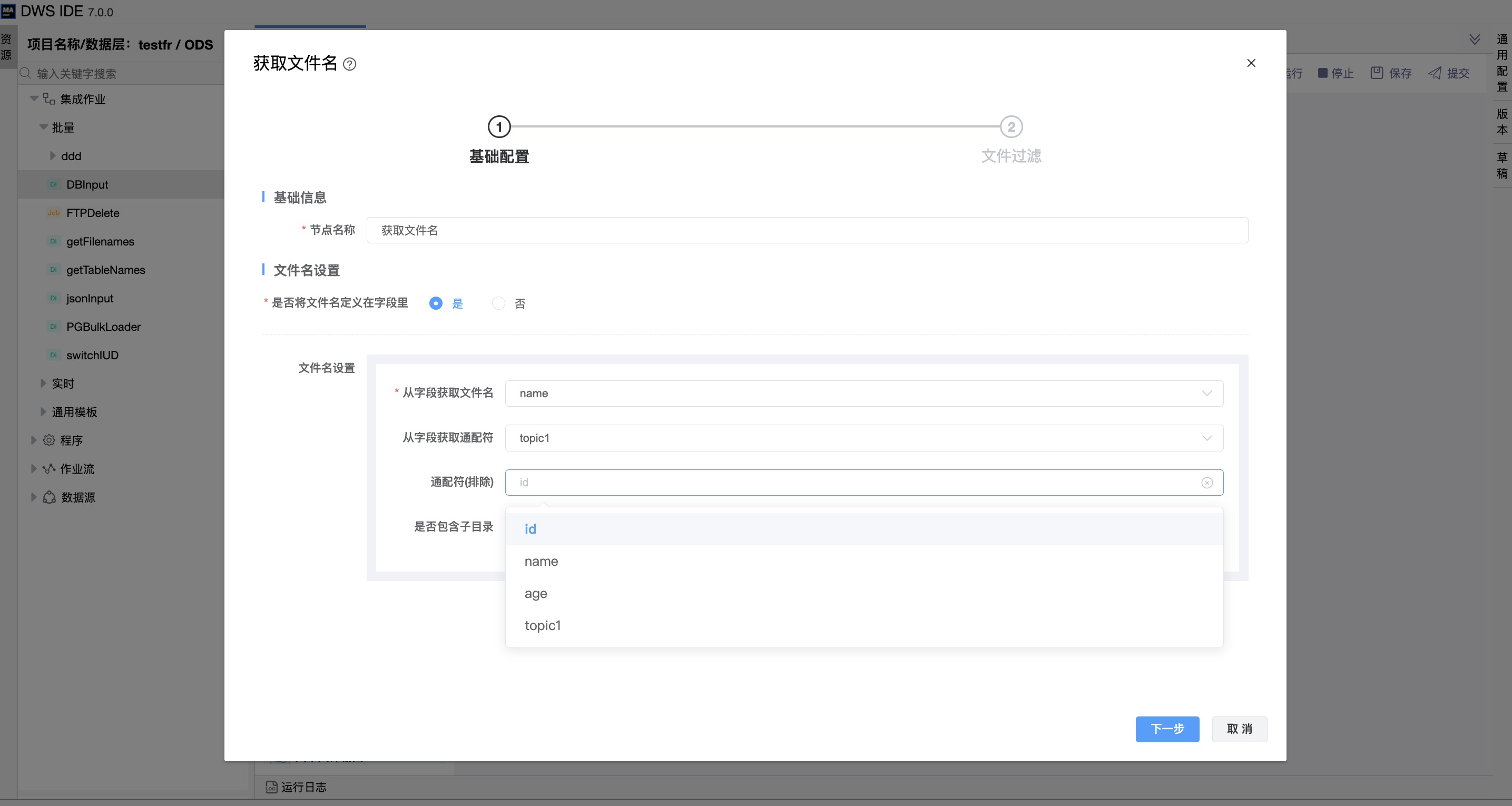
 是否将文件名定义在字段里:是
是否将文件名定义在字段里:是
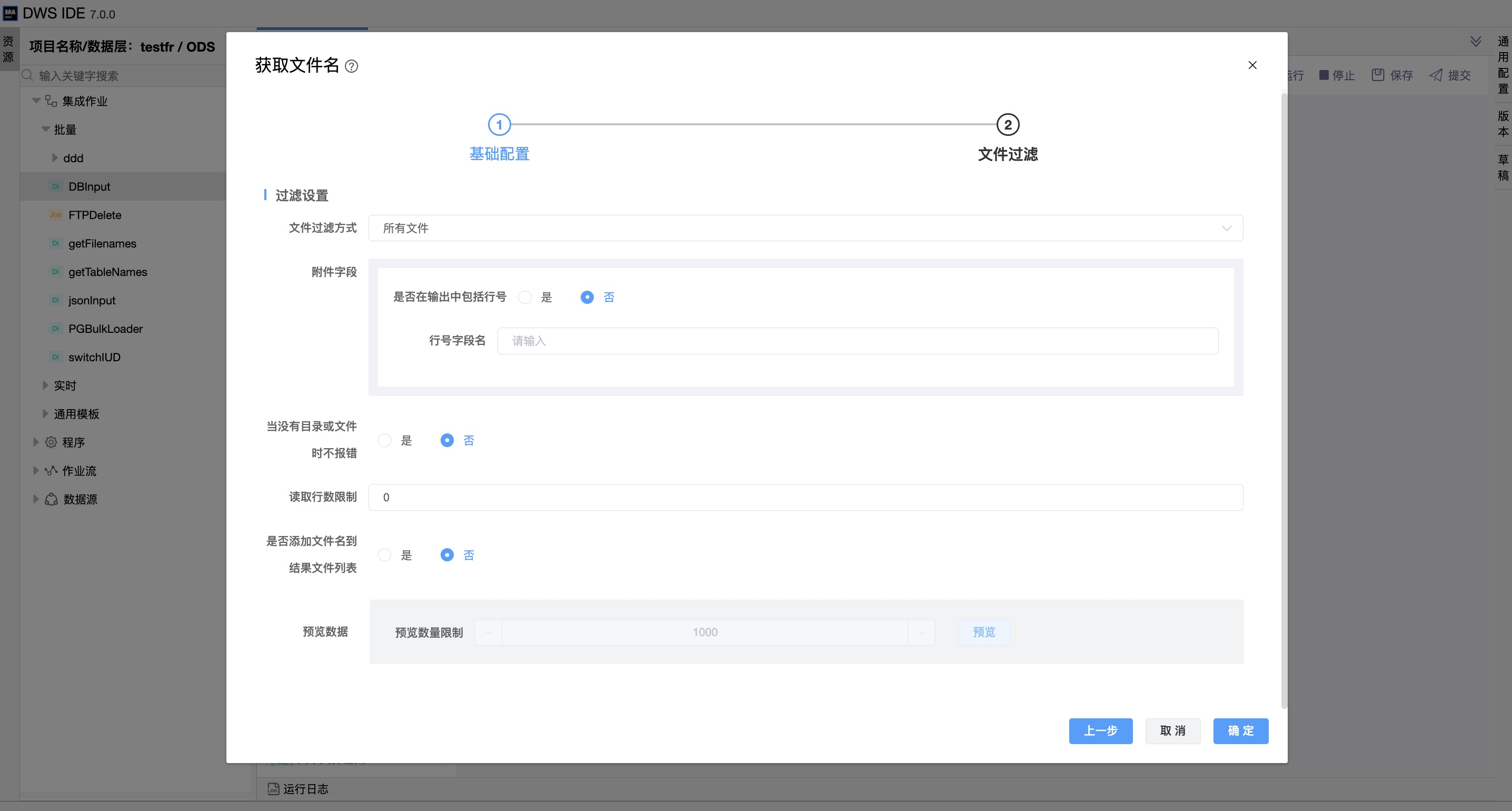
 《文件过滤》
《文件过滤》
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 是否将文件名定以在字段里 | |
| 选择类型 | 可选择“HDFS”类型或“LOCAL”类型。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(HDFS)的数据源进行选择。 |
| 文件或路径 | 如果未在字段中定义文件名,请指定源文件获取位置。 |
| 正则表达式 | 指定一个正则表达式来匹配指定目录中的文件名。 |
| 正则表达式(排除) | 指定一个正则表达式以排除指定目录中的文件名。 |
| 从字段获取文件名 | 若选择了“将文件名定义在字段里”,则需要从上一节点输出的字段中选择设置文件名的变量。 |
| 从字段获取通配符 | 若选择了“将文件名定义在字段里”,则需要从上一节点输出的字段中选择设置通配符的变量。 |
| 通配符(排除) | 若选择了“将文件名定义在字段里”,则需要从上一节点输出的字段中选择设置通配符(排除)的变量。 |
| 文件过滤方式 | 可选择获取“所有文件”, 也可以选择单独“只获取文件”和“只获取目录”。 |
| 没有目录或文件时不报错 | 没有目录或文件时不报错。 |
| 是否添加文件名到结果文件列表 | 选择将已处理文件名添加到结果文件列表。 |