# 数据源管理
在配置数据集成同步任务前,用户需要配置好数据同步的源端和目标端数据库相关信息,以便在配置同步任务时,可以通过选择数据源名称来确定同步任务读取和写入的数据库。
当前版本支持的数据源,包括:关系数据库、大数据、NoSQL、消息队列、ERP。
数据源管理的功能包括:
# 支持的数据源
| 类型 | 版本 |
|---|---|
| MySQL | 5.7.25、8.0.28 |
| SQL Server | 2012、2016 |
| Oracle | 12c、19c |
| IBM DB2 | 9.7 |
| PostgreSQL | 9.6.2、10.23 |
| 南大通用 GBase8s | 8.3.81.51 |
| 达梦 | DM8 |
| 人大金仓 KingbaseES | V8R6 |
| openGauss | 2.1.0 |
| Oscar | 7.0.8 |
| Hive | 2.1.1-cdh6.3.2 |
| HBase | 2.1.0-cdh6.3.2 |
| Clickhouse | 22.1.3.7 |
| HDFS | Hadoop 3.0.0-cdh6.3.2 |
| StarRocks | 3.0.3 |
| Inceptor | 3.1.4 |
| ArgoDB | 6.0.3 |
| Hyperbase | 9.0 |
| Elasticsearch | 8.1.2 |
| MongoDB | 4.2.5 |
| Neo4j | 4.3.6 |
| Kafka | 2.13-2.8.2 |
| RabbitMQ | 3.8.9 |
| SAP | ecc6.0 |
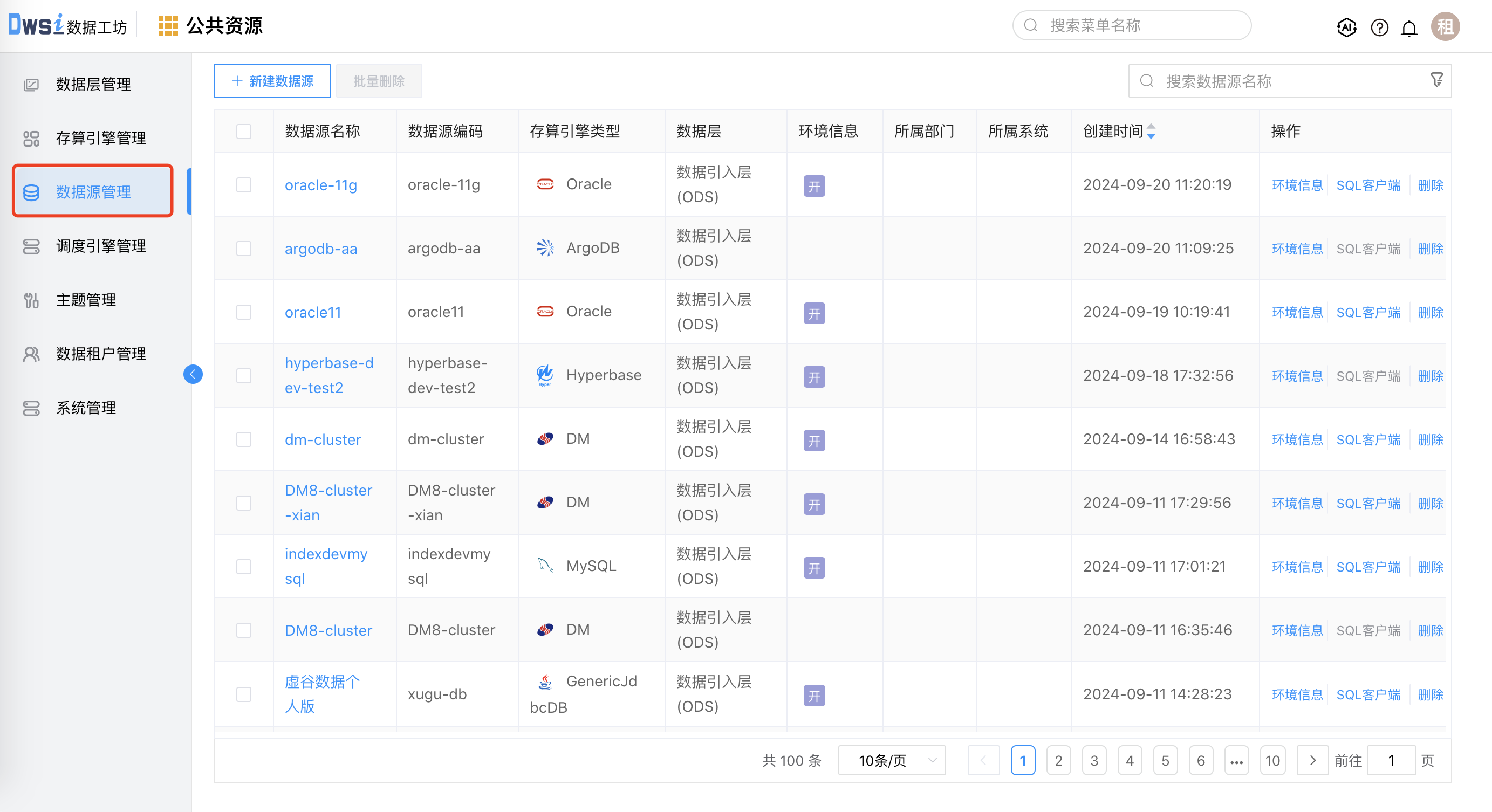
# 功能入口
点击菜单栏“公共资源”,进入公共资源管理界面,点击左侧菜单的"数据源管理",进入数据源管理界面。
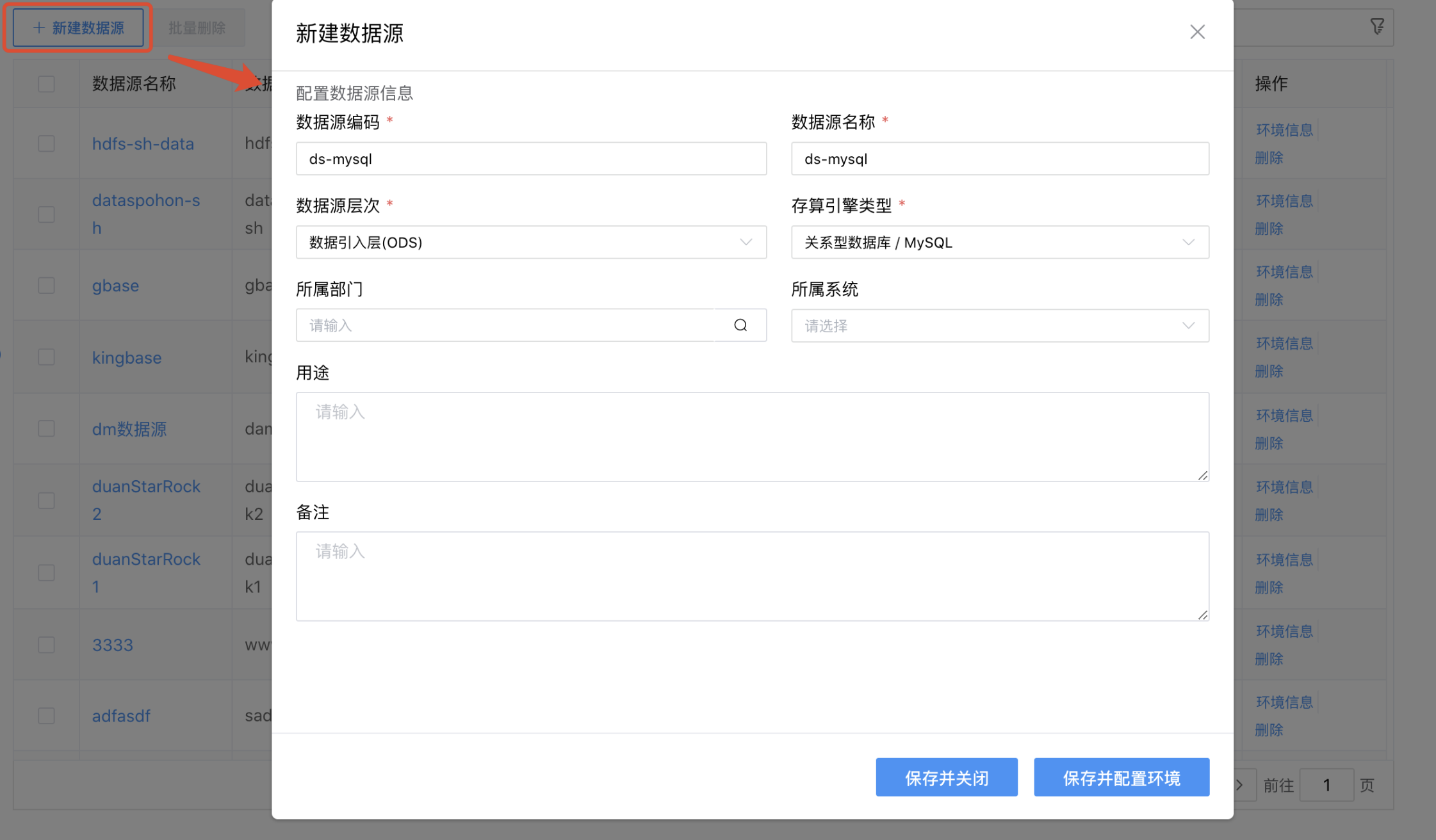
# 新建数据源
点击【新建数据源】按钮,弹出"创建数据源"的弹窗,按照界面要求录入数据源参数。
为确保数据源的可用性,可以点击【开始测试】按钮进行连通性测试。
点击【保存并关闭】按钮,保存新建的数据源信息。
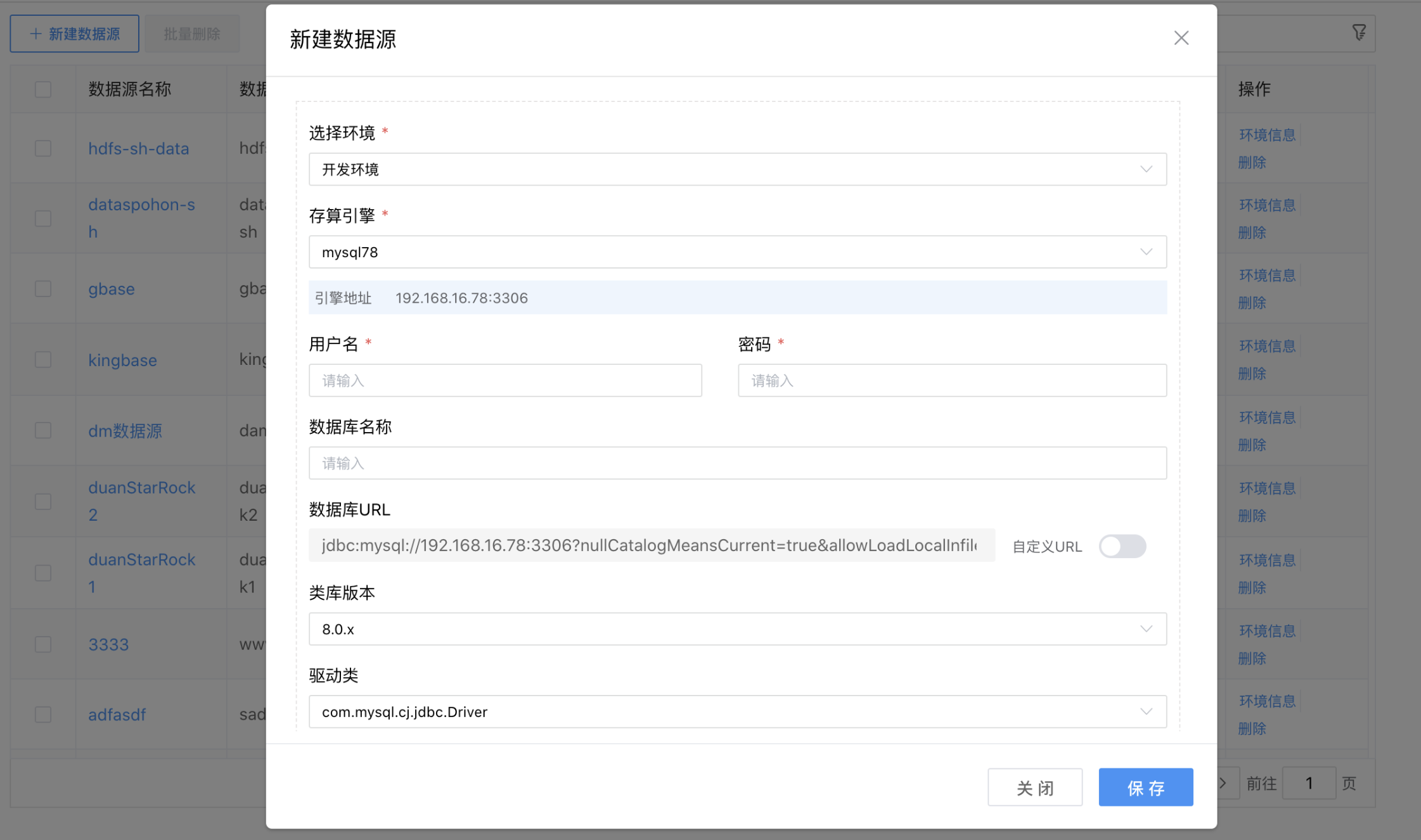
点击【保存并配置环境】按钮,跳转到数据源环境配置页面,按照页面要求继续录入数据源多个环境(如:开发环境、生产环境)的配置参数。

新建数据源配置项说明:
| 配置项 | 描述 |
|---|---|
| 数据源编码 | 当前创建的数据源编码,由用户自定义且不可为空,不少于3个字符。命名可包含字母、数字、下划线、中划线。 |
| 数据源名称 | 当前创建的数据源名称,由用户自定义且不可为空,不少于3个字符。命名可包含汉字、字母、数字、下划线、中划线。 |
| 数据源层次 | 当前创建的数据源所属数据层,从下拉选项选择且不可为空。一个数据源只能隶属一个数据层。 |
| 存算引擎类型 | 数据源对应的存算引擎类型。 |
| 所属系统 | 当前创建的数据源所属系统,从下拉选项选择(数据字典)。 |
| 所属部门 | 当前创建的数据源所属部门,从机构选项进行选择。 |
| 用途 | 当前创建的数据源的用途。 |
| 备注 | 当前创建的数据源的备注信息,用于记录用户自定义内容。 |
# 修改数据源
点击数据源列表上的"数据源名称",弹出"数据源详情"弹窗。
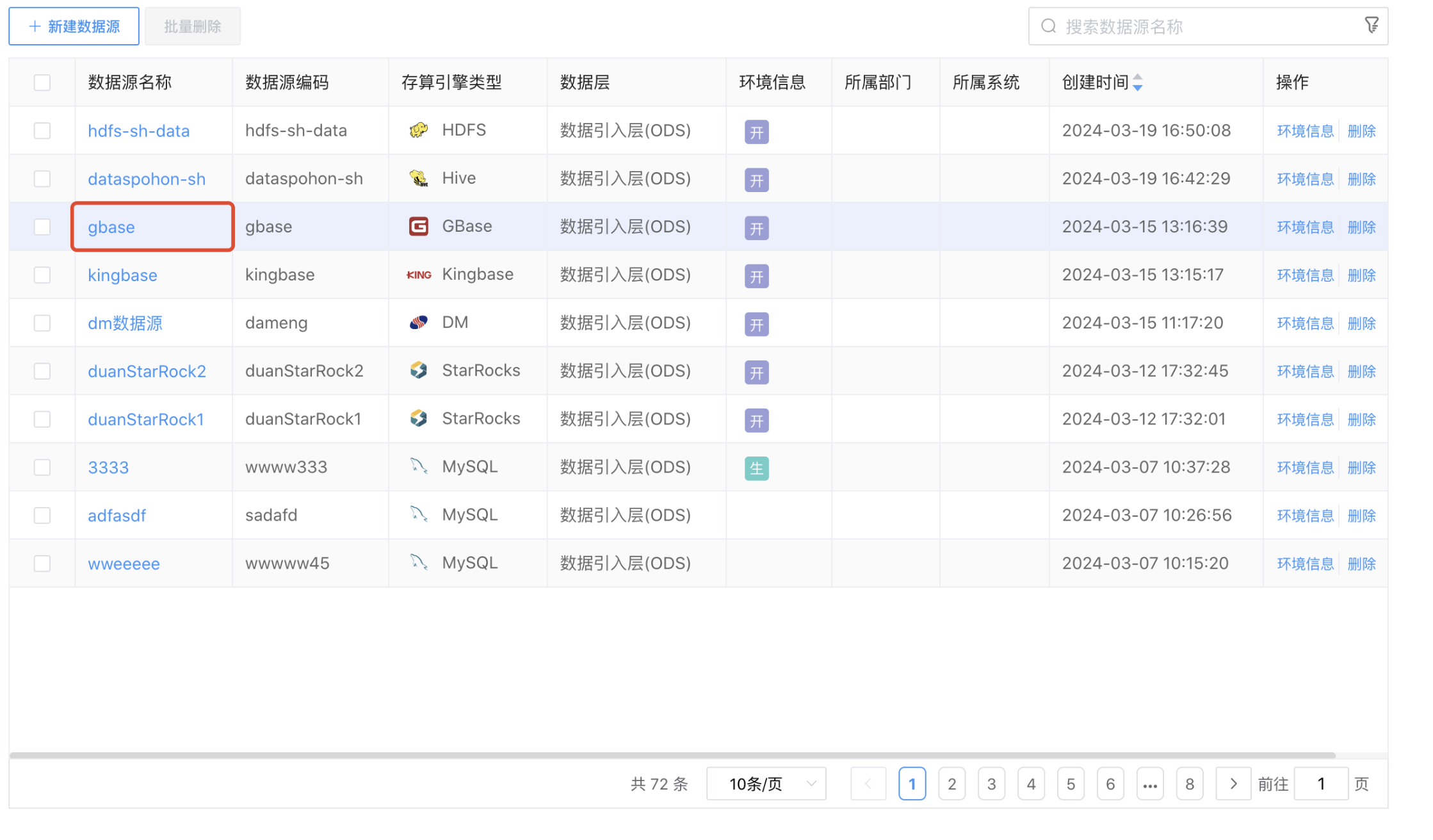
点击弹窗左上角的【编辑内容】,可修改的参数项变为"可编辑"状态,用户可以根据需求进行参数的修改。
点击【确定】按钮,完成参数的修改、保存。
点击【取消】按钮,取消本次修改操作。
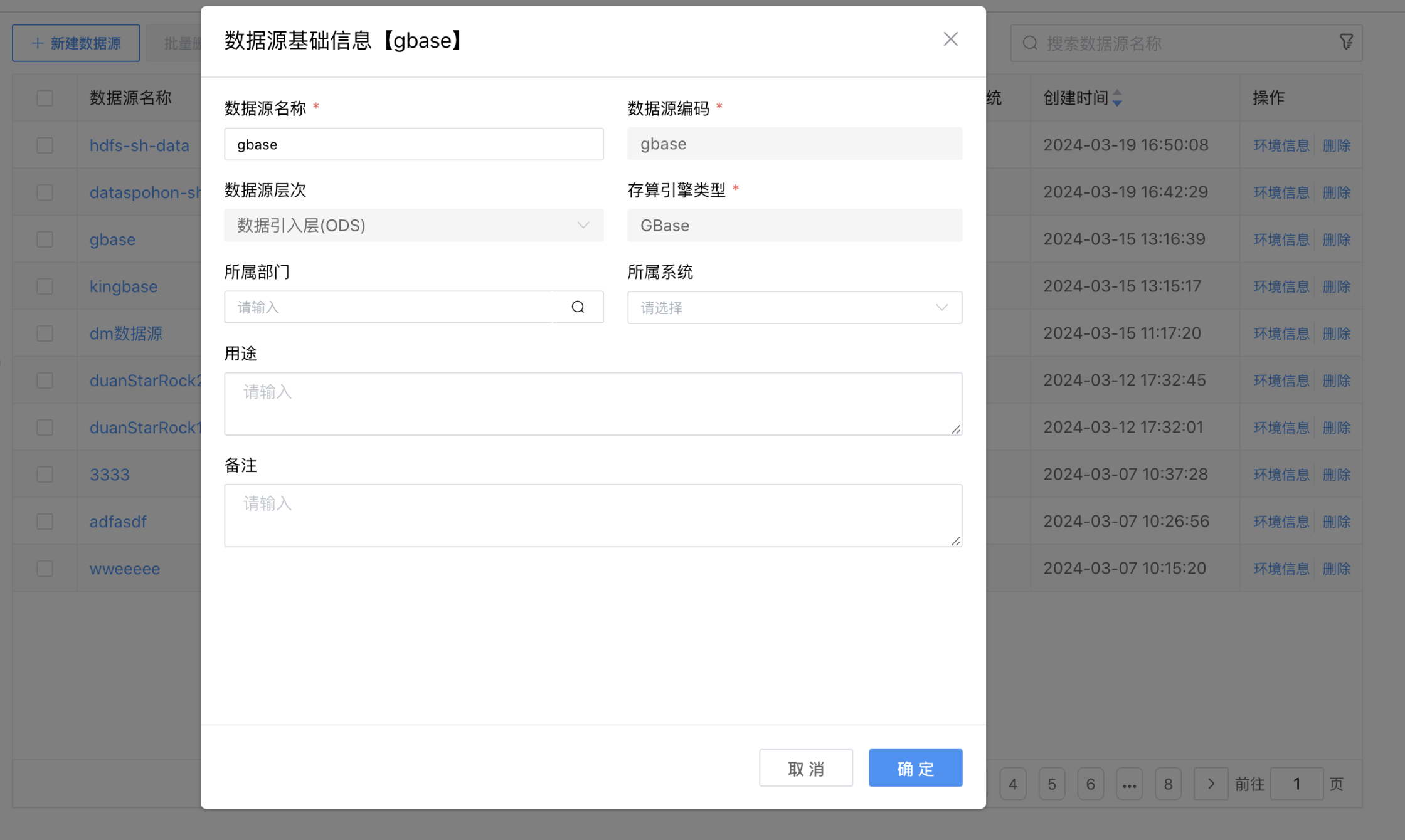
# 删除数据源
点击数据源列表后边的【删除】按钮,弹出"删除确认"弹框。
点击弹框的【确认】按钮,完成删除操作。
点击弹框的【取消】按钮,取消本次删除操作。
⚠️ 提示:删除数据源后,在 IDE 中再次打开已经引用该数据源的作业时会提示“该数据源不存在”的信息。
# 维护环境信息
点击数据源列表后边的【环境信息】按钮,弹出"+增加环境"菜单,可以创建、维护各个环境(开发环境、生产环境……)的数据源连接配置信息。
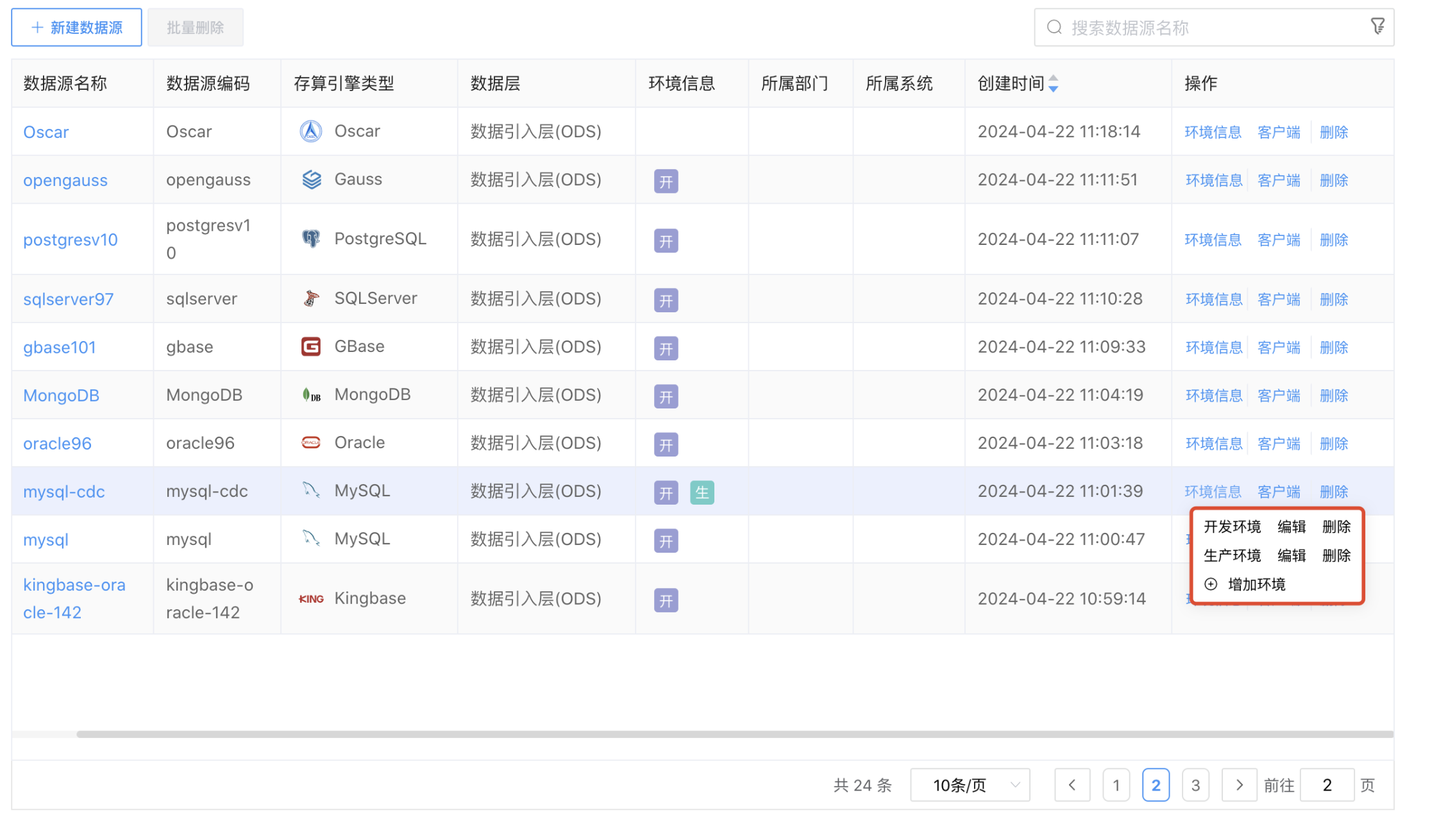
点击【+增加环境】,可以创建新的数据源环境连接配置参数。
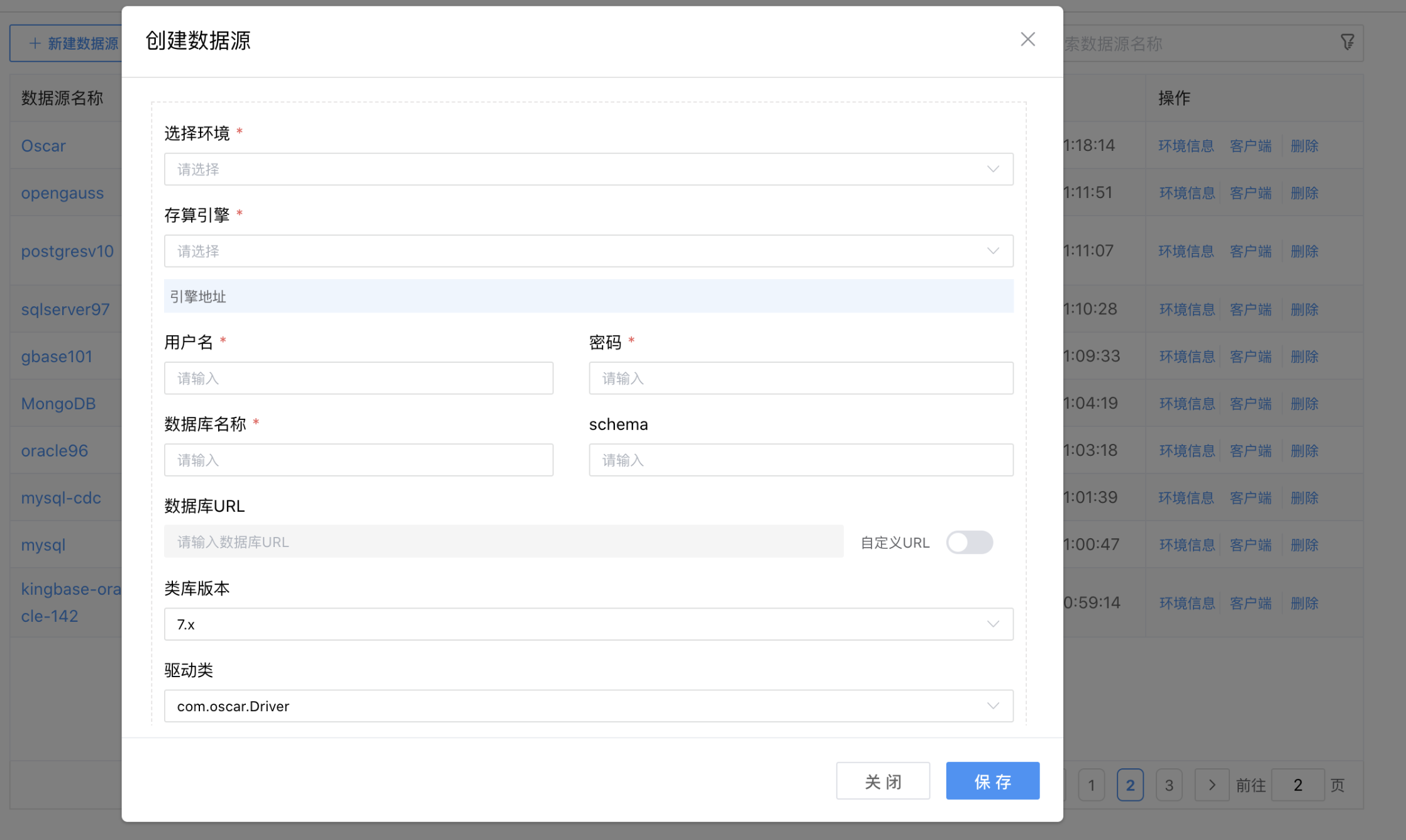
数据源环境配置项说明:
| 配置项 | 描述 |
|---|---|
| 选择环境 | 从下拉列表中选择:开发环境、生产环境、……。 |
| 存算引擎 | 数据源对应的存算引擎。 |
| 用户名 | 所配置的数据库的用户名。 |
| 密码 | 所配置的数据库的密码。 |
| 数据库名称 | 当前创建的数据源所属系统,从下拉选项选择(数据字典)。 |
| Schema | 数据库 Schema名称。 |
| 数据库URL | 自动生成的数据库URL连接地址。 |
| 自定义URL | 如果需要修改URL链接,可以启用开开关,然后进行手工修改。 |
| 类库版本 | 数据源的驱动版本号。 |
| 驱动类 | 数据源的驱动类。 |
| 连接参数 | 数据源的扩展参数。 |
| 连通性测试 | 测试数据源是否能正常连通。 |
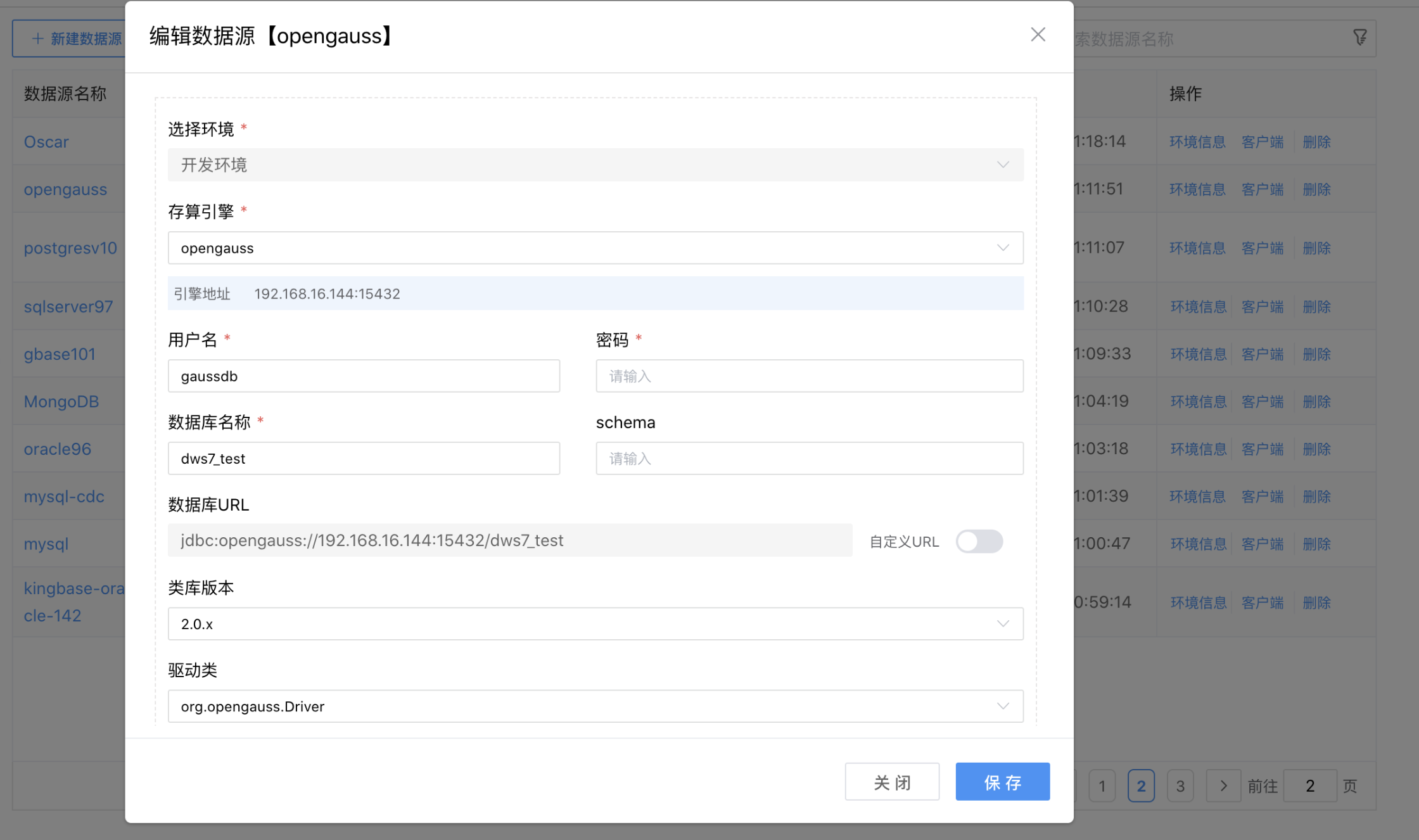
点击【编辑】,可以修改当前数据源环境连接配置参数。
点击【删除】,可以删除当前数据源环境连接配置。
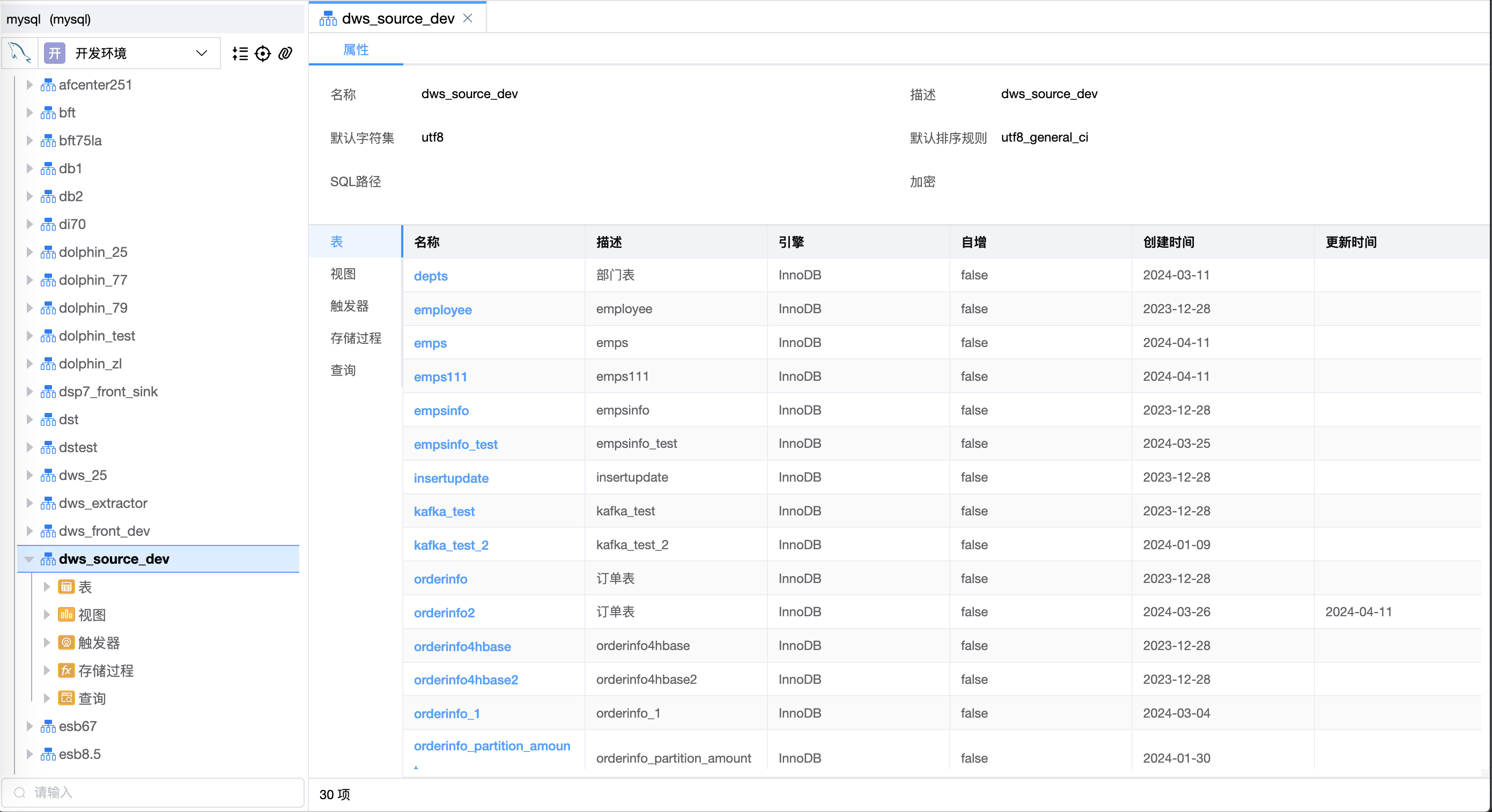
# SQL客户端
SQL客户端是一种在线浏览数据源信息的工具。支持数据库/Schema、表、视图、触发器、存储过程、列、索引、约束、分区、表数据、SQL语句执行/停止等;SQL编辑器语法高亮、提示、自动补全(数据库/Schema、表、视图、字段)。
当前版本支持 10 种关系型数据库(MySQL、SQL Server、Oracle、PostgreSQL、DB2、达梦、openGauss、GBase、Oscar、人大金仓)、4种大数据库(Hive、Inceptor、StarRocks、ClickHouse)。
点击数据源列表后边的【SQL客户端】按钮,会打开新的浏览器Tab页,可以浏览当前数据源的信息。
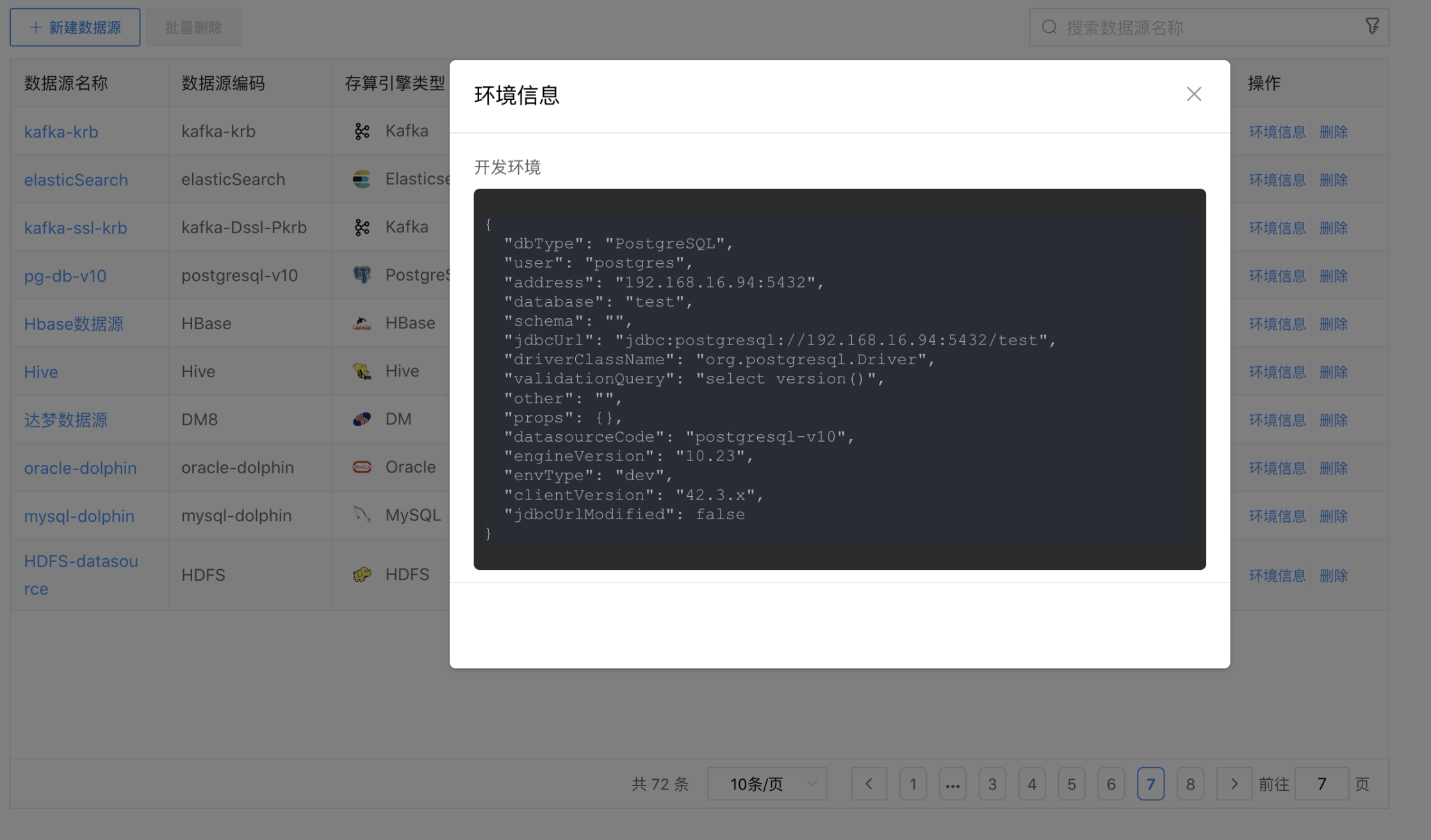
# 查看连接信息
点击数据源列表后边的【连接信息】按钮,弹出"连接信息"弹窗,可以查看各个环境的数据源连接信息。
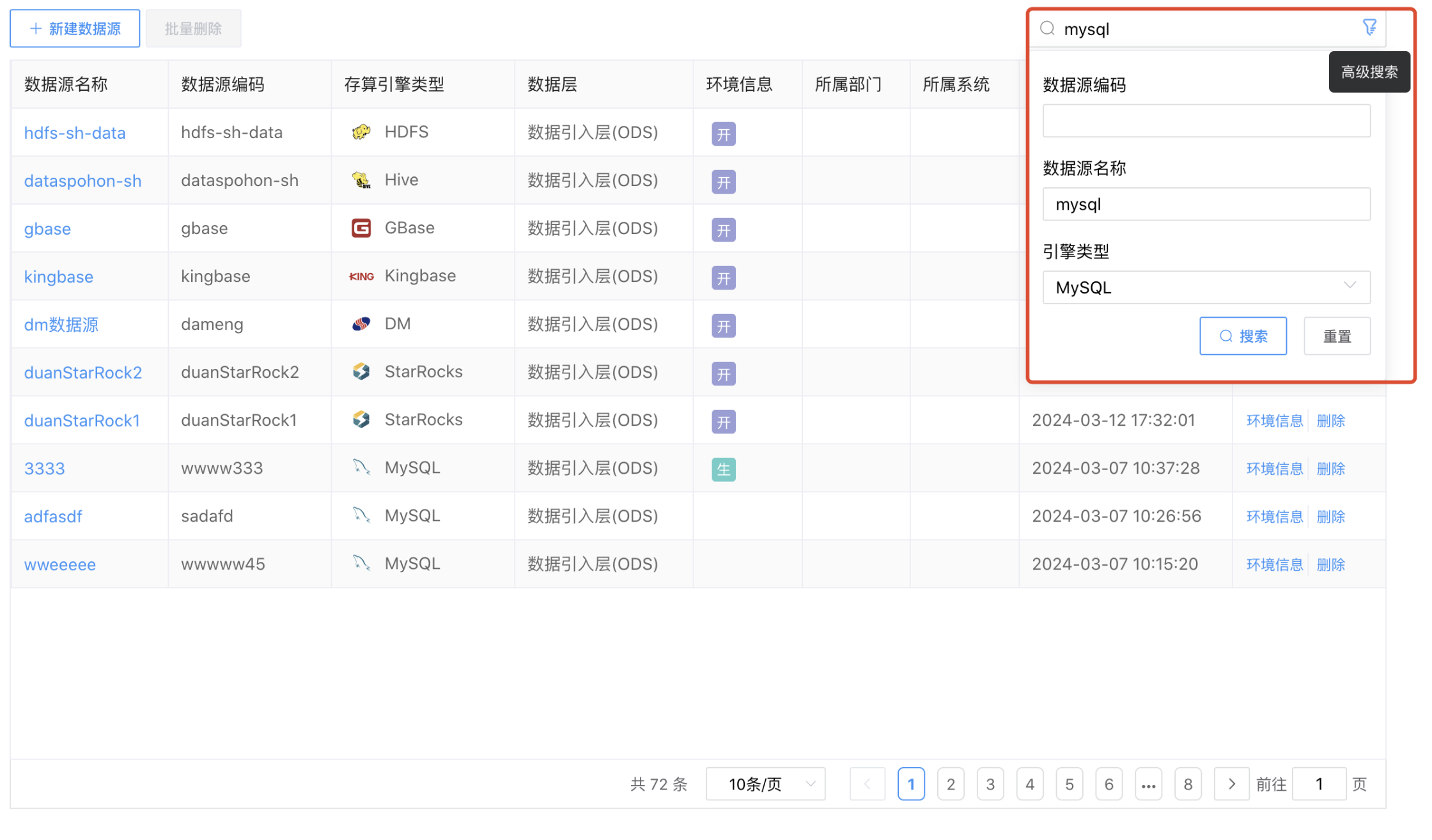
# 搜索
点击存算引擎列表右上方的【高级搜索】按钮,输入搜索条件"数据源编码"或者"数据源名称",点击【搜索】按钮,可以按照条件完成数据源的模糊查询,点击【重置】按钮,可以清空搜索条件。
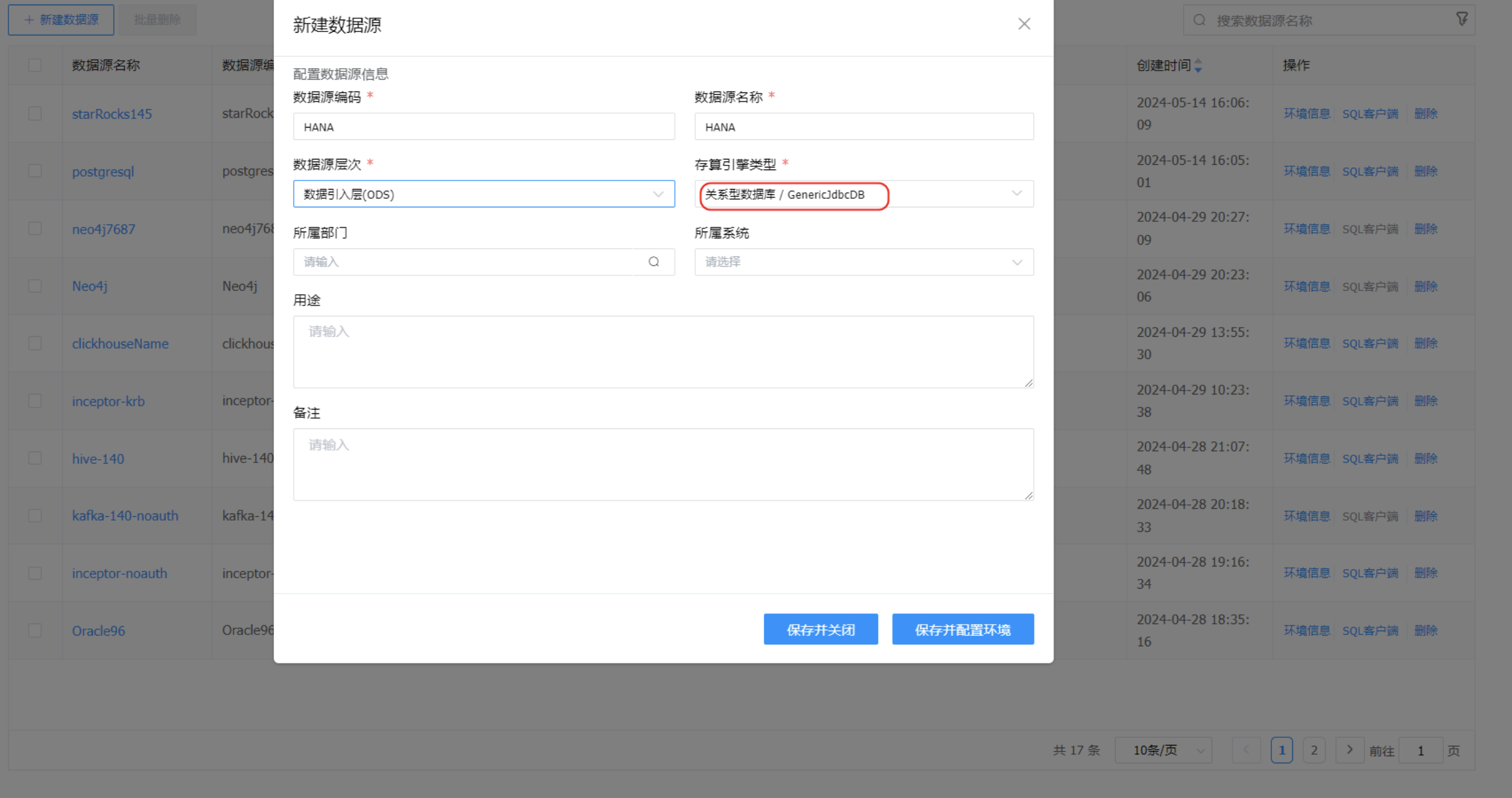
# 补充说明:Generic JDBC 数据源
Generic JDBC 存算引擎能快速接入更多关系型数据库,是通用的关系型数据库 jdbc 连接方式。
以下以 Generic JDBC 类型创建 HANA_SAP 数据源为例说明使用步骤。
创建存算引擎参考:HANA_SAP存算引擎
创建数据源
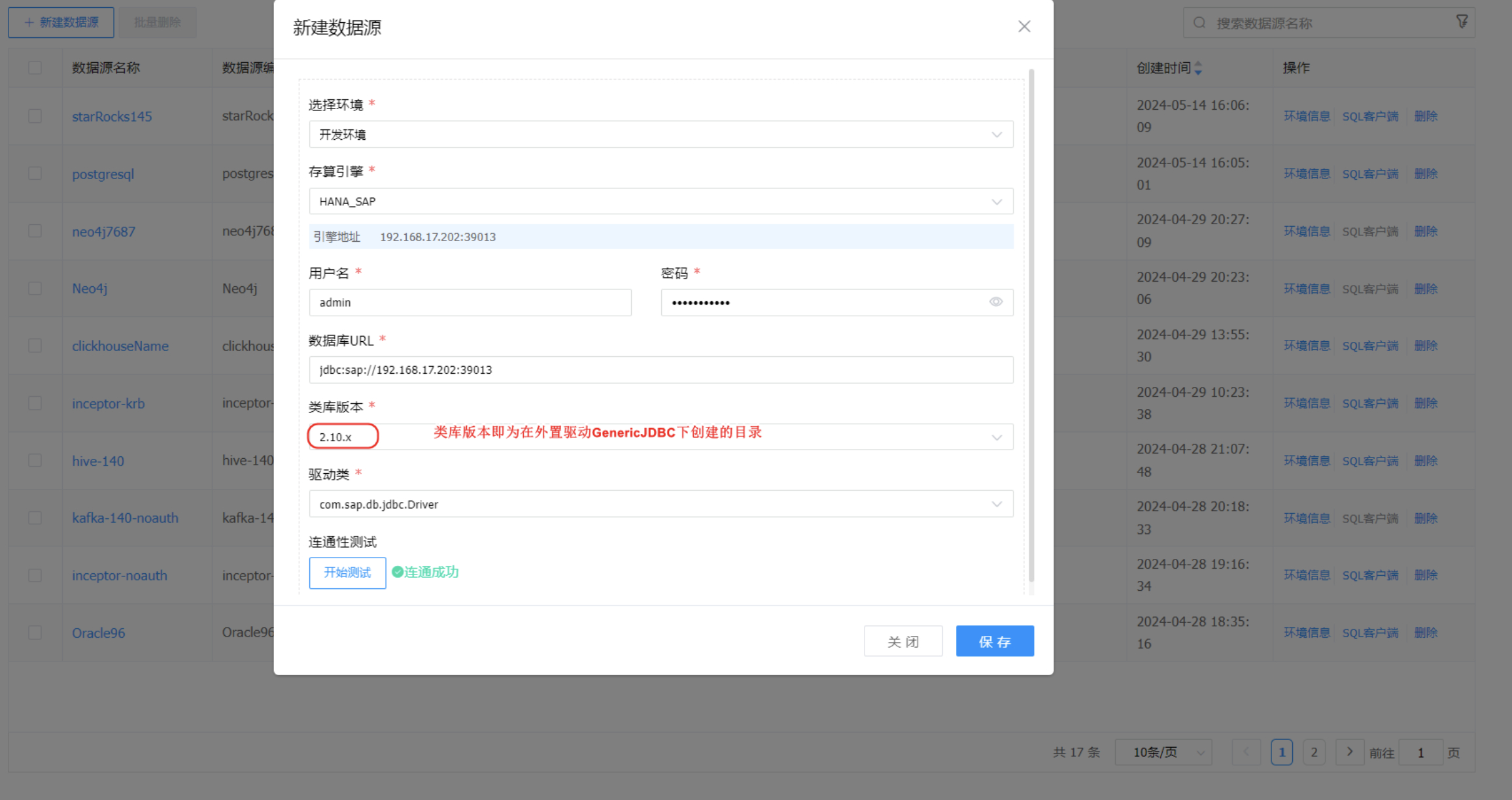
⚠️ 提示:在IDE中如果要使用该 GenericJDBC 创建的数据源,仍然需要将驱动放置在对应应用的 lib 目录下(dws_server、dolphinscheduler、Primeton DI、seatunnel)。
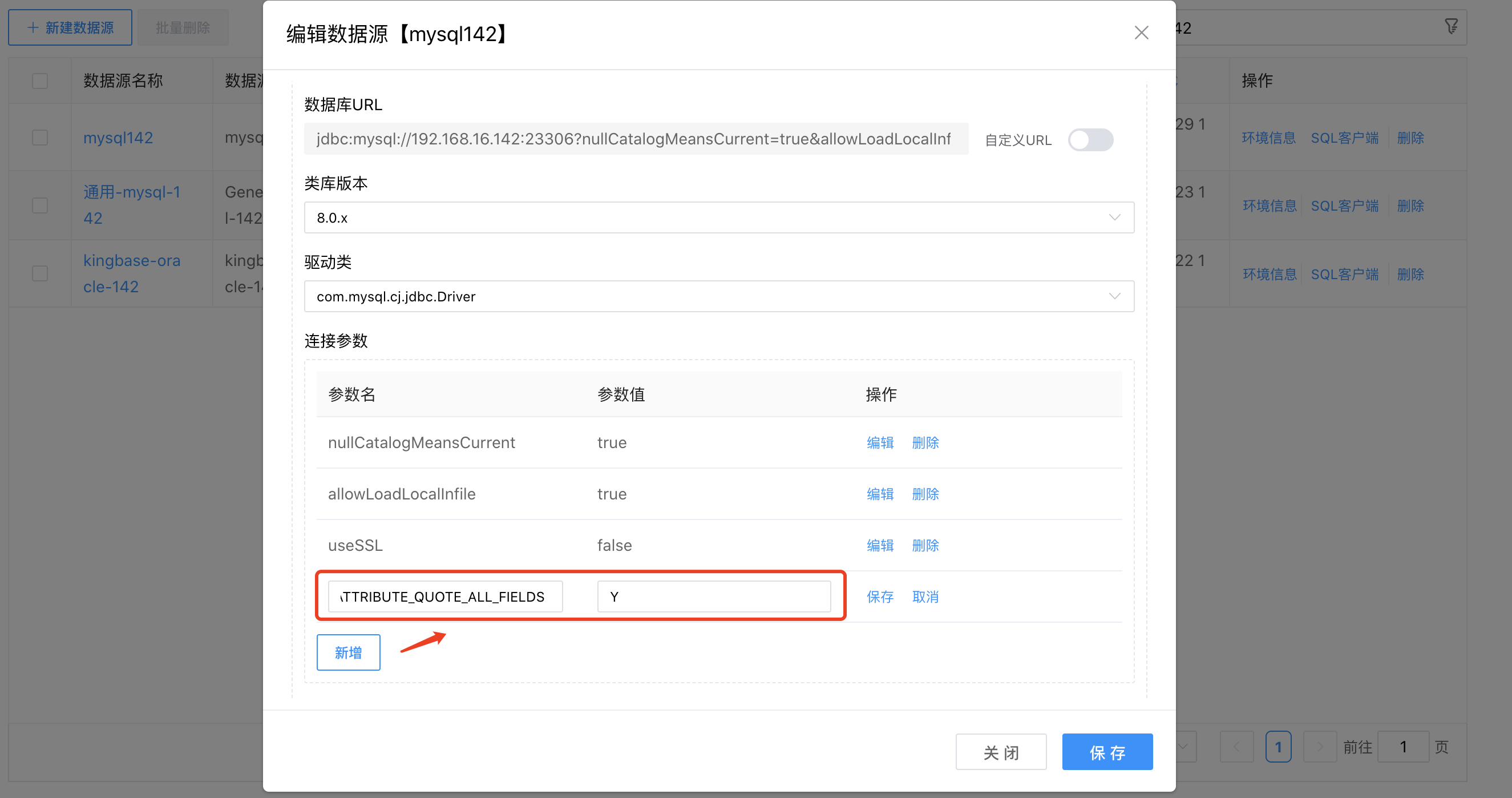
# 补充说明:规避名称与数据库关键字重名冲突
通过修改数据源配置参数,使名称(Schema/库、表、字段)规避数据库关键字重名冲突。
启用此配置可以规避名称与数据库关键字重名冲突的问题
DWS_ATTRIBUTE_QUOTE_ALL_FIELDS = Y/N; 含义:默认为 N,表示不启用,配置为Y表示启用,所有名称都使用双引号包裹,例如:Id=>"Id"。