
# 批量加载组件
本章节详细说明批量加载组件的功能及属性,具体如下:

# MySQL批量加载
功能介绍:MySQL 批量加载程序使用“将数据加载到表中”将数据从 Kettle 内部流式传输到命名管道......”到数据库中。
使用场景:
图标:

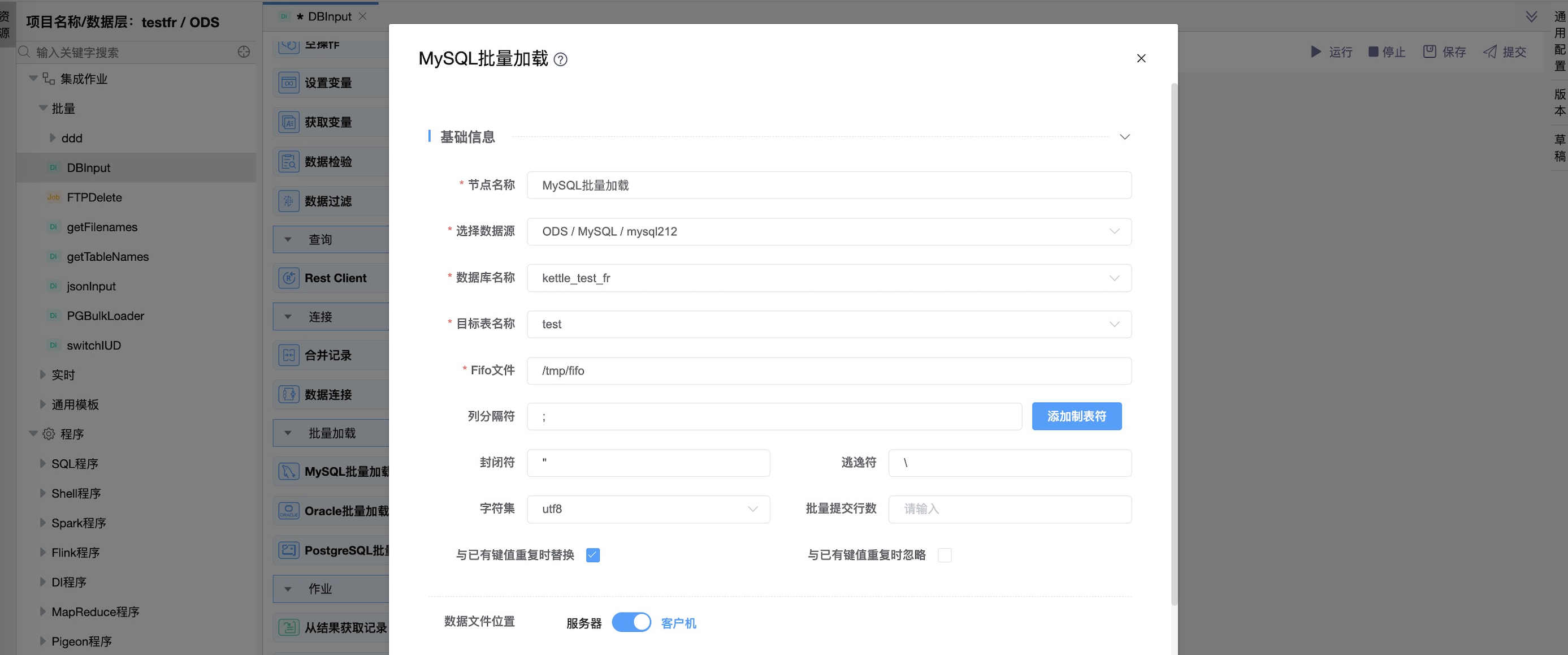
组件界面:
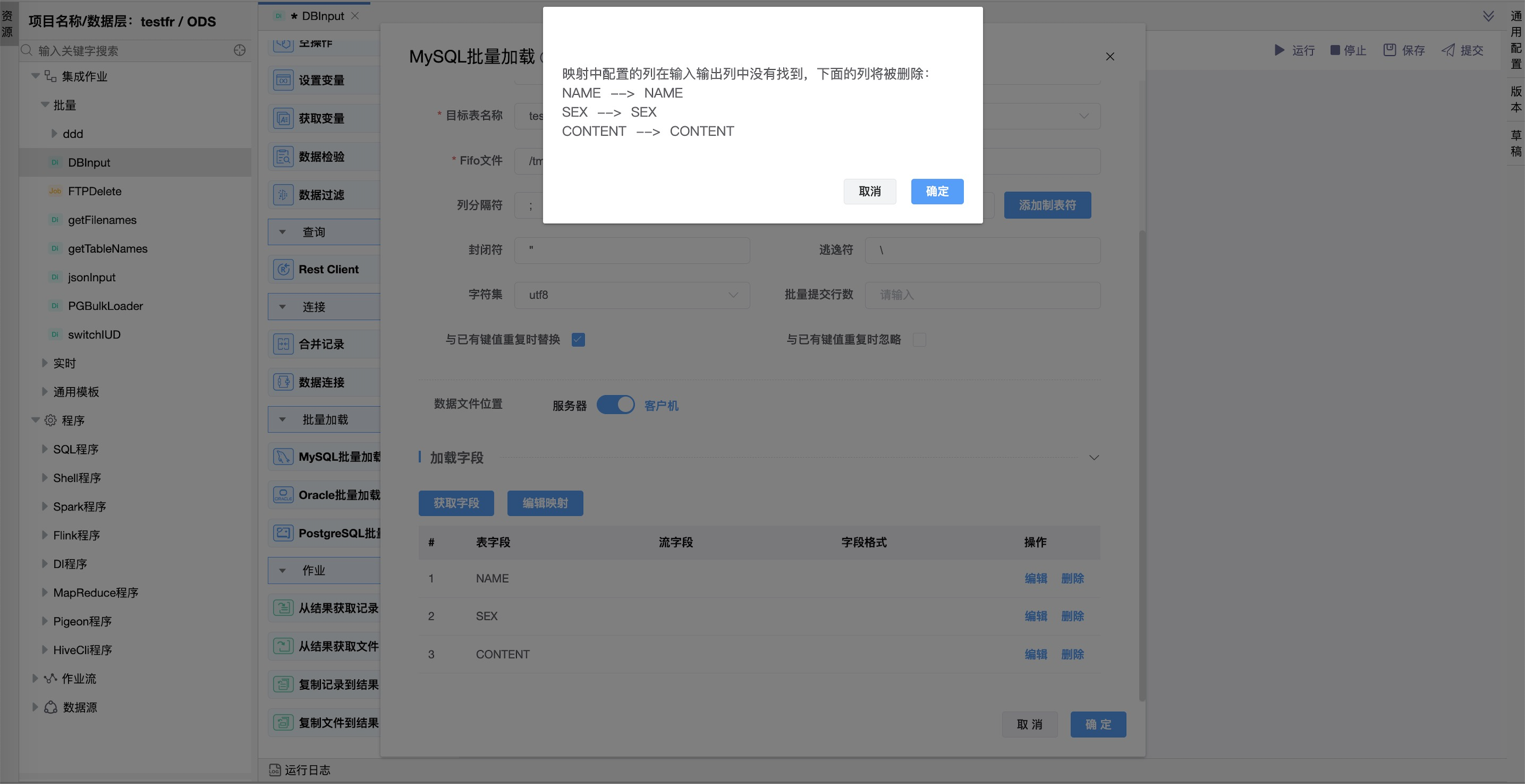
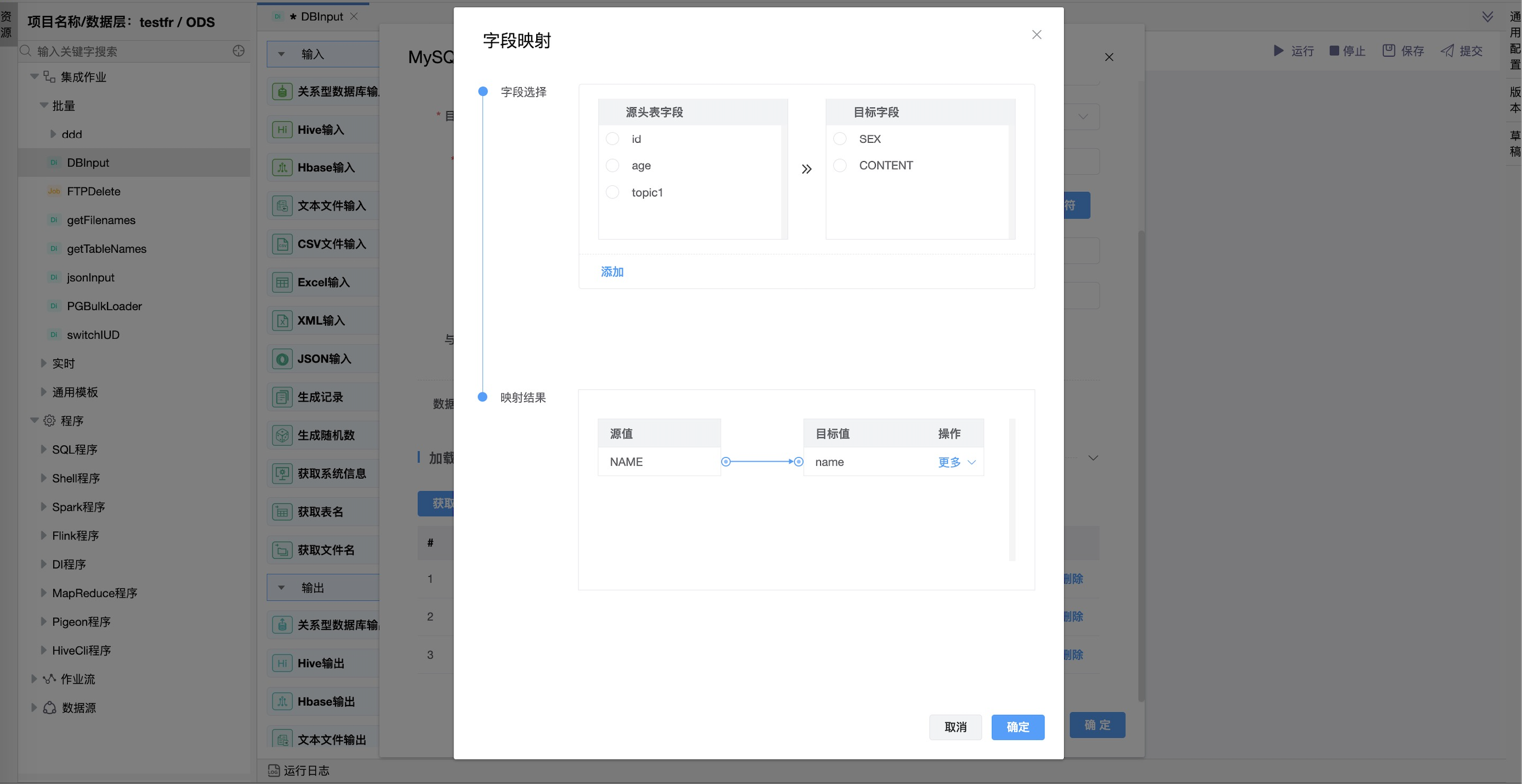
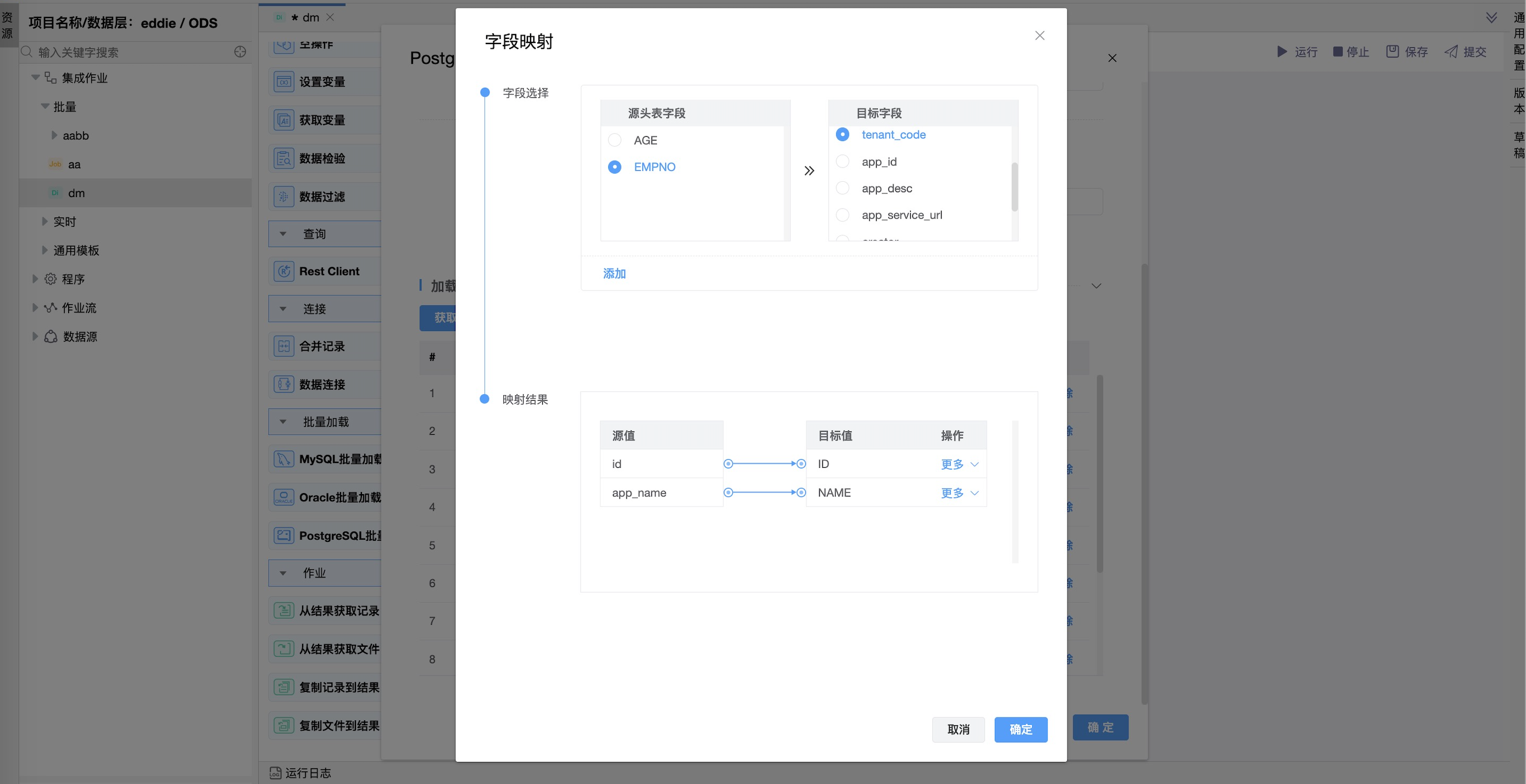
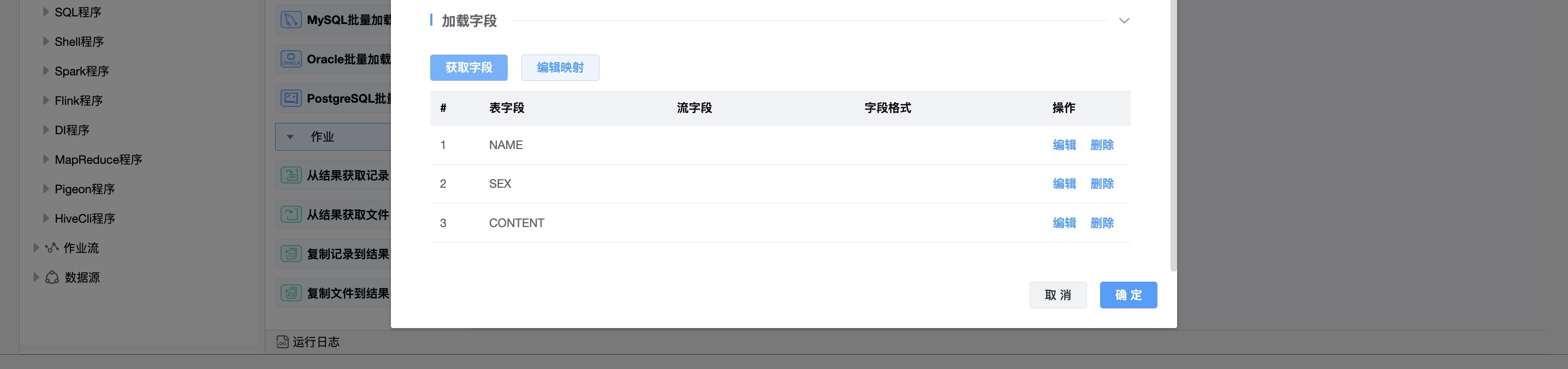 字段映射
字段映射
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(MySQL)的数据源进行选择。 |
| 数据库名称 | 目标表所在的数据库连接的名称。 |
| 目标表名称 | 目标表的名称。 |
| Fifo文件 | 这是用作命名管道的fifo文件。当它不存在时,将使用命令mkfifo和chmod 666创建它(这就是为什么它不能在Windows中工作)。 |
| 列分隔符 | 字段的分隔符。(如果未给出,则默认为制表器。) |
| 封闭符 | 用于字符串的封闭符。 |
| 逃逸符 | 如果该框在字段中,则使用转义字符进行转义。 |
| 字符集 | 使用的字符集(可选)。 |
| 批量提交行数 | 将数据加载分割为数据块,然后重新启动数据加载。 |
| 与已有键值重复时替换 | 如果选中,“REPLACE”将被添加到命令中。如果指定,则输入行替换现有行。换句话说,就是与现有行具有相同主键值或唯一索引值的行。 |
| 与已有键值重复时忽略 | 如果选中,“IGNORE”将被添加到命令中。如果指定,则跳过与唯一键值上的现有行重复的输入行。 |
| 加载字段 | 表字段:要在MySQL表中加载的表字段。 流字段:从传入行中获取的字段。 字段格式: 此选项可以决定是否应该保留格式(不更改格式)或更改。 |
# Oracle批量加载
功能介绍:此步骤类型允许您批量加载数据到Oracle数据库。
使用场景:它将接收到的数据写入合适的加载格式,然后调用Oracle SQL*Loader将其传输到指定的表中。
图标:

组件界面:
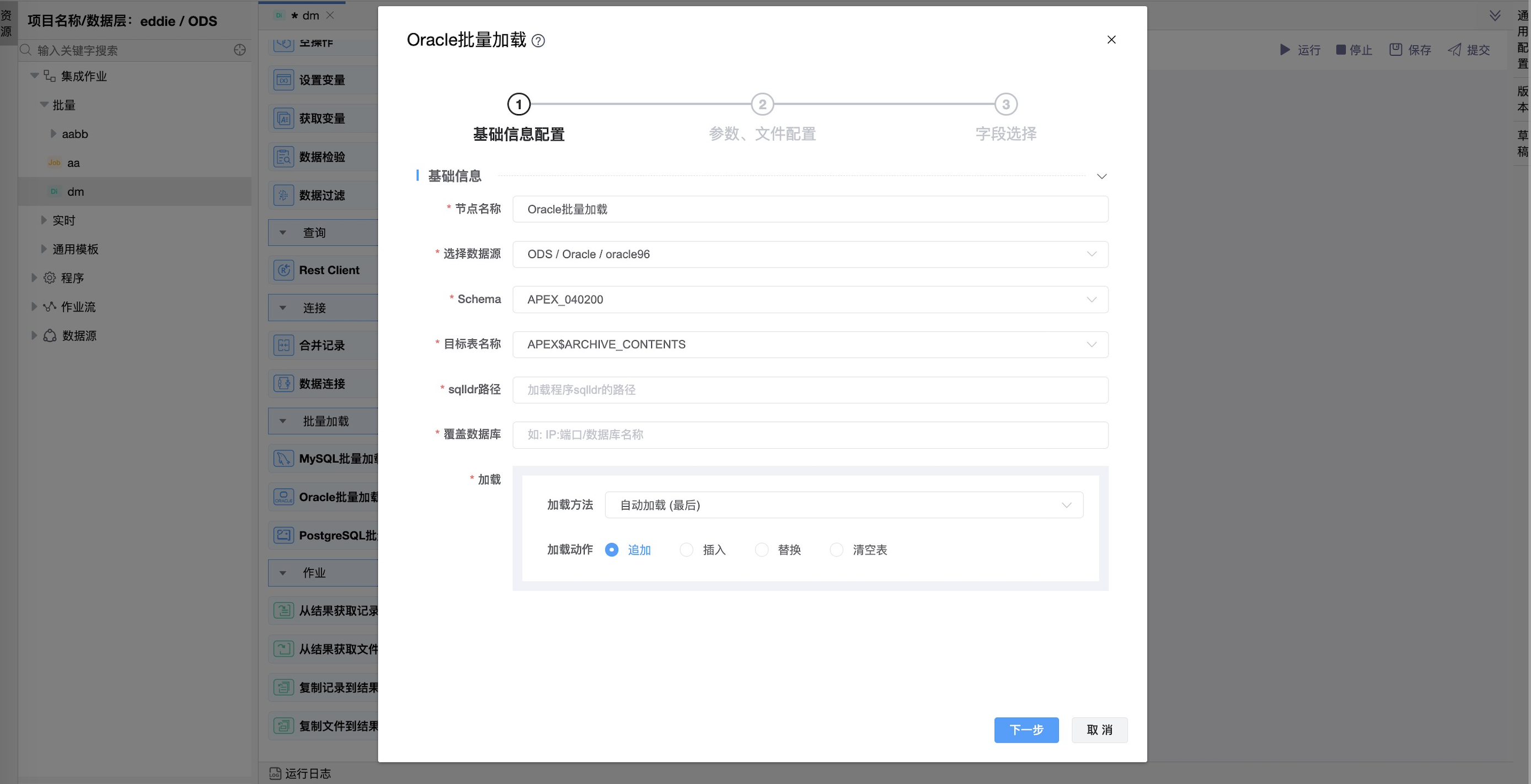
《基础信息配置》
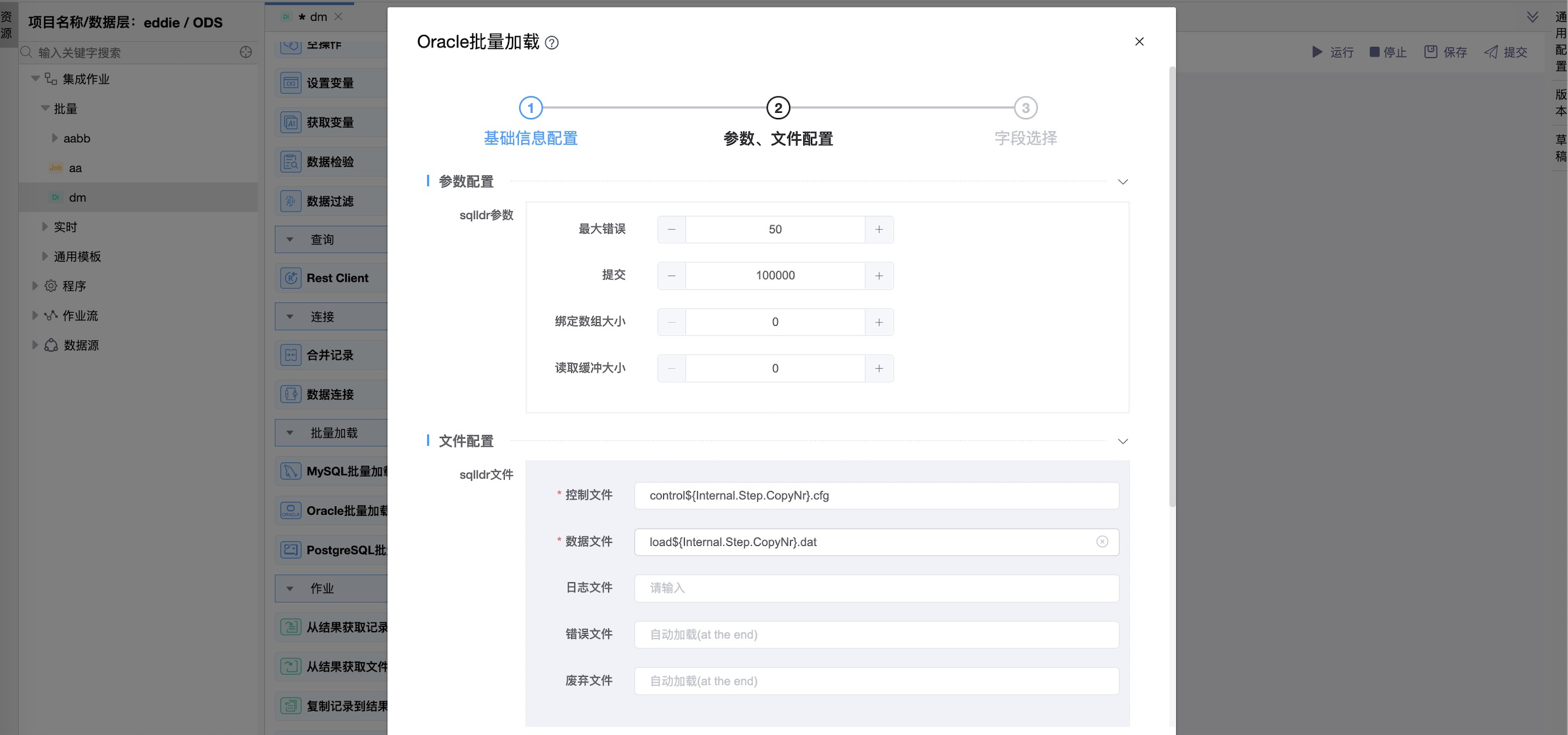
 《参数、文件配置》
《参数、文件配置》
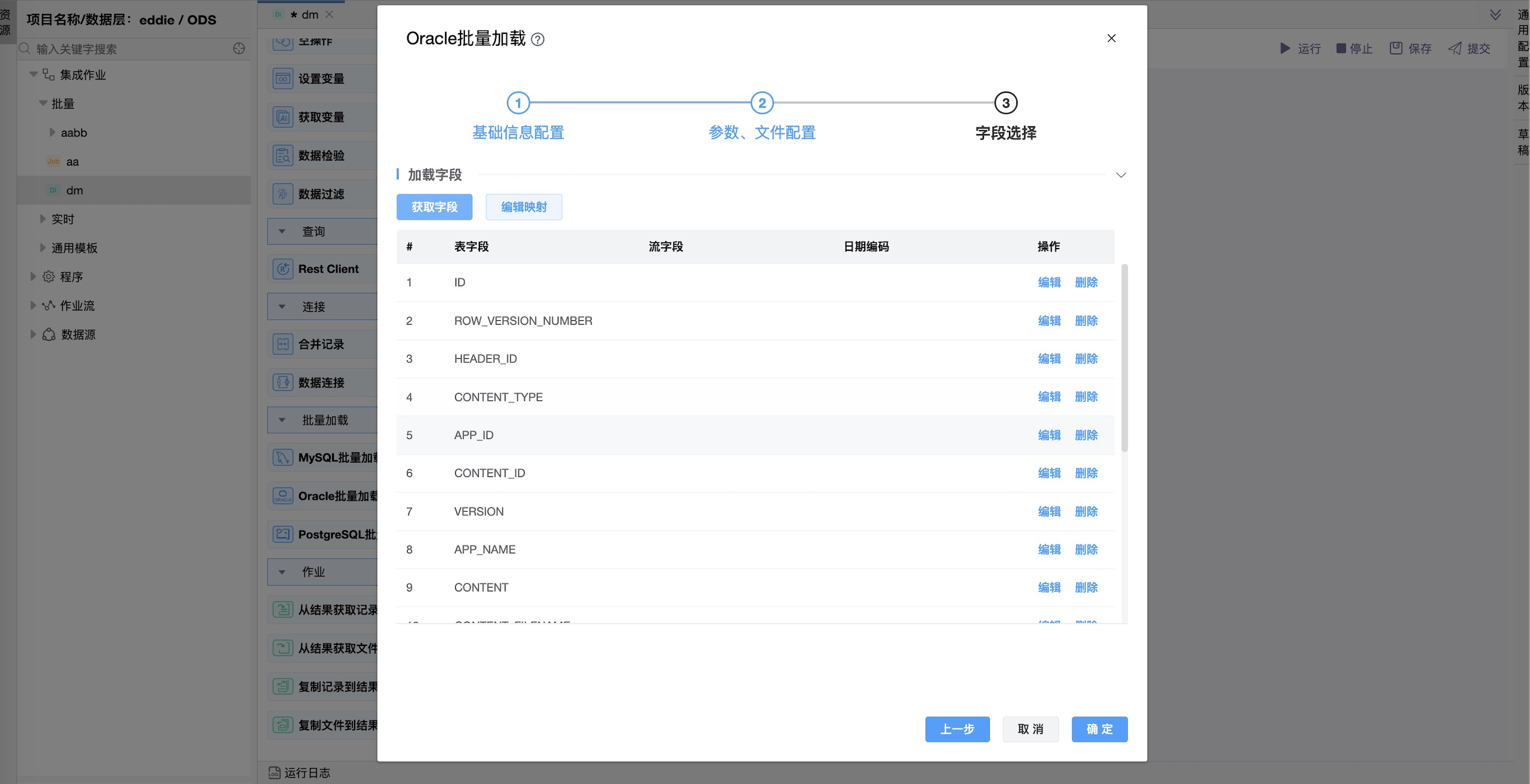
 《字段选择》
“获取字段”
《字段选择》
“获取字段”
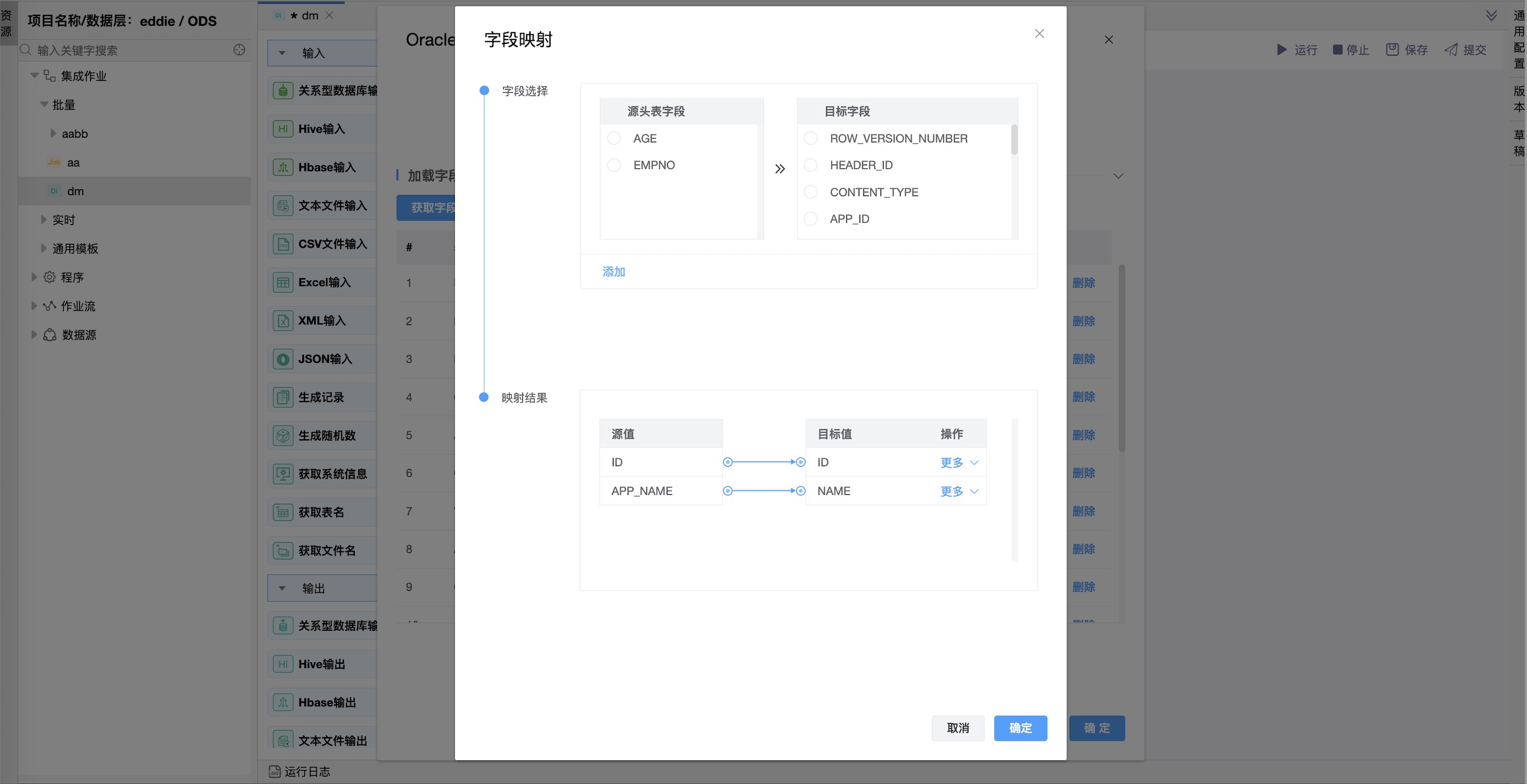
 “编辑映射”(需连接输入节点)
“编辑映射”(需连接输入节点)
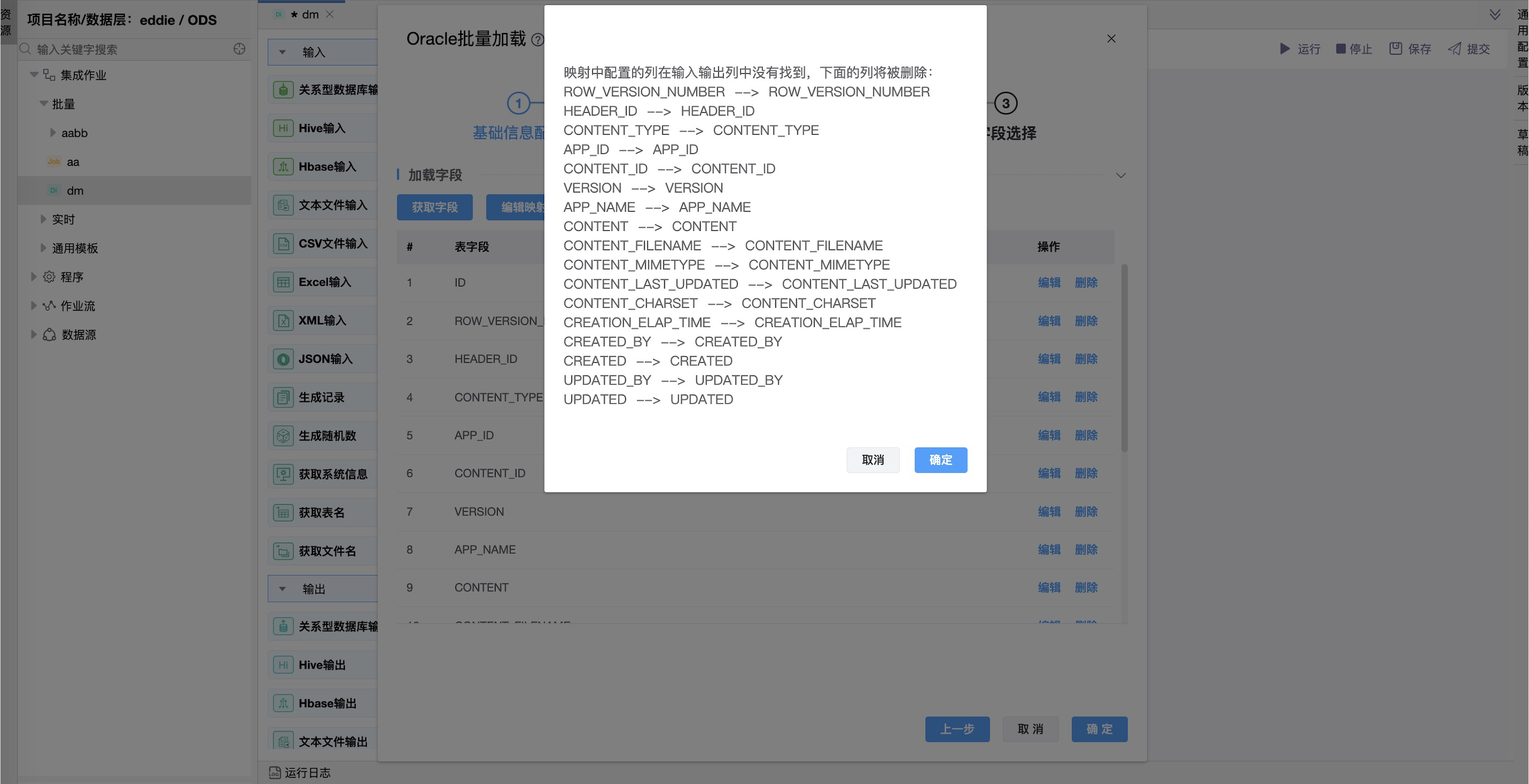
参数说明:
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(Oracle)的数据源进行选择。 |
| Schema | 选定的目标模式,要向其中写入数据的表的Schema名称。 |
| 目标表名称 | 目标表的名称。 |
| Sqldr路径 | sqldr实用程序(包括sqldr)的完整路径。如果sqldr位于正在执行的应用程序的路径中,则可以将其留给sqldr。 |
| 加载方法 | “自动加载(在结束时)”、“手动加载(仅创建文件)”或“自动加载(在运行中)”。自动加载(在最后)将在接收到该步骤中带有指定参数的所有输入后启动sqldr。手动加载只会创建一个控件和数据文件,这可以作为一个后门:你可以让PDI生成数据,并创建你自己的控件文件来加载数据(在这一步之外)。自动加载(动态)将启动sqldr,并在此步骤接收到输入时将数据传输到sqldr。 注意:“自动加载(动态)”要求您的操作系统支持将data='-'传递给sqldr以从stdin而不是实际文件中加载数据。 |
| 载荷作用 | |
| 加载动作 | 追加,插入,替换,截断。这些映射到要执行的sqldr操作。 |
| sqlldr参数 | 最大错误:出错的行数,超过该行sqldr将中止。这对应于sqldr的"ERROR"属性。 提交:提交之后的行数,这对应于sqldr的“rows”属性,在使用常规路径负载和直接路径负载之间有所不同。 绑定数组大小:对应sqldr的“BINDSIZE”属性。 读取缓冲大小:对应sqldr的“READSIZE”属性。 |
| sqlldr文件 | 控制文件:用作sqldr控制文件的文件名。 数据文件:要写入数据的数据文件的名称。 日志文件:日志文件的名称。 错误文件:错误文件的名称。 废弃文件:废弃文件的名称。 |
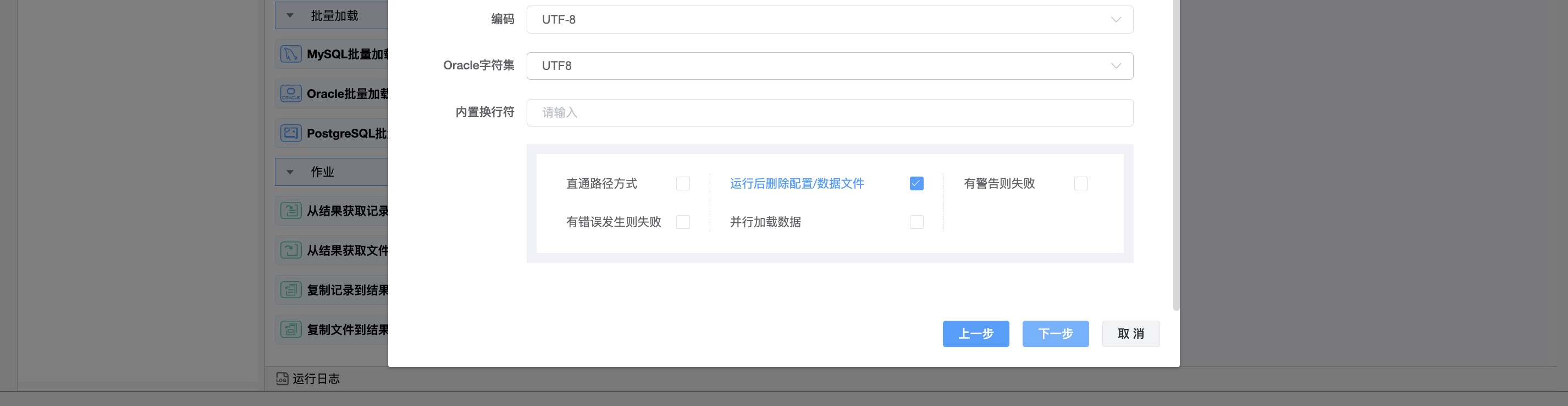
| 编码 | 以特定编码对数据进行编码,除了下拉列表中的编码外,还可以选择任何有效的编码。 |
| 直通路径方式 | 打开直接路径加载,对应于sqldr中的direct =TRUE。 |
| 运行后删除数据/配置文件 | 当开关打开时,控件和数据文件将在加载后被擦除。 |
| 加载字段 | 这个表包含了加载数据的字段列表,属性包括: 表字段:要在Oracle表中加载的表字段; 流字段:从传入行中获取的字段; 日期编码: “日期”或“日期掩码”决定如何在Oracle中加载日期/时间戳。当留空时,对于日期,默认为“Date”。“Date”类型将值截断为月几,而DateTime选项传递日期和时间信息。 |
# PostgreSQL批量加载
功能介绍:该组件用于将数据快速导入PostgreSQL数据库。
使用场景:PostgreSQL的批量加载是一个实验性的步骤,我们将使用“COPY data from STDIN”将Kettle内部的数据流传输到psql命令中。
这种加载数据的方式提供了两方面的优势:批量加载的性能和Pentaho data Integration转换的灵活性。
注意:此步骤不适用于JNDI定义的连接,只支持JDBC。
图标:

组件界面:
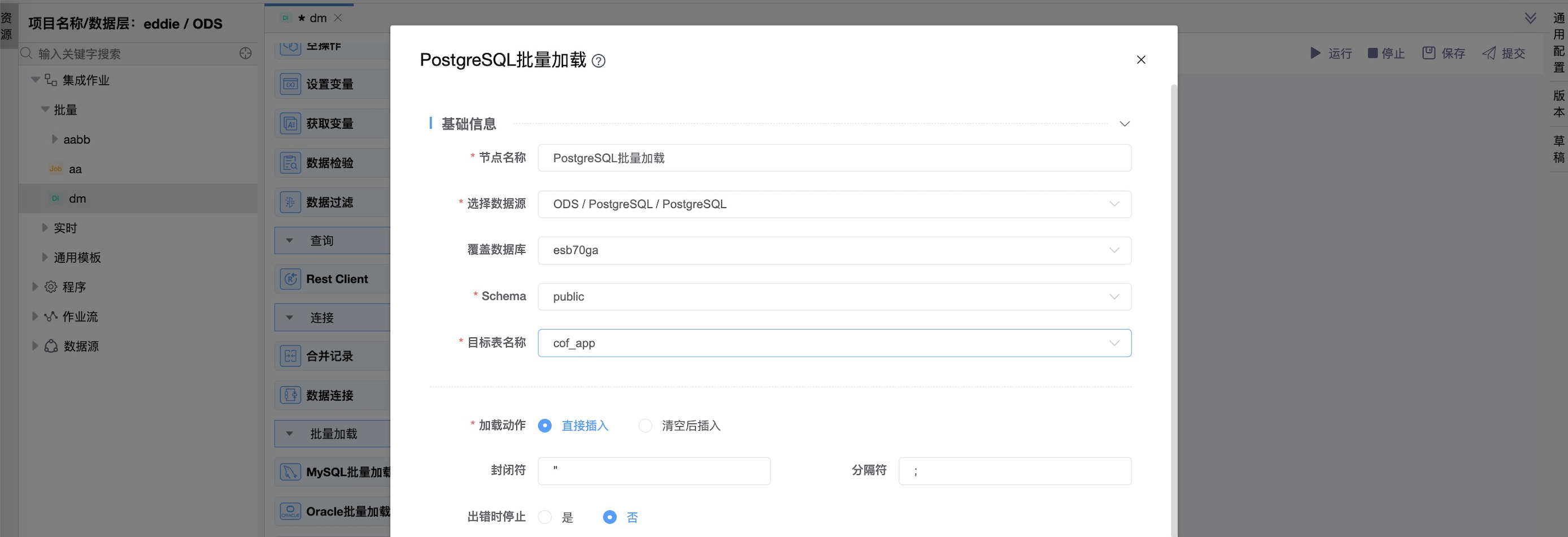

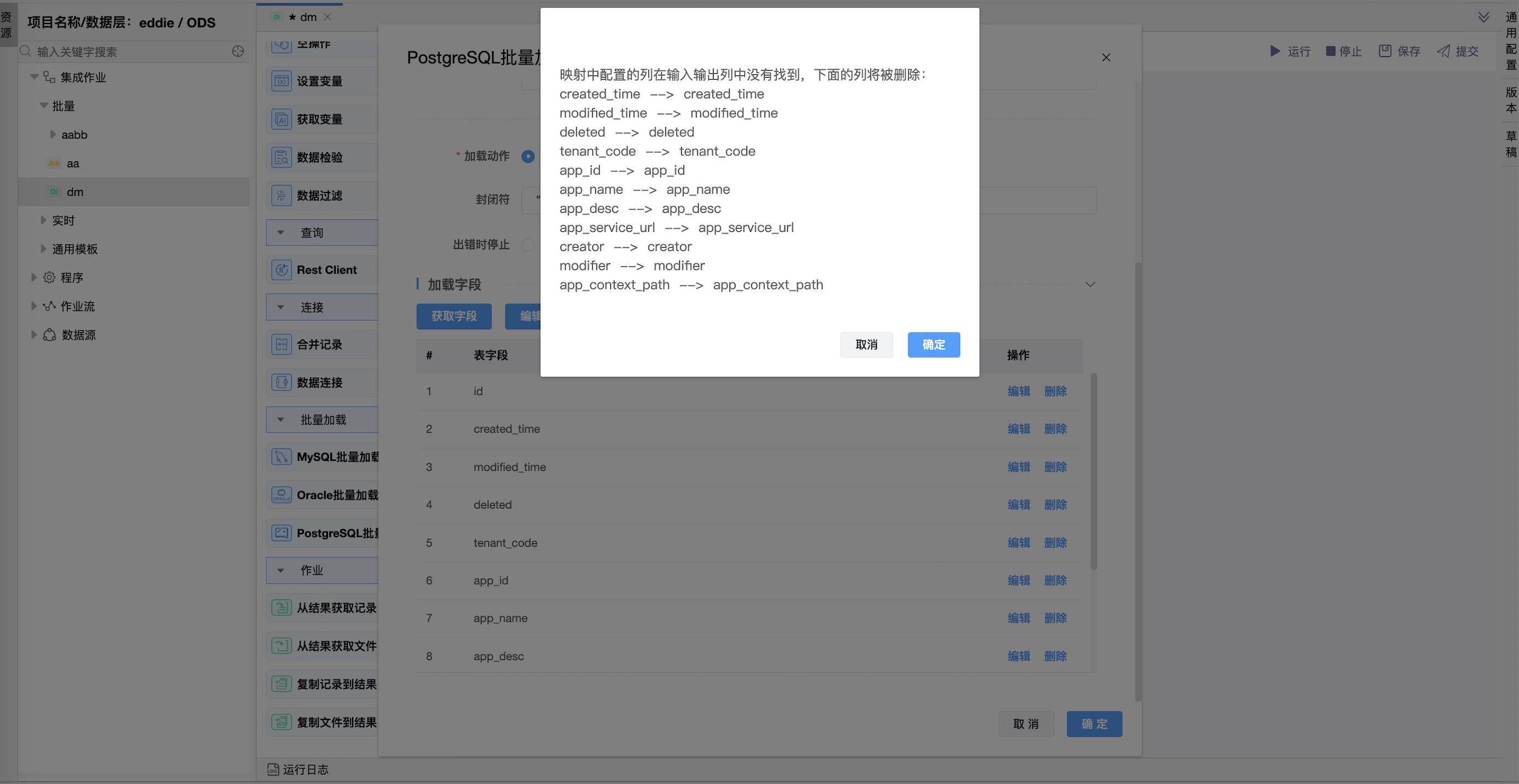
| 参数 | 说明 |
|---|---|
| 节点名称 | 当前创建的节点名称,由用户自定义且不可为空。命名可包含字母、数字、下划线。 |
| 选择数据源 | 当前输入绑定的数据源名称,从下拉选项中列出的指定的关联类型(PostgreSQL)的数据源进行选择。 |
| Schema | 选定的目标模式,要向其中写入数据的表的Schema名称。 |
| 目标表名称 | 目标表的名称。 |
| 加载动作 | 插入、截断。Insert插入,truncate首先截断表。 注意:当您运行转换集群或多步骤副本时,不要使用“Truncate”!在这种情况下,在转换开始之前截断表,例如在作业中。 |
| 列隔符 | 字段的分隔符。(如果未给出,则默认为制表器。) |
| 封闭符 | 用于字符串的封闭符。 |
| 加载字段 | 这个表包含了加载数据的字段列表,属性包括: 表字段:PostgreSQL表中要加载的表字段; 流字段:从传入行中获取的字段; 日期编码: “日期”或“日期掩码”决定如何在PostgreSQLe中加载日期/时间戳。当留空时,对于日期,默认为“Date”。“Date”类型将值截断为月几,而DateTime选项传递日期和时间信息。 |