# Kafka复杂Json数据写入文件
本示例主要演示从Kafka表中读取数据,通过JsonPath组件进行字段配置,将处理后的数据写入文件中。
主要步骤如下:
# 准备数据
1、在Kafka中创建主题example-userinfo,在主题中写入数据:
Kafka数据:
{
"_id": "670f897bf887ef30bee8ca2e",
"id": 1,
"name": "张三",
"age": 18,
"hobby": [
"音乐",
"美术",
"舞蹈"
],
"birthday": "2024-10-16",
"leader": true,
"salary": 1E+5,
"createTime": "1970-01-21",
"address": {
"city": "New York",
"zip": "10001",
"coordinates": {
"lng": -74.006,
"lat": 40.7128
}
}
}
2、在seatunnel目录下创建localfile文件夹,复制目录路径备用。 此示例的目录路径为:/home/seatunnel/apache-seatunnel-7.0.2/localfile
# 新建同步作业
点击数据同步上的【...】,选择弹出菜单【新建数据同步作业】,作业名称为:KafkaSource-JsonPath-SQL-LocalFile。
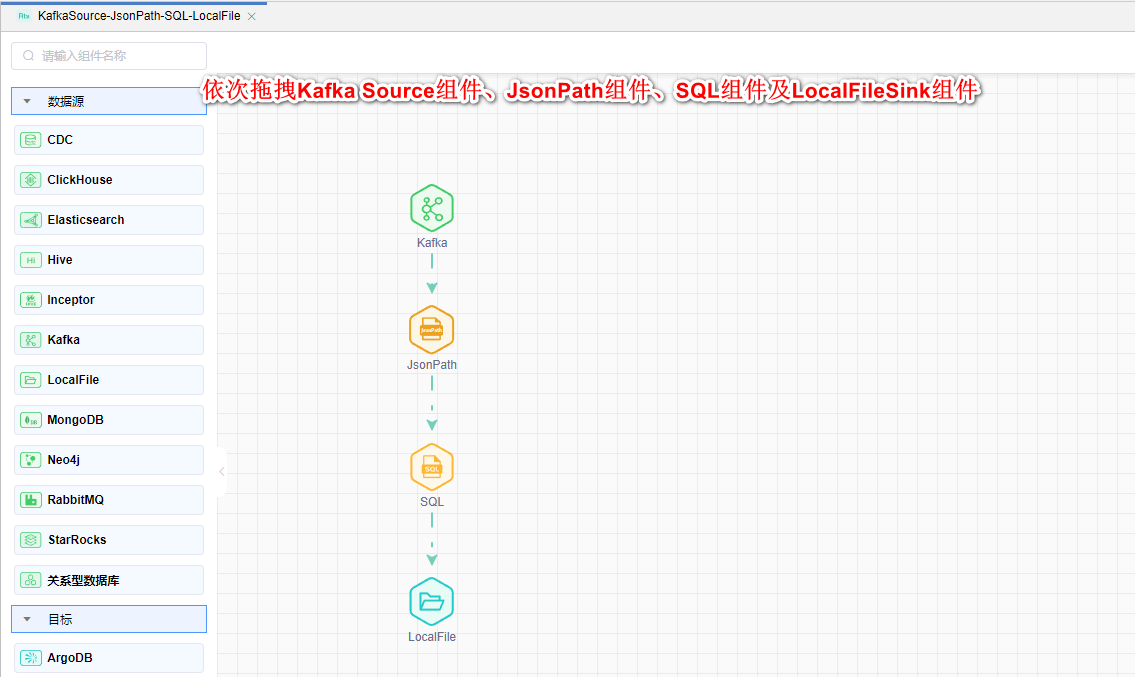
# 拖拽图元
依次拖拽数据源中的Kafka Source组件、转换中的JsonPath组件、SQL组件和目标中的LocalFile Sink组件,依次连线。如下图所示:
# 配置组件属性
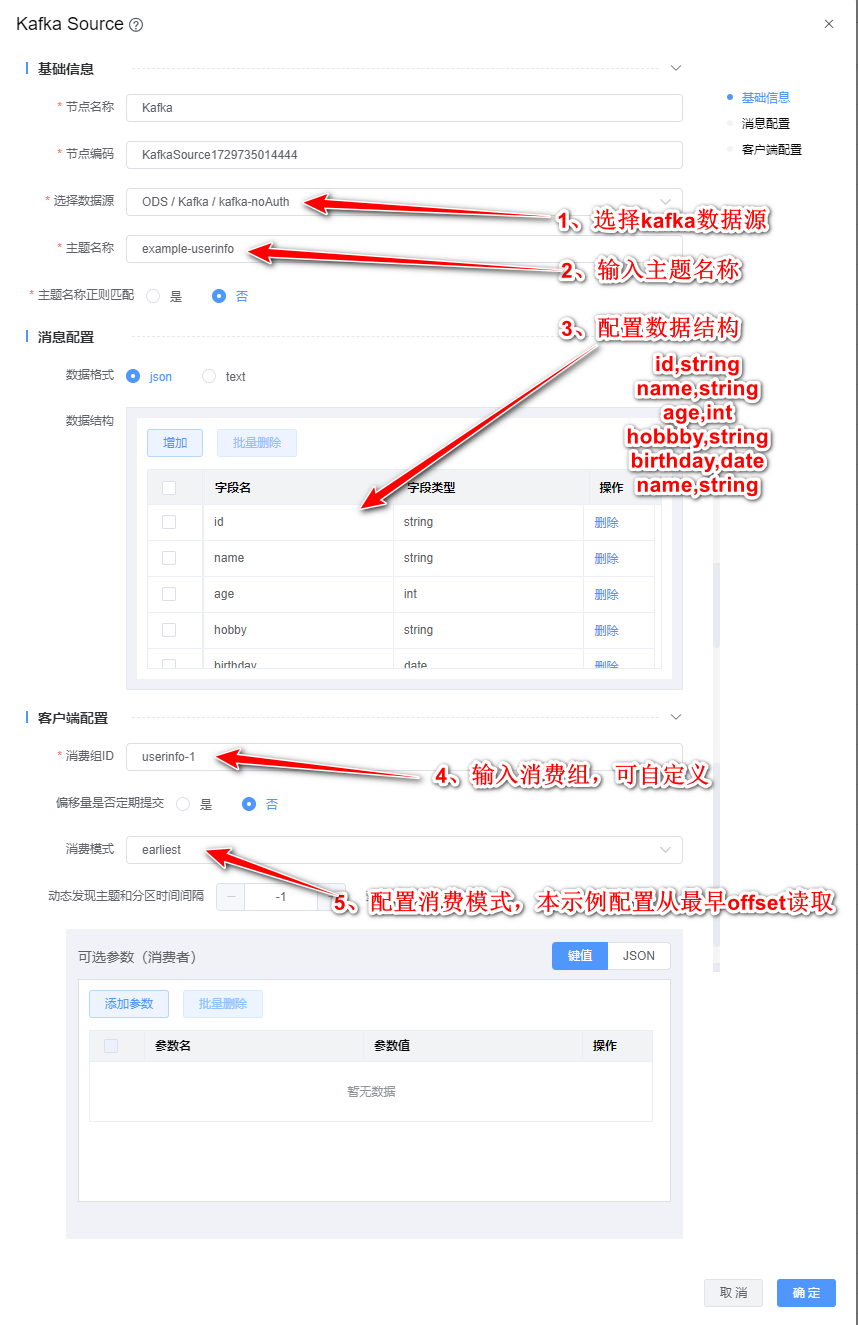
1、双击"Kafka Source"组件,根据下图所示步骤依次配置。
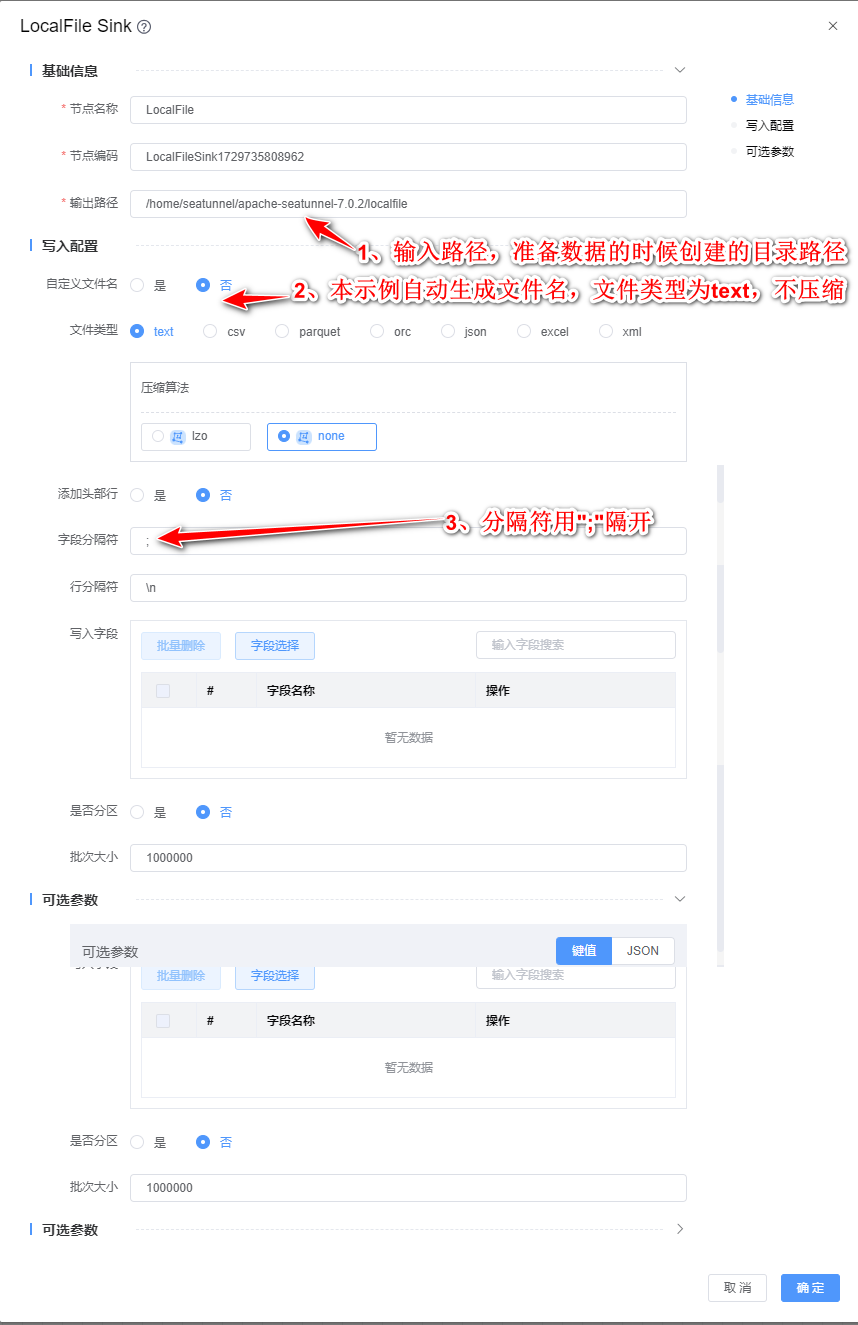
2、双击"LocalFile Sink"组件,根据下图所示步骤依次配置。
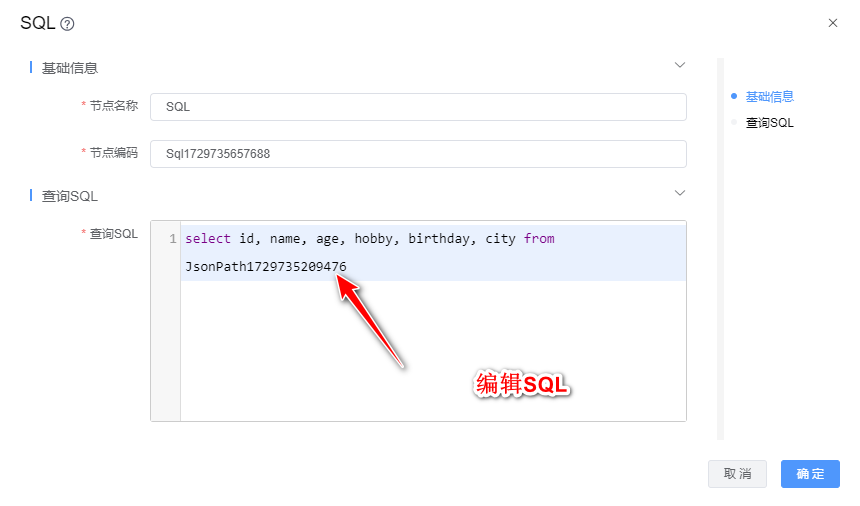
3、双击"SQL"组件,根据下图所示步骤依次配置。
查询SQL:select id, name, age, hobby, birthday, city from JsonPath1729735209476
其中JsonPath1729735209476为JsonPath组件的节点编码
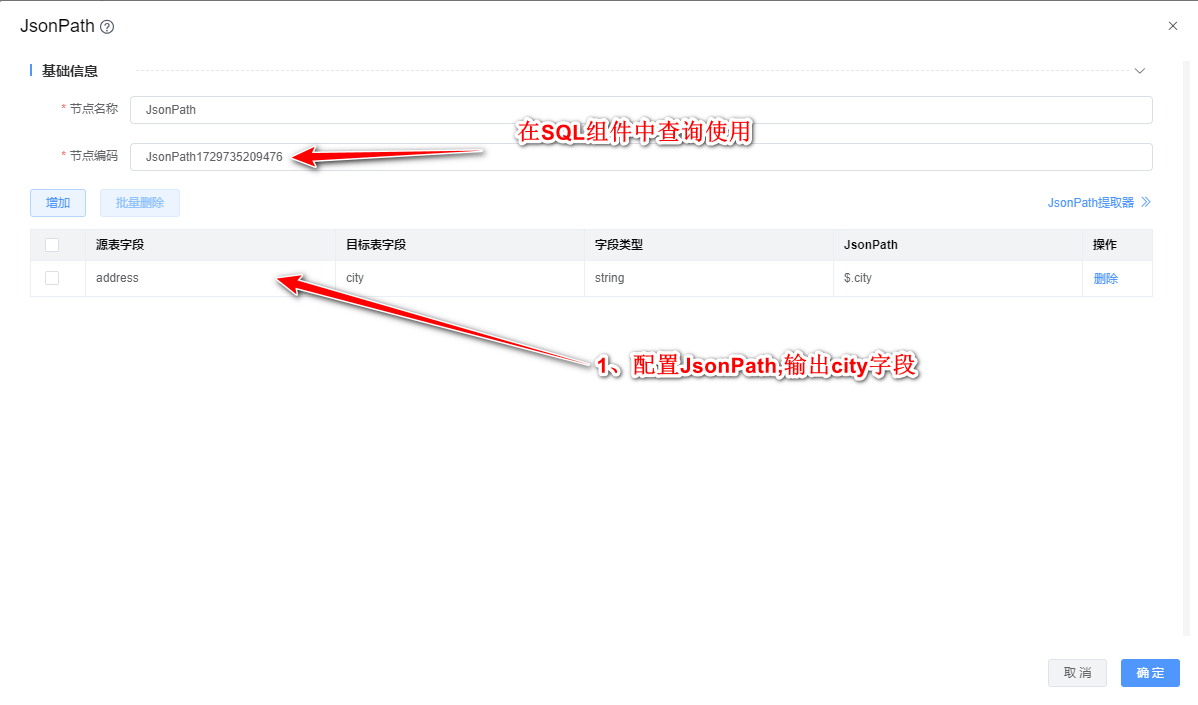
4、双击"JsonPath"组件,根据下图所示步骤依次配置。
5、Ctrl+S保存该模型。
# 运行
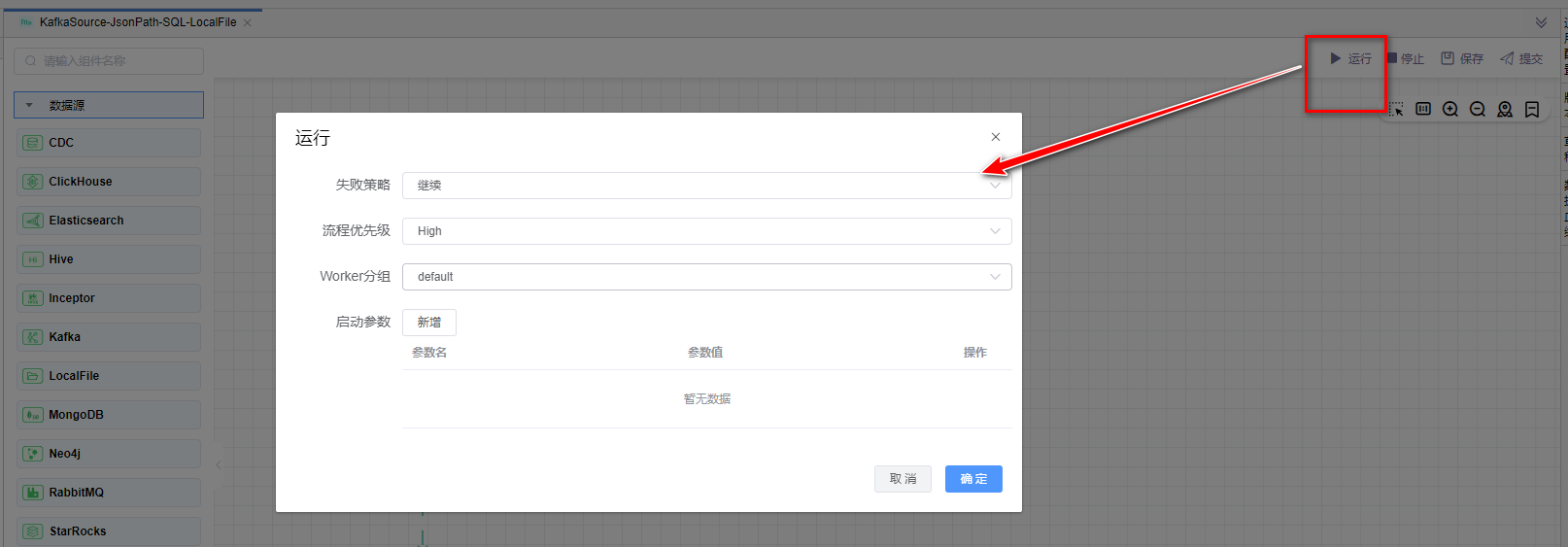
点击【运行】按钮,可以运行已经开发完毕的场景,在日志栏可以看运行日志及运行结果。
# 查看数据
在/home/seatunnel/apache-seatunnel-7.0.2/localfile下查看数据。

# 提交版本
当草稿运行正常后,点击【提交】按钮可以将该版本提交到作业调度,每次修改提交都会生成新的版本,可以看到提交的历史版本,并可以随意切换版本。
提交后的版本,可以在作业调度中进行"定时"调度配置。