# CDC同步关系型数据库示例
本示例主要演示从Mysql empsinfo表中实时读取数据,通过FieldMapper组件进行字段配置,去掉EMPNO字段后,将数据写入Mysql empsinfo_miggration表中。
主要步骤如下:
# 环境准备说明
增量同步与多表迁移的向导界面类似,且都支持多表增量同步。与多表迁移的不同点在于,增量同步不是一次性将数据从源表同步到目标表,而是源表的数据发生变化(增加、修改、删除)时才会同步到目标表。
⚠️ 提示:
1、源表和目标表都必须定义主键;
2、目标表不存在时,模型运行时会自动创建表,和源表结构一致;
3、目标表存在时,要确保源表与目标表的数据结构、字段类型一致,且定义主键。同时源表开启了 cdc 配置。
增量同步支持的数据源如下:
| 数据源类型 | 版本 | 驱动 |
|---|---|---|
| MySQL-CDC | MySQL: 5.6,5.7,8.0.x | JDBC Driver: 8.0.28 |
| PostgreSQL-CDC | PostgresSQL: 9.6, 10, 11, 12, 13,14 | JDBC Driver: 42.5.1 |
| SQLServer-CDC | Sqlserver: 2012, 2014, 2016, 2017, 2019 | JDBC Driver: 9.4.1.jre8 |
| MongoDB-CDC | MongoDB: 3.12.11 | JDBC Driver: 3.12.11 |
| Oracle-CDC | Oracle: 12c | JDBC Driver: 19.3.0.0 |
CDC 增量同步作业需要提前对数据库进行配置,具体的配置方法如下:
# MySQL-CDC 配置
1、修改 MySQL 配置,开启 binlog 功能,并设置 binlog 格式为 row 模式。
binlog 是 MySQL 的二进制日志文件,它记录了数据库中的所有变更操作,Mysql CDC Connector 会通过 binlog 来捕获数据的变化。
参考配置如下:
[mysqld]
# ----------------------------------------------
# Enable the binlog for replication & CDC
# ----------------------------------------------
# Enable binary replication log and set the prefix, expiration, and log format.
# The prefix is arbitrary, expiration can be short for integration tests but would
# be longer on a production system. Row-level info is required for ingest to work.
# Server ID is required, but this will vary on production systems
server-id = 223344
log_bin = mysql-bin
expire_logs_days = 1
binlog_format = row
# enable gtid mode
gtid_mode = on
enforce_gtid_consistency = on
2、添加权限(如果是非 root 用户)
MySQL Binlog 权限需要三个权限 SELECT, REPLICATION SLAVE, REPLICATION CLIENT:
Select 权限代表允许从表中查看数据。
Replication client 权限代表允许执行show master status,show slave status,show binary logs 命令。
Replication slave 权限代表允许slave主机通过此用户连接master以便建立主从复制关系。
3、执行命令(如果是非 root 用户)
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'dws'@'%' IDENTIFIED BY 'dws';
# PostgreSQL-CDC 配置
1、修改 postgresql.conf 配置文件,参考配置如下:
# 更改wal日志方式为logical(方式有:minimal、replica 、logical )
wal_level = logical
# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots
max_replication_slots = 20
# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样
max_wal_senders = 20
# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s,0表示禁用)
wal_sender_timeout = 180s
2、开启权限
-- 更改复制标识包含更新和删除之前值
ALTER TABLE table_name REPLICA IDENTITY FULL;
-- 查看复制标识(为f标识说明设置成功)
select relreplident from pg_class where relname='table_name';
# SQL Server-CDC 配置
1、开启SQL Server CDC的必要条件
- 需要开启数据库 CDC
- 需要开启表 CDC
- 需要开启代理服务
- 磁盘要有足够的空间,保存日志文件
- 表必须要有主键或者是唯一索引
2、参考文档:https://support.huaweicloud.com/intl/zh-cn/usermanual-roma/fdi-ug-202009081.html
oracle
# MongoDB-CDC 配置
1、开启Mongodb CDC的必要条件
- MongoDB version: MongoDB version >= 4.0.
- Cluster deployment: replica sets or sharded clusters
- Storage Engine: WiredTiger Storage Engine.
- Permissions:changeStream and read(执行如下语句)
use admin;
db.createRole(
{
role: "strole",
privileges: [{
resource: { db: "", collection: "" },
actions: [
"splitVector",
"listDatabases",
"listCollections",
"collStats",
"find",
"changeStream" ]
}],
roles: [
{ role: 'read', db: 'config' }
]
}
);
db.createUser(
{
user: 'stuser',
pwd: 'stpw',
roles: [
{ role: 'strole', db: 'admin' }
]
}
);
2、配置 MongoDB 副本集 创建 mongo1.conf,参考配置如下:
# 端口默认
port = 27017
#数据目录
dbpath = /usr/local/Cellar/mongodb-community/7.0.0/data/db
#日志所在目录
logpath = /usr/local/Cellar/mongodb-community/7.0.0/data/logs/mongodb.log
#日志输出方式
logappend = true
# 在后台启动
fork=true
# 0.0.0.0 表示任意IP均可连接
bind_ip=0.0.0.0
#副本集名称
replSet=rs0
3、启动 MongoDB 节点,参考命令如下:
cd /usr/local/Cellar/mongodb-community/7.0.0/bin
启动命令:
mongod -f mongo.conf
4、初始化副本集
# 连接mongodb
./mongo mongodb://127.0.0.1:27017
use admin
# 设置变量
rs0= {
_id: "rs0",
members: [
{
_id: 0,
host: "127.0.0.1:27017"
},
]
}
# 执行初始化
rs.initiate(rs0)
# Oracle-CDC 配置
1、创建空文件目录存放Oracle归档日志和用户表空间。
mkdir -p /opt/oracle/oradata/recovery_area
mkdir -p /opt/oracle/oradata/ORCLCDB
chown -R oracle /opt/oracle/***
2、启用日志归档
以管理员身份登录并启用Oracle归档日志。
sqlplus /nolog;
connect sys as sysdba;
alter system set db_recovery_file_dest_size = 10G;
alter system set db_recovery_file_dest = '/opt/oracle/oradata/recovery_area' scope=spfile;
shutdown immediate;
startup mount;
alter database archivelog;
alter database open;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
archive log list;
3、用户赋权
以管理员身份登录,创建一个名为logminer_user的帐户,密码为“oracle”,并授予该帐户读取表和日志的权限。
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/ORCLCDB/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
CREATE USER logminer_user IDENTIFIED BY oracle DEFAULT TABLESPACE logminer_tbs QUOTA UNLIMITED ON logminer_tbs;
GRANT CREATE SESSION TO logminer_user;
GRANT SELECT ON V_$DATABASE to logminer_user;
GRANT SELECT ON V_$LOG TO logminer_user;
GRANT SELECT ON V_$LOGFILE TO logminer_user;
GRANT SELECT ON V_$LOGMNR_LOGS TO logminer_user;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO logminer_user;
GRANT SELECT ON V_$ARCHIVED_LOG TO logminer_user;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO logminer_user;
GRANT EXECUTE ON DBMS_LOGMNR TO logminer_user;
GRANT EXECUTE ON DBMS_LOGMNR_D TO logminer_user;
GRANT LOGMINING TO logminer_user;
GRANT SELECT ANY TABLE TO logminer_user;
GRANT ANALYZE ANY TO logminer_user;
# 准备数据
创建库example
创建表 empsinfo 和 empsinfo_miggration 分别作为源表和目标表,并给源表 INSERT 一些数据。
-- ---------------------------------------
-- Table structure for empsinfo
-- ---------------------------------------
DROP TABLE IF EXISTS `empsinfo`;
CREATE TABLE `empsinfo` (
`ID` int NOT NULL,
`NAME` varchar(10) DEFAULT NULL,
`AGE` decimal(3,0) DEFAULT NULL,
`EMPNO` int DEFAULT NULL,
PRIMARY KEY (`ID`)
);
-- ---------------------------------------
-- Table structure for empsinfo_miggration
-- ---------------------------------------
DROP TABLE IF EXISTS `empsinfo_miggration`;
CREATE TABLE `empsinfo_miggration` (
`ID` int NOT NULL,
`NAME` varchar(10) DEFAULT NULL,
`AGE` decimal(3,0) DEFAULT NULL,
`EMPNO` int DEFAULT NULL,
PRIMARY KEY (`ID`)
);
-- ----------------------------
-- Records of empsinfo
-- ----------------------------
BEGIN;
INSERT INTO `empsinfo` (`ID`, `NAME`, `AGE`, `EMPNO`) VALUES (10001, 'WARD', 25, 7521);
INSERT INTO `empsinfo` (`ID`, `NAME`, `AGE`, `EMPNO`) VALUES (10002, 'JONES', 32, 7566);
INSERT INTO `empsinfo` (`ID`, `NAME`, `AGE`, `EMPNO`) VALUES (10003, 'BLAKE', 15, 7698);
INSERT INTO `empsinfo` (`ID`, `NAME`, `AGE`, `EMPNO`) VALUES (10004, 'SCOTT', 53, 7788);
INSERT INTO `empsinfo` (`ID`, `NAME`, `AGE`, `EMPNO`) VALUES (10005, 'KING', 22, 7839);
COMMIT;
# 新建同步作业
点击数据同步上的【...】,选择弹出菜单【新建数据同步作业】,作业名称为:CDCSource-FieldMapper-JDBCSink。
# 拖拽图元
依次拖拽数据源中的CDC组件、转换中的FieldMapper组件和目标中的关系型数据库组件,依次连线。如下图所示:

# 配置组件属性
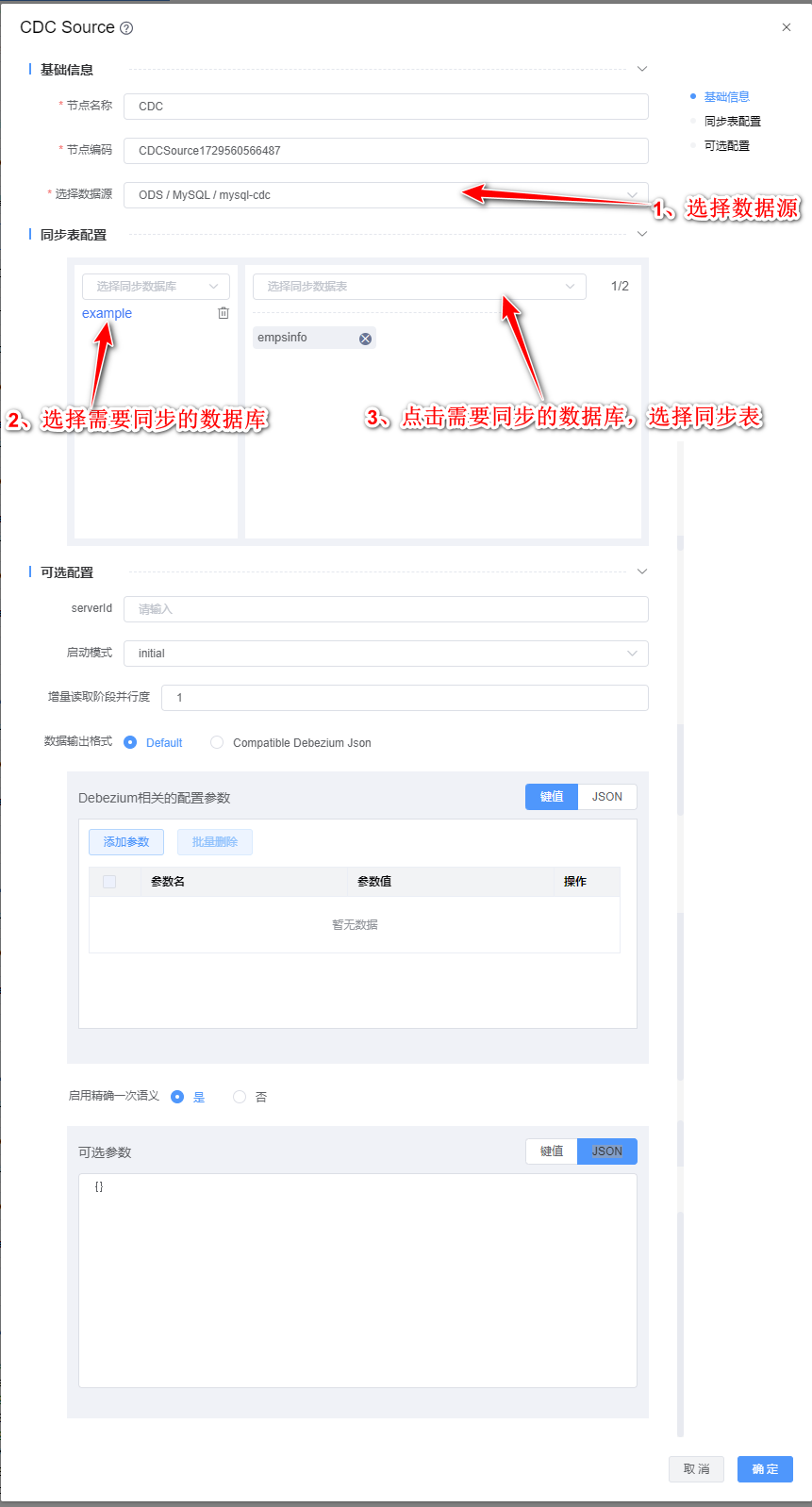
1、双击"CDC"组件,根据下图所示步骤依次配置。
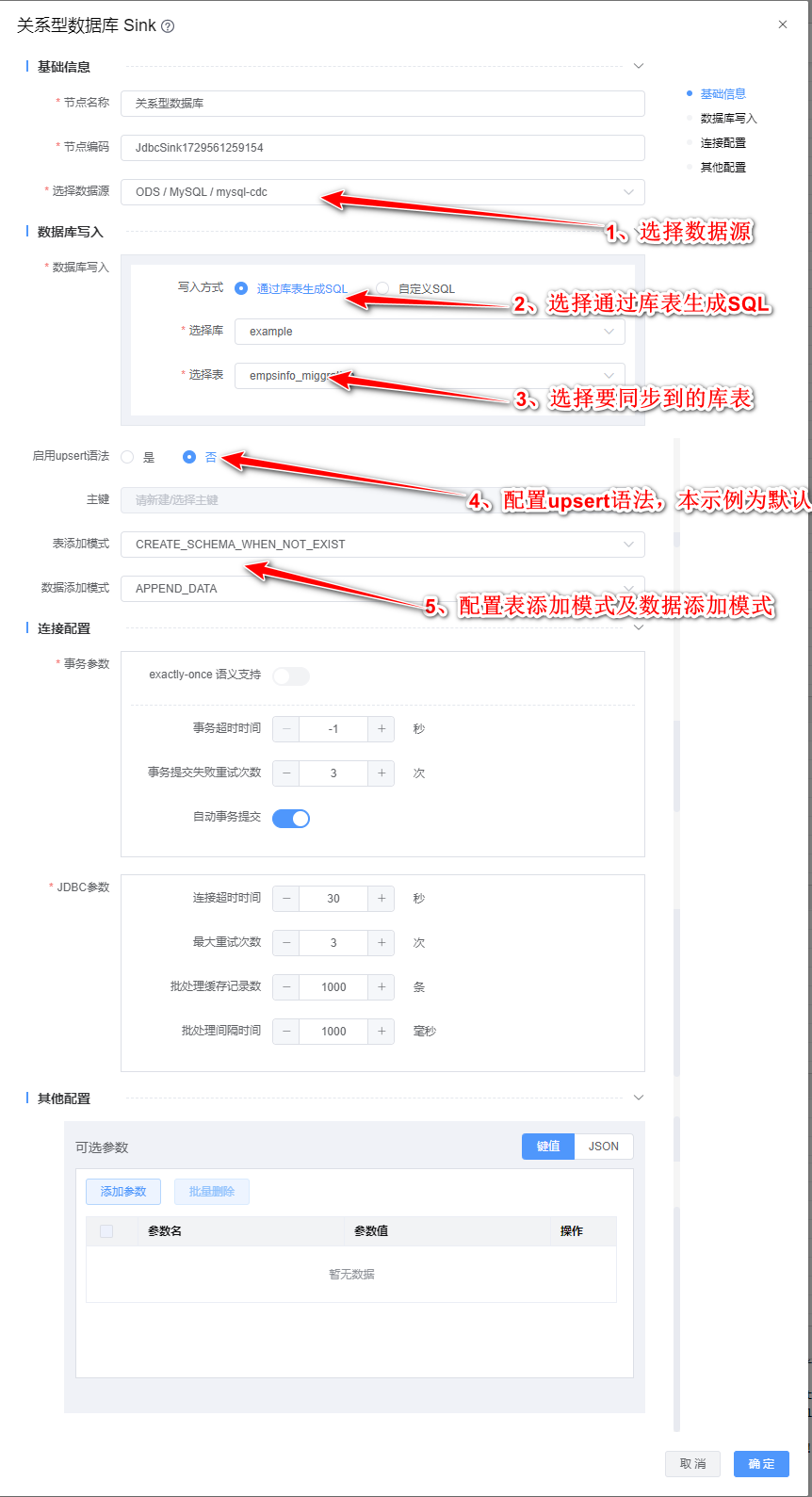
2、双击"关系型数据库"组件,根据下图所示步骤依次配置。
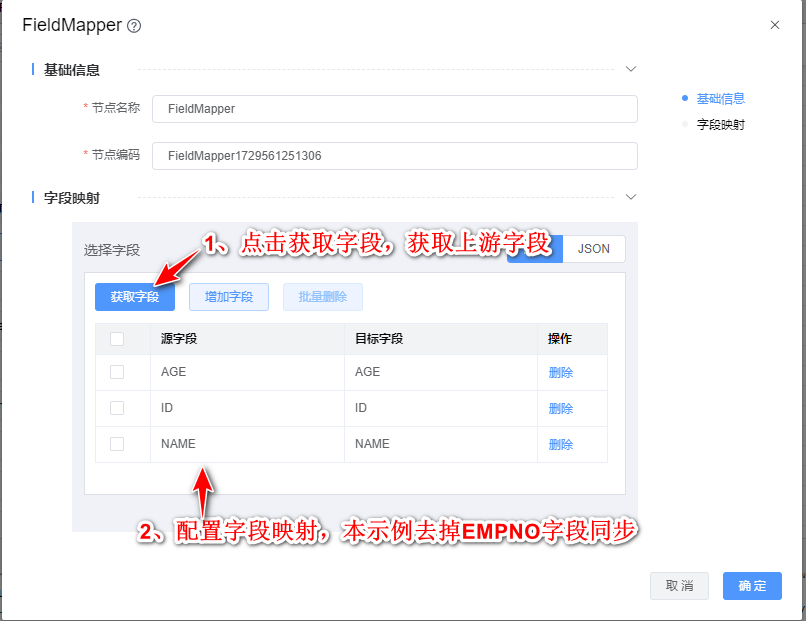
3、双击"FieldMapper"组件,根据下图所示步骤依次配置。
4、Ctrl+S保存该模型。
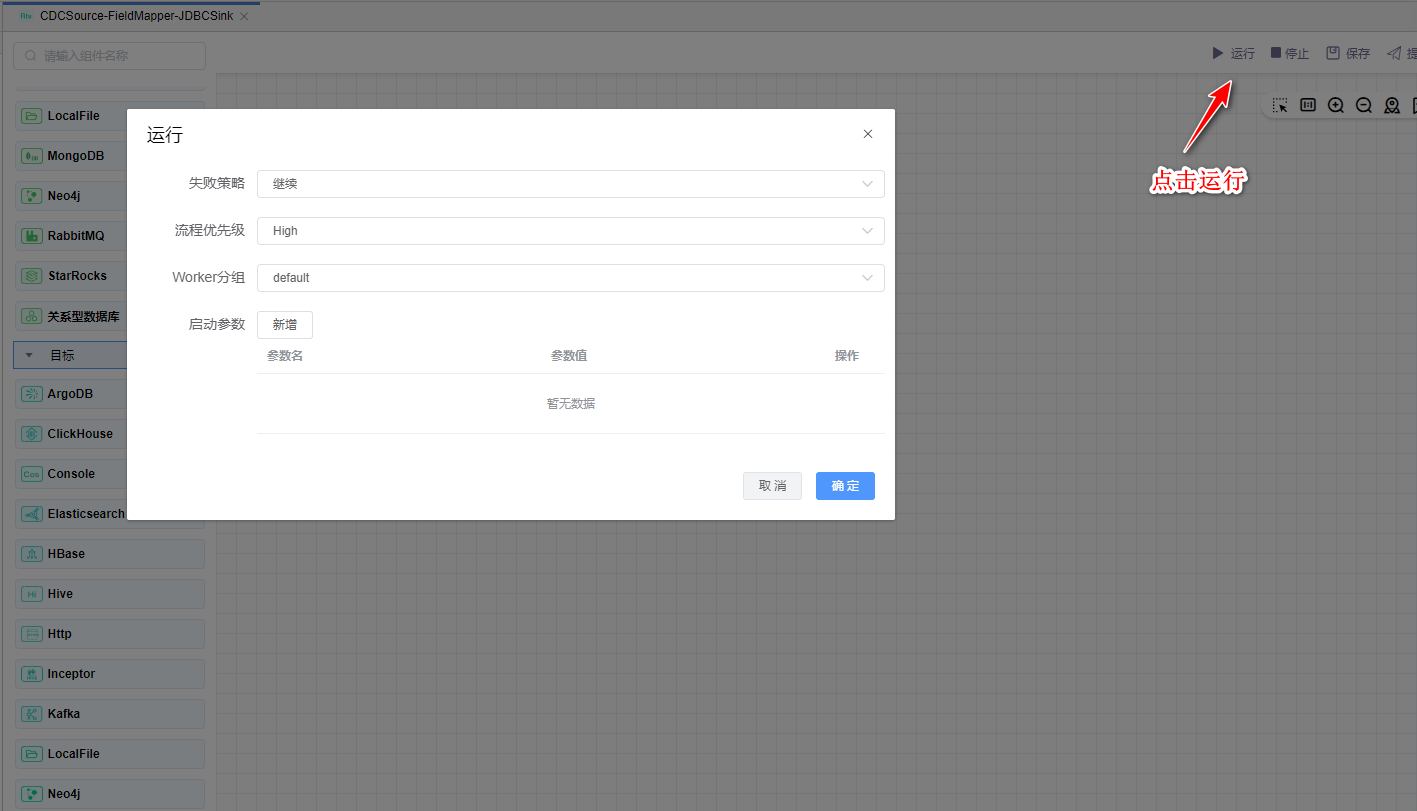
# 运行
点击【运行】按钮,可以运行已经开发完毕的场景,在日志栏可以看运行日志及运行结果。
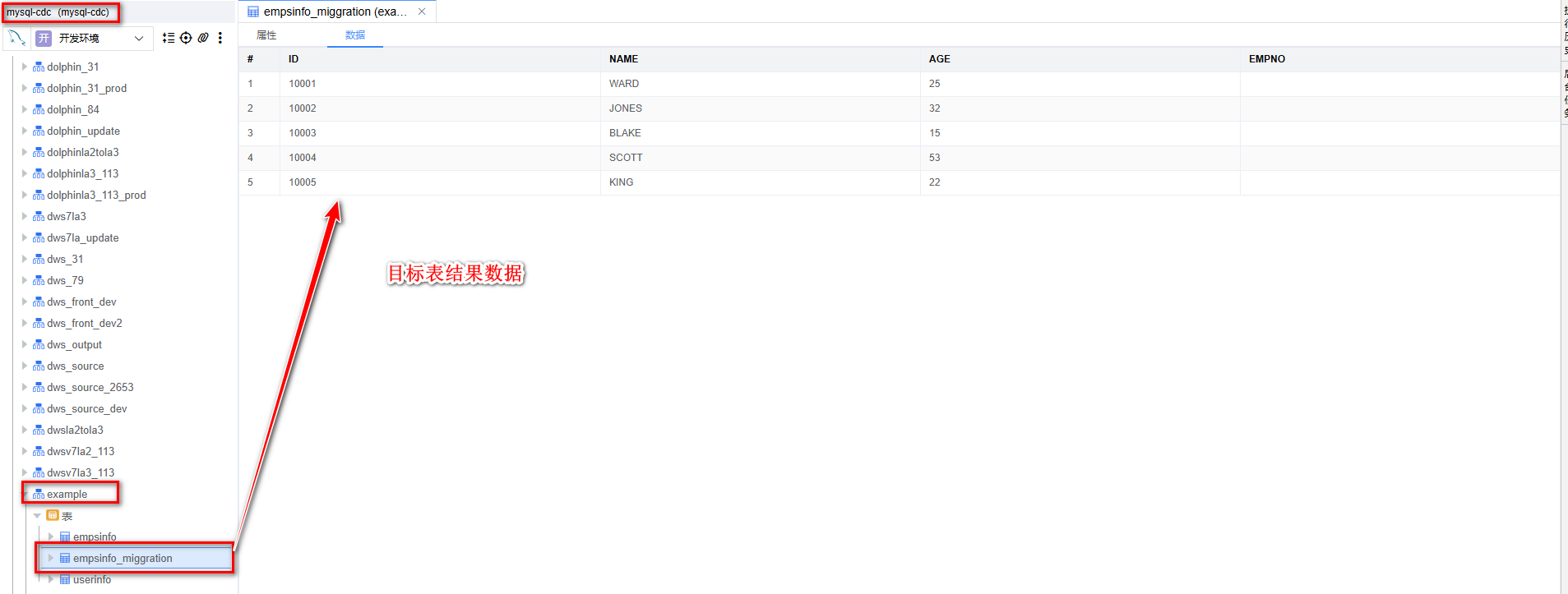
# 查看数据
从SQL客户端中去目标表查看 empsinfo 源表数据已经同步到 empsinfo_miggration 目标表中。
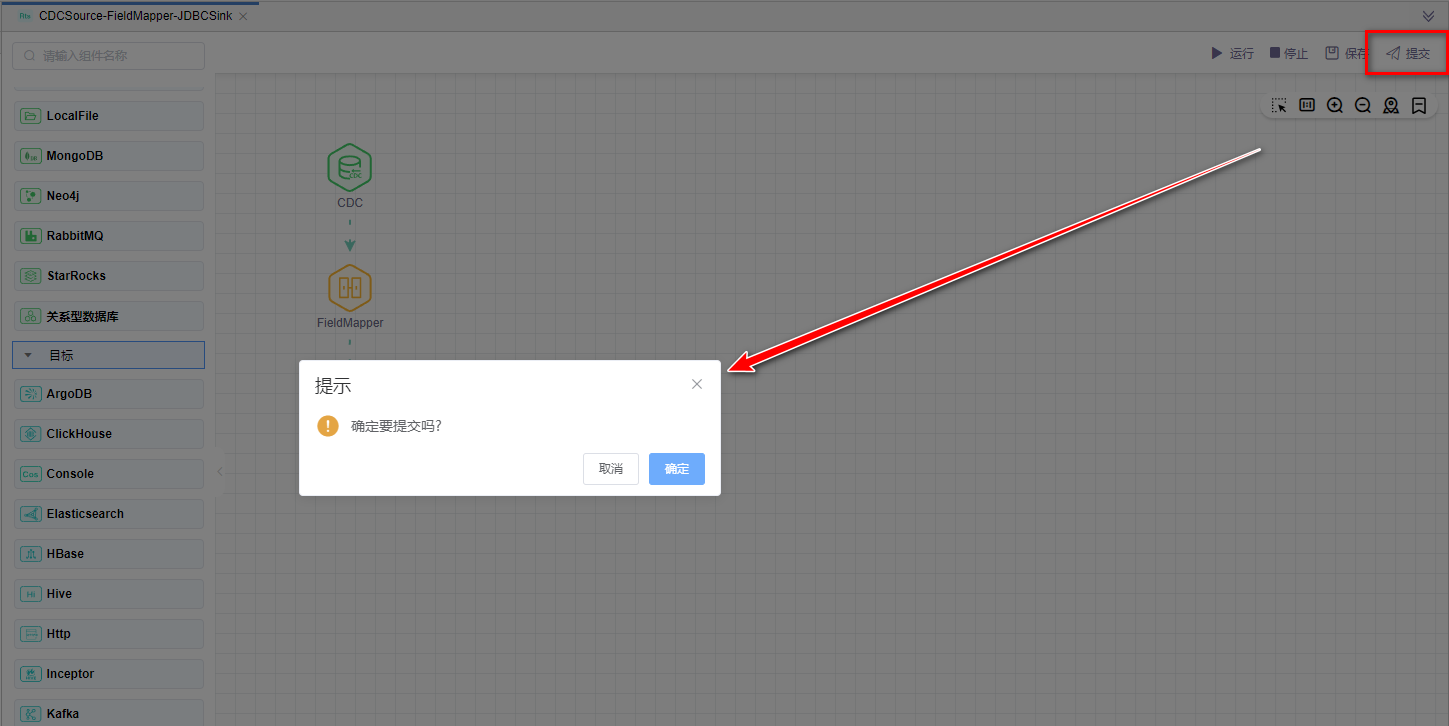
# 提交版本
当草稿运行正常后,点击【提交】按钮可以将该版本提交到作业调度,每次修改提交都会生成新的版本,可以看到提交的历史版本,并可以随意切换版本。
提交后的版本,可以在作业调度中进行"定时"调度配置。