# 将neo4j数据库数据经过处理后写入Kafka
本示例主要演示从neo4j中读取数据,通过FieldMapper组件进行字段映射,写入Kafka中。
主要步骤如下:
# 新建同步作业
点击数据同步上的【...】,选择弹出菜单【新建数据同步作业】,作业名称为:neo4j-kafka。
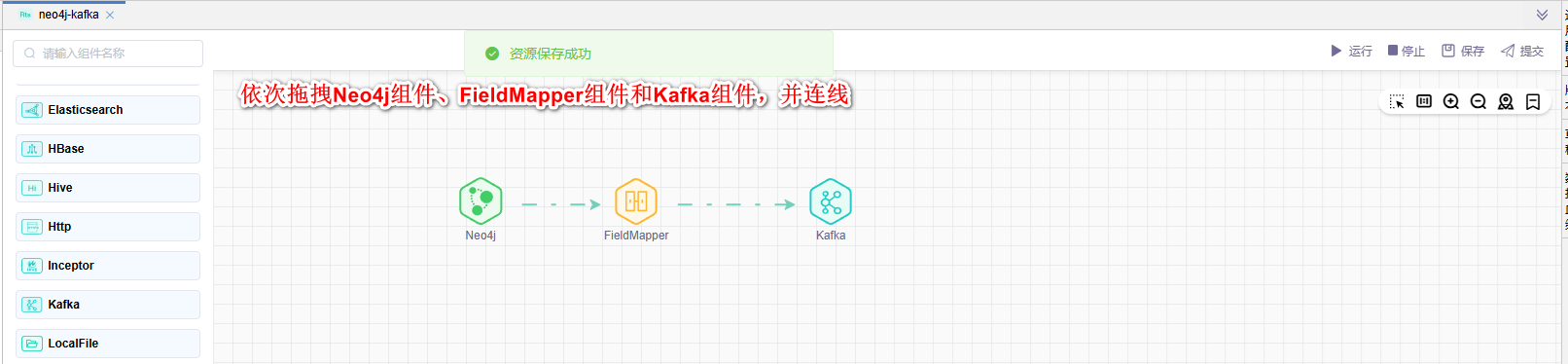
# 拖拽图元
依次拖拽数据源中的Neo4j Source组件、转换中的FieldMapper组件和目标中的Kafka Sink组件,依次连线。如下图所示:
# 配置组件属性
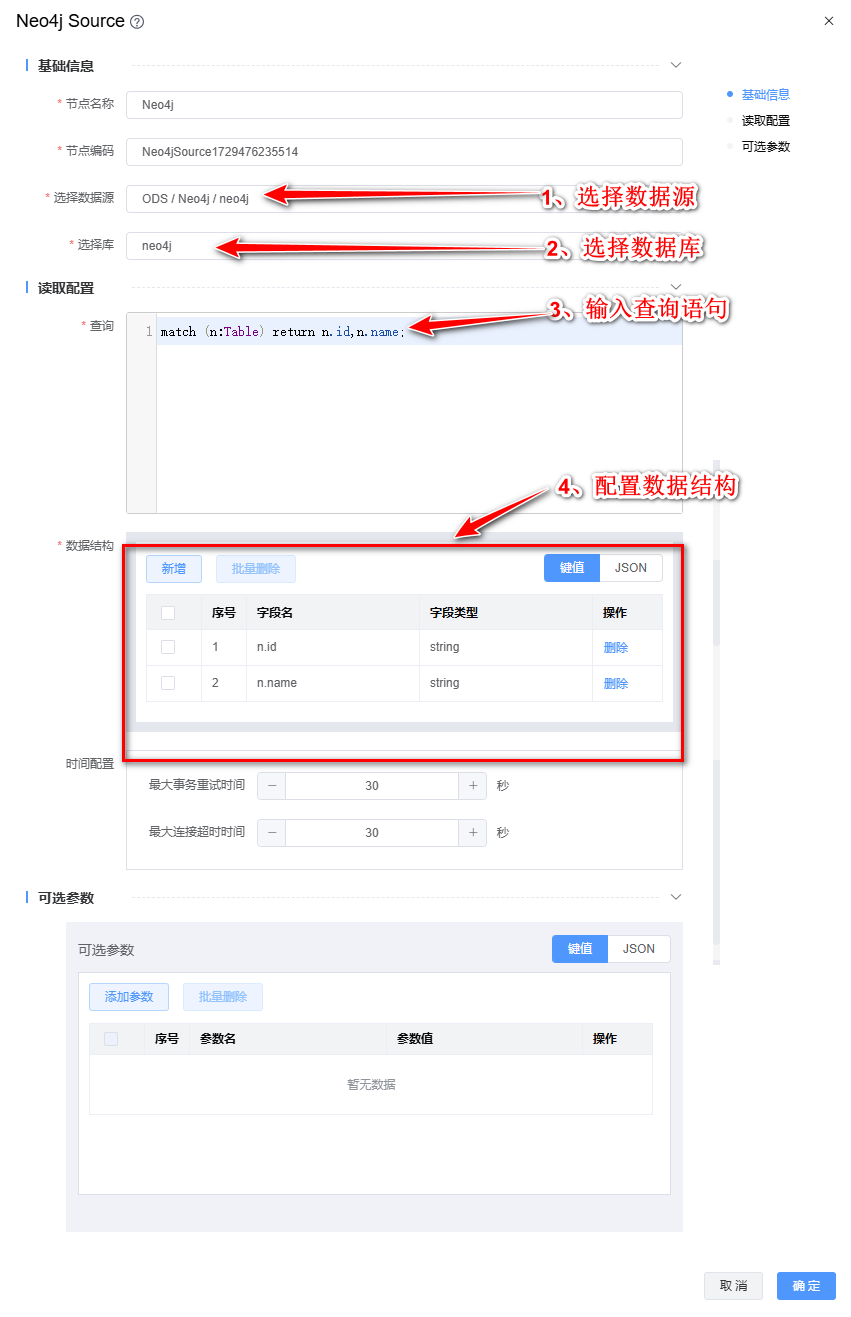
1、双击"Neo4j Source"组件,根据下图所示步骤依次配置。
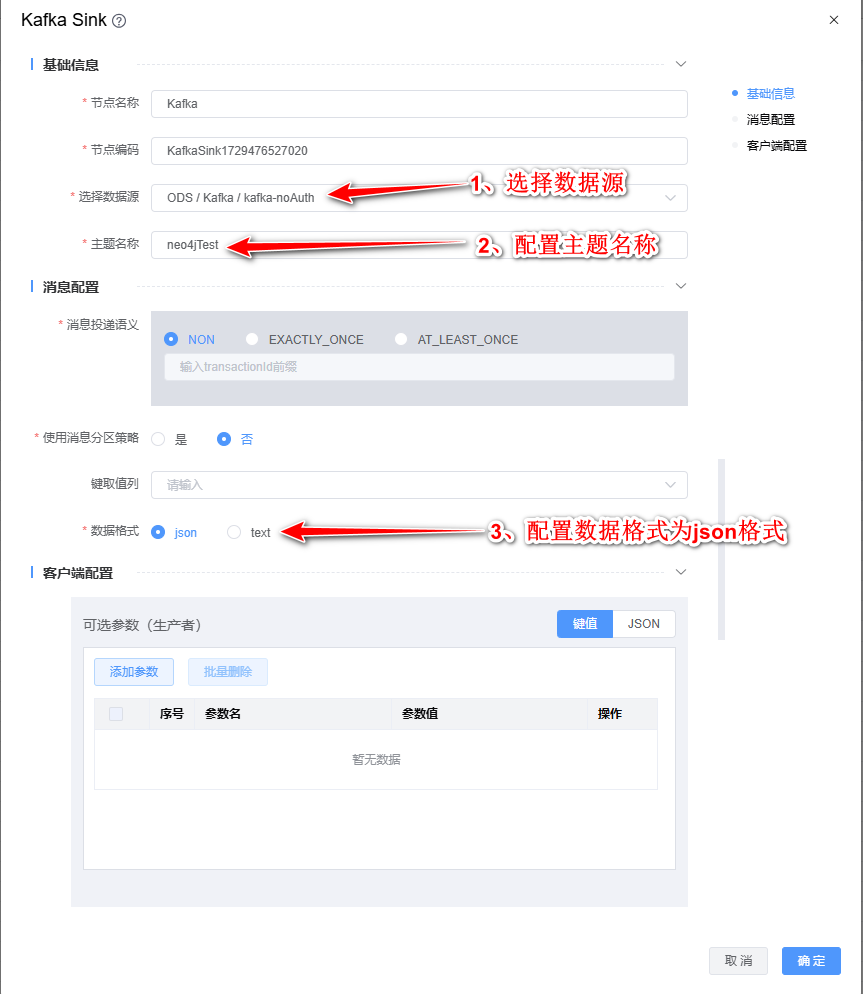
2、双击"Kafka Sink"组件,根据下图所示步骤依次配置。
3、双击"FieldMapper"组件,根据下图所示步骤依次配置。
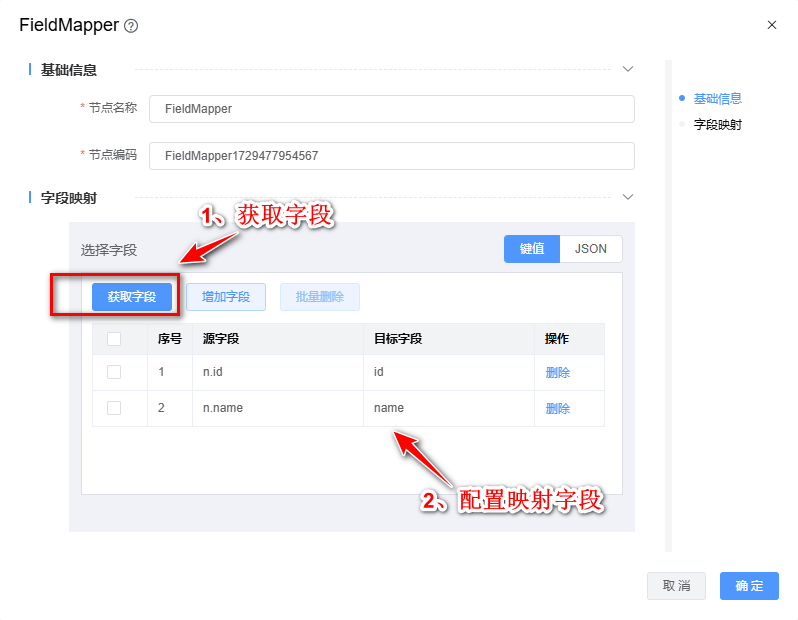
4、Ctrl+S保存该模型。
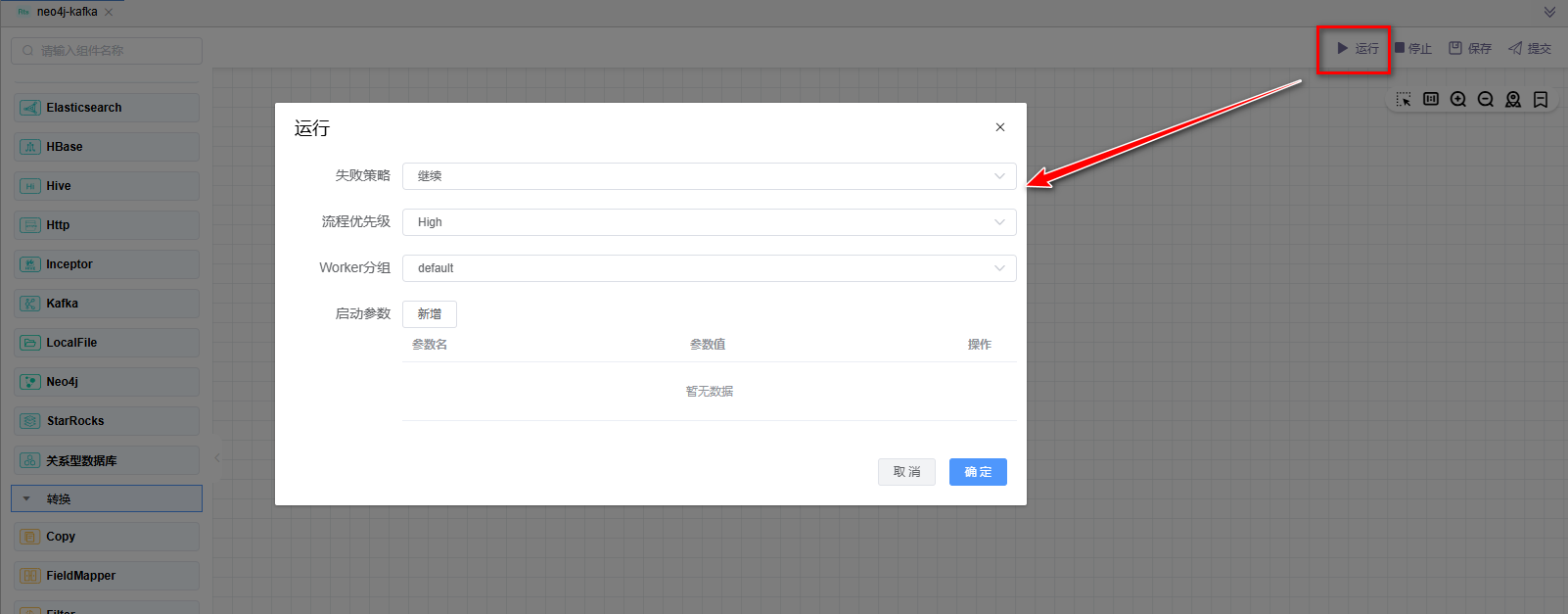
# 运行
点击【运行】按钮,可以运行已经开发完毕的场景,在日志栏可以看运行日志及运行结果。
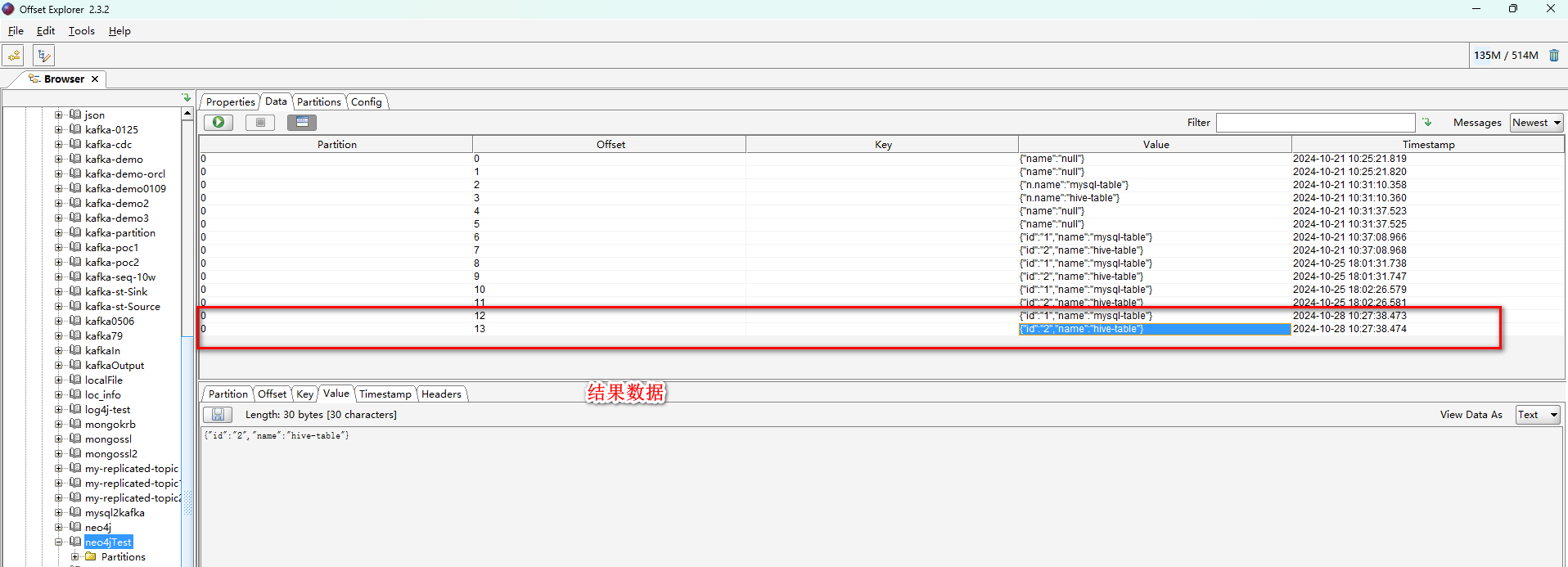
# 查看数据
在kafka中查看数据。
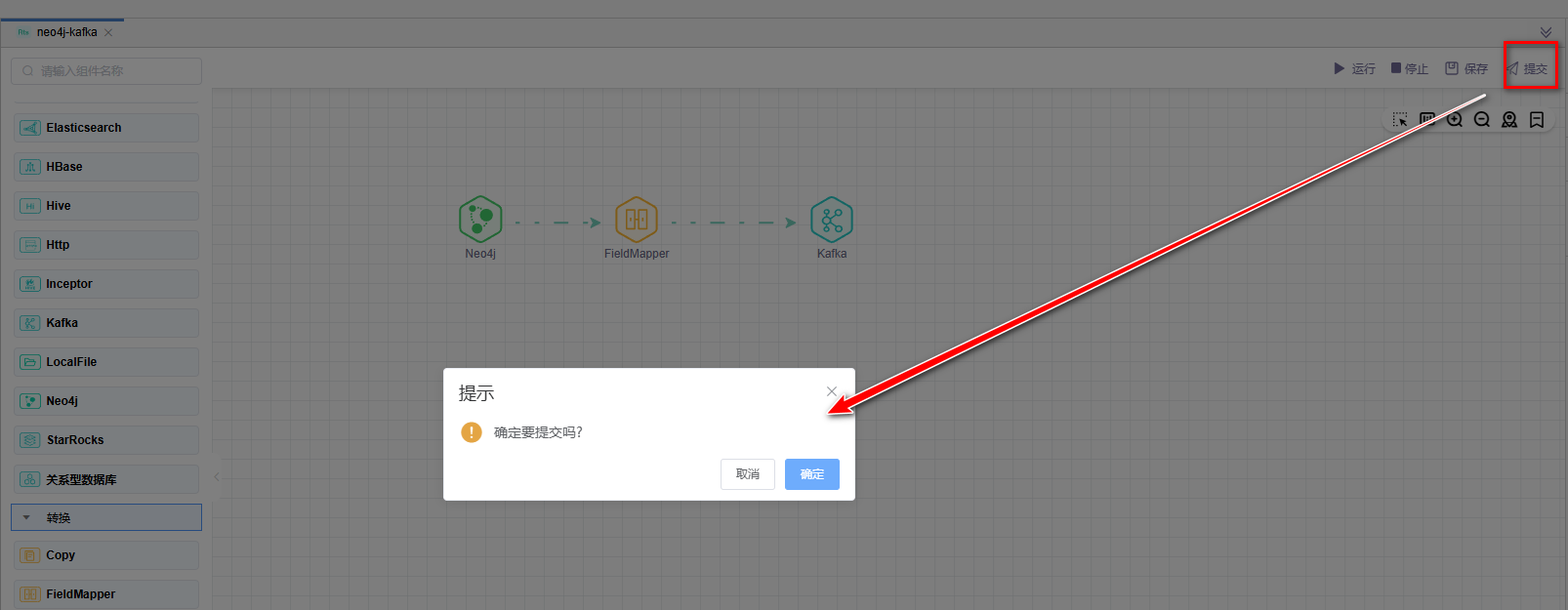
# 提交版本
当草稿运行正常后,点击【提交】按钮可以将该版本提交到作业调度,每次修改提交都会生成新的版本,可以看到提交的历史版本,并可以随意切换版本。
提交后的版本,可以在作业调度中进行"定时"调度配置。